Автор: Денис Аветисян
Новое исследование показывает, что даже небольшие языковые модели способны эффективно оценивать качество текста, полагаясь на внутренние представления, а не на объем знаний.
В статье представлен метод Representation-as-a-Judge, демонстрирующий возможность оценки текстов малыми языковыми моделями на основе асимметрии семантической ёмкости внутренних представлений.
Широко распространенная практика использования больших языковых моделей (LLM) в качестве автоматических оценщиков, несмотря на свою популярность, сопряжена с высокими вычислительными затратами и непрозрачностью. В настоящей работе, озаглавленной ‘Rethinking LLM-as-a-Judge: Representation-as-a-Judge with Small Language Models via Semantic Capacity Asymmetry’, исследуется возможность применения небольших моделей для эффективной оценки, используя внутренние представления, а не генерацию текста. Авторы показали, что небольшие языковые модели, несмотря на ограниченные возможности генерации, кодируют значимые оценочные сигналы в своих скрытых состояниях, что указывает на асимметрию в требуемой семантической емкости для оценки и генерации. Может ли новый подход, переходящий от парадигмы «LLM-как-судья» к «Представление-как-судья», открыть путь к более экономичным, надежным и интерпретируемым системам оценки?
Выявление Сущности Рассуждений: Проблемы Оценки
Оценка способности к рассуждениям у больших языковых моделей (LLM) представляет собой сложную задачу, поскольку существующие методы часто опираются на аннотации, выполненные людьми, или на использование других LLM в качестве «судей». Оба подхода имеют свои недостатки: ручная аннотация требует значительных временных и финансовых затрат, а также подвержена субъективности, в то время как LLM-основанные оценки могут быть предвзятыми, отражая ограничения и предубеждения самой модели-оценщика. Это создает серьезную проблему при определении истинного уровня интеллектуальных способностей LLM и затрудняет прогресс в разработке и внедрении более надежных и эффективных систем искусственного интеллекта, поскольку сложно отличить реальное рассуждение от поверхностного сопоставления с шаблонами.
Современные методы оценки способностей больших языковых моделей сталкиваются с серьезной проблемой: отличить подлинное рассуждение от поверхностного сопоставления с образцами. Модели могут успешно решать задачи, просто находя закономерности в данных, не демонстрируя при этом настоящего понимания или способности к обобщению. Это затрудняет объективную оценку прогресса в разработке искусственного интеллекта и препятствует внедрению этих моделей в критически важные приложения, где надежность и обоснованность ответов имеют первостепенное значение. Отсутствие четкой дифференциации между этими подходами не позволяет точно определить, насколько модели действительно способны к решению новых, нестандартных задач, и, следовательно, ограничивает их потенциал.

Раскрытие Внутренних Сигналов Рассуждений
Гипотеза асимметрии семантической емкости предполагает, что оценка требует меньших семантических ресурсов, чем генерация. Это указывает на то, что оценочные сигналы уже присутствуют во внутренних представлениях языковой модели, не требуя сложных вычислительных процессов для их формирования. Данный феномен объясняется тем, что оценка может сводиться к сопоставлению входных данных с существующими внутренними представлениями, в то время как генерация требует создания новых представлений и их последующей реализации в виде текста. Следовательно, модели способны оценивать информацию, используя относительно небольшую часть своих семантических ресурсов, что подтверждается экспериментальными данными и является основой для извлечения оценочных сигналов из внутренних представлений модели.
Метод “Representation-as-Judge” использует предположение о том, что оценочные сигналы присутствуют во внутренних представлениях языковой модели, и извлекает эти сигналы непосредственно из латентной структуры небольших языковых моделей. В отличие от подхода “LLM-as-Judge”, требующего явных запросов и внешних знаний для формирования оценок, данный метод обходит необходимость в дополнительных входных данных или обучении. Извлечение оценочных сигналов осуществляется путем анализа существующих внутренних представлений модели, что позволяет оценивать качество различных вариантов без генерации текстовых суждений или обращения к внешним базам знаний. Это позволяет значительно упростить процесс оценки и снизить вычислительные затраты.
