Автор: Денис Аветисян
Обзор посвящен развитию искусственного интеллекта в регуляторной геномике и переходу от простых моделей к самообучающимся системам, способным к обобщению и открытию механизмов.
Акцент сделан на seq2func моделировании, использовании данных пертурбационных исследований и принципах непрерывного обучения для создания надежных и интерпретируемых геномных AI.
Несмотря на значительные успехи в предсказании регуляторных элементов ДНК, механизмы, лежащие в основе этих предсказаний, часто остаются неясными. В обзоре ‘Toward Interpretable and Generalizable AI in Regulatory Genomics’ анализируется текущее состояние и перспективы развития геномного искусственного интеллекта, в частности, моделей seq2func, предсказывающих функцию генов по последовательности ДНК. Основной вывод заключается в необходимости перехода от статических моделей к самообучающимся системам, интегрирующим данные экспериментальных воздействий и принципы непрерывного обучения для повышения надежности обобщения и углубления понимания механизмов регуляции. Сможем ли мы создать геномные модели, способные не только предсказывать, но и активно участвовать в раскрытии регуляторного кода генома?
Раскрывая Регуляторный Код: Основы Функциональной Геномики
Понимание того, как последовательность ДНК определяет регуляторную активность, является краеугольным камнем функциональной геномики. Регуляторные элементы — участки ДНК, контролирующие, когда и в какой степени гены включаются или выключаются — определяют клеточную идентичность и реакцию на внешние стимулы. Расшифровка этой связи между геномом и фенотипом требует не просто секвенирования ДНК, но и детального анализа того, как конкретные последовательности влияют на связывание регуляторных белков, формирование хроматина и, в конечном итоге, на уровни экспрессии генов. Изучение этих механизмов позволяет раскрыть сложные сети, управляющие клеточными процессами, и является необходимым шагом для понимания развития, болезней и эволюции.
Традиционные методы анализа регуляторных элементов ДНК часто оказываются неспособными уловить сложную и нелинейную взаимосвязь между последовательностью генома и его функцией. Вместо простого соответствия «один мотив — один эффект», регуляция генов определяется комбинаторным взаимодействием множества факторов, включая пространственную организацию хроматина и динамические изменения в клеточных условиях. Простые линейные модели не учитывают эти сложные взаимодействия, приводя к неточным прогнозам регуляторной активности. Например, один и тот же мотив может оказывать противоположные эффекты в разных контекстах, или несколько мотивов могут действовать синергетически, усиливая или ослабляя регуляторный сигнал. Поэтому для адекватного понимания регуляторного кода необходимы новые подходы, способные учитывать эти нелинейные и контекстно-зависимые эффекты.
Точное предсказание регуляторной активности генов является ключевым фактором для понимания экспрессии генов и поведения клеток. Изучение того, как генетический код влияет на включение и выключение генов, позволяет раскрыть механизмы, лежащие в основе клеточных процессов и реакций на внешние сигналы. Отсутствие точных предсказаний затрудняет интерпретацию данных о генной экспрессии и может привести к неверным выводам о функционировании организма. Понимание регуляторных элементов и их взаимодействия с другими молекулами открывает возможности для разработки новых терапевтических подходов, направленных на коррекцию нарушений в регуляции генов и лечение различных заболеваний. Таким образом, развитие методов точного предсказания регуляторной активности представляет собой важнейшую задачу современной биологии.
