Автор: Денис Аветисян
В статье представлен инновационный метод создания квантовых ядер, использующий вариационные группы генераторов для повышения выразительности и масштабируемости моделей машинного обучения.

Исследование предлагает новый квантовый генераторный ядро (QGK), демонстрирующий улучшенную производительность и эффективность по сравнению с существующими подходами в задачах машинного обучения.
Несмотря на теоретические преимущества квантовых методов ядра в разделении неразделимых классически признаков, практическое применение квантового машинного обучения сдерживается ограничениями текущего поколения квантового оборудования. В данной работе, посвященной ‘Quantum Generator Kernels’, предложен новый подход, использующий квантовые ядра генераторного типа и вариационные группы генераторов, для эффективного представления и обработки больших объемов данных в квантовом пространстве. Разработанная методика демонстрирует превосходство над существующими квантовыми и классическими подходами в задачах проецирования и классификации, обеспечивая масштабируемость и адаптацию к различным контекстам. Позволит ли данный подход раскрыть весь потенциал квантовых вычислений для решения сложных задач машинного обучения?
Вызов масштабируемых ядерных методов
Традиционные методы с использованием ядерных функций демонстрируют впечатляющую способность к нелинейному моделированию, позволяя выявлять сложные зависимости в данных. Однако, их применение к большим наборам данных сталкивается с существенными вычислительными трудностями. Основная проблема заключается в том, что сложность вычислений растет пропорционально квадрату числа объектов O(n^2), что делает обработку больших массивов информации крайне ресурсоемкой. В результате, несмотря на свою теоретическую мощь, классические методы с ядрами зачастую оказываются непрактичными для решения современных задач машинного обучения, требующих анализа огромных объемов данных, таких как обработка изображений, анализ текстов или геномные исследования. Это стимулирует поиск новых подходов к проектированию и реализации ядерных методов, способных эффективно масштабироваться для работы с большими данными.
Ограничения, с которыми сталкиваются традиционные методы ядерного машинного обучения при работе с большими объемами данных, существенно затрудняют их применение в сложных задачах, таких как анализ геномных данных, обработка естественного языка и компьютерное зрение. В связи с этим, активно разрабатываются новые подходы к проектированию и реализации ядерных методов. Исследования направлены на создание более эффективных алгоритмов, способных справляться с высокой вычислительной сложностью, присущей классическим ядрам. Особое внимание уделяется разработке приближенных методов, позволяющих снизить вычислительные затраты без существенной потери точности, а также созданию ядер, адаптированных к специфике конкретных задач и типов данных. Эти инновации необходимы для расширения области применения мощных, но требовательных к ресурсам, ядерных моделей.
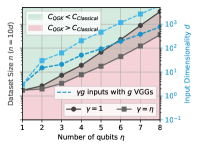
Основным препятствием для применения методов ядра к большим объемам данных является масштабирование матрицы ядра. Классические ядра демонстрируют вычислительную сложность порядка O(n^2 \cdot d), где n — количество объектов в наборе данных, а d — размерность признакового пространства. Это означает, что время вычислений и требования к памяти растут квадратично с увеличением количества данных и линейно с увеличением размерности, что делает обработку больших и высокоразмерных наборов данных крайне ресурсоемкой. В результате, даже при использовании мощных вычислительных ресурсов, применение классических ядер становится непрактичным для многих современных задач машинного обучения, требующих анализа огромных объемов информации.
Квантовый генератор ядра: новый подход
Ядро квантового генератора (QGK) использует принципы квантовых вычислений для создания высокоэкспрессивной и масштабируемой функции ядра. В отличие от классических методов, QGK оперирует с данными в квантовом пространстве, позволяя эффективно моделировать сложные нелинейные зависимости. Это достигается за счет кодирования данных в квантовое состояние и последующего вычисления скалярного произведения между этими состояниями, что определяет сходство между объектами. Преимущество QGK заключается в способности обрабатывать большие объемы данных и эффективно представлять сложные взаимосвязи, что обеспечивает повышенную точность и производительность в задачах машинного обучения.
