Автор: Денис Аветисян
Исследователи предлагают принципиально новый подход к пониманию и улучшению архитектуры трансформеров, рассматривая их как дискретные алгоритмы оптимизации.
Представлен фреймворк YuriiFormer, использующий методы ускоренной оптимизации на основе динамических систем для повышения эффективности и производительности трансформеров.
Несмотря на впечатляющие успехи, архитектура трансформеров остается недостаточно изученной с точки зрения фундаментальных принципов оптимизации. В статье ‘YuriiFormer: A Suite of Nesterov-Accelerated Transformers’ предложена вариационная схема, интерпретирующая слои трансформера как итерации алгоритма оптимизации, действующего на векторные представления токенов, где самовнимание реализует шаг градиентного спуска энергии взаимодействия, а MLP-слои — обновление потенциальной энергии. Данный подход позволил разработать архитектуру, ускоренную методом Нестерова, демонстрирующую превосходство над базовой моделью nanoGPT на задачах TinyStories и OpenWebText. Может ли подобная трактовка трансформеров как дискретных оптимизационных алгоритмов привести к созданию принципиально новых и более эффективных архитектур нейронных сетей?
Трансформеры и границы градиентного спуска
Несмотря на впечатляющие успехи, стандартные архитектуры Transformer в процессе обучения полагаются на вычислительно затратный метод градиентного спуска, что становится серьезным препятствием для масштабирования. Этот метод требует огромного количества вычислений для корректировки параметров модели, особенно при работе с большими объемами данных и сложными задачами. Каждая итерация обучения предполагает вычисление градиентов по всем параметрам, что требует значительных ресурсов памяти и вычислительной мощности. По мере увеличения размера модели и объёма данных, время обучения и необходимые ресурсы экспоненциально возрастают, ограничивая возможность применения Transformer к задачам, требующим ещё большей мощности и сложности. Таким образом, зависимость от градиентного спуска является узким местом, препятствующим дальнейшему развитию и масштабированию архитектур Transformer.
В процессе обучения больших трансформеров традиционные методы оптимизации сталкиваются с существенными трудностями, обусловленными сложностью и высокой размерностью ландшафта функции потерь. Этот ландшафт характеризуется многочисленными локальными минимумами, седловыми точками и плоскими областями, что затрудняет эффективный поиск глобального минимума. Стандартные алгоритмы, такие как стохастический градиентный спуск, часто «застревают» в локальных оптимумах или демонстрируют медленную сходимость, требуя значительных вычислительных ресурсов и времени для достижения приемлемой производительности. Особенно остро эта проблема проявляется при масштабировании моделей для решения более сложных задач и обработки огромных объемов данных, где даже небольшие отклонения от оптимального решения могут существенно повлиять на конечный результат. Изучение и разработка новых методов оптимизации, способных эффективно преодолевать эти препятствия, является ключевой задачей для дальнейшего развития и применения трансформеров.
Неэффективность стандартных методов оптимизации особенно ярко проявляется при масштабировании Transformer-архитектур для решения более сложных задач и обработки больших объемов данных. По мере увеличения размера модели и датасета, поверхность функции потерь становится чрезвычайно изрезанной и многомерной, что существенно затрудняет поиск глобального минимума с помощью градиентного спуска. Этот процесс требует экспоненциально больше вычислительных ресурсов и времени, что становится серьезным препятствием для дальнейшего развития и применения Transformer в областях, требующих обработки колоссальных объемов информации, таких как анализ больших данных, обработка естественного языка и компьютерное зрение. \nabla L(w) — градиент функции потерь, становится все менее информативным по мере роста размерности пространства параметров w , что приводит к замедлению обучения и снижению качества модели.

Гамильтонова динамика как основа оптимизации
Гамильтонова механика предлагает перспективный подход к оптимизации, рассматривая процесс обучения как эволюцию системы к состоянию с минимальной энергией. В рамках этой парадигмы, параметры модели интерпретируются как обобщенные координаты, а функция потерь — как гамильтониан, определяющий энергию системы. Минимизация функции потерь эквивалентна поиску состояния с наименьшей энергией, которое достигается за счет динамики, управляемой уравнениями Гамильтона. Такой подход позволяет применять инструменты и методы, разработанные для анализа гамильтоновых систем, к задачам машинного обучения, что потенциально обеспечивает более эффективные и стабильные алгоритмы оптимизации по сравнению с традиционными методами, основанными на градиентном спуске. H(q,p) = T(p) + V(q), где q — обобщенные координаты, p — соответствующие импульсы, T — кинетическая энергия, а V — потенциальная энергия.
