Автор: Денис Аветисян
Новый тест WorldVQA выявляет пробелы в понимании визуальной информации даже у самых продвинутых мультимодальных моделей.
Исследование оценивает способность моделей точно идентифицировать объекты на изображениях и обнаруживает значительные проблемы с фактической точностью и калибровкой.
Несмотря на впечатляющий прогресс в области мультимодальных больших языковых моделей, оценка их фактических знаний об окружающем мире остается сложной задачей. В данной работе представлена новая методика оценки — ‘WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models’, предназначенная для изоляции и измерения способности моделей к точному распознаванию визуальных сущностей. Полученные результаты демонстрируют существенные пробелы в фактических знаниях и калибровке даже в самых современных моделях, выявляя склонность к галлюцинациям. Сможем ли мы создать модели, обладающие действительно энциклопедическими знаниями и способные надежно интерпретировать визуальную информацию?
Иллюзии Разума: Пределы Современных Мультимодальных Моделей
Несмотря на значительный прогресс в разработке мультимодальных больших языковых моделей (MLLM), обеспечение фактической достоверности остаётся сложной задачей, что приводит к феномену “галлюцинаций”. Эти модели, способные обрабатывать и объединять информацию из различных источников, таких как текст и изображения, зачастую генерируют утверждения, не соответствующие действительности или представленным данным. Данная проблема возникает из-за сложности в установлении надёжной связи между визуальным вводом и соответствующими знаниями, а также из-за тенденции моделей к экстраполяции и генерации нового контента, который может быть не подкреплен фактическими данными. Это ограничивает их применение в задачах, требующих высокой точности и надёжности, таких как медицинская диагностика или анализ юридических документов, и подчеркивает необходимость дальнейших исследований в области фактического обоснования и снижения склонности к галлюцинациям.
Существующие оценочные тесты для мультимодальных моделей часто не позволяют четко определить, где модель демонстрирует фактические пробелы в знаниях, а где — трудности с комплексным анализом. Вместо того, чтобы изолированно оценивать способность модели вспоминать конкретные факты, представленные в визуальном или текстовом формате, многие тесты требуют от неё выполнения сложных умозаключений и обобщений. Это приводит к тому, что ошибки, вызванные недостатком базовых знаний, маскируются под проблемы с логическим мышлением, и наоборот. Таким образом, существующие метрики не всегда точно отражают истинный уровень осведомленности модели, затрудняя разработку эффективных стратегий для улучшения её фактической точности и надёжности.
Для достоверной оценки фактической точности современных мультимодальных моделей необходимы специализированные эталоны, сконцентрированные на проверке элементарных знаний. Вместо сложных сценариев, требующих комбинации различных навыков, эти эталоны должны изолировать простейшую связь между визуальным стимулом и его корректной меткой. Такой подход позволяет точно определить, способна ли модель устанавливать прямые соответствия между увиденным и известными фактами, а не полагаться на обобщения или умозаключения. Именно выявление дефицита в этих базовых знаниях является ключевым шагом к созданию более надежных и правдивых мультимодальных систем, способных достоверно интерпретировать окружающий мир.
WorldVQA: Эталон для Проверки Атомарных Знаний
Бенчмарк WorldVQA разработан для оценки способности моделей отвечать на вопросы, требующие исключительно прямой визуальной идентификации и фактического извлечения информации, что позволяет изолировать и проверить так называемые “атомарные знания”. Это означает, что вопросы сформулированы таким образом, чтобы ответ напрямую соответствовал визуальному признаку объекта и его общепринятому наименованию, избегая необходимости в сложных логических умозаключениях или интерпретации контекста. Основная цель — точная проверка способности модели к ассоциации визуального образа с соответствующей фактологической информацией, без привлечения дополнительных знаний или рассуждений.
В основе WorldVQA лежит принцип “атомарной изоляции”, что означает, что вопросы сформулированы таким образом, чтобы требовать прямой связи между визуальным стимулом и соответствующим таксономическим названием объекта. Это исключает необходимость в сложных рассуждениях или выводах, сосредотачиваясь исключительно на способности модели к непосредственному распознаванию и вспоминанию фактов. Вопросы специально разработаны для проверки только базового понимания, избегая ситуаций, когда для ответа требуется анализ контекста, интерпретация намерений или комбинирование нескольких фактов. Такой подход позволяет точно оценить способность модели к извлечению и сопоставлению элементарных знаний об объектах, представленных на изображении.
