Автор: Денис Аветисян
Новое исследование предлагает метод диагностики надежности больших языковых моделей в роли оценщиков, отделяя внутреннюю согласованность от соответствия человеческим суждениям.
В статье представлен фреймворк на основе теории отклика на задачу для диагностики надежности больших языковых моделей, выступающих в качестве оценщиков, с применением модели градированного отклика и анализом метрик оценки.
Несмотря на широкое распространение автоматизированной оценки с использованием больших языковых моделей (LLM), валидация их надежности часто ограничивается анализом наблюдаемых результатов, не раскрывая стабильность самих моделей как измерительных инструментов. В статье ‘Diagnosing the Reliability of LLM-as-a-Judge via Item Response Theory’ предложен двухфазный диагностический фреймворк, основанный на теории отклика на задачу (IRT), для оценки надежности LLM-судей. Предложенный подход, использующий модель градиентного отклика (GRM) IRT, позволяет формализовать надежность через две взаимодополняющие характеристики: внутреннюю согласованность и соответствие человеческим оценкам. Позволит ли данный подход выявить систематические причины ненадежности LLM-судей и повысить качество автоматизированной оценки?
Автоматизированная Оценка LLM: Вызовы и Перспективы
В связи с растущей зависимостью от больших языковых моделей (LLM), возникла острая необходимость в автоматизированных методах оценки их производительности. Однако существующие эталонные тесты и метрики зачастую оказываются неспособными адекватно отразить сложные аспекты качества генерируемого текста, такие как креативность, логическая связность и соответствие контексту. Традиционные показатели, фокусирующиеся на поверхностных характеристиках, не всегда коррелируют с восприятием качества человеком, что приводит к несоответствиям между автоматической оценкой и реальной полезностью модели. В результате, возникает потребность в разработке более изощренных и всесторонних систем оценки, способных улавливать тонкие нюансы и обеспечивать более точное представление о возможностях и ограничениях LLM.
Традиционная оценка качества работы больших языковых моделей (LLM) при помощи людей представляет собой значительное препятствие для быстрого прогресса в этой области. Процесс, требующий квалифицированных лингвистов и экспертов, не только обходится весьма дорого, но и занимает продолжительное время. Каждый этап — от подготовки тестовых примеров до анализа полученных ответов — требует значительных трудозатрат, что существенно замедляет циклы разработки и внедрения новых моделей. Этот «узкое место» в процессе оценки ограничивает возможности исследователей и разработчиков быстро и эффективно совершенствовать LLM, а также препятствует оперативному развертыванию этих технологий для решения реальных задач. Подобная неэффективность подталкивает к поиску альтернативных, автоматизированных методов оценки, способных обеспечить более быструю и экономичную проверку качества.
В связи с растущей потребностью в автоматизированной оценке больших языковых моделей (LLM), всё более актуальным становится использование самих LLM в качестве судей. Этот подход позволяет значительно ускорить процесс оценки и снизить затраты, связанные с традиционной ручной экспертизой. Однако, применение LLM для оценки других LLM поднимает важные вопросы о надёжности и соответствии этим моделям человеческих предпочтений. Существует риск, что LLM-судья будет предвзято оценивать ответы, основываясь на собственных особенностях обучения и внутренних критериях, а не на реальном качестве и полезности информации для человека. В связи с этим, ведутся активные исследования, направленные на разработку методов калибровки и выравнивания LLM-судей, чтобы обеспечить их объективность и соответствие ожиданиям пользователей.
