Автор: Денис Аветисян
Исследователи предлагают систему WideSeek, использующую многоагентные системы и обучение с подкреплением для одновременного охвата больших объемов информации.
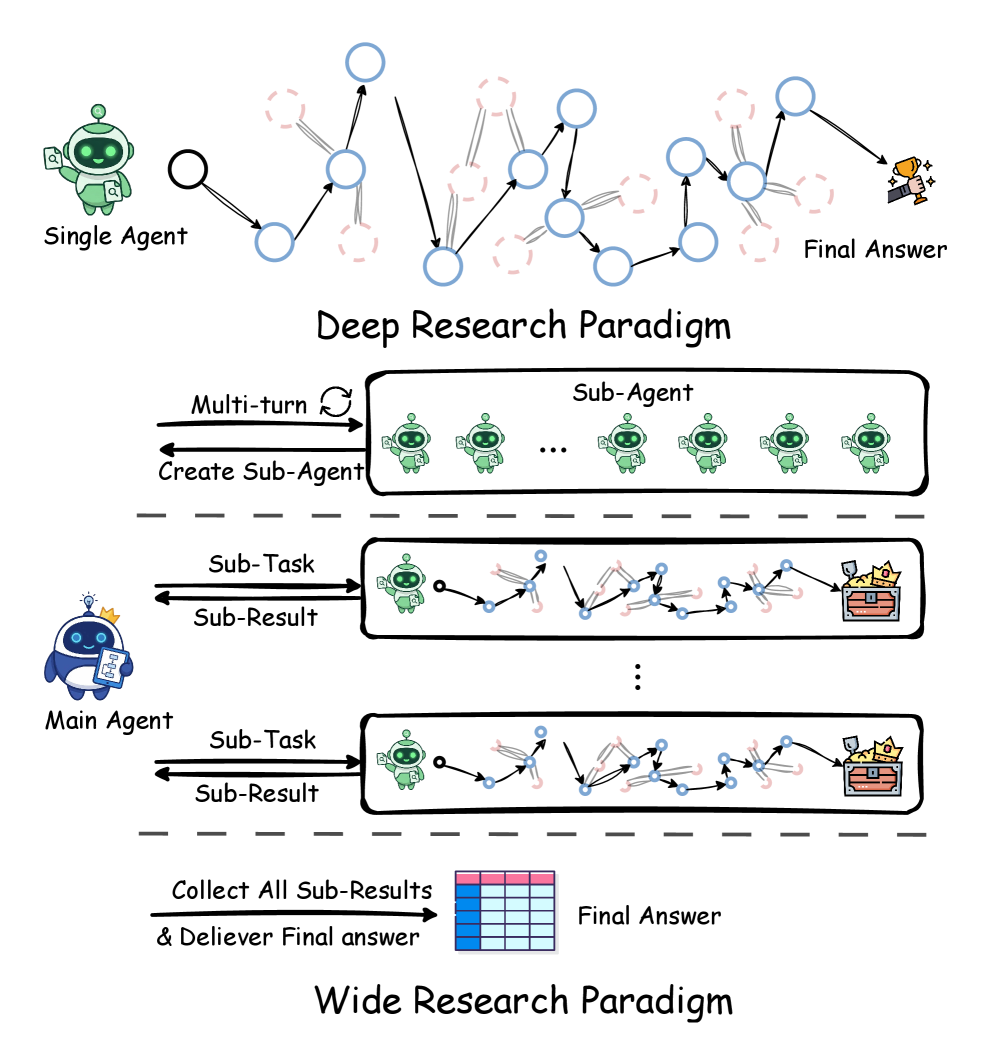
В статье представлена новая методика широкого поиска информации и эталонный набор данных WideSeekBench для оценки эффективности параллельного извлечения знаний.
Поиск информации всё чаще требует не углубленного анализа отдельных источников, а охвата широкого спектра данных при соблюдении сложных ограничений. В данной работе, ‘WideSeek: Advancing Wide Research via Multi-Agent Scaling’, предложен новый подход к решению этой задачи, основанный на масштабировании многоагентных систем. Авторы представляют WideSeekBench — эталонный набор данных для широкого поиска информации, и WideSeek — динамическую иерархическую архитектуру, оптимизированную с помощью обучения с подкреплением. Сможет ли этот подход, демонстрирующий эффективность масштабирования числа агентов, стать основой для нового этапа развития интеллектуального поиска информации?