Ядро квантового генератора (QGK) использует вариационные генераторные группы (VGG) для определения квантового отображения признаков, эффективно преобразующего входные данные в многомерное гильбертово пространство. VGG позволяют параметризовать и оптимизировать структуру этого отображения, что позволяет QGK создавать сложные, нелинейные представления данных. Данный подход обеспечивает компактное кодирование информации в высокоразмерном пространстве, что является ключевым фактором для повышения выразительности и обобщающей способности ядра. Эффективность отображения признаков, основанного на VGG, заключается в возможности адаптации к структуре данных и выделения наиболее значимых признаков для решения конкретной задачи.
Квантовое отображение признаков в QGK формируется посредством последовательностей квантовых схем, что позволяет осуществлять сложные нелинейные преобразования данных. Вычислительная сложность QGK составляет O(4η + n⋅γ⋅g² + n⋅8η + n²⋅2η), где η — сложность отдельных операций квантовой схемы, n — размерность данных, γ — параметр, определяющий сложность генерации, а g — размерность генерируемого пространства. Данная сложность демонстрирует преимущество QGK над классическими ядрами для наборов данных, размер которых превышает определенный порог, обусловленный параметрами η, γ и g.
Оптимизация квантового отображения признаков
Ключевым компонентом QGK является Линейная проекция (LinearProjection), представляющая собой преобразование входных данных в веса, определяющие параметры генератора. Данная проекция выполняет сопоставление исходных признаков с вектором параметров, используемым для построения квантового генератора. Эффективность работы QGK напрямую зависит от качества этой проекции, поскольку она определяет, насколько точно входные данные будут представлены в квантовом пространстве признаков. В процессе обучения QGK оптимизация Линейной проекции направлена на минимизацию ошибки генерации и повышение точности выполнения целевой задачи. Фактически, Линейная проекция служит мостом между классическими данными и квантовым представлением, необходимым для функционирования QGK.
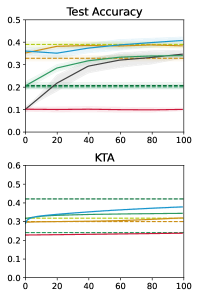
Оптимизация проекции осуществляется посредством KernelTargetAlignment, метода, направленного на согласование индуцированного ядра с конкретной задачей. Суть метода заключается в минимизации расхождения между ядром, определенным квантовой схемой, и целевым ядром, оптимальным для решения поставленной задачи классификации или регрессии. Достигается это путем корректировки параметров квантовой схемы таким образом, чтобы максимизировать соответствие между ядром и целевой функцией, что, в свою очередь, снижает обобщающую ошибку модели и повышает ее точность на новых, ранее не встречавшихся данных. Эффективность KernelTargetAlignment заключается в адаптации квантового ядра к специфике задачи, позволяя добиться лучших результатов по сравнению с использованием фиксированного ядра.
Для обеспечения точного вычисления матрицы ядра в квантовом пространстве признаков, в QGK используется метрика Верности (Fidelity). Эффективность QGK по сравнению с классическими ядрами проявляется при размере набора данных ‘n’, превышающем значение, определяемое как n > 9γ⋅4η + 8η / (3γ⋅(3γ-1)⋅4η), где γ и η представляют собой параметры, влияющие на сложность вычислений и размерность пространства признаков. Превышение этого порога позволяет QGK выполнять вычисления более эффективно, чем классические аналоги, благодаря свойствам квантовых вычислений.