Интегрирование Верле — численный метод, используемый для моделирования гамильтоновых систем, который представляет собой эффективную и стабильную альтернативу методу градиентного спуска. В отличие от градиентного спуска, который напрямую использует градиенты функции потерь, Верле основан на вычислении положений и скоростей системы во времени, используя только текущие и предыдущие значения, что снижает чувствительность к шагу обучения и обеспечивает лучшую стабильность, особенно в задачах с высокой размерностью. Метод Верле не требует явного вычисления градиентов, что может значительно ускорить процесс обучения, а его симплектическая природа обеспечивает сохранение энергии системы, что способствует более плавной и предсказуемой сходимости. В частности, при решении задач оптимизации, где функция потерь может быть сложной и невыпуклой, метод Верле демонстрирует устойчивость к осцилляциям и позволяет избежать застревания в локальных минимумах.
Формулирование задачи оптимизации в рамках гамильтоновой механики позволяет получить преимущества в скорости сходимости и снижении вычислительных затрат. Традиционные методы, такие как градиентный спуск, могут страдать от колебаний и медленной сходимости, особенно в задачах с высокой размерностью или сложной поверхностью потерь. Гамильтонова формулировка, напротив, использует концепцию энергии и сохранение энергии для обеспечения более стабильной и эффективной траектории оптимизации. \frac{dq}{dt} = \frac{\partial H}{\partial p} и \frac{dp}{dt} = -\frac{\partial H}{\partial q} описывают эволюцию системы, где q и p — координаты и импульсы, а H — гамильтониан (функция энергии). Использование численных методов, таких как интеграция Верле, позволяет эффективно решать эти уравнения, обеспечивая более быстрое и надежное достижение минимума функции потерь.
YuriiFormer: Трансформер, вдохновленный гамильтоновой механикой
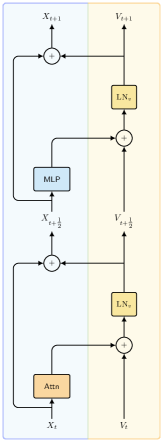
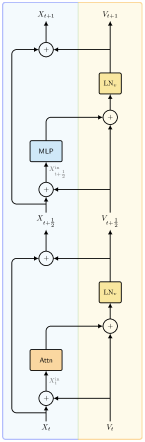
Архитектура YuriiFormer объединяет методы ускорения Нестерова и расщепления Ли-Троттера в рамках фреймворка Transformer. Ускорение Нестерова включает в себя добавление импульса к процессу оптимизации, что позволяет более эффективно ориентироваться в пространстве потерь и ускорять сходимость. Расщепление Ли-Троттера представляет собой приближение решения уравнения Шрёдингера, используемое для эффективного моделирования эволюции системы. Интеграция этих методов позволяет YuriiFormer эффективно решать задачи, требующие моделирования динамических систем и оптимизации сложных функций, сохраняя при этом преимущества архитектуры Transformer в обработке последовательностей данных.
Метод расщепления Ли-Троттера представляет собой численный подход к аппроксимации решения уравнения Шрёдингера, i\hbar \frac{\partial}{\partial t} |\psi(t)\rangle = H |\psi(t)\rangle, где H — гамильтониан системы. Этот метод позволяет разложить оператор эволюции во времени на последовательность более простых операций, что значительно снижает вычислительную сложность моделирования динамики квантовых систем. Расщепление основано на приближении, предполагающем, что операторы, составляющие гамильтониан, коммутируют или слабо взаимодействуют, позволяя разбить эволюцию во времени на отдельные шаги, моделирующие каждый оператор по отдельности. Это особенно полезно в задачах, где гамильтониан содержит сложные взаимодействия, требующие значительных вычислительных ресурсов для прямого решения уравнения Шрёдингера.