Широкий поиск информации: вызов для современных систем
Современные системы искусственного интеллекта сталкиваются с существенными трудностями при решении задач общего поиска широкой информации (GBIS). В отличие от человека, способного сформулировать запрос в общих чертах и интерпретировать неоднозначные данные, ИИ требует предельно точных и конкретных запросов. Неспособность справиться с двусмысленностью приводит к нерелевантным результатам или полному отсутствию ответа. Это особенно заметно при поиске информации, требующей синтеза знаний из различных источников и понимания контекста. Таким образом, существующие алгоритмы, ориентированные на узкоспециализированные задачи, демонстрируют ограниченную эффективность в ситуациях, когда требуется гибкий и адаптивный подход к поиску информации.
Традиционные методы поиска информации зачастую ограничены использованием небольшого числа источников, что существенно снижает их эффективность при решении комплексных задач. Вместо того, чтобы исследовать широкий спектр данных и выявлять скрытые взаимосвязи, такие системы, как правило, оперируют заранее заданными базами знаний или конкретными веб-сайтами. Это приводит к тому, что важные сведения, рассеянные по различным контекстам, остаются незамеченными, а синтез информации для получения целостной картины становится затруднительным. В результате, даже при наличии релевантных данных, традиционные подходы не способны обеспечить всесторонний анализ и глубокое понимание изучаемого вопроса, ограничивая возможности для инноваций и принятия обоснованных решений.
Для эффективного поиска широкой информации требуется агент, способный формировать сложные запросы и ориентироваться в обширных графах знаний. Такой агент не просто извлекает данные, но и синтезирует их из различных источников, выстраивая логические связи и заполняя пробелы в информации. Способность к формулированию многоуровневых запросов позволяет уточнять цели поиска и отсеивать нерелевантные данные, а навигация по графам знаний обеспечивает доступ к взаимосвязанным фактам и концепциям. В отличие от традиционных систем, полагающихся на ключевые слова, подобный агент способен понимать контекст и намерения пользователя, что значительно повышает точность и релевантность результатов. Реализация такого агента требует передовых алгоритмов обработки естественного языка и машинного обучения, способных к пониманию семантики и логическому выводу.
WideSeek: многоагентный подход к синтезу информации
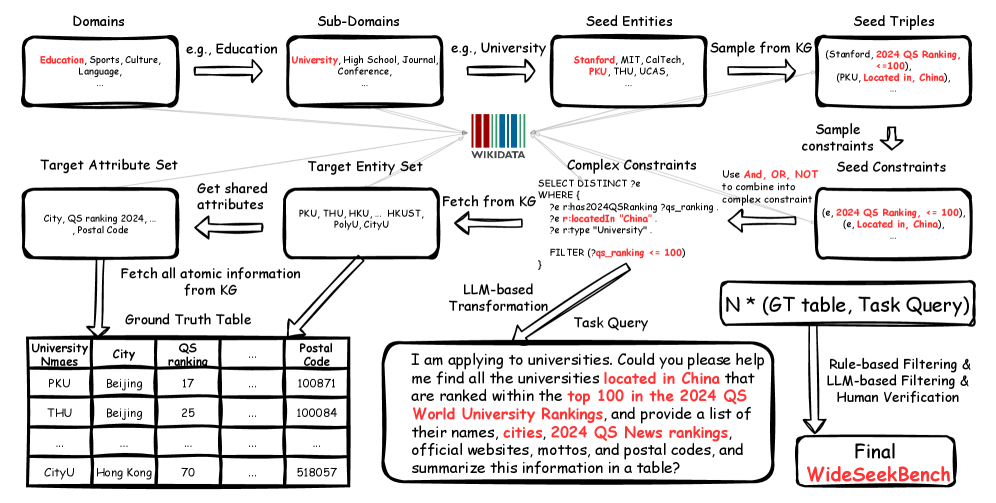
WideSeek использует динамическую многоагентную систему для исследования и синтеза информации, что позволяет преодолеть ограничения, присущие подходу с использованием единственного запроса. Вместо последовательного выполнения одного запроса, система задействует несколько агентов, которые параллельно исследуют различные аспекты темы и взаимосвязи между данными. Каждый агент выполняет специализированную задачу — например, формулирование запросов, навигацию по графу знаний или оценку релевантности полученных результатов — и обменивается информацией с другими агентами для достижения общей цели. Такая архитектура позволяет эффективно обрабатывать сложные запросы, требующие агрегации данных из различных источников, и обеспечивает более полное и точное представление информации.
Система WideSeek использует алгоритмы обучения с подкреплением для множества агентов (MultiAgentRL) для оптимизации их поведения при исследовании графа знаний и формулировании запросов. Применение MultiAgentRL позволяет каждому агенту независимо обучаться стратегии эффективного перемещения по графу, учитывая специфические цели и ограничения. Обучение происходит посредством взаимодействия агентов с графом знаний и получения вознаграждения за успешное нахождение релевантной информации и формирование корректных запросов SPARQL. Этот подход позволяет динамически адаптировать поведение агентов, улучшая общую эффективность системы по сравнению со статическими методами поиска и запросов.