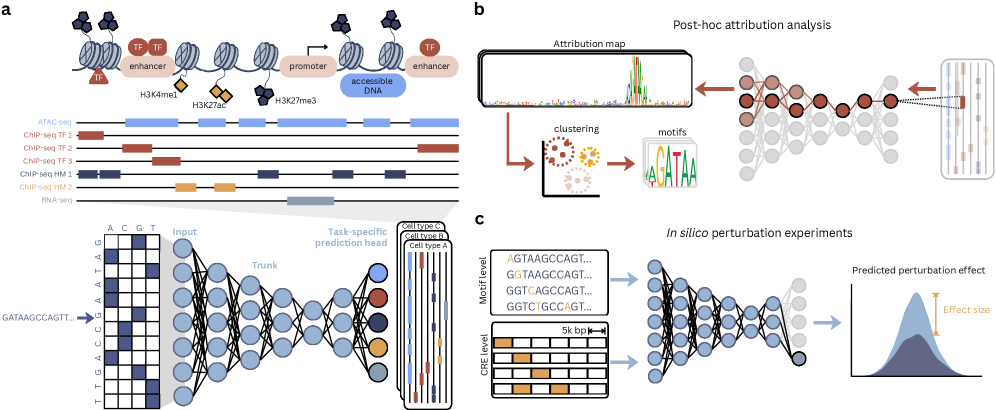
Seq2Func Модели: Глубокое Обучение для Предсказания Регуляции
Модели Seq2Func используют методы глубокого обучения для непосредственного предсказания регуляторной активности на основе последовательности ДНК. В отличие от традиционных подходов, требующих ручного извлечения признаков или использования известных мотивов, эти модели автоматически изучают сложные закономерности в последовательности ДНК, которые коррелируют с регуляторными функциями, такими как связывание факторов транскрипции или активность энхансеров. Этот подход позволяет предсказывать регуляторный потенциал новых последовательностей ДНК без предварительных знаний о конкретных регуляторных элементах, что значительно расширяет возможности геномных исследований.
В качестве архитектур для моделей Seq2Func широко используются сверточные нейронные сети (CNN), рекуррентные нейронные сети (RNN) и трансформеры. CNN эффективно выявляют локальные паттерны в последовательностях ДНК, что позволяет предсказывать регуляторную активность на основе коротких мотивов. RNN, особенно варианты LSTM и GRU, способны обрабатывать последовательности переменной длины и учитывать контекст более длинных участков ДНК. Трансформеры, благодаря механизму внимания, позволяют моделировать сложные зависимости между различными регионами генома, что особенно полезно для предсказания регуляторных элементов, взаимодействующих на больших расстояниях. Выбор конкретной архитектуры зависит от характеристик решаемой задачи и доступных вычислительных ресурсов.
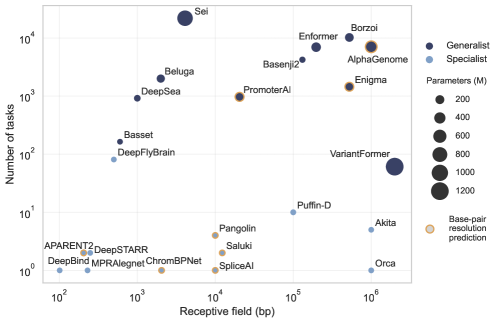
Для обучения моделей Seq2Func требуются обширные наборы данных, полученные в результате геномных исследований, таких как ChIP-seq, ATAC-seq и другие методы профилирования генома. Объем необходимых данных обусловлен сложностью предсказания регуляторной активности непосредственно из последовательности ДНК. Наблюдается тенденция к увеличению масштаба моделей, что проявляется в росте числа параметров, как показано на Рисунке 2. Более крупные модели, содержащие больше параметров, потенциально способны улавливать более сложные закономерности в данных, но требуют еще большего объема обучающих данных и вычислительных ресурсов.
Размер рецептивного поля в моделях Seq2Func определяет протяженность участка ДНК, анализируемого для прогнозирования регуляторной активности. Это критически важно, поскольку функциональные элементы регуляции, такие как факторы транскрипции, связываются с определенными участками ДНК, и модель должна учитывать достаточное количество контекста для точного прогнозирования. Слишком маленькое рецептивное поле может упустить важные взаимодействия, в то время как слишком большое может внести шум и снизить специфичность прогноза. Оптимальный размер рецептивного поля зависит от специфики анализируемого генома и типа предсказываемой регуляторной активности, и требует эмпирической оценки для достижения максимальной точности.