Ускорение Нестерова включает в себя добавление импульса к процессу оптимизации, что позволяет более эффективно исследовать пространство потерь и ускорить сходимость. В отличие от стандартного градиентного спуска, где обновление параметров основывается только на текущем градиенте, ускорение Нестерова вычисляет градиент в точке, куда оптимизатор предположительно переместится на следующем шаге. Это позволяет «заглянуть вперед» и скорректировать направление движения, уменьшая осцилляции и обеспечивая более стабильную сходимость к минимуму функции потерь. В частности, обновление параметров происходит по формуле v_{t+1} = \mu v_t + \eta \nabla J(x_t + \mu v_t), где μ — коэффициент момента, η — скорость обучения, v_t — текущий импульс, а J — функция потерь.
Архитектура YuriiFormer использует многослойные персептроны (MLP) и механизмы внимания для преобразования и фокусировки векторных представлений токенов (token embeddings). В основе функционирования лежат потенциальные и энергии взаимодействия, которые используются для формирования весов в MLP и механизмах внимания. Потенциальная энергия определяет базовое состояние каждого токена, а энергии взаимодействия моделируют взаимосвязи между токенами, позволяя модели эффективно улавливать контекст и зависимости. Использование MLP обеспечивает нелинейные преобразования токенов, в то время как механизмы внимания позволяют модели динамически взвешивать различные токены в зависимости от их релевантности для текущей задачи, что способствует более эффективному представлению информации.
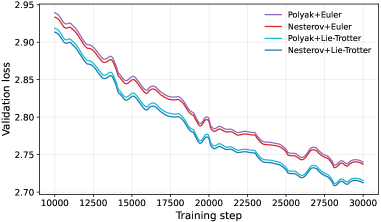
Результаты валидации и прирост производительности
Результаты валидации демонстрируют устойчивое превосходство архитектуры YuriiFormer над стандартными Transformer-моделями при выполнении ряда эталонных задач. В ходе экспериментов было установлено, что YuriiFormer демонстрирует более низкие значения потерь при валидации на различных наборах данных, что свидетельствует о его повышенной способности к обобщению и более эффективному обучению. В частности, на датасете TinyStories (12 слоёв/12 голов/768 измерений) модель достигла валидационных потерь в 2.92, а на OpenWebText (12L/12H/768d) — 2.70, что превосходит показатели GPT-2 на обоих наборах данных. Данные результаты указывают на перспективность использования вдохновлённых гамильтоновой механикой архитектур для создания более производительных и масштабируемых моделей глубокого обучения.
В ходе экспериментов модель YuriiFormer продемонстрировала превосходство над архитектурой GPT-2 в задачах оценки качества генерируемого текста. На датасете TinyStories, при конфигурации 12 слоев, 12 голов внимания и размерности 768, YuriiFormer достиг показателя валидационной ошибки в 2.92, что ниже результата, продемонстрированного GPT-2. Аналогичная тенденция наблюдалась и на датасете OpenWebText, где YuriiFormer показал валидационную ошибку в 2.70, также превзойдя показатели GPT-2. Эти результаты указывают на то, что предложенная архитектура, вдохновленная принципами гамильтоновой механики, обладает потенциалом для повышения эффективности и качества языковых моделей.
В ходе тестирования на бенчмарке HellaSwag, оценивающем способность модели к здравому смыслу и предсказанию завершения предложений, архитектура YuriiFormer продемонстрировала точность в 31,8%. Этот результат, хоть и незначительно, но превосходит показатель GPT-2, составивший 31,5%. Полученное превосходство, пусть и небольшое, подтверждает потенциал подхода, основанного на принципах гамильтоновой механики, для улучшения производительности языковых моделей в задачах, требующих понимания контекста и логических связей.
Полученные результаты указывают на то, что архитектуры, вдохновленные гамильтоновой механикой, представляют собой перспективное направление для создания более эффективных и масштабируемых моделей глубокого обучения. В отличие от традиционных подходов, использующих статичные веса, гамильтоновы нейронные сети позволяют динамически перераспределять вычислительные ресурсы, адаптируясь к сложности данных и снижая потребность в параметрах. Это, в свою очередь, потенциально ведет к ускорению обучения, уменьшению энергопотребления и возможности работы с более крупными наборами данных, что делает их привлекательной альтернативой существующим архитектурам, таким как Transformer. Дальнейшие исследования в этой области могут открыть новые горизонты в разработке интеллектуальных систем и искусственного интеллекта.