В отличие от подхода LLM-as-Judge, где оценка формируется путем генерации языковой моделью суждений на основе входных данных, метод Representation-as-a-Judge принципиально отличается. Он не предполагает создания оценок “с нуля”, а фокусируется на декодировании уже существующих оценочных сигналов, заложенных во внутреннем представлении модели. Это означает, что вместо того, чтобы запрашивать у модели мнение, происходит извлечение информации о ее внутренних предпочтениях и оценках, закодированных в латентном пространстве. Таким образом, акцент смещается с генерации суждений на декодирование уже имеющихся оценочных сигналов.
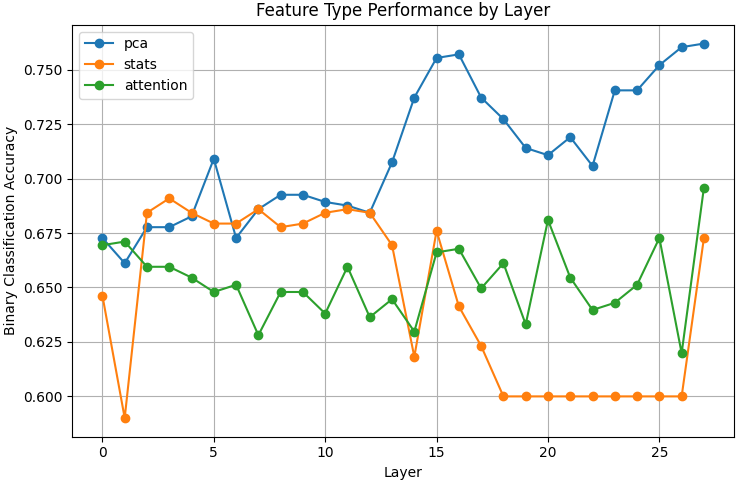
INSPECTOR: Фреймворк Оценки на Основе Зондирования
Фреймворк INSPECTOR представляет собой новый подход к оценке способностей языковых моделей к рассуждениям, основанный на методах зондирования (probing). В отличие от традиционных методов оценки, требующих наличия эталонных ответов, INSPECTOR анализирует внутренние представления модели, извлекая информацию из скрытых состояний. Это позволяет проводить оценку без необходимости использования внешних данных или эталонных решений, что делает процесс оценки более гибким и независимым. Техника зондирования заключается в обучении классификаторов на основе внутренних представлений модели, что позволяет выявлять, как именно модель обрабатывает информацию и выполняет рассуждения.