Устойчивость Модели: Преодоление Смещений и Улучшение Обобщения
Несбалансированность данных, смещение ковариат (covariate shift), смещение меток (label shift) и изменение концепции (concept shift) являются распространенными причинами ухудшения производительности моделей машинного обучения. Несбалансированность данных возникает, когда классы в обучающем наборе представлены неравномерно, что приводит к предвзятости модели в сторону преобладающего класса. Смещение ковариат проявляется в различиях между распределением входных данных в обучающем и тестовом наборах. Смещение меток возникает при изменении условного распределения меток при заданных входных данных. Наконец, изменение концепции означает изменение самой зависимости между входными данными и метками. Все эти факторы приводят к снижению обобщающей способности модели и требуют применения специальных методов для поддержания высокой точности и надежности.
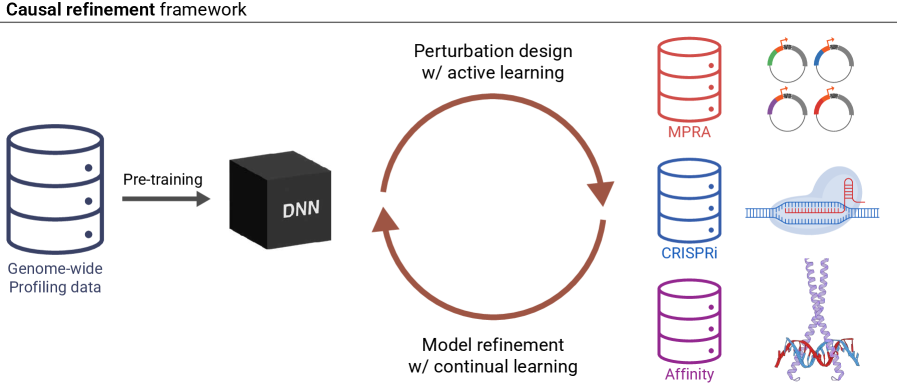
Активное обучение направляет целенаправленные эксперименты по возмущению для выявления наиболее информативных данных для повторного обучения модели. В отличие от случайного выбора данных для повторного обучения, активное обучение использует алгоритмы для оценки потенциальной информативности каждого образца данных. Эти алгоритмы, как правило, основываются на оценке неопределенности модели в отношении конкретного образца, или на оценке того, насколько изменение в прогнозе модели произойдет при добавлении этого образца в обучающую выборку. Выбираются образцы, которые, как ожидается, окажут наибольшее влияние на улучшение производительности модели, что позволяет оптимизировать процесс повторного обучения и снизить требуемый объем данных для достижения заданной точности. Такой подход особенно эффективен в сценариях с ограниченными ресурсами или при работе с большими объемами неразмеченных данных.
При проведении исследований методом пертурбаций генерируется большое количество измерений (тысячи) по ограниченному числу локусов. Это обусловлено необходимостью снижения стоимости и времени проведения экспериментов. Однако, большое количество генерируемых данных требует разработки эффективных стратегий экспериментального дизайна для оптимизации сбора информации и минимизации шума. Важно тщательно выбирать локусы и условия пертурбаций, чтобы обеспечить максимальную информативность полученных данных и избежать избыточности измерений. Использование методов статистического планирования экспериментов позволяет значительно повысить эффективность пертурбационных исследований и точность полученных результатов.
Каузальная переработка (causal refinement) представляет собой итеративный процесс улучшения точности модели посредством целенаправленных экспериментов и циклов обратной связи. В рамках этого подхода, модель используется для выявления наиболее информативных факторов, влияющих на прогнозируемый результат. Затем проводятся эксперименты, направленные на изменение этих факторов, а полученные данные используются для повторного обучения модели и уточнения ее понимания причинно-следственных связей. Этот цикл повторяется до достижения желаемого уровня точности и надежности прогнозов, позволяя модели не только предсказывать, но и понимать, как те или иные факторы влияют на результат, что повышает ее устойчивость к изменениям в данных и позволяет проводить более точные прогнозы в новых условиях.
