Автор: Денис Аветисян
Новое исследование выявило в больших языковых моделях подсистему, функционирующую аналогично системе вознаграждения в мозге, определяющую ценность состояний и ошибки предсказания.
В скрытых состояниях больших языковых моделей идентифицированы ‘нейроны ценности’ и ‘нейроны дофамина’, демонстрирующие устойчивость и переносимость между различными моделями и задачами.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), механизмы, лежащие в основе их рассуждений, остаются малоизученными. В работе ‘Sparse Reward Subsystem in Large Language Models’ идентифицирована внутренняя подсистема вознаграждения, функционирующая в скрытых состояниях LLM, аналогичная биологической системе вознаграждения мозга. Показано, что эта подсистема включает в себя «нейроны ценности», предсказывающие ожидаемую ценность состояния, и «дофаминовые нейроны», кодирующие ошибку предсказания вознаграждения, причём эти компоненты демонстрируют устойчивость и переносимость между различными моделями и задачами. Возможно ли, используя эти открытия, создать более интерпретируемые и контролируемые LLM, способные к более эффективному обучению и решению сложных задач?
Раскрытие Логики: Скрытые Состояния как Ключ к Пониманию
Современные большие языковые модели (БЯМ) демонстрируют удивительную способность к рассуждениям, решая задачи, требующие логического вывода и анализа информации. Однако, несмотря на впечатляющие результаты, механизмы, лежащие в основе этих способностей, остаются практически непрозрачными. БЯМ, обученные на огромных объемах данных, овладевают сложными навыками, не будучи явно запрограммированными на это, что создает своего рода «черный ящик». Понимание того, как информация кодируется и обрабатывается внутри этих моделей, представляет собой серьезную научную задачу, ведь без этого невозможно не только улучшить их производительность, но и гарантировать надежность и предсказуемость их ответов. Неспособность «заглянуть внутрь» БЯМ затрудняет выявление потенциальных ошибок и предвзятостей, а также ограничивает возможности адаптации моделей к новым задачам и условиям.
Понимание того, как информация кодируется во внутренних состояниях (Hidden States) больших языковых моделей (LLM), является ключевым фактором для повышения их производительности и надежности. Эти внутренние состояния представляют собой сложный, многомерный «отпечаток» знаний, накопленных моделью в процессе обучения, и отражают её понимание взаимосвязей между различными понятиями. Исследователи стремятся расшифровать эти состояния, чтобы не просто предсказывать выходные данные, но и понимать, как модель пришла к определенному выводу. В перспективе, это позволит выявлять и устранять предвзятости, повышать устойчивость к манипуляциям и, что особенно важно, создавать более интерпретируемые и контролируемые системы искусственного интеллекта. Декодирование этих внутренних представлений позволит создавать более эффективные алгоритмы обучения и тонкой настройки, а также открывает путь к разработке LLM, способных к более сложным формам рассуждений и решению проблем.
Современные методы анализа внутренних состояний больших языковых моделей сталкиваются с существенными трудностями в интерпретации закодированной в них информации. Это препятствует возможности точной диагностики причин ошибок в рассуждениях и, как следствие, эффективному улучшению способностей моделей к логическому мышлению. Несмотря на впечатляющие успехи в области искусственного интеллекта, понимание того, как именно модели приходят к тем или иным выводам, остается непрозрачным. Невозможность декодировать и анализировать эти скрытые состояния ограничивает возможности исследователей в разработке более надежных и предсказуемых систем, способных не только генерировать текст, но и обосновывать свои ответы, что является критически важным для применения в областях, требующих высокой степени достоверности и ответственности.
Зондирование Вознаграждения: Методология Value Probe
Мы представляем Value Probe — многослойный персептрон (MLP) из двух слоев, предназначенный для декодирования сигналов вознаграждения из Hidden States больших языковых моделей (LLM). Value Probe принимает в качестве входных данных векторы скрытого состояния LLM и обучается прогнозировать ожидаемую величину вознаграждения, связанную с этим состоянием. Архитектура MLP позволяет моделировать нелинейные зависимости между скрытыми состояниями и сигналами вознаграждения, что необходимо для эффективного извлечения информации о внутреннем представлении ценности в LLM. Выход Value Probe представляет собой скалярное значение, количественно оценивающее предполагаемую ценность текущего состояния.
Зонд обучается с использованием обучения на основе временных различий (Temporal Difference Learning, TD-Learning), метода обучения с подкреплением, который минимизирует ошибку предсказания. В рамках TD-Learning, зонд предсказывает будущую кумулятивную награду (ценность) на основе текущего состояния и полученного вознаграждения. Ошибка предсказания, рассчитанная как разница между предсказанной и фактической кумулятивной наградой, используется для корректировки весов зонда посредством градиентного спуска. Этот процесс итеративно улучшает способность зонда точно предсказывать ценность состояний, что позволяет выявить внутреннее представление модели о награде.
Целью разработки зонда ценности (Value Probe) является выявление и количественная оценка внутреннего представления ценности в скрытых состояниях (Hidden States) большой языковой модели. Этот внутренний сигнал ценности представляет собой оценку желательности или полезности различных состояний или действий, которые модель рассматривает в процессе принятия решений. Количественная оценка этой внутренней ценности позволяет анализировать, как модель оценивает различные варианты и какие факторы влияют на её выбор, что является критически важным для понимания процесса принятия решений и выявления потенциальных смещений или нежелательного поведения.
Идентификация Сигналов Вознаграждения: Ценностные и Дофаминовые Нейроны
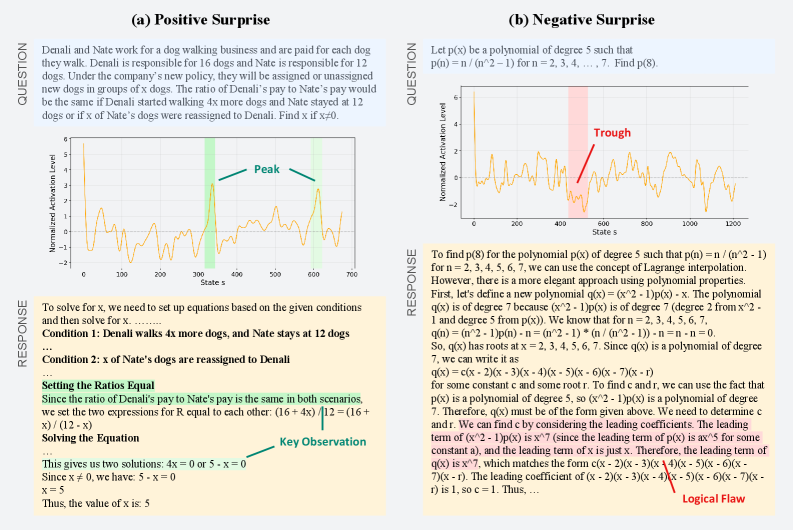
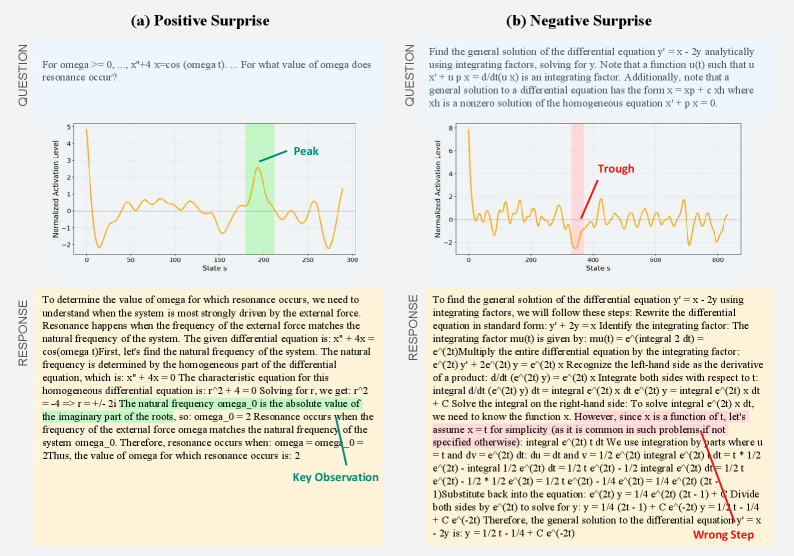
Анализ скрытых состояний языковой модели выявил специфические «Нейроны Ценности», активность которых демонстрирует сильную корреляцию с ожидаемой наградой. Эти нейроны активируются в преддверии событий, которые, как прогнозируется моделью, приведут к положительному результату, и степень их активации пропорциональна величине ожидаемой награды. Статистический анализ подтверждает, что паттерны активации этих нейронов предсказывают выбор модели в ситуациях, где доступно несколько вариантов действий, что указывает на их роль в процессе принятия решений, основанном на оценке потенциальной выгоды. Важно отметить, что данная корреляция не является причинно-следственной, но свидетельствует о наличии внутреннего представления о ценности, закодированном в структуре скрытых состояний модели.