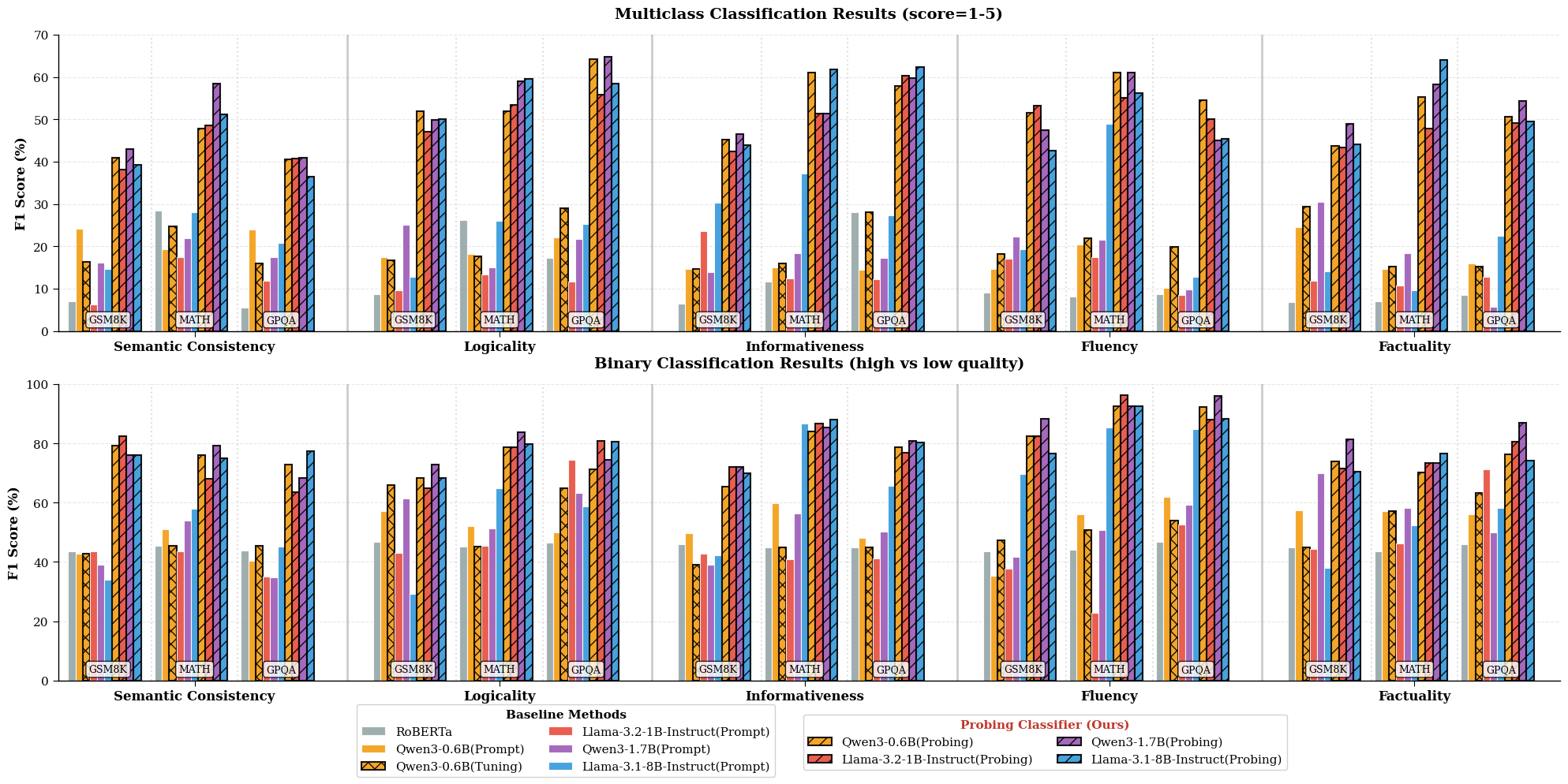
В рамках INSPECTOR, оценка производительности языковых моделей на сложных задачах рассуждений, таких как GSM8K, MATH и GPQA, осуществляется путем обучения классификаторов на скрытых состояниях небольших языковых моделей. Использование бинарных классификаторов, обученных на этих скрытых состояниях, позволяет достичь показателя F1 в диапазоне 80-90%. Этот подход позволяет оценить внутренние представления модели и её способность к рассуждениям без необходимости использования внешних эталонных ответов или сложных метрик.
В рамках INSPECTOR для эффективной обработки многомерных внутренних представлений языковых моделей используются методы снижения размерности, в частности, метод главных компонент (PCA). Экспериментальные данные демонстрируют, что применение PCA приводит к улучшению показателя F1 на 20% и более по сравнению с базовыми подходами, основанными на прямом запросе (prompting). Это улучшение обусловлено способностью PCA выделять наиболее значимые признаки из скрытых состояний, что позволяет классификаторам точнее оценивать рассуждения модели без использования эталонных ответов.
