Автор: Денис Аветисян
Новое исследование показывает, что современные детекторы изображений, созданных нейросетями, часто полагаются на легко устранимые артефакты, а не на выявление реальных манипуляций.
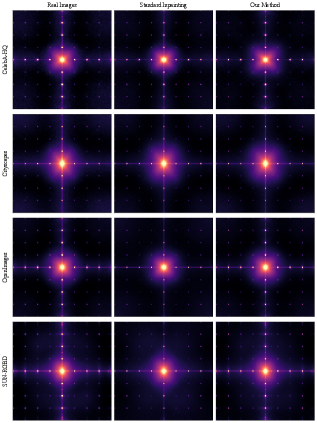
Анализ метода Inpainting Exchange (INP-X) демонстрирует уязвимость детекторов к глобальным артефактам, возникающим при использовании вариационных автоэнкодеров (VAE) в диффузионных моделях.
Современные детекторы, призванные выявлять изображения, сгенерированные искусственным интеллектом, зачастую демонстрируют уязвимость к незначительным изменениям. В работе «AI-Generated Image Detectors Overrely on Global Artifacts: Evidence from Inpainting Exchange» исследователи показали, что эти детекторы полагаются на глобальные артефакты, возникающие в процессе восстановления изображений, а не на фактические изменения в контенте. Предложенный метод Inpainting Exchange (INP-X) позволяет выявить эту зависимость, восстанавливая исходные пиксели за пределами отредактированной области, и приводит к резкому снижению точности детекторов — вплоть до случайного угадывания. Не является ли это сигналом о необходимости разработки детекторов, способных анализировать контент изображения, а не полагаться на легко устранимые глобальные признаки?
Искусство восстановления: вызовы и перспективы генеративных моделей
Современные генеративные модели, особенно диффузионные модели, работающие в латентном пространстве, совершили революцию в области создания изображений и, в частности, в задаче восстановления поврежденных областей — инпейнтинга. В отличие от предыдущих методов, которые часто приводили к заметным артефактам и несогласованности, эти модели способны генерировать правдоподобные и реалистичные детали, органично вписывающиеся в исходное изображение. Они достигают этого, постепенно добавляя шум к изображению, а затем обучаясь обращать этот процесс, генерируя новые пиксели на основе контекста окружающей области. В результате, даже сложные сцены с богатой текстурой и освещением могут быть восстановлены с удивительной точностью, открывая новые возможности для редактирования фотографий, реставрации старых изображений и создания визуальных эффектов.
Несмотря на значительный прогресс в области генеративных моделей, таких как диффузионные, в областях, подвергшихся восстановлению — так называемом “inpaint” — зачастую сохраняются едва заметные артефакты. Эти дефекты, хоть и не всегда бросаются в глаза при беглом взгляде, могут свидетельствовать об искусственном происхождении изображения, вызывая обоснованные опасения относительно его подлинности. Исследования показывают, что даже незначительные несоответствия в текстуре или освещении могут быть обнаружены специализированными алгоритмами, а также опытными экспертами, что ставит под вопрос доверие к контенту, полученному с помощью технологий восстановления. Подобные нюансы особенно критичны в сферах, где достоверность изображения имеет первостепенное значение, например, в журналистике, криминалистике и архивном деле.
Традиционные методы восстановления изображений, известные как inpainting, часто сталкиваются с трудностями при работе со сложными сценами. В отличие от современных подходов, основанных на диффузионных моделях, они испытывают проблемы с поддержанием глобальной согласованности изображения. Это приводит к заметным искажениям в восстановленных областях, особенно когда необходимо заполнить большие пропуски или восстановить детали на фоне сложного текстурного рисунка. Восстановленные фрагменты могут казаться оторванными от остальной части изображения, нарушая визуальную целостность и создавая неестественные артефакты. Неспособность учитывать общую структуру и семантику сцены приводит к тому, что восстановленные области кажутся нелогичными или несоответствующими контексту, что снижает реалистичность и достоверность изображения.

Распознавание искусственного интеллекта: многогранный подход
Обнаружение изображений, сгенерированных искусственным интеллектом, основывается на выявлении статистических аномалий и несоответствий, возникающих в процессе работы генеративных моделей. Эти модели, такие как GAN и диффузионные модели, обучаются на больших наборах данных и, в процессе генерации нового контента, могут вносить специфические артефакты и паттерны, отличающиеся от тех, что характерны для реальных изображений. Анализ статистических характеристик пикселей, частотных спектров и других параметров позволяет выявить эти отклонения. Например, сгенерированные изображения могут демонстрировать более низкое разнообразие текстур или неестественные корреляции между пикселями, что служит индикатором искусственного происхождения. Выявление подобных статистических несоответствий является ключевым принципом в современных методах обнаружения сгенерированных изображений.
Для дифференциации между реальными и синтезированными изображениями критически важны методы анализа расхождения Кульбака-Лейблера (KL Divergence) и применение сверточных нейронных сетей (CNN) и Vision Transformers (ViT). Анализ KL Divergence позволяет выявлять статистические аномалии в распределении пикселей и признаков, характерные для генеративных моделей. CNN и ViT, обученные на больших наборах данных, способны извлекать сложные признаки и паттерны, позволяющие идентифицировать артефакты, типичные для сгенерированных изображений, такие как нереалистичные текстуры или структурные несоответствия. Эффективность этих методов повышается при использовании ансамблей моделей и применении техник аугментации данных.
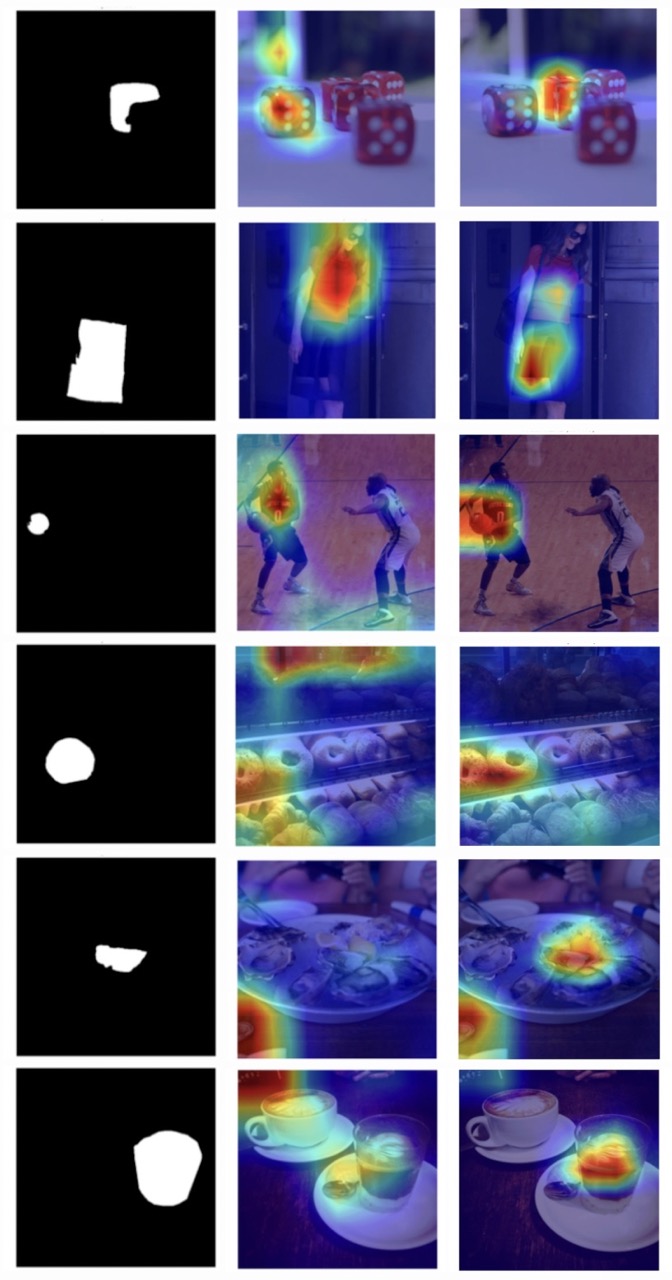
Методы визуализации, такие как Grad-CAM (Gradient-weighted Class Activation Mapping) и Attention Rollout, позволяют определить области изображения, наиболее сильно указывающие на признаки искусственной генерации. Grad-CAM выявляет регионы, которые наиболее влияют на решение модели классификации, выделяя их на основе градиентов. Attention Rollout, в свою очередь, последовательно агрегирует карты внимания из различных слоев нейронной сети, чтобы визуализировать, какие части изображения привлекают наибольшее внимание модели в процессе принятия решения. Анализ полученных тепловых карт позволяет экспертам и алгоритмам точно локализовать аномалии и несоответствия, характерные для изображений, созданных генеративными моделями, и тем самым повысить точность обнаружения подделок.