При разработке WorldVQA особое внимание уделялось принципам таксономического разнообразия и целостности данных. Таксономическое разнообразие обеспечивается включением в набор данных изображений, представляющих широкий спектр объектов из различных таксономических групп, что позволяет оценить способность моделей к обобщению знаний. Целостность данных гарантируется строгим контролем качества аннотаций и проверкой соответствия изображений и соответствующих таксономических наименований. Эти меры направлены на снижение вероятности возникновения систематических ошибок и предвзятости в оценке моделей, а также на повышение надежности и репрезентативности результатов.
Количественная Оценка Соответствия: Калибровка и Метрики
Для количественной оценки соответствия между уверенностью модели и её фактической точностью в WorldVQA используются метрики, такие как “Weighted Average Slope” (средний взвешенный наклон) и “Expected Calibration Error” (ожидаемая ошибка калибровки). “Weighted Average Slope” измеряет линейную зависимость между предсказанной уверенностью и фактической точностью, где более высокий наклон указывает на лучшую калибровку. “Expected Calibration Error” вычисляет разницу между средней уверенностью для заданного уровня уверенности и фактической точностью для этого уровня. Низкое значение ECE свидетельствует о том, что модель хорошо откалибрована и её предсказанные вероятности отражают реальную вероятность правильного ответа. Обе метрики позволяют оценить, насколько надежны предсказания модели и насколько можно доверять её уверенности в ответах.
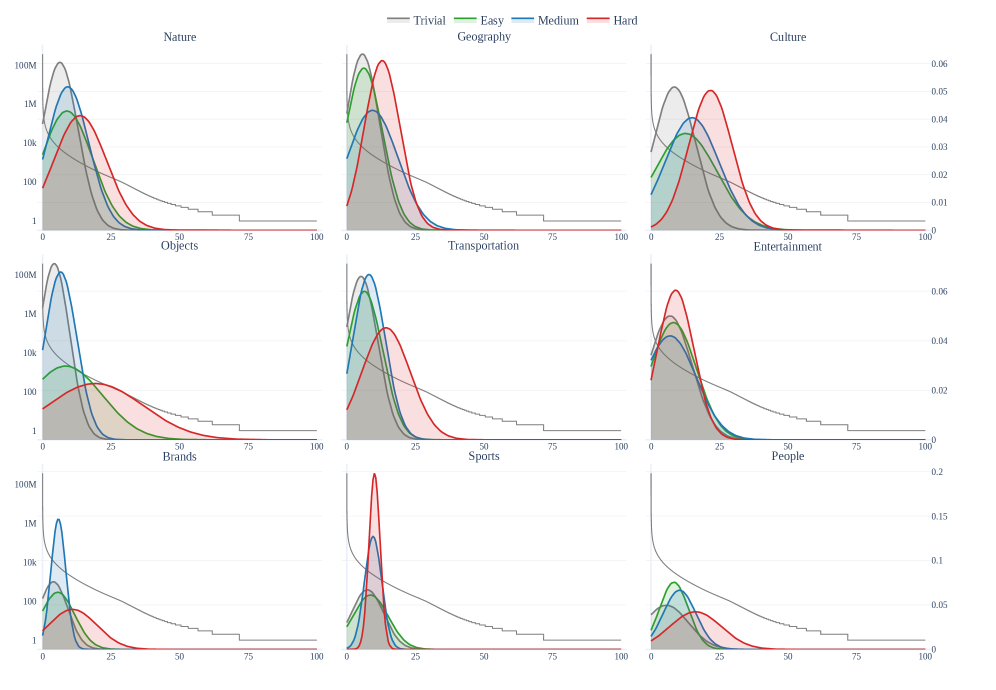
Для оценки сложности вопросов и обеспечения более точной оценки, эталонный набор данных использует ‘MetaCLIP’ для приближенного определения частоты встречаемости сущностей в реальном мире. ‘MetaCLIP’ позволяет оценить вероятность появления той или иной сущности в повседневной жизни, что используется для стратификации сложности вопросов — вопросы, затрагивающие редкие сущности, считаются более сложными. Такой подход позволяет не просто оценивать общую точность модели, но и анализировать ее производительность в зависимости от частоты встречаемости сущностей, предоставляя более детальную и нюансированную оценку ее способности к фактическому обоснованию.