Архитектура WideSeek позволяет формировать сложные запросы на языке SPARQL, что обеспечивает доступ к структурированным данным, хранящимся в графах знаний. SPARQL, являясь стандартным языком запросов для RDF данных, позволяет агентам системы извлекать конкретные факты и взаимосвязи из графа знаний. Использование SPARQL позволяет не только получать данные, но и выполнять сложные логические операции, такие как фильтрация, агрегация и объединение данных из различных частей графа знаний, что существенно расширяет возможности системы по синтезу информации и построению комплексных ответов на запросы.
Ускорение обучения с помощью контролируемой тонкой настройки
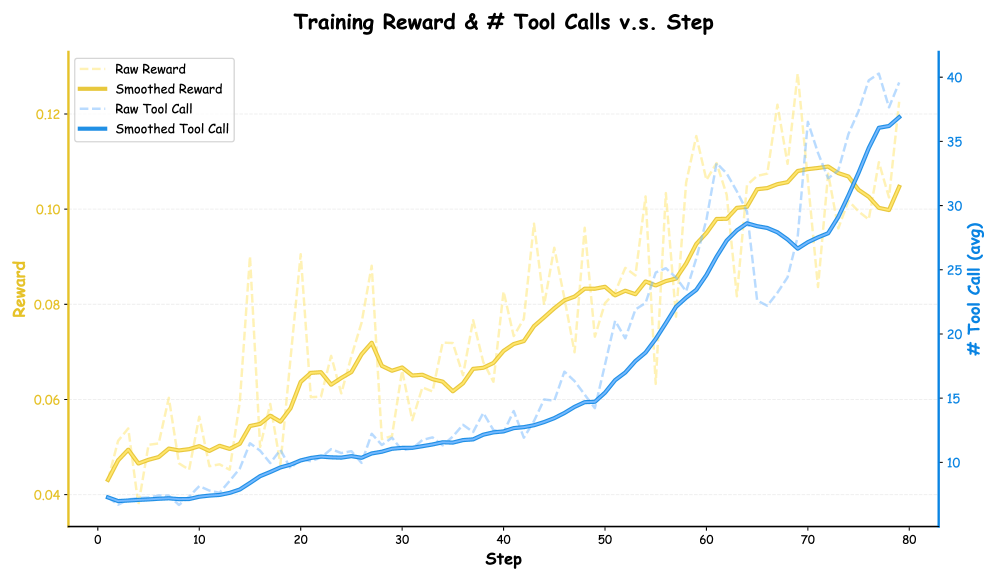
Для существенного ускорения обучения используется метод контролируемого обучения с подкреплением (Supervised Fine-Tuning, SFT), применяемый к предварительной тренировке политики WideSeek. В рамках этого процесса политика обучается на высококачественных траекториях, представляющих собой последовательности действий, демонстрирующих эффективное решение задач. Использование SFT позволяет политике быстро освоить базовые навыки и стратегии, значительно сокращая время, необходимое для достижения оптимальной производительности по сравнению с обучением с нуля или использованием стандартных алгоритмов обучения с подкреплением. Высокое качество траекторий, используемых для обучения, критически важно для обеспечения стабильности и эффективности предварительно обученной политики.
В процессе обучения с подкреплением используется мощная языковая модель GPT4 для генерации и оценки первоначальных решений задач. GPT4 выступает в роли эксперта, способного создавать разнообразные варианты действий и оценивать их потенциальную эффективность на основе заданных критериев. Это позволяет значительно ускорить процесс обучения политики, поскольку модель не начинает с нуля, а использует предварительно сгенерированные и оцененные траектории в качестве отправной точки. Оценка решений GPT4 основывается на анализе их соответствия поставленным целям и логической связности, что обеспечивает высокое качество начальных данных для обучения.
Архитектура двойной модели, управляемая шаблонами строк `FStringTemplates`, обеспечивает повышение разнообразия и логической корректности генерируемых запросов. `FStringTemplates` задают структуру и ограничения для генерации запросов, позволяя создавать более разнообразные варианты, сохраняя при этом логическую связность и соответствие поставленной задаче. Внутренняя структура архитектуры двойной модели предполагает использование двух моделей, взаимодействующих между собой для улучшения качества генерируемых запросов: одна модель генерирует запрос, а другая оценивает его логическую корректность и соответствие шаблону, что способствует созданию более надежных и релевантных результатов.
