Автор: Денис Аветисян
Новое исследование показывает, что высокая производительность языковой модели при стандартном обучении не гарантирует успеха при дальнейшем обучении с подкреплением, и предлагает метод решения проблемы несоответствия данных.
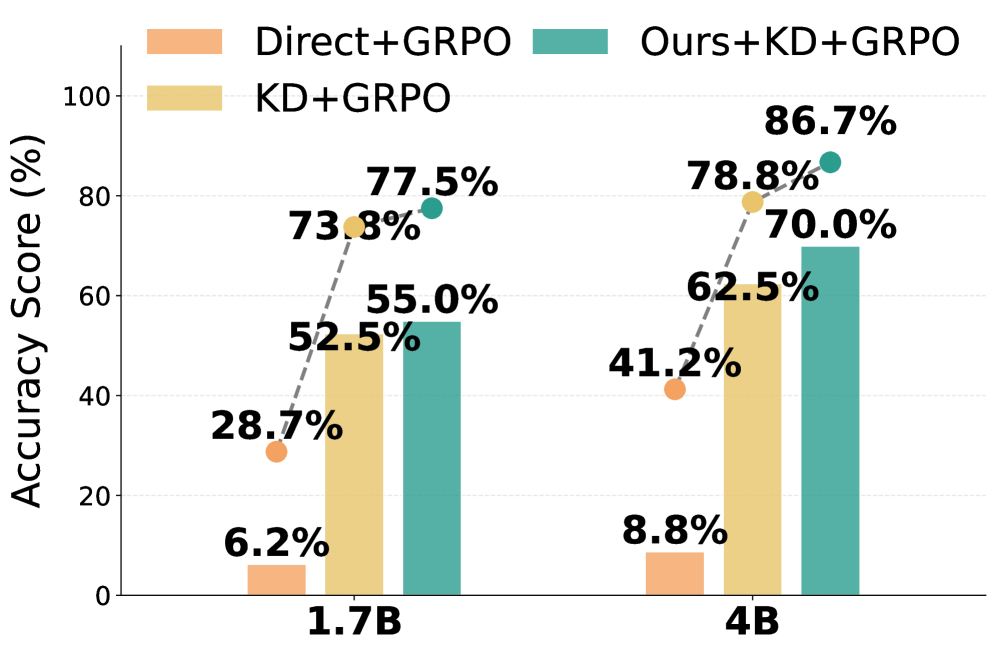
Предложена методика PEAR для коррекции расхождения между данными офлайн-обучения и онлайн-обучения с подкреплением, что приводит к повышению итоговой производительности.
Не всегда сильные показатели языковой модели на этапе предварительной дообучения (SFT) гарантируют успех после обучения с подкреплением. В работе ‘Good SFT Optimizes for SFT, Better SFT Prepares for Reinforcement Learning’ показано, что расхождение в распределении данных между этапами SFT и обучения с подкреплением может приводить к снижению итоговой производительности. Авторы предлагают алгоритм PEAR, перевешивающий потери на этапе SFT с использованием важностной выборки для корректировки этого расхождения и улучшения подготовки модели к обучению с подкреплением. Способствует ли учет особенностей последующего обучения с подкреплением уже на этапе SFT созданию более эффективных и универсальных языковых моделей?
Инициализация Разума: Основа Автономного Обучения с Подкреплением
Современные языковые модели, несмотря на впечатляющие возможности в обработке информации, зачастую демонстрируют трудности при решении задач, требующих многоступенчатого логического мышления. Их способность к последовательному анализу и построению аргументации, особенно в сложных сценариях, остается ограниченной. Это связано с тем, что обучение таких моделей преимущественно ведется на больших объемах текстовых данных, где акцент делается на статистические закономерности, а не на логическую структуру и причинно-следственные связи. В результате, модели могут генерировать грамматически корректные и контекстуально уместные тексты, но испытывают затруднения при решении проблем, требующих глубокого анализа, планирования и дедуктивных рассуждений. Неспособность к эффективному многошаговому мышлению ограничивает их применение в сферах, где критически важна способность к логическому выводу и решению сложных задач.
Обучение с учителем в автономном режиме (Offline SFT) играет ключевую роль в наделении языковых моделей способностью к рассуждениям. В отличие от традиционных методов, требующих интерактивного взаимодействия, Offline SFT использует существующие наборы данных, содержащие примеры логических цепочек и решений. Этот подход позволяет модели усвоить паттерны мышления и применять их к новым задачам, не нуждаясь в постоянной обратной связи. По сути, Offline SFT формирует фундамент для сложных когнитивных процессов, позволяя модели «научиться думать», прежде чем столкнуться с неизвестными ситуациями, значительно повышая её эффективность в решении задач, требующих многоступенчатых рассуждений и логического анализа.
Эффективность обучения с учителем в автономном режиме (Offline SFT) напрямую зависит от качества данных, используемых для обучения. Эти данные, генерируемые так называемой «политикой поведения» (Behavior Policy), определяют начальную траекторию рассуждений модели. Политика поведения, по сути, задает стратегию, по которой генерируются примеры решения задач, и именно эта стратегия формирует основу для последующего обучения. Если данные, сгенерированные политикой поведения, содержат ошибки, неполны или не отражают разнообразие возможных сценариев, модель не сможет эффективно освоить сложные навыки рассуждения. Таким образом, тщательный подбор и оптимизация политики поведения являются критически важными для успешной инициализации модели и обеспечения ее способности к логическому мышлению и решению задач.
В процессе обучения с помощью Offline Supervised Fine-Tuning (Offline SFT) функция Negative Log Likelihood (NLL) играет ключевую роль в корректировке начальных параметров языковой модели. NLL представляет собой меру того, насколько вероятно, что модель предскажет правильную последовательность действий, основанную на данных, полученных от Behavior Policy. По сути, эта функция оценивает разницу между предсказанным распределением вероятностей и фактическим распределением в обучающем наборе. Минимизируя NLL, алгоритм постепенно настраивает параметры модели, чтобы повысить вероятность генерации правильных ответов и улучшить способность к многоступенчатому рассуждению. Таким образом, функция потерь NLL служит компасом, направляющим процесс обучения и позволяющим модели усваивать сложные логические связи из предоставленных данных.
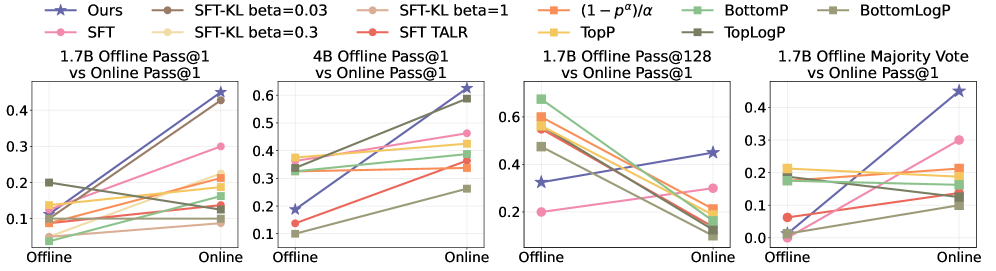
Устранение Расхождений: Преодоление Несоответствия Распределений
Расхождение в распределениях (Distribution Mismatch) возникает, когда политика поведения (Behavior Policy), использованная для сбора данных в офлайн-режиме, отличается от целевой политики (Target Policy), оптимизируемой в процессе обучения. Данное расхождение обусловлено тем, что данные, собранные политикой поведения, отражают ее специфические стратегии принятия решений, в то время как целевая политика может преследовать иные цели или использовать отличные подходы. В результате, модель может обучаться на данных, которые нерепрезентативны для желаемого поведения, что приводит к снижению эффективности и обобщающей способности. Величиной этого расхождения является разница между вероятностями действий, выбранных каждой из политик, при одинаковых состояниях.
Несоответствие между распределением данных, собранных поведенческой политикой, и распределением, используемым целевой политикой в процессе обучения, приводит к неточным оценкам градиента. Данная неточность возникает из-за того, что целевая политика экстраполирует за пределы области, покрытой обучающими данными, что приводит к смещенным оценкам качества действий. В результате модель испытывает затруднения при освоении сложных навыков рассуждения, поскольку процесс обучения основан на неверных сигналах, что снижает эффективность оптимизации и ограничивает способность модели обобщать полученные знания на новые ситуации. Проблема усугубляется в задачах, требующих долгосрочного планирования и принятия решений, где даже небольшие погрешности в оценке градиента могут накапливаться и приводить к значительному ухудшению производительности.
Метод PEAR решает проблему расхождения между распределениями данных, полученных по поведеческой политике и используемых при оптимизации целевой политики, посредством перевзвешивания выборок. В основе этого подхода лежит оценка правдоподобия каждой выборки под обеими политиками, а ключевым метрическим показателем является отношение правдоподобия суффикса (Suffix Likelihood Ratio) \frac{\pi_{\theta}(a|s)}{\pi_{\theta}(a|s)} . Перевзвешивание позволяет скорректировать вклад каждой выборки в процесс обучения, снижая смещение, вызванное различием в распределениях и обеспечивая более точную оценку градиента.
Метод PEAR улучшает начальную инициализацию модели за счет снижения расхождения между распределениями данных, собранных поведенческой политикой, и целевой политикой, оптимизируемой в процессе обучения. Это достигается путем перевзвешивания выборок на основе их вероятности в рамках обеих политик, что позволяет получить более точные оценки градиента и повысить эффективность обучения сложным навыкам рассуждения. Улучшенная инициализация, полученная с помощью PEAR, значительно повышает производительность последующего онлайн-обучения с подкреплением, позволяя агенту быстрее адаптироваться и достигать оптимальной политики в реальной среде.

Уточнение Рассуждений: Онлайн-Обучение с Подкреплением и Контроль Разреженности
Для дальнейшей тренировки модели используется обучение с подкреплением в режиме реального времени (Online RL). Этот подход предполагает взаимодействие модели с окружающей средой, где она получает обратную связь за свои действия и корректирует стратегию рассуждений. В процессе обучения модель самостоятельно исследует пространство решений, адаптируясь к различным сценариям и улучшая свои навыки решения задач. В отличие от обучения на статичном наборе данных, Online RL позволяет модели непрерывно совершенствоваться, основываясь на опыте, полученном в процессе взаимодействия со средой.
Контроль разреженности (sparsity) обновлений параметров во время онлайн-обучения с подкреплением (Online RL) является критически важным. Высокая разреженность обновлений указывает на то, что лишь небольшая часть параметров модели изменяется на каждом шаге обучения. Это может свидетельствовать о чрезмерно консервативном процессе обучения, когда модель избегает значительных изменений, даже если они необходимы для улучшения производительности. В результате, прогресс в обучении замедляется, и модель может не достичь оптимального уровня производительности. Мониторинг разреженности позволяет выявить и скорректировать параметры обучения, чтобы обеспечить более эффективное и прогрессивное обучение модели.
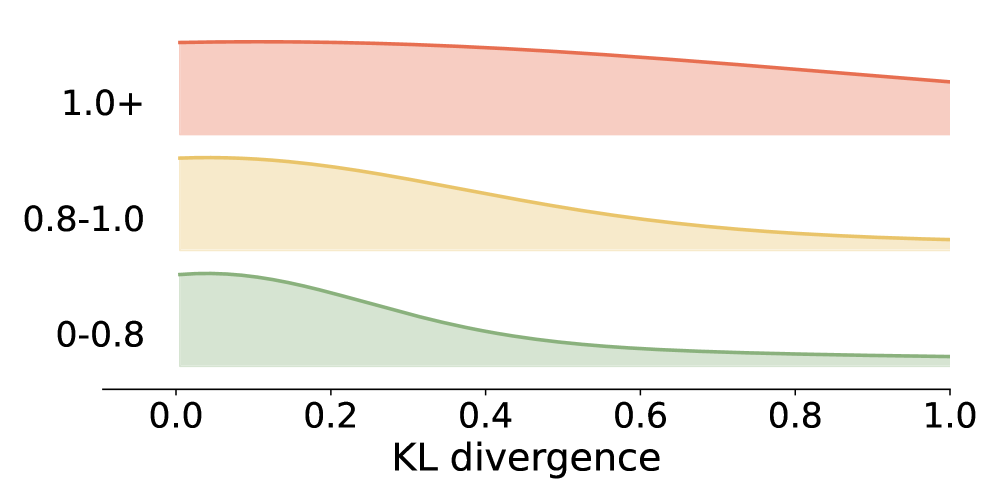
В процессе обучения с подкреплением (Online RL) расхождение Кульбака-Лейблера (KL Divergence) используется в качестве регуляризатора для ограничения отклонения целевой политики от исходной, инициализированной политики. KL(P||Q) измеряет разницу между двумя распределениями вероятностей, P и Q, и в данном контексте штрафует целевую политику за слишком значительное изменение поведения по сравнению с начальным состоянием. Это позволяет предотвратить нестабильность обучения и сохранить полезные знания, полученные на этапе предварительного обучения, обеспечивая более плавный и контролируемый процесс адаптации модели к новой среде.
Оценка эффективности предложенного подхода, сочетающего онлайн обучение с подкреплением и разреженность параметров, проводилась на эталонных наборах данных AIME Benchmarks с использованием метрики Pass@K. Результаты показали прирост в 14.6% по метрике Pass@8 на наборе AIME-2025, что демонстрирует существенное улучшение способности модели к решению задач по сравнению с исходным состоянием. Данный показатель отражает вероятность успешного решения задачи хотя бы в одном из K попыток, и его увеличение подтверждает эффективность предложенных методов обучения.
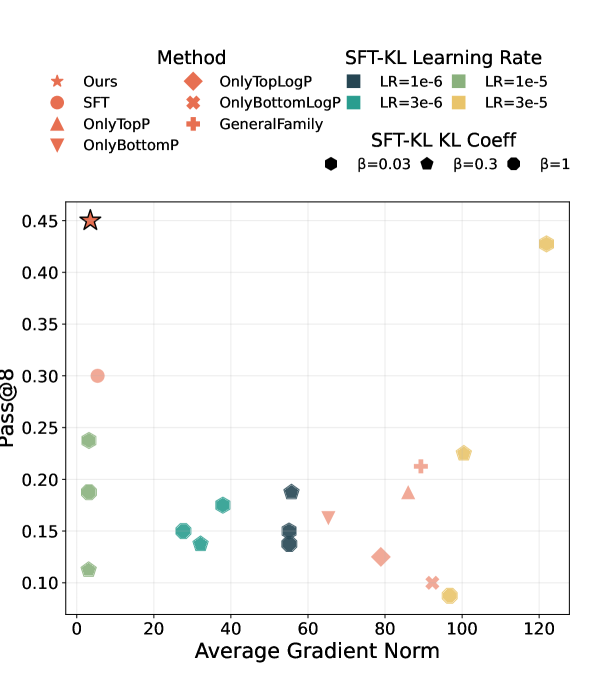
Адаптивное Обучение: Перевзвешивание Потерь на Основе Токенов
Для решения проблемы неравномерной сложности токенов в процессе обучения, разработан метод динамической перевзвешивания потерь — Token-Adaptive Loss Reweighting. В рамках Offline SFT (Supervised Fine-Tuning) этот подход позволяет корректировать веса потерь в реальном времени, уделяя больше внимания тем токенам, которые представляют наибольшую сложность для модели. Благодаря этому, обучение становится более эффективным, поскольку модель фокусируется на тех аспектах, где требуется наибольшая оптимизация. Динамическая корректировка весов позволяет не только улучшить общую производительность, но и повысить способность модели к рассуждениям и решению сложных задач, обеспечивая более глубокое понимание и обработку информации.
Адаптивное перевзвешивание потерь, основанное на токенах, существенно повышает эффективность обучения за счет динамической концентрации на наиболее сложных элементах входных данных. Этот подход позволяет модели более эффективно усваивать информацию, поскольку большая часть вычислительных ресурсов направляется на те токены, которые представляют наибольшую трудность для прогнозирования. В результате, модель улучшает свои способности к рассуждению и решению сложных задач, поскольку она вынуждена более тщательно анализировать и понимать сложные связи между токенами. Такая фокусировка на сложных элементах позволяет достичь более высокого уровня понимания и генерации текста, что особенно важно для задач, требующих глубокого логического анализа и вывода.
Для обеспечения стабильности процесса тонкой настройки модели используется метод контроля расхождения на основе дивергенции Кульбака-Лейблера (KL-дивергенции). Данный подход позволяет отслеживать степень отличия между базовой моделью и моделью, подвергающейся тонкой настройке, предотвращая чрезмерное отклонение от исходных знаний. KL(P||Q) измеряет информационную потерю при использовании распределения Q для аппроксимации распределения P. В данном контексте, мониторинг KL-дивергенции позволяет вовремя корректировать процесс обучения, предотвращая «забывание» базовой моделью ранее усвоенных знаний и обеспечивая более плавную и стабильную адаптацию к новым данным, что критически важно для поддержания обобщающей способности и избежания переобучения.
Исследования показали, что применение данного метода в сочетании с обучением с подкреплением в режиме реального времени значительно повышает эффективность модели, что было подтверждено на платформе SynLogic Games. В ходе экспериментов зафиксировано устойчивое превосходство над базовыми подходами по метрике Pass@1, указывающей на способность модели успешно решать логические задачи с первой попытки. Данное улучшение демонстрирует, что динамическая переоценка потерь и адаптивное обучение позволяют модели более эффективно усваивать сложные закономерности и демонстрировать повышенную надежность в решении задач, требующих логического мышления и рассуждений.
Исследование демонстрирует, что высокая производительность языковой модели в режиме офлайн-обучения не гарантирует успешной адаптации к обучению с подкреплением. Это напоминает о сложности предсказания поведения развивающейся системы. Поль Эрдеш однажды сказал: «Математика — это не просто набор фактов, это способ думать». Аналогично, сильная офлайн-производительность — это лишь один аспект, который необходимо учитывать при построении устойчивой системы обучения с подкреплением. Предложенный авторами метод PEAR направлен на смягчение расхождения между данными офлайн-обучения и онлайн-обучением, что позволяет модели более эффективно адаптироваться к новым условиям. Этот подход подчёркивает, что система — это не статичная структура, а динамично развивающийся сад, требующий постоянного ухода и адаптации.
Что же дальше?
Представленная работа демонстрирует, что сила языковой модели в статичном, оффлайн режиме не гарантирует успеха в динамичном взаимодействии с обучением с подкреплением. Это не открытие, конечно. Скорее, это очередное подтверждение: масштабируемость — всего лишь слово, которым мы оправдываем сложность. Стремление к “сильному” оффлайн-перформансу — это попытка построить крепость на зыбучих песках, игнорируя неизбежное расхождение между данными, на которых модель обучалась, и реальностью, с которой она столкнется.
Метод PEAR, предложенный авторами, — это лишь попытка смягчить эту расходимость, исправить прогностическую ошибку. Но идеальная архитектура — это миф, нужный нам, чтобы не сойти с ума. Вместо поиска “идеального” решения, возможно, стоит сосредоточиться на создании систем, способных к самокоррекции, к адаптации к новым данным, к признанию собственной неполноты. Всё, что оптимизировано, однажды потеряет гибкость.
Будущие исследования, вероятно, будут направлены не на повышение “абсолютной” производительности, а на повышение робастности и адаптивности языковых моделей. Системы — это не инструменты, а экосистемы. Их нельзя построить, только вырастить. Задача — не создать совершенный интеллект, а создать среду, в которой интеллект может эволюционировать.
Оригинал статьи: https://arxiv.org/pdf/2602.01058.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Квантовый скачок в обработке радиоастрономических данных
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
2026-02-03 15:56