Понимание и смягчение артефактов: спектральный сдвиг и за его пределами
Артефакты, возникающие в сгенерированных изображениях, часто проявляются в виде спектральных сдвигов и ослабления высокочастотных составляющих. Эти искажения являются следствием процесса кодирования и декодирования, используемого в вариационных автоэнкодерах (VAE). В процессе кодирования изображение сжимается в латентное пространство, что неизбежно приводит к потере информации, особенно в высокочастотном диапазоне. При декодировании, реконструкция изображения из латентного представления может приводить к смещению спектральных характеристик, что проявляется как изменения в распределении частот и ослабление деталей. Данные артефакты являются структурными особенностями, присущими изображениям, сгенерированным с использованием VAE, и могут быть использованы для идентификации искусственно созданного контента.
Преобразования Вейвлета (Wavelet Transforms) представляют собой эффективный инструмент для выявления тонких частотных искажений, возникающих в сгенерированных изображениях. В отличие от стандартного преобразования Фурье, вейвлет-анализ позволяет локализовать частотные компоненты во времени и пространстве, что критически важно для обнаружения артефактов, вызванных процессами кодирования и декодирования в вариационных автоэнкодерах (VAE). Количественная оценка этих искажений достигается путем анализа коэффициентов вейвлет-преобразования, позволяя выявлять отклонения от естественного спектра и предоставляя объективное доказательство манипуляций с изображением. Применение вейвлет-анализа позволяет выявить даже незначительные изменения в высокочастотных компонентах, которые могут быть невидимы при визуальном осмотре.
Анализ потерь VAE (Variational Autoencoder) и высокочастотного контента изображений, сгенерированных моделями SDXL и FLUX.1, выявил высокую корреляцию — 0.9374 и 0.9362 соответственно. Данный показатель демонстрирует, что генеративные модели активно используют спектральные артефакты, связанные с потерей высокочастотных деталей, в процессе создания изображений. По сути, снижение потерь VAE напрямую связано с сохранением или намеренным внесением определенных частотных искажений, что указывает на фундаментальную зависимость этих моделей от манипулирования спектральными характеристиками для достижения результатов генерации.
Набор данных Semi-Truths представляет собой эталонный набор для оценки эффективности методов обнаружения манипуляций, выполненных с использованием современных генеративных моделей. Он содержит изображения, созданные с применением усовершенствованных техник, таких как вариационные автоэнкодеры (VAE), и предназначен для тестирования способности алгоритмов выявлять тонкие спектральные искажения и другие артефакты, возникающие в процессе генерации. Набор данных позволяет количественно оценить производительность различных детекторов и сравнить их устойчивость к изображениям, созданным с использованием новейших генеративных моделей, обеспечивая объективную метрику для оценки прогресса в области выявления подделок.

Inpainting Exchange: новый подход к снижению артефактов
Метод Inpainting Exchange (INP-X) представляет собой подход к восстановлению исходных пикселей за пределами отредактированной области изображения. В отличие от традиционных методов, которые часто приводят к глобальным артефактам, INP-X нацелен на минимизацию этих искажений путем прямого восстановления информации, присутствовавшей в оригинальном изображении до внесения изменений. Этот процесс направлен на снижение визуальных несоответствий и улучшение общей реалистичности отредактированного изображения за счет более точного воссоздания исходной структуры пикселей вне области редактирования.