Строгая оценка возможностей широкого поиска информации
Для всесторонней оценки возможностей системы WideSeek использовался комплекс метрик, включающий в себя показатель успешности (Success Rate), а также F1-меру для строк (Row F1) и отдельных элементов (Item F1). Показатель успешности определяет, насколько полно и точно система отвечает на поставленные запросы. Row F1 оценивает качество найденных релевантных строк в ответах, в то время как Item F1 фокусируется на точности определения отдельных релевантных элементов внутри этих строк. Применение этих метрик в совокупности позволяет получить детальное представление об эффективности системы в широком спектре задач поиска информации, выявляя сильные и слабые стороны ее работы и обеспечивая объективную оценку прогресса в разработке.
Вся процедура оценки была построена на использовании модели GPT4 в качестве эксперта-оценщика, что позволило обеспечить высокую степень согласованности и надёжности при анализе решений, полученных в ходе экспериментов. Применение GPT4 гарантирует объективность оценки, исключая субъективные факторы, которые могли бы повлиять на результаты. Этот подход особенно важен при работе со сложными задачами, требующими глубокого понимания контекста и нюансов, поскольку GPT4 способен анализировать ответы с учётом семантической близости и релевантности информации. Такой метод оценки позволяет с высокой точностью измерять способность моделей к широкому поиску информации и определять наиболее эффективные стратегии решения задач.
Модель WideSeek-8B-SFT-RL продемонстрировала значительное улучшение в области поиска широкого спектра информации, достигнув среднего значения F1-меры в 12.87% на бенчмарке WideSeekBench при оценке четырех лучших результатов (Mean@4 Item F1). Наряду с этим, максимальное значение F1-меры для строк (Max Row F1) составило 3.88%, что указывает на способность модели эффективно извлекать релевантную информацию из различных источников и представлять её в структурированном виде. Данные результаты подтверждают, что WideSeek-8B-SFT-RL обладает повышенной точностью и способностью к обобщению при решении сложных задач поиска информации.
Обученная модель WideSeek-8B-SFT-RL демонстрирует значительно превосходящую обобщающую способность по сравнению с базовой моделью Qwen3-8B. Результаты показывают, что Item F1 для WideSeek-8B-SFT-RL достигает 26.42%, что превосходит показатель в 21.03%, демонстрируемый современными проприетарными моделями. Это указывает на то, что WideSeek-8B-SFT-RL не только эффективно справляется с задачами, на которых она обучалась, но и успешно адаптируется к новым, ранее не встречавшимся информационным запросам, обеспечивая более надежные и точные результаты в широком спектре поисковых сценариев.
Исследование демонстрирует отход от последовательного, углубленного поиска информации к параллельному, широкому охвату — концепция, которая, несомненно, обречена на постепенное усложнение и, как следствие, появление технического долга. Авторы предлагают WideSeekBench и WideSeek, стремясь оптимизировать сбор информации через многоагентные системы и обучение с подкреплением. Однако, стоит помнить, что любая архитектура, даже самая элегантная в теории, со временем превратится в анекдот, когда столкнется с суровой реальностью продакшена. Как метко заметил Дональд Кнут: «Оптимизм — это вера в то, что все будет хорошо. Пессимизм — это уверенность в том, что так и будет». Эта фраза отражает неизбежность появления компромиссов и упрощений в любом практическом применении, независимо от изначальной чистоты замысла.
Что дальше?
Представленная работа, безусловно, демонстрирует возможность параллельного поиска информации. Однако, история учит, что каждая новая архитектура неизбежно сталкивается с ограничениями масштабируемости. В конечном итоге, даже самые элегантные решения в области multi-agent систем превратятся в сложный клубок взаимосвязей, требующий постоянной поддержки и оптимизации. Появится новая «узкая» точка, и всё придётся начинать сначала.
Более того, возникает вопрос: насколько «широкий» поиск действительно полезен? Когда информации становится слишком много, задача выделения релевантного становится экспоненциально сложнее. Вероятно, следующий этап развития потребует не просто увеличения скорости поиска, а создания интеллектуальных механизмов фильтрации и синтеза знаний — то есть, возвращения к идее глубокого анализа, но с использованием инструментов, позволяющих обрабатывать гораздо большие объёмы данных.
Всё новое — это просто старое с худшей документацией. И, скорее всего, через несколько лет кто-нибудь скажет, что «Wide Research» работала прекрасно, пока не появился какой-нибудь «SuperWideResearch» с ещё более сложной настройкой. Такова уж участь исследователя — вечно догонять ускользающее совершенство.
Оригинал статьи: https://arxiv.org/pdf/2602.02636.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Квантовый скачок в обработке радиоастрономических данных
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Оптимизация обучения нейросетей: новый подход на основе оптимального управления
2026-02-04 07:08