Согласованность с Человеческими Суждениями: Измерение Выравнивания
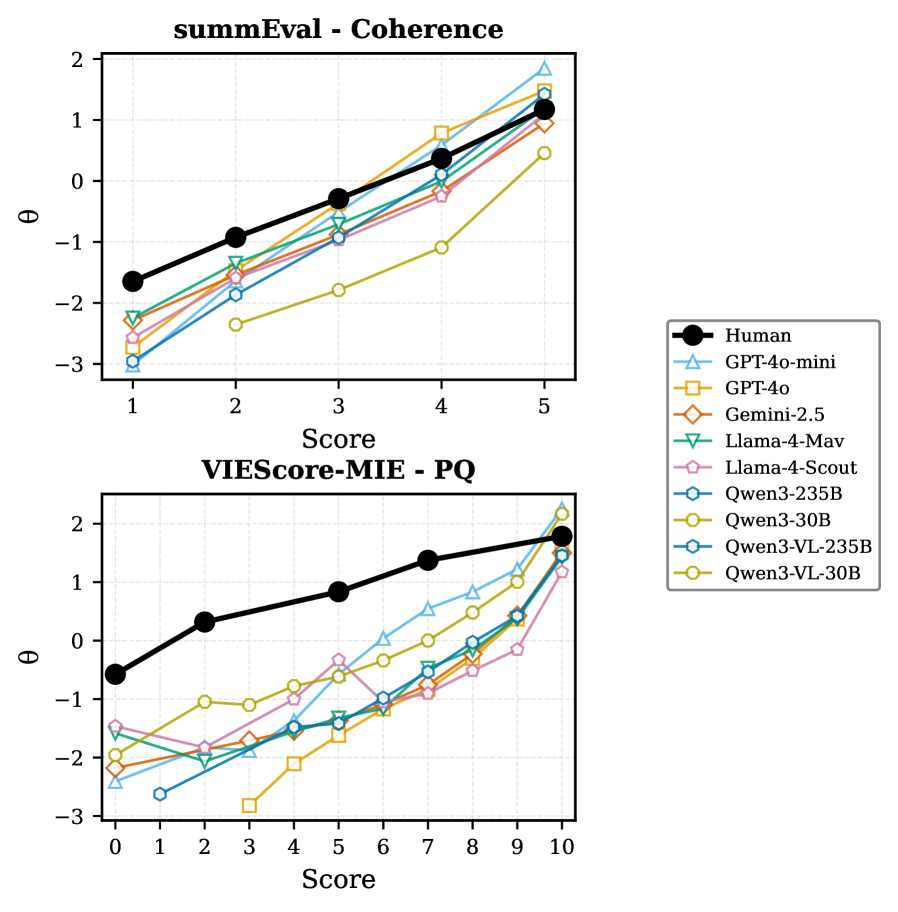
Одной из ключевых задач при оценке больших языковых моделей (LLM) является обеспечение их соответствия человеческим суждениям, известное как человеческое выравнивание. Этот аспект определяет, насколько оценки, выдаваемые LLM, коррелируют с оценками, данными людьми-экспертами. Низкая степень корреляции указывает на расхождения в восприятии качества и может свидетельствовать о предвзятости модели или её неспособности адекватно оценивать сложные или нюансированные задачи. Для количественной оценки человеческого выравнивания используются различные метрики, позволяющие выявить области, требующие улучшения и обеспечивающие более надежную и предсказуемую работу LLM в соответствии с человеческими ожиданиями.
Для количественной оценки согласованности восприятия качества между большими языковыми моделями (LLM) и людьми используются метрики, такие как Distributional Alignment (DWD) и Discrimination Breadth Ratio (θratio). Значения DWD варьируются от 0.15 до 0.61, отражая степень соответствия распределений оценок LLM и человеческих экспертов. Метрика θratio, в свою очередь, оценивает способность LLM различать варианты качества, при этом значения от 1.0 до >2.0 зависят от конкретной задачи; значения выше 1.0 указывают на то, что LLM может более тонко различать качество, чем люди в данной задаче. Эти метрики позволяют выявить потенциальные расхождения в оценках и определить области, где требуется улучшение согласованности LLM с человеческими предпочтениями.