Для повышения надежности оценки используется детекция семантического содержимого на уровне отдельных экземпляров данных. Этот процесс позволяет предотвратить утечку информации из тестового набора, вызванную наличием в нем экземпляров, семантически дублирующих данные из обучающей выборки. Детекция осуществляется путем анализа семантической близости между экземплярами тестового набора и обучающими данными, что позволяет исключить из оценки экземпляры, которые могут привести к завышенным результатам из-за нежелательного «знания» модели о них. Таким образом, обеспечивается более объективная и достоверная оценка обобщающей способности модели.
Влияние и Перспективы: Что Значит Это для Искусственного Интеллекта?
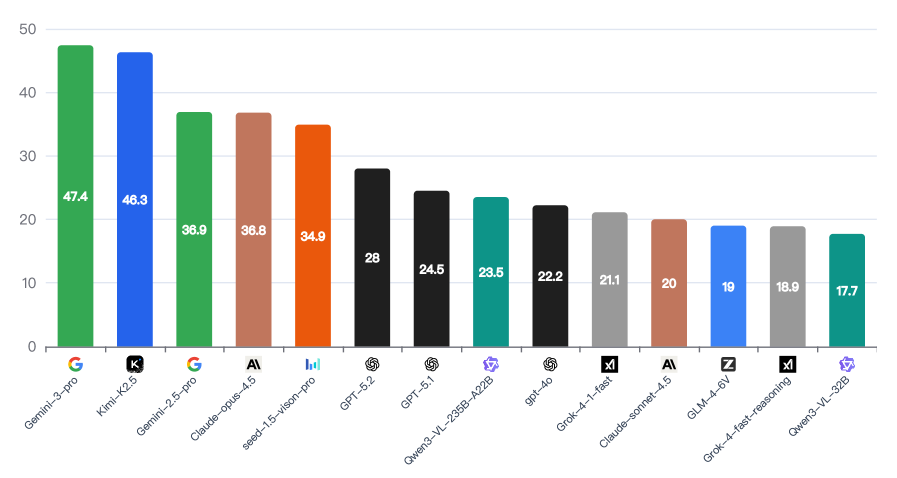
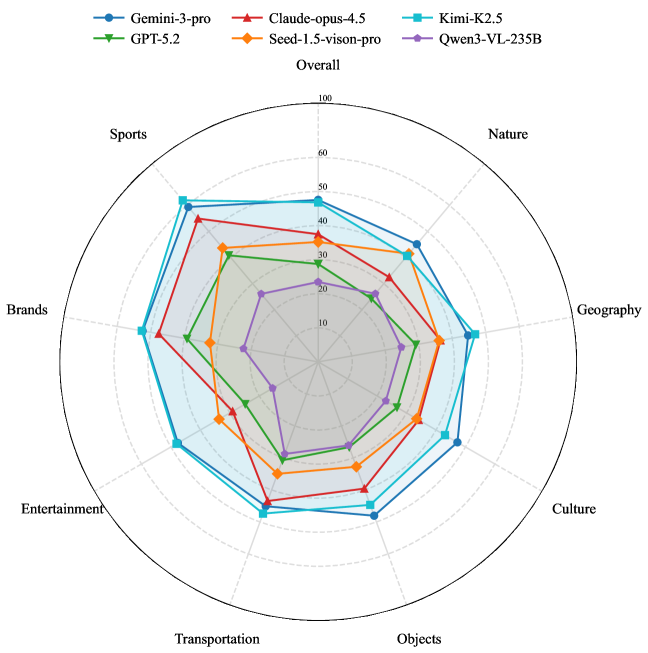
Оценка производительности современных мультимодальных больших языковых моделей (MLLM), таких как Gemini-3-pro, Kimi K2.5 и GPT-5.1, на базе набора данных WorldVQA, выявила сохраняющиеся трудности в области фактической обоснованности ответов. Несмотря на достижение впечатляющих результатов — Gemini-3-pro показал F-score в 47.4%, а Kimi K2.5 — 46.8% — даже самые передовые модели демонстрируют склонность к генерации ответов, не полностью подтверждаемых фактическими данными. Этот результат подчеркивает, что, несмотря на значительный прогресс в области искусственного интеллекта, надежная привязка к реальному миру и точная передача информации остаются ключевой проблемой, требующей дальнейших исследований и разработок в архитектуре и обучении MLLM.
Согласно результатам оценки на базе набора данных WorldVQA, модель Gemini-3-pro продемонстрировала наивысший показатель эффективности, достигнув значения F-меры в 47,4%. Этот результат свидетельