Автор: Денис Аветисян
Исследователи представили DIFFA-2 — модель, использующую диффузионный подход для обработки и анализа звуковых данных, демонстрируя альтернативу традиционным методам.
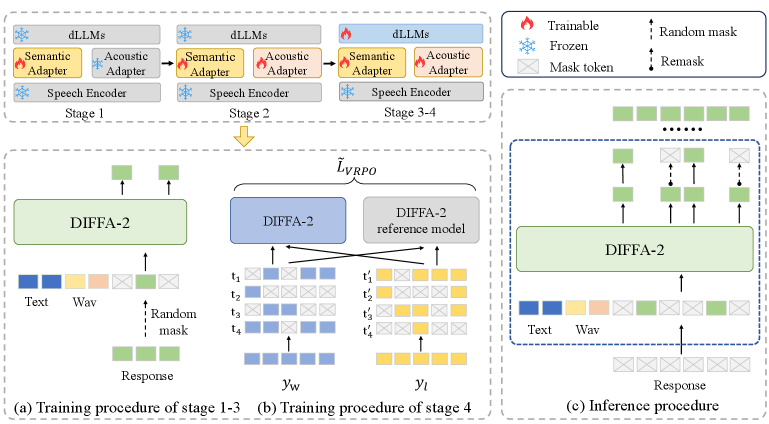
DIFFA-2 — диффузионная большая языковая модель, обеспечивающая конкурентоспособную производительность в задачах понимания звука и мультимодального обучения.
Авторегрессионные большие аудиоязыковые модели демонстрируют впечатляющие результаты в понимании и обработке звука, однако их масштабирование требует значительных вычислительных ресурсов и ограничивает скорость обработки. В данной работе представлена модель DIFFA-2, практичная диффузионная большая аудиоязыковая модель для общего понимания звука. DIFFA-2 использует улучшенный кодировщик речи, двойные семантические и акустические адаптеры, и обучена по четырехэтапной программе, сочетающей семантическое и акустическое выравнивание, масштабное контролируемое обучение и оптимизацию предпочтений с уменьшением дисперсии, используя исключительно открытые корпуса данных. Доказательство ли, что диффузионные модели могут стать эффективной основой для крупномасштабного анализа и обработки аудиоинформации, открывая новые возможности для мультимодального машинного обучения?
Эволюция Аудио-Языковых Моделей: От Теории к Практике
Быстрое развитие больших аудио-языковых моделей (Large Audio Language Models) знаменует собой важный прорыв в области искусственного интеллекта. Эти модели, способные одновременно обрабатывать и понимать как речь, так и текст, открывают новые возможности для взаимодействия человека и машины. Они не просто транскрибируют аудио или генерируют текст, а способны устанавливать сложные связи между ними, что позволяет решать задачи, требующие глубокого понимания контекста. Например, модели способны отвечать на вопросы по содержанию аудиозаписи, суммировать длинные аудиолекции или даже создавать новые аудиоматериалы на основе текстовых запросов. Такая интеграция речевого и текстового анализа существенно расширяет область применения ИИ, включая автоматизированные системы поддержки клиентов, образовательные платформы и инструменты для создания контента.
Первые модели обработки аудио и языка, известные как AR-LALM, использовали авторегрессивные методы, последовательно предсказывая следующие элементы аудио- или текстовой последовательности. Несмотря на первоначальный успех, эти модели столкнулись с ограничениями в обработке сложных взаимосвязей и логических выводов, что затрудняло понимание контекста и выполнение задач, требующих глубокого анализа. Кроме того, авторегрессивный подход оказался вычислительно затратным и неэффективным при работе с длинными последовательностями, что ограничивало масштабируемость и практическое применение этих моделей в реальных сценариях обработки аудио и языка. Эти недостатки стимулировали поиск альтернативных архитектур, способных преодолеть эти ограничения и обеспечить более мощную и эффективную обработку аудио-лингвистической информации.
Потребность в более мощных и масштабируемых архитектурах искусственного интеллекта привела к разработке диффузионных моделей (DiffusionLLMs). Традиционные авторегрессионные подходы, хоть и успешно справлялись с базовой обработкой речи и текста, демонстрировали ограниченные возможности в сложных рассуждениях и требовали значительных вычислительных ресурсов. В отличие от них, диффузионные модели используют принципиально иной подход, имитируя процесс постепенного добавления шума к данным, а затем — восстановление исходного сигнала. Такой метод позволяет создавать модели, способные к более эффективной генерации и пониманию аудио- и текстовой информации, а также лучше масштабироваться для обработки больших объемов данных. Этот переход к диффузионным моделям открывает новые перспективы в области создания интеллектуальных систем, способных к более естественному и сложному взаимодействию с человеком.
DIFFA: Первый Шаг к Диффузионной Обработке Аудио и Языка
DIFFA (Diffusion-based Framework for Audio-Language tasks) стала важным шагом вперед в области задач, связанных с обработкой аудио и языка, благодаря использованию диффузионных моделей. В отличие от традиционных авторегрессионных подходов, DIFFA применяет процесс постепенного добавления шума к данным, а затем обучения модели для его удаления, что позволяет генерировать более разнообразные и реалистичные результаты. Эта архитектура позволила впервые продемонстрировать потенциал диффузионных моделей в задачах, требующих одновременной обработки аудио и языковой информации, открывая новые возможности для исследований в данной области. Использование диффузии позволило модели изучать распределение данных более эффективно, чем предыдущие методы.
Экспериментальные результаты показали, что DIFFA продемонстрировала первоначальные улучшения по сравнению с авторегрессионными моделями в задачах, связанных с аудио и языком. В частности, наблюдалось повышение качества генерируемого аудио, а также улучшение метрик, оценивающих соответствие аудио и текстового описания. Эти результаты подтвердили перспективность использования диффузионных моделей в качестве альтернативы традиционным авторегрессионным архитектурам для задач обработки аудио и речи, что послужило стимулом для дальнейших исследований в данной области.
Несмотря на то, что DIFFA продемонстрировала перспективные результаты в задачах обработки аудио и речи, модель имела ряд ограничений, которые послужили мотивацией для разработки более надежной и эффективной преемницы. К этим ограничениям относились проблемы с генерацией длинных последовательностей, вычислительная сложность процесса диффузии и трудности с достижением стабильной производительности на различных наборах данных. Эти факторы обусловили необходимость в архитектуре, способной преодолеть указанные недостатки и обеспечить более качественные и устойчивые результаты в задачах синтеза и обработки звука.
DIFFA-2: Укрепление Диффузионной Архитектуры
DIFFA-2 представляет собой масштабную языковую модель, основанную на диффузионных моделях и предназначенную для обработки аудиоданных. Архитектура модели разработана для достижения высокой производительности в задачах, связанных с пониманием и генерацией речи. В отличие от традиционных подходов, DIFFA-2 использует принципы диффузии для создания более реалистичных и детализированных аудиовыходов, что позволяет ей превосходить существующие решения в качестве и точности. Модель относится к классу больших языковых моделей (LLM), что подразумевает использование значительного количества параметров и обучение на обширных наборах данных для достижения высокого уровня понимания и генерации аудиоконтента.
В основе архитектуры DIFFA-2 лежит использование модели Whisper-Large-V3 для кодирования речевого сигнала, обеспечивающее извлечение информативных признаков из аудиоданных. Для согласования этих аудиопредставлений с семантическим пространством используется компонент SemanticAdapter, который выполняет адаптацию признаков, позволяя модели понимать смысл и контекст произнесенной речи. Это обеспечивает эффективное представление аудиоинформации для последующей обработки и генерации.
В основе DIFFA-2 лежит применение Low-Rank Adaptation (LoRA) для эффективной тонкой настройки модели, что позволяет значительно снизить вычислительные затраты и объем требуемой памяти. Для захвата тонких акустических характеристик используется AcousticAdapter, взаимодействующий с Q-Former. Q-Former выполняет роль интерфейса, преобразуя аудиосигналы в векторные представления, которые затем обрабатываются AcousticAdapter для более точной передачи акустической информации в процессе генерации речи или анализа аудио.
Для повышения производительности DIFFA-2 использует поэтапное обучение (ProgressiveTraining), которое включает в себя три типа данных. ASRData — это данные автоматического распознавания речи, используемые для начальной фазы обучения модели. SFTData — данные, полученные в результате обучения с подкреплением на основе человеческих предпочтений (Supervised Fine-Tuning Data), применяемые для улучшения точности и связности генерируемого аудио. На заключительном этапе используется PreferenceAlignmentData — данные, предназначенные для точной настройки модели в соответствии с предпочтениями пользователей, что позволяет достичь оптимального качества и соответствия запросам.
DIFFA-2 демонстрирует высокую производительность, используя всего 99 миллионов обучаемых параметров, что составляет лишь 1.1% от общего числа параметров модели. Обучение осуществлялось на 14 800 часах открытых данных, что позволило достичь значительных результатов при относительно небольшом количестве используемых ресурсов и данных. Эффективность использования параметров свидетельствует об оптимизации архитектуры и методов обучения, позволяющих добиться высокого качества генерации аудио с минимальными вычислительными затратами.
Валидация Производительности и Широкое Влияние
Модель DIFFA-2 прошла тщательное тестирование на авторитетных бенчмарках, включающих MMSU, MMAU и MMAR, демонстрируя стабильно высокие результаты в сравнении с другими существующими решениями. Эти комплексные оценки подтверждают эффективность архитектуры модели и её способность к точной обработке и пониманию аудиоданных. В ходе тестирования DIFFA-2 показала конкурентоспособные показатели по всем ключевым метрикам, что свидетельствует о её надежности и потенциале для широкого спектра применений в области распознавания и обработки речи. Результаты, полученные на этих бенчмарках, служат надежным подтверждением качества и производительности модели, выделяя её среди аналогов.
В ходе тестирования на наборе данных MMAU Test-mini модель DIFFA-2 продемонстрировала высокую точность, достигнув показателя в 69.60%. Этот результат превосходит аналогичные показатели других открытых моделей, что свидетельствует о повышенной эффективности DIFFA-2 в задачах, требующих детального понимания и точной интерпретации аудиоинформации. Достижение такого уровня точности открывает возможности для более надежного и качественного выполнения задач в различных областях, включая распознавание речи, анализ звуковых сигналов и автоматическую транскрипцию.
В ходе всестороннего тестирования на бенчмарке MMSU, модель DIFFA-2 продемонстрировала общую точность в 60.45%. Этот результат позволяет констатировать незначительное, но уверенное превосходство над такими признанными моделями, как Kimi-Audio (59.28%) и Qwen2.5-Omni (59.09%). Достижение более высокой точности на MMSU указывает на улучшенную способность DIFFA-2 к пониманию и обработке сложных аудиозапросов, что делает её перспективным инструментом для широкого спектра приложений, связанных с распознаванием и анализом речи.
В ходе тестирования на бенчмарке MMAR модель DIFFA-2 продемонстрировала значительный прогресс, достигнув общей точности в 50.80%. Этот результат на 13.6 процентных пункта превосходит показатели предыдущей версии, DIFFA, которая показывала точность в 37.20%. Подобное улучшение свидетельствует об эффективности внесенных изменений в архитектуру и процесс обучения, позволяя модели более точно интерпретировать и обрабатывать сложные акустические данные. Достигнутый прогресс открывает возможности для более широкого применения DIFFA-2 в задачах, требующих высокой точности распознавания и анализа звуковой информации.
Интеграция оптимизации на основе снижения дисперсии предпочтений (VarianceReducedPreferenceOptimization) позволила значительно улучшить способность модели следовать инструкциям и учитывать акустические особенности входных данных. Этот метод, основанный на минимизации вариативности в процессе обучения, позволяет модели более точно интерпретировать запросы пользователей и адаптироваться к различным условиям записи звука. В результате, DIFFA-2 демонстрирует повышенную надежность и стабильность в задачах распознавания и синтеза речи, обеспечивая более качественный и естественный результат даже при наличии шумов или искажений в аудиосигнале. Данный подход позволяет модели не просто понимать, что сказано, но и как это сказано, что является ключевым фактором для достижения высокого уровня производительности в реальных сценариях использования.
Для повышения практической применимости модели DIFFA-2 была внедрена методика FactorBasedParallelDecoding. Данный подход позволяет значительно ускорить процесс вывода данных, разбивая задачу на параллельно обрабатываемые компоненты. Это достигается за счет факторизации вычислений, что снижает общую нагрузку и время отклика модели. В результате, DIFFA-2 демонстрирует повышенную эффективность при обработке запросов, что делает её более подходящей для использования в реальных приложениях, требующих оперативной обработки аудиоданных, таких как системы голосового управления или автоматизированные сервисы транскрипции. Благодаря этой оптимизации, модель становится более доступной для широкого круга пользователей и разработчиков.
Исследование, представленное в данной работе, демонстрирует элегантность подхода к пониманию аудио, используя диффузионные языковые модели. DIFFA-2, в своей архитектуре, подчеркивает важность целостного взгляда на систему — нельзя изолированно улучшать отдельные компоненты, не учитывая их взаимодействие. Как однажды заметил Карл Фридрих Гаусс: «Всякое разложение начинается на границах ответственности — если их не видно, скоро будет больно». Эта фраза точно отражает суть проектирования надежных систем, где четкое определение границ и взаимодействие компонентов являются ключевыми. В данном контексте, успешность DIFFA-2 подтверждает, что структурированный подход к моделированию, учитывающий взаимосвязи между данными и компонентами, приводит к созданию эффективных и устойчивых решений для задач мультимодального обучения.
Что Дальше?
Представленная работа, демонстрируя конкурентоспособность диффузионных моделей в области понимания аудио, открывает любопытную перспективу. Однако, аналогия с пересадкой сердца намекает на необходимость более глубокого понимания “кровотока” — то есть, принципов, лежащих в основе обработки мультимодальной информации. Простое наращивание параметров модели, как правило, не решает фундаментальных проблем; скорее, маскирует их. Необходимо исследовать, как диффузионные модели могут эффективно интегрировать информацию из различных источников, не теряя при этом контекстуальную целостность.
Очевидным направлением дальнейших исследований является преодоление ограничений, связанных с параллельным декодированием. Скорость и эффективность — важные параметры, но они должны быть согласованы с качеством и точностью. Поиск оптимального баланса между этими характеристиками — сложная задача, требующая нетривиальных решений. Более того, необходимо учитывать, что структура модели определяет ее поведение, и любое изменение должно быть тщательно продумано с учетом этой взаимосвязи.
В конечном счете, истинный прогресс в области понимания аудио не будет достигнут путем простого копирования архитектур, успешных в других областях. Требуется элегантный дизайн, основанный на простоте и ясности. Задача состоит не в том, чтобы создать еще одну “черную коробку”, а в том, чтобы понять, как информация представлена и обработана в мозге, и попытаться воспроизвести эти принципы в искусственных системах.
Оригинал статьи: https://arxiv.org/pdf/2601.23161.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Искусственный интеллект: хрупкость визуального мышления
- Квантовая механика: скрытый детерминизм?
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
- Текстуры обмана: Как взломать ИИ, управляющий роботами
2026-02-03 05:56