Метрики, такие как расстояние Вассерштейна между распределениями (DWD) и коэффициент широты дискриминации (θratio), позволяют выявить систематические расхождения между оценками качества, данными LLM, и оценками экспертов-людей. Низкие значения DWD (близкие к 0.15) и значения θratio, приближающиеся к 1.0, указывают на высокую степень согласованности. В то же время, более высокие значения DWD (до 0.61) и θratio (превышающие 2.0) свидетельствуют о потенциальных смещениях в оценках LLM, указывая на конкретные области, где требуется улучшение соответствия человеческим предпочтениям и более точная дифференциация качественного контента.
Внутренняя Согласованность Судей: Обеспечение Надёжности Оценок
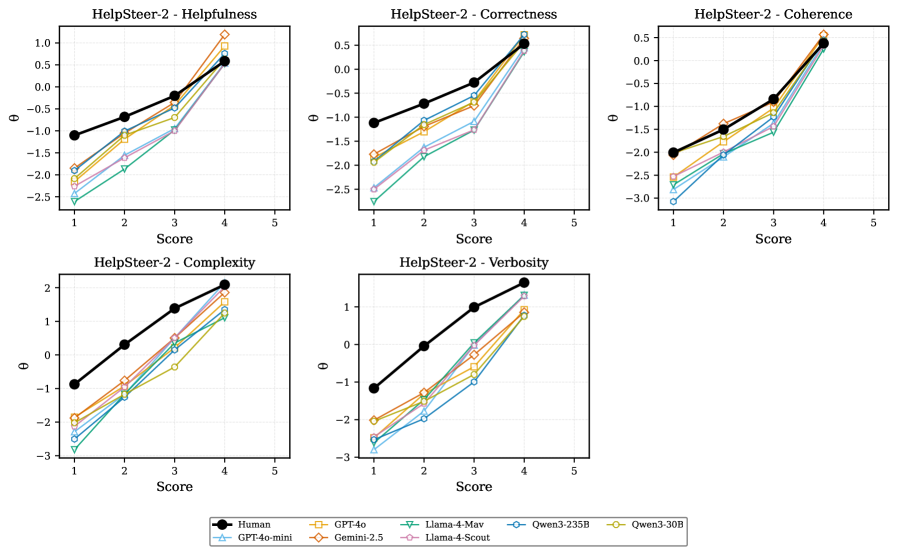
Внутренняя согласованность (Intrinsic Consistency) судей, основанных на больших языковых моделях (LLM), является критически важным фактором для обеспечения надежности оценок. Данный показатель отражает способность модели выдавать стабильные и непротиворечивые результаты при оценке одного и того же контента в эквивалентных условиях. Несогласованность может возникать из-за незначительных вариаций во входных данных или случайных факторов, влияющих на процесс оценки. Для обеспечения надежности необходимо, чтобы судейская LLM демонстрировала высокую степень внутренней согласованности, что позволяет исключить влияние случайных факторов и получить объективную оценку качества контента. Отсутствие внутренней согласованности ведет к недостоверным результатам и снижает ценность автоматизированной оценки.
Для оценки стабильности оценки, выдаваемой LLM-судьей, применяются методы вариации запросов и вычисления коэффициента согласованности запросов (CVC). Вариация запросов заключается в незначительных изменениях формулировок, предназначенных для проверки чувствительности LLM к небольшим отклонениям во входных данных. CVC количественно оценивает степень согласованности оценок, полученных для эквивалентных запросов, и представляет собой меру внутренней согласованности LLM. В наших исследованиях, приемлемая согласованность достигается при значении CVC менее 0.10, что указывает на низкую чувствительность к незначительным изменениям входных данных и, следовательно, на стабильную оценку.
Показатель предельной надёжности (ρ) количественно оценивает долю дисперсии в оценках, выдаваемых языковой моделью, которая связана с реальными различиями в качестве оцениваемых объектов, отделяя полезный сигнал от шума. По сути, он определяет, насколько оценки модели отражают истинные различия, а не случайные колебания. Приемлемый уровень надёжности считается достигнутым при значении ρ ≥ 0.7, что указывает на то, что большая часть вариативности в оценках модели объясняется различиями в качестве, а не случайными факторами.