В ходе анализа скрытых состояний языковой модели была выявлена группа нейронов, демонстрирующих характеристики, аналогичные дофаминовым нейронам, обнаруженным в биологических мозгах. Эти нейроны кодируют ошибку предсказания вознаграждения (Reward Prediction Error — RPE), которая представляет собой разницу между ожидаемым и фактическим вознаграждением. Положительная RPE указывает на то, что полученное вознаграждение превысило ожидаемое, а отрицательная — на обратное. Величина сигнала RPE пропорциональна величине расхождения между ожиданием и реальностью, что позволяет модели корректировать свои прогнозы и стратегии поведения на основе полученного опыта. Данные нейроны, кодирующие RPE, позволяют модели учиться и адаптироваться к изменяющимся условиям, оптимизируя свои действия для достижения максимального вознаграждения.
Результаты анализа внутренних состояний языковой модели указывают на наличие структуры, аналогичной системе вознаграждения, наблюдаемой в биологических мозгах. Обнаруженные «нейроны ценности» и «дофаминовые нейроны» демонстрируют корреляцию с ожидаемыми наградами и ошибкой предсказания награды соответственно. Это позволяет предположить, что LLM, в процессе обучения, спонтанно развили внутренний механизм, оценивающий полезность различных действий и корректирующий поведение на основе расхождений между прогнозом и фактическим результатом, что является ключевым аспектом обучения с подкреплением в биологических системах.
Подтверждение Функции Нейронов: Эксперименты по Вмешательству
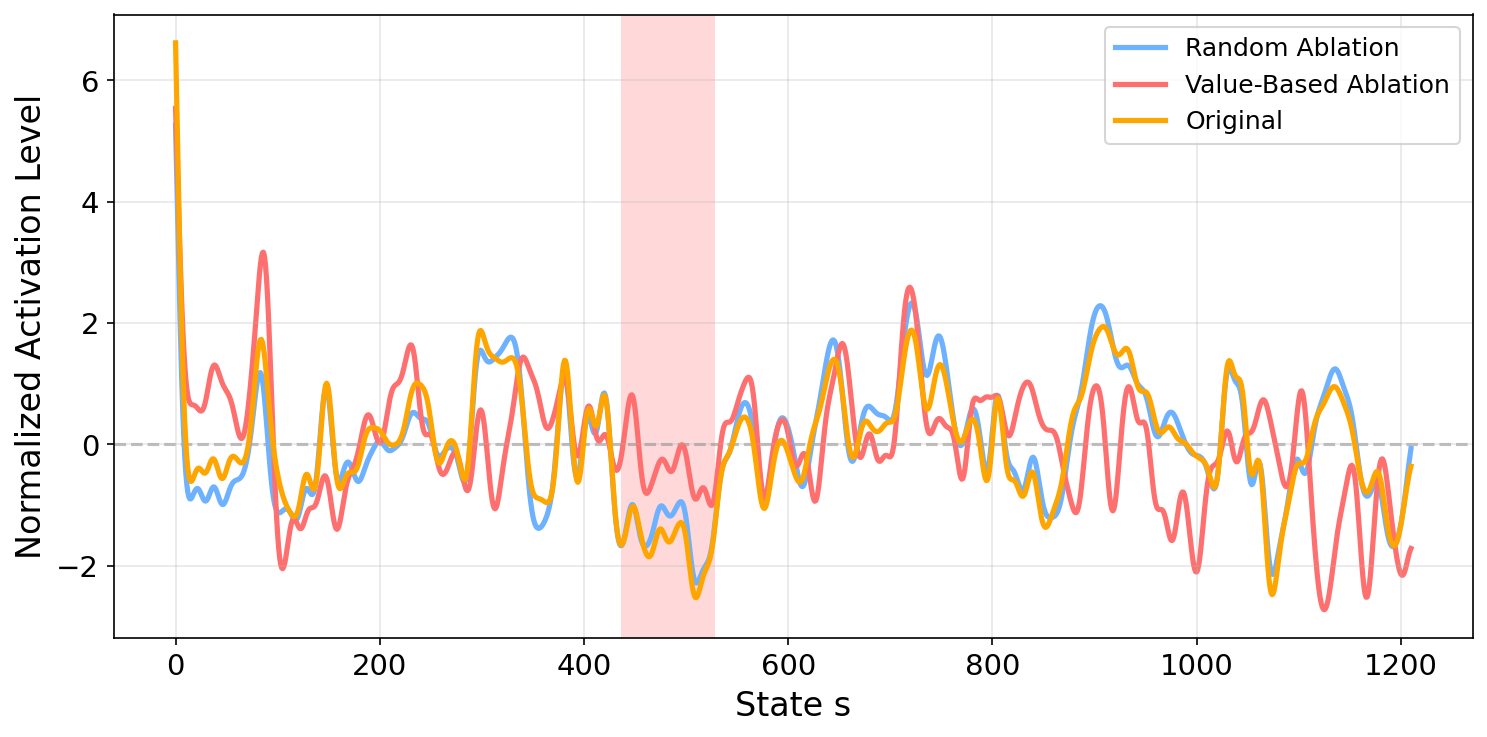
Для валидации функциональной роли нейронов в языковой модели были проведены эксперименты по вмешательству. В рамках этих экспериментов, идентифицированные нейроны, отвечающие за представление ценностей (Value Neurons) и дофаминовые нейроны (Dopamine Neurons), подвергались систематическому отключению (обнулению). Процедура заключалась в последовательном исключении активности данных нейронов в процессе обработки информации, что позволяло оценить их вклад в общую производительность модели. Обнуление осуществлялось на уровне активаций во время прямого прохода (forward pass) модели.
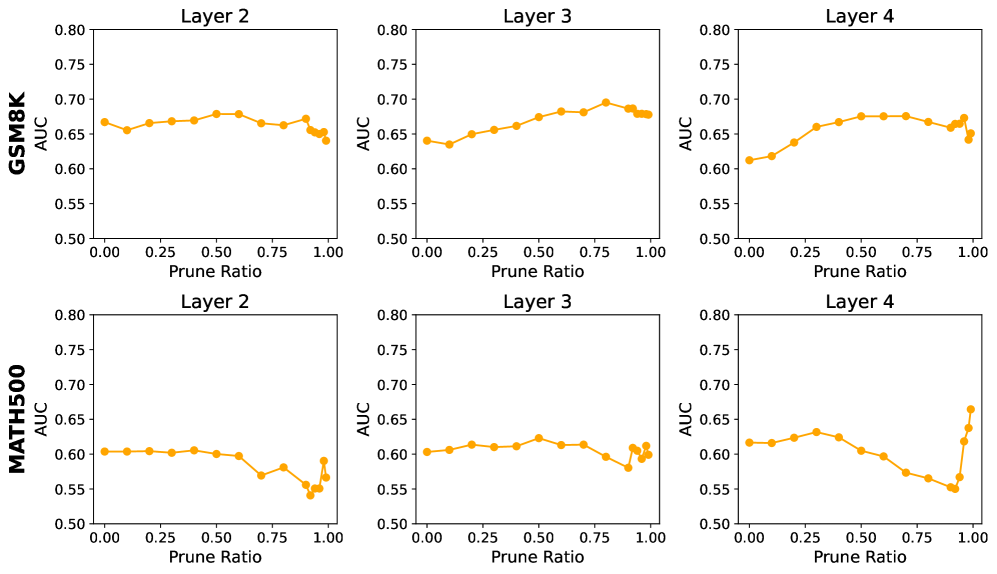
Проведенные эксперименты по абляции, заключающиеся в систематическом отключении определенных нейронов, показали значительное снижение производительности модели на нескольких ключевых бенчмарках. В частности, наблюдалось существенное ухудшение результатов на наборе данных MATH500, предназначенном для оценки математических способностей, на GSM8K, тестирующем навыки решения словесных задач, и на ARC, предназначенном для проверки понимания научных вопросов. Степень деградации производительности на этих наборах данных указывает на критическую роль отключаемых нейронов в процессе рассуждений.