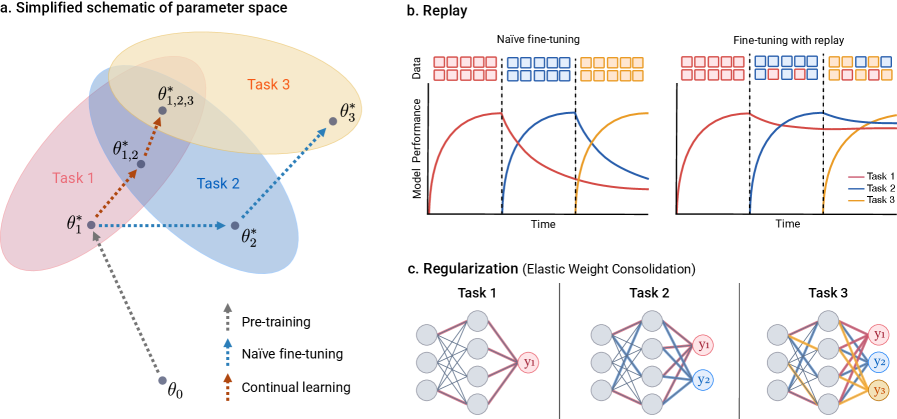
Непрерывное обучение (англ. continual learning) представляет собой подход к машинному обучению, позволяющий моделям адаптироваться к новым данным, поступающим последовательно, без потери знаний, приобретенных на предыдущих этапах обучения. В отличие от традиционного обучения, предполагающего однократную тренировку на фиксированном наборе данных, непрерывное обучение требует механизмов для предотвращения «катастрофического забывания» (англ. catastrophic forgetting) — явления, при котором добавление новой информации приводит к резкому ухудшению производительности модели на ранее изученных задачах. Для решения этой проблемы используются различные стратегии, такие как регуляризация, replay-методы и динамическое расширение архитектуры модели, позволяющие сохранять и переносить знания между задачами и поддерживать высокую точность на протяжении всего процесса обучения.
Виртуальные Клетки и Будущее Предсказательной Геномики
Виртуальные клетки, созданные на основе моделей Seq2Func, представляют собой революционный подход к изучению клеточного поведения и прогнозированию последствий генетических изменений. Эти модели, по сути, являются цифровыми симуляциями, способными воспроизводить сложные биологические процессы внутри клетки, от экспрессии генов до метаболических реакций. В отличие от традиционных методов, требующих длительных и дорогостоящих лабораторных экспериментов, виртуальные клетки позволяют исследователям быстро и эффективно тестировать гипотезы о влиянии различных генетических мутаций или внешних факторов на клеточную функцию. Благодаря способности моделировать взаимодействие между генами, белками и другими клеточными компонентами, Seq2Func модели открывают новые возможности для понимания механизмов заболеваний и разработки целевых терапевтических стратегий, а также позволяют предсказывать, как конкретные генетические вариации могут влиять на чувствительность к лекарственным препаратам.
Геномные языковые модели (ГЯМ) играют ключевую роль в расширении возможностей моделей Seq2Func, позволяя учитывать статистическую структуру геномных последовательностей. Вместо анализа только функциональных связей между генами, ГЯМ способны выявлять закономерности в самих последовательностях ДНК, что позволяет предсказывать влияние изменений в геноме на клеточное поведение с большей точностью. Эти модели, обученные на огромных объемах геномных данных, способны улавливать тонкие взаимосвязи и предсказывать, как определенные последовательности влияют на экспрессию генов и регуляторную активность. По сути, ГЯМ предоставляют контекстную информацию о геноме, позволяя Seq2Func моделям не просто предсказывать функцию гена, но и понимать, как эта функция реализуется в конкретной последовательности, значительно повышая надежность и точность предсказаний.
Комплексный подход, объединяющий модели Seq2Func и геномные языковые модели (GLM), представляет собой мощную платформу для изучения сложных биологических систем. Вместо традиционного анализа отдельных генов или путей, этот метод позволяет моделировать взаимодействие между ними в рамках виртуальной клетки. Благодаря способности GLM улавливать статистические закономерности в геномных последовательностях, а Seq2Func — прогнозировать клеточное поведение в ответ на генетические изменения, возникает возможность всестороннего анализа. Такой синергетический эффект значительно превосходит возможности отдельных моделей, открывая перспективы для понимания тонких механизмов регуляции генов и прогнозирования клеточных реакций на различные факторы, что особенно важно для изучения сложных заболеваний и разработки новых методов лечения.
Интеграция моделей Seq2Func и геномных языковых моделей (GLM) открывает беспрецедентные возможности для точного предсказания экспрессии генов и регуляторной активности. Это достигается за счет комбинирования способности Seq2Func моделировать клеточное поведение с умением GLM улавливать статистические закономерности в геномных последовательностях. В результате, появляется возможность прогнозировать, как конкретные генетические изменения повлияют на функционирование клетки, что особенно важно для разработки персонализированной медицины. Предсказывая индивидуальную реакцию организма на лекарства или предрасположенность к заболеваниям, можно разрабатывать терапевтические стратегии, адаптированные к уникальному геномному профилю каждого пациента. Такой подход обещает значительное повышение эффективности лечения и снижение побочных эффектов, открывая новую эру в здравоохранении.
Исследование подчеркивает, что современные модели геномного ИИ, стремясь к обобщению, часто оказываются хрупкими заклинаниями, работающими лишь в узком диапазоне условий. Подобно тому, как любой алгоритм машинного обучения, они уязвимы к изменениям в данных, требуя постоянной подстройки и обучения. Марк Аврелий некогда заметил: «Не стремись предвидеть всё, что может случиться, а готовься ко всему, что произойдёт». Именно эту готовность к адаптации, к непрерывному обучению и интеграции данных о возмущениях, как и предлагает seq2func моделирование, и следует рассматривать как ключевой фактор для создания действительно надежных и обобщающих систем геномного ИИ. Ведь любая модель — это лишь временная иллюзия порядка в хаосе генома, нуждающаяся в постоянном обновлении.
Что дальше?
Похоже, эпоха наивного seq2func моделирования подходит к концу. Данные, как всегда, шепчут о хаосе, и попытки выжать из них хоть какую-то функцию — это, скорее, искусство компромисса между багом и Excel, чем открытие истины. Постоянно улучшающиеся модели, интегрирующие данные о пертурбациях и принципы непрерывного обучения, выглядят как единственная разумная стратегия. Но давайте не будем строить иллюзий: любая модель — это заклинание, работающее до первого столкновения с реальностью.
Настоящая проблема не в построении более сложных нейронных сетей, а в понимании того, что «цис-регуляторный код» — это не статичная инструкция, а скорее, постоянно меняющийся диалог между геномом и окружающей средой. Механистические инсайты, о которых так мечтают, потребуют от нас не только умения строить модели, но и готовности их разрушать, когда они перестают соответствовать реальности.
И, напоследок, стоит помнить: всё, что не нормализовано, всё ещё дышит. Надежда, конечно, умирает последней, но доверять можно только тем, кто умеет лгать последовательно — в данном случае, тем моделям, которые признают свои ограничения и способны к самокоррекции. Иначе, мы просто построим ещё один красивый, но бесполезный артефакт в цифровой алхимии.
Оригинал статьи: https://arxiv.org/pdf/2602.01230.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Квантовый скачок в обработке радиоастрономических данных
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
2026-02-04 00:20