![Анализ группировки VGG показывает, что использование различных масштабирований входных данных (линейное, квадратичное, экспоненциальное и полное) и ширины проекции (от узкой до широкой) влияет на способность к запутанности, измеряемую показателем Мейера-Уоллаха, и выразительность, определяемую спектральной концентрацией, при этом размер групп [15, 60, 240] оказывает влияние на стандартное отклонение, а визуализация величины и фазы полученных матриц генераторов <span class="katex-eq" data-katex-display="false"> \hat{{\bm{H}}} </span> позволяет оценить влияние ширины проекции на структуру генераторов.](https://arxiv.org/html/2602.00361v1/x16.png)
Влияние квантового шума и перспективы развития
Для успешного применения квантовой генеративной модели Кода (QGK) на существующих квантовых устройствах необходимо глубокое понимание и эффективное смягчение влияния шума. Квантовые вычисления подвержены различным источникам ошибок, которые могут значительно исказить результаты и снизить производительность модели. Изучение характеристик N<a href="https://top-mob.com/chto-takoe-stabilizator-i-dlya-chego-on-nuzhen/">ois</a>eModel — модели шума, специфичной для конкретного квантового оборудования — позволяет разработать стратегии коррекции ошибок и оптимизировать параметры QGK для повышения ее устойчивости. Особое внимание уделяется разработке методов, позволяющих минимизировать влияние декогеренции и ошибок управления, что критически важно для достижения надежных результатов на шумных промежуточных квантовых устройствах. Только путем тщательного анализа и компенсации шума можно надеяться на эффективное использование потенциала QGK в практических задачах машинного обучения.
Предварительная обработка данных с использованием классических методов значительно повышает устойчивость и эффективность квантового генеративного классификатора (QGK). Исследования показали, что применение таких техник, как нормализация и уменьшение размерности, позволяет QGK лучше справляться с шумами и нерегулярностями, характерными для реальных квантовых устройств. Это достигается за счет улучшения качества входных данных, что позволяет алгоритму более эффективно извлекать полезные признаки и строить более точные модели классификации. В результате, предварительная обработка данных не только повышает общую производительность QGK, но и способствует его более надежной работе в условиях ограниченных квантовых ресурсов, обеспечивая стабильные результаты на задачах распознавания изображений, таких как MNIST и CIFAR10.
Разработанный квантовый генеративный классификатор (QGK), в сочетании с подходом, основанным на гамильтониане, открывает новые возможности для исследования моделей квантового машинного обучения с повышенной выразительностью и масштабируемостью. Исследования демонстрируют, что QGK достигает конкурентоспособных результатов в задачах классификации изображений, обеспечивая точность в 92% на датасете MNIST и 85% на CIFAR10. При этом, важным преимуществом является эффективность модели, требующая для работы всего η ≤ 5 кубитов, что делает её перспективной для реализации на существующих и будущих квантовых устройствах.
Представленная работа демонстрирует стремление к созданию систем, способных к адаптации и развитию, а не к статической совершенности. Подход, основанный на вариационных генераторных группах, позволяет создавать квантовые ядра, которые не просто выполняют задачу, но и учатся на процессе. Это напоминает о словах Давида Гильберта: «Мы должны знать. Мы должны знать, что мы можем знать». Подобно тому, как квантовые ядра расширяют возможности представления данных, так и постоянное стремление к углублению понимания границ познания открывает новые горизонты в области машинного обучения. Вместо поиска идеального решения, работа предлагает метод, позволяющий системе эволюционировать и находить оптимальные стратегии в динамично меняющейся среде. Система, способная к самообучению и адаптации, представляется куда более жизнеспособной, чем статичная, пусть и теоретически совершенная конструкция.
Что дальше?
Представленные ядра, порожденные вариационными группами, — лишь еще одна ступень в стремлении к универсальному алгоритму. Иллюзия контроля над сложностью, возникающая при конструировании квантовых карт признаков, обманчива. Разделение системы на управляемые компоненты — не решение, а лишь отсрочка неизбежного. Всё связанное когда-нибудь упадёт синхронно, и новые ядра, как и все предыдущие, не избегнут этой участи.
Истинный вызов заключается не в создании более выразительных карт, а в понимании пределов выразительности вообще. Настоящая проблема — не масштабируемость, а растущая зависимость от всё более хрупких предположений о природе данных. Каждый архитектурный выбор — это пророчество о будущем сбое, замаскированное под инженерное решение.
Дальнейшие исследования, вероятно, сосредоточатся на автоматизации процесса конструирования ядер, но это лишь усложнит экосистему, не уменьшив её энтропию. Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить, и даже тогда они неизбежно эволюционируют в непредсказуемом направлении. В конечном итоге, речь идет не о квантовых ядрах, а о природе самой сложности.
Оригинал статьи: https://arxiv.org/pdf/2602.00361.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-03 11:13