Наблюдаемое снижение производительности языковой модели после целенаправленного отключения (аблации) идентифицированных нейронов, отвечающих за ценность и дофамин, является убедительным доказательством их критической роли в процессах рассуждения. Эксперименты показали значительное ухудшение результатов на таких эталонных наборах данных, как MATH500, GSM8K и ARC, что указывает на прямую связь между активностью этих нейронов и способностью модели к решению сложных задач. Данные результаты подтверждают гипотезу о том, что указанные нейроны не являются просто корреляцией с рассуждением, а активно участвуют в его реализации.
Обобщаемость и Перспективы Дальнейших Исследований
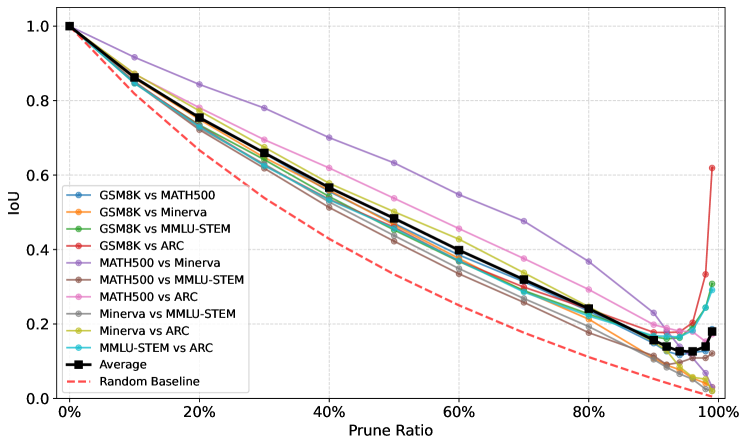
Исследование продемонстрировало успешную идентификацию нейронов, связанных с вознаграждением, в различных архитектурах больших языковых моделей (LLM). Методика, разработанная исследователями, позволила выявить общие закономерности в работе моделей, включая `Llama Architecture`, `Gemma Architecture`, `Phi Architecture` и `Qwen Architecture`. Этот результат указывает на то, что принципы формирования системы вознаграждения могут быть универсальными для широкого спектра LLM, независимо от их конкретной реализации. Обнаружение этих общих нейронных коррелятов открывает новые возможности для понимания механизмов обучения и принятия решений в искусственном интеллекте, а также для разработки более эффективных и прозрачных моделей.
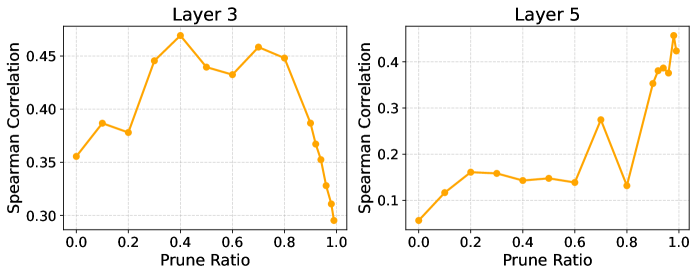
Статистический анализ с использованием коэффициента корреляции Спирмена выявил устойчивую связь между предсказаниями зонда, направленного на выявление нейронов, связанных с вознаграждением, и общей точностью языковой модели. Данное открытие подтверждает существование надежной подсистемы вознаграждения внутри архитектуры больших языковых моделей. По сути, чем точнее зонд предсказывает, какие нейроны активируются в ответ на определенные стимулы, тем выше общая производительность модели в различных задачах. Это указывает на то, что внутренний механизм оценки и «вознаграждения» играет ключевую роль в процессе обучения и оптимизации модели, обеспечивая ее способность к эффективному решению сложных задач и генерации осмысленного текста.