LLM-Судьи в Действии: Бенчмаркинг Производительности
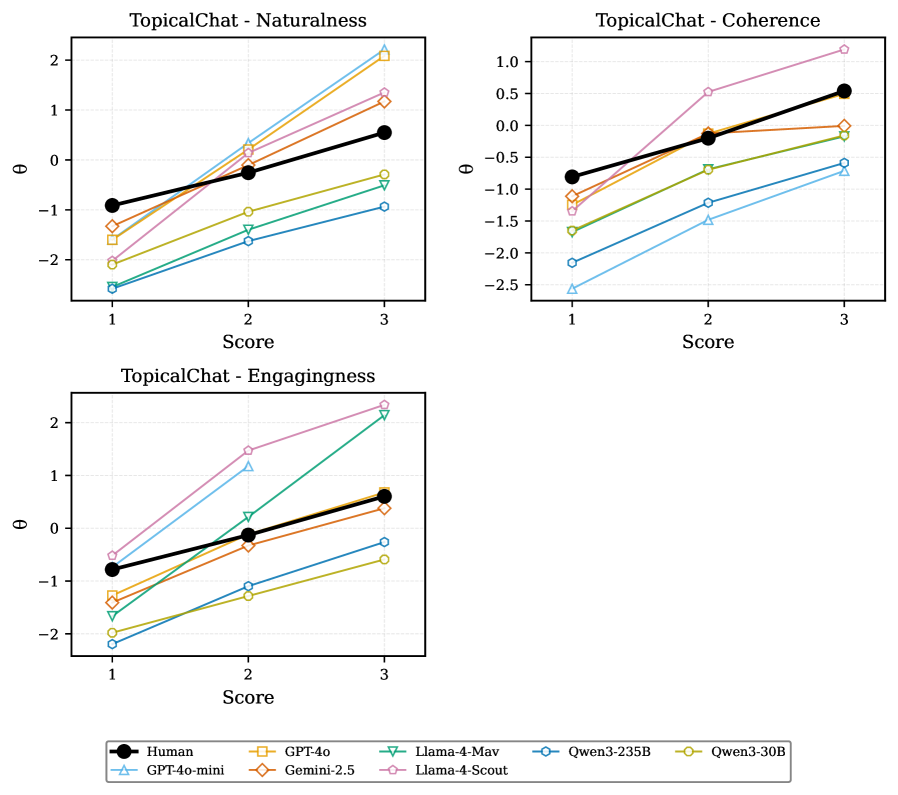
В настоящее время методика использования больших языковых моделей (LLM) в качестве судей активно внедряется в различных оценочных бенчмарках. В частности, LLM применяются для оценки качества сгенерированных текстов в бенчмарке SummEval, предназначенном для оценки суммаризации, в TopicalChat — для оценки диалоговых систем, и в HelpSteer-2 — для оценки систем, отвечающих на запросы. Это позволяет автоматизировать процесс оценки и получить более объективные результаты, особенно в задачах, требующих понимания естественного языка и контекста.