Усиление Надежности посредством Фильтрации Данных
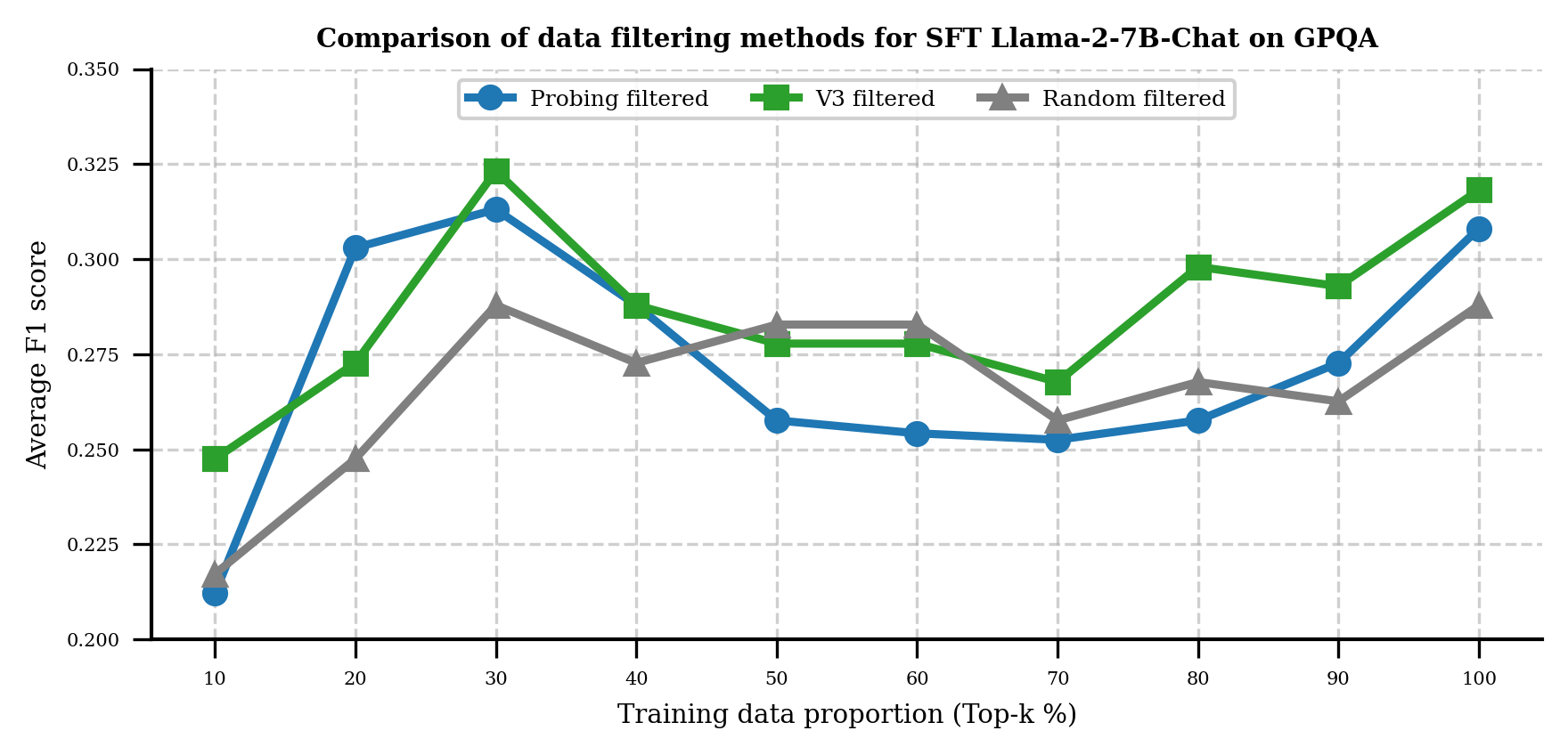
Эффективность INSPECTOR, как и любой другой методики оценки, основанной на анализе данных, напрямую зависит от качества используемого обучающего набора. Недостаточно чистые или вводящие в заблуждение данные способны существенно исказить результаты, приводя к неверным выводам о производительности оцениваемой системы. Поэтому тщательный отбор высококачественных примеров является критически важным этапом, позволяющим минимизировать влияние шума и обеспечить надежность и объективность оценки. Именно качество исходных данных определяет способность алгоритма к обобщению и точному прогнозированию, влияя на достоверность всех последующих аналитических выводов.