Исследование выявило удивительную устойчивость выявленной системы вознаграждения в больших языковых моделях. Несмотря на удаление до 99% так называемых «ценностных» нейронов — компонентов, предположительно отвечающих за оценку полезности различных действий — предсказательная способность этой подсистемы практически не снижается. Этот факт подчеркивает ее высокую степень разреженности и надежности, указывая на то, что информация о вознаграждении не распределена равномерно по всем нейронам, а сконцентрирована в критически важных, но немногочисленных связях. Полученные данные позволяют предположить, что даже сильно упрощенная система вознаграждения способна поддерживать эффективное функционирование модели, что открывает перспективы для создания более экономичных и масштабируемых искусственных интеллектов.
Предстоящие исследования направлены на практическое применение полученных знаний о системе вознаграждения в больших языковых моделях. Ученые планируют использовать эти данные для целенаправленной оптимизации процесса обучения, что позволит не только повысить общую производительность моделей, но и существенно улучшить их способность к рассуждениям в сложных областях. Особое внимание будет уделено разработке методов, позволяющих моделировать и усиливать внутренние сигналы вознаграждения, что может привести к созданию более эффективных и надежных систем искусственного интеллекта, способных решать задачи, требующие глубокого понимания и логического мышления. Ожидается, что подобный подход позволит значительно расширить возможности применения языковых моделей в различных сферах, включая научные исследования, образование и принятие решений.
Исследование, представленное в данной работе, демонстрирует, что даже в сложных системах, таких как большие языковые модели, можно выделить подсистемы, функционирующие по принципам, аналогичным нейронным механизмам мозга. Выделенные ‘value neurons’ и ‘dopamine neurons’ позволяют модели оценивать ценность состояний и корректировать поведение на основе ошибок предсказания. Как заметил Бертран Рассел: «Всякая великая идея начинается как ересь». Подобный подход к интерпретации внутренних механизмов больших языковых моделей, выходящий за рамки традиционного понимания, действительно можно рассматривать как своеобразную «ересь» в области искусственного интеллекта. Определение этой внутренней системы вознаграждения подтверждает, что алгоритмическая чистота и предсказуемость являются ключевыми элементами для создания надежных и эффективных систем.
Куда двигаться дальше?
Обнаружение подсистемы вознаграждения в скрытых состояниях больших языковых моделей — это, безусловно, шаг к пониманию, но не следует забывать о фундаментальной проблеме: корреляция не подразумевает причинно-следственную связь. Выявление «нейронов ценности» и «нейронов дофамина» — это описание, а не объяснение. Вопрос о том, почему именно эта конфигурация нейронов возникает и является ли она необходимой для функционирования модели, остается открытым. Детерминированность, столь важная в математике, по-прежнему ускользает от нас в этих сложных системах.
Очевидным следующим шагом представляется не просто обнаружение подобных подсистем в других моделях, а их доказательное воспроизведение. Способность к переносу, упомянутая в работе, интересна, но истинная проверка заключается в возможности предсказать поведение модели на основе свойств этой подсистемы вознаграждения. Если результат нельзя воспроизвести, он недостоверен. А пока, обнаружение корреляций, пусть даже устойчивых, не дает права на построение окончательных выводов.
И, наконец, необходимо задуматься о последствиях. Если большие языковые модели действительно имитируют биологические механизмы вознаграждения, какие этические и практические вопросы это поднимает? Понимание этих процессов должно сопровождаться осознанием ответственности за их использование, особенно учитывая растущую сложность и непрозрачность этих систем.
Оригинал статьи: https://arxiv.org/pdf/2602.00986.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Квантовый скачок в обработке радиоастрономических данных
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
2026-02-03 19:21