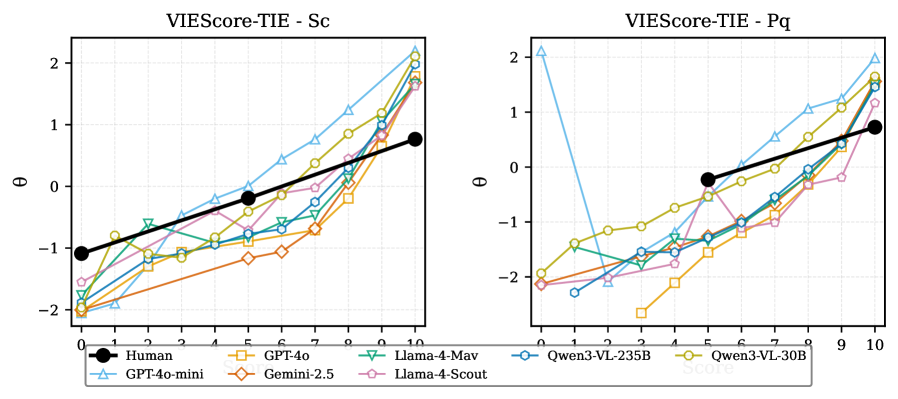
VIEScore представляет собой метрику, используемую для оценки качества изображений, генерируемых моделями, объединяющими зрение и язык (Vision-Language Models, VLMs). Она позволяет автоматизированно оценивать соответствие сгенерированных изображений текстовым запросам, используя большие языковые модели (LLM) в качестве судей. В отличие от традиционных метрик, требующих ручной аннотации, VIEScore предоставляет возможность быстрой и масштабируемой оценки качества визуального контента, создаваемого VLMs, что особенно актуально для задач генерации изображений по текстовому описанию.
Использование LLM в качестве судей в различных бенчмарках, таких как SummEval, TopicalChat и HelpSteer-2, а также VIEScore для оценки изображений, генерируемых Vision-Language Models (VLMs), предоставляет ценные данные о сильных и слабых сторонах этой методологии. Анализ результатов в различных доменах позволяет выявить области, где LLM демонстрируют высокую точность и последовательность, а также выявить проблемные места, требующие дальнейшей оптимизации. Эти данные служат основой для итеративного улучшения LLM-судей, направленного на повышение надежности и объективности оценки сгенерированного контента.
Исследование, представленное в данной работе, стремится к выявлению внутренней согласованности больших языковых моделей, выступающих в роли оценщиков. Авторы предлагают использовать теорию отклика на элементы для отделения этой внутренней согласованности от соответствия человеческим суждениям. Это позволяет получить более тонкое понимание надёжности моделей, выявляя, насколько последовательно они оценивают одни и те же данные. Как однажды заметил Кен Томпсон: «Простота — это высшая степень изысканности». Эта фраза отражает стремление к ясности и доказуемости, которые являются ключевыми в предложенном подходе к диагностике надёжности LLM-as-a-Judge. Ведь истинная надёжность проявляется не просто в «работе на тестах», а в математической чистоте и внутренней согласованности алгоритма.
Куда двигаться дальше?
Представленный анализ, использующий принципы теории отклика на задачу, выявляет фундаментальную сложность в оценке «судейства» больших языковых моделей. Разделение внутренней согласованности от соответствия человеческим суждениям — шаг необходимый, но он лишь подчеркивает глубину нерешенных вопросов. Оптимизация без анализа, как известно, — это самообман и ловушка для неосторожного разработчика. Попытки «настроить» модель на соответствие человеческому мнению без понимания ее внутренней логики обречены на создание хрупких и непредсказуемых систем.
Будущие исследования должны сосредоточиться на разработке более строгих метрик внутренней согласованности, независимых от субъективных оценок. Необходимо исследовать, как различные архитектурные решения влияют на эту согласованность, и как ее можно формально доказать. Модели, демонстрирующие внутреннюю непротиворечивость, вероятно, окажутся более устойчивыми и надежными в долгосрочной перспективе, даже если они не сразу соответствуют ожиданиям человеческих экспертов.
В конечном счете, задача состоит не в том, чтобы создать модель, имитирующую человеческое суждение, а в том, чтобы создать систему, способную к формальной, доказуемой логике. Именно в математической чистоте алгоритма, а не в его способности «проходить тесты», лежит истинная элегантность и надежность.
Оригинал статьи: https://arxiv.org/pdf/2602.00521.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Квантовый скачок в обработке радиоастрономических данных
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
2026-02-03 17:33