Отбор высококачественных данных играет ключевую роль в обеспечении надёжности любой системы, основанной на анализе данных. Некачественные или вводящие в заблуждение примеры могут существенно исказить результаты оценки и привести к ошибочным выводам. Процесс фильтрации данных позволяет выявлять и исключать такие примеры, тем самым повышая точность и стабильность оценки. Особенно важно это в контексте сложных моделей, где даже незначительные погрешности в обучающих данных могут привести к существенным отклонениям в работе системы. Эффективная фильтрация данных — это не просто удаление «шума», но и активный процесс улучшения качества обучающего набора, что в конечном итоге способствует созданию более надёжных и обобщаемых моделей.
Исследования показали, что использование сбалансированного набора данных, состоящего из 5 * n примеров (где n — минимальное количество примеров для каждого уровня оценки), позволяет добиться эффективной оценки даже при ограниченном объеме данных. Такой подход особенно важен для задач, где сбор большого количества размеченных данных затруднен или невозможен. В частности, применение контролируемого обучения с подкреплением (SFT) на основе отфильтрованных и сбалансированных данных значительно улучшает надежность и обобщающую способность метрик оценки. Это означает, что полученные оценки будут более устойчивы к шуму и отклонениям в данных, а также лучше переноситься на новые, ранее не виданные примеры, что критически важно для создания действительно полезных и достоверных систем оценки.
Исследование демонстрирует, что даже небольшие языковые модели способны кодировать достаточные оценочные сигналы во внутренних представлениях, что ставит под вопрос необходимость использования огромных моделей для оценки качества генерируемого текста. Этот подход, названный Representation-as-a-Judge, подчеркивает важность внутренней логики и структуры модели, а не просто ее размера. Как заметил Роберт Тарьян: «Структуры данных и алгоритмы — это не самоцель, а средство для решения задач». Эта фраза прекрасно отражает суть работы, где акцент делается на эффективном использовании внутренних представлений модели для достижения высокой точности оценки, что является доказательством математической чистоты и элегантности подхода.
Что дальше?
Представленные результаты, хотя и обнадеживают, не отменяют необходимости критического взгляда на саму природу «оценки» в контексте языковых моделей. Утверждение о том, что «достаточно» оценочных сигналов содержится во внутренних представлениях малых моделей, требует дальнейшей формализации. Необходимо строгое математическое описание этих сигналов, их связь с различными аспектами «качества» текста и, самое главное, доказательство их универсальности — а не просто работоспособности на ограниченном наборе данных. Оптимизация без анализа, как известно, — это самообман и ловушка для неосторожного разработчика.
Особое внимание следует уделить проблеме фильтрации данных, используемых для «прощупывания» внутренних представлений. Зависимость от конкретного набора данных для обучения и прощупывания — это слабое место, которое необходимо устранить. Разработка методов, устойчивых к шуму и предвзятости в данных, представляется критически важной задачей. В противном случае, мы рискуем создать систему, которая просто воспроизводит предрассудки, заложенные в исходных данных.
И, наконец, следует помнить о фундаментальном вопросе: что вообще означает «оценить» текст? Имеем ли мы дело с объективной характеристикой, или же оценка всегда субъективна и контекстуальна? Иными словами, даже самая точная и эффективная система оценки останется лишь приближением к идеалу, если мы не сможем четко определить, что этот идеал собой представляет.
Оригинал статьи: https://arxiv.org/pdf/2601.22588.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Экзотические разложения: новые грани цилиндрической алгебры
- Навыки агентов: Новый уровень интеллекта ИИ
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Иллюзия Компетентности: Как ИИ Переоценивает Себя
2026-02-03 07:26