Метод Inpainting Exchange (INP-X) ставит под сомнение распространенное предположение о неизбежности артефактов при генеративном редактировании изображений. Традиционно, артефакты рассматривались как побочный эффект, присущий самим генеративным процессам. Однако, INP-X, напрямую воздействуя на источники искажений путем восстановления исходных пикселей за пределами отредактированной области, демонстрирует возможность значительного снижения или даже устранения этих артефактов. Этот подход предполагает, что многие наблюдаемые искажения не являются фундаментальной характеристикой генерации, а результатом конкретных методов обработки и восстановления данных, которые можно оптимизировать.
Метод Inpainting Exchange (INP-X) показал значительное снижение эффективности алгоритмов обнаружения манипуляций. В ходе тестирования точность коммерческих API для обнаружения подделок снизилась с более чем 91% до 55%. Аналогично, точность наиболее эффективного детектора с открытым исходным кодом, DNF, упала до 0.604. Эти результаты демонстрируют, что INP-X способен эффективно вносить изменения в изображение, затрудняющие его аутентификацию с использованием существующих методов обнаружения.
При использовании метода Inpainting Exchange (INP-X) наблюдается значительное снижение производительности детекторов изображений, основанных на сверточных нейронных сетях (CNN). Модели EfficientNet и ResNet-50 достигают среднего значения IoU (mIoU) в диапазоне 0.45-0.49 при анализе изображений, обработанных с помощью INP-X. Детекторы, основанные на архитектуре Vision Transformer (ViT), демонстрируют еще более низкие показатели, с mIoU в диапазоне 0.37-0.41. Данные результаты свидетельствуют о том, что INP-X эффективно снижает способность детекторов точно идентифицировать манипулированные области изображения.
Метод Inpainting Exchange (INP-X) демонстрирует возможность снижения ожидаемых спектральных сдвигов и глобальных артефактов, возникающих при редактировании изображений. Традиционно, манипуляции с изображениями неизбежно приводят к изменениям в спектральном составе и появлению глобальных искажений, которые могут быть обнаружены детекторами. INP-X, восстанавливая исходные пиксели за пределами отредактированной области, эффективно противодействует этим эффектам, что позволяет создавать более реалистичные изображения. Экспериментальные данные показывают, что INP-X значительно снижает точность работы коммерческих и открытых API обнаружения манипуляций, указывая на снижение видимости изменений, внесенных в изображение.