Перспективы развития: за пределами YuriiFormer
Дальнейшие исследования могут быть направлены на изучение альтернативных схем разбиения и методов интегрирования, что потенциально позволит значительно повысить эффективность оптимизации. Существующие подходы к численному решению дифференциальных уравнений, лежащих в основе модели YuriiFormer, предлагают широкий спектр возможностей для экспериментов. Например, адаптивные методы интегрирования, автоматически регулирующие шаг интегрирования в зависимости от локальных характеристик решения, могут обеспечить более точные и быстрые вычисления. Кроме того, исследование различных схем разбиения, таких как методы Рунге-Кутты или методы экстраполяции, может привести к снижению вычислительной сложности и повышению стабильности процесса обучения. Оптимизация этих аспектов позволит создавать более эффективные и масштабируемые модели глубокого обучения, способные решать сложные задачи с минимальными затратами ресурсов.
Исследования показывают, что применение принципов гамильтоновой динамики, успешно реализованное в архитектуре YuriiFormer, имеет значительный потенциал для улучшения производительности и других моделей глубокого обучения, в частности, сверточных нейронных сетей. В отличие от традиционных методов оптимизации, основанных на градиентном спуске, гамильтонова динамика предлагает подход, вдохновленный физикой, который позволяет более эффективно исследовать пространство параметров и избегать локальных минимумов. Предварительные расчеты указывают на возможность существенного снижения вычислительных затрат и повышения скорости обучения при адаптации гамильтоновых методов к сверточным архитектурам, что открывает новые перспективы для разработки более эффективных и энергоэффективных систем искусственного интеллекта. Дальнейшие исследования в этой области направлены на оптимизацию интеграции гамильтоновых методов с существующими архитектурами и адаптацию параметров динамической системы для достижения максимальной производительности.
Данная работа закладывает основу для разработки принципиально эффективных моделей глубокого обучения, вдохновленных законами физики и динамическими системами. Вместо традиционного подхода, ориентированного на эмпирическую оптимизацию, представленный метод стремится к созданию архитектур, которые по своей сути обладают высокой эффективностью за счет использования принципов, лежащих в основе физических процессов. Это означает, что модели, построенные на подобном фундаменте, потенциально могут достигать более высокой производительности при меньших вычислительных затратах. В перспективе, данный подход позволит создавать более устойчивые и обобщающие модели, способные эффективно работать в различных условиях и с разными типами данных, открывая новые горизонты в области искусственного интеллекта и машинного обучения.
Представленная работа демонстрирует подход к трансформерам не как к статичным структурам, а как к динамическим системам оптимизации. Это переосмысление позволяет применять методы численной оптимизации для совершенствования архитектуры и повышения производительности. В этом контексте, слова Алана Тьюринга приобретают особую актуальность: «Иногда люди, которые кажутся сумасшедшими, — это те, кто видит вещи, которые другие не видят». Действительно, авторы статьи, рассматривая трансформеры через призму дискретной оптимизации, открывают новые возможности для их развития, выходя за рамки традиционных представлений. Оптимизация, как показано в работе, становится не просто инструментом, а основой для создания саморазвивающихся систем, где каждый шаг приближает к более эффективному решению.
Куда Ведёт Этот Путь?
Представление трансформеров как дискретных алгоритмов оптимизации открывает не столько новые возможности, сколько обнажает глубинные ограничения. Стремление к ускорению, к «лучшему» градиентному спуску, неизбежно наталкивается на хаос, который не является сбоем, а языком природы. Любой архитектурный выбор — это пророчество о будущем отказе, замаскированное под обещанием стабильности. Гарантии, конечно, можно предложить, но это лишь договор с вероятностью, а не победа над энтропией.
Попытки «вырастить» трансформеры, а не строить их, потребуют переосмысления метрик оценки. Вместо слепого стремления к минимальному кросс-энтропии, необходимо учитывать устойчивость к возмущениям, способность к самовосстановлению и, возможно, даже способность к «эволюции» в процессе обучения. Стабильность — это иллюзия, которая хорошо кэшируется, но реальная сила кроется в адаптивности.
Дальнейшее исследование динамических систем, лежащих в основе трансформеров, вероятно, приведёт к появлению моделей, способных не просто «обучаться», но и «понимать» ограничения своей собственной архитектуры. В конечном итоге, задача не в том, чтобы создать «идеальный» трансформер, а в том, чтобы создать систему, способную существовать в условиях неопределённости и неминуемого распада.
Оригинал статьи: https://arxiv.org/pdf/2601.23236.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-03 07:36