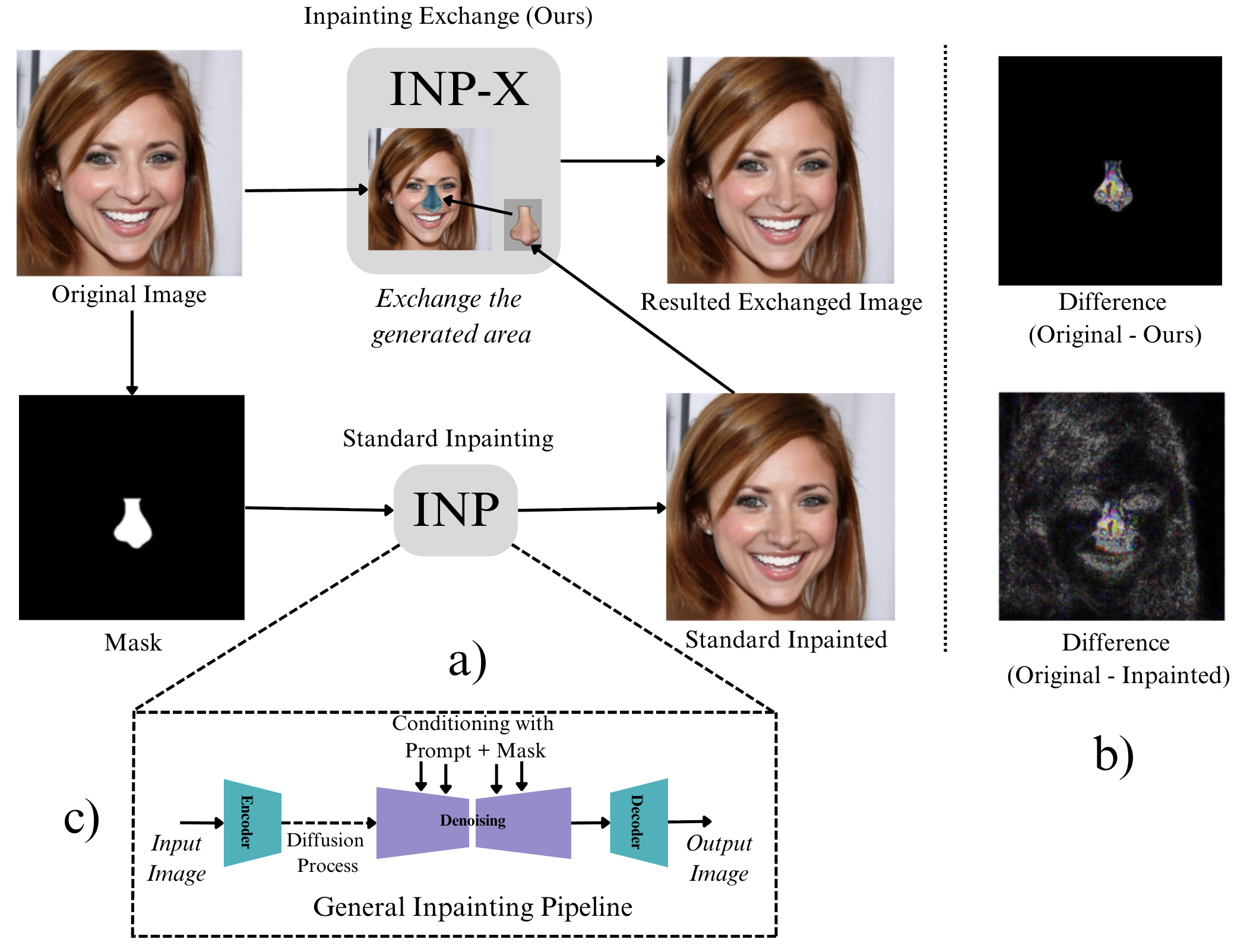
Исследование демонстрирует, что современные детекторы, определяющие искусственно сгенерированные изображения, часто полагаются на легко устранимые глобальные артефакты, возникающие в процессе диффузионной реставрации, вместо того, чтобы выявлять реальные манипуляции с контентом. Это напоминает о важности глубокого понимания внутренних механизмов систем, а не поверхностной оценки результатов. Как заметил Эндрю Ын: «Искусственный интеллект — это не только создание умных алгоритмов, но и понимание ограничений этих алгоритмов». Данная работа, предлагая метод INP-X для выявления этой уязвимости, подчеркивает, что красота масштабируется, беспорядок нет — и это справедливо как для кода, так и для систем обнаружения подделок. Поверхностный анализ, основанный на видимых дефектах, не выдержит испытания временем и новыми технологиями.
Куда Ведет Этот Путь?
Представленное исследование обнажает тревожную тенденцию: современная автоматизированная детекция изображений, сгенерированных искусственным интеллектом, зачастую фокусируется не на сущностных признаках манипуляции, а на легко устранимых глобальных артефактах, привнесенных компонентом VAE в процессе диффузионной заливки. Это напоминает попытку оценить произведение искусства по качеству холста, а не по замыслу художника. Изящество алгоритма должно заключаться в понимании сути, а не в эксплуатации побочных эффектов.
Методика INP-X, предложенная в данной работе, служит скорее диагнозом, чем лекарством. Она демонстрирует уязвимость, но не устраняет ее. Будущие исследования должны быть направлены на разработку детекторов, устойчивых к манипуляциям с артефактами, способных оценивать семантическую согласованность и правдоподобность изображения на более глубоком уровне. Необходимо перейти от поиска «следов» к пониманию «смысла».
По-настоящему элегантное решение потребует не только совершенствования алгоритмов, но и переосмысления самой задачи. Возможно, вместо того чтобы пытаться «вычислить» искусственность, следует сосредоточиться на оценке степени соответствия изображения законам физики и визуального восприятия. В конечном итоге, красота в коде проявляется через простоту и ясность, а истинное понимание — через способность видеть за формой суть.
Оригинал статьи: https://arxiv.org/pdf/2602.00192.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Квантовый скачок в обработке радиоастрономических данных
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
2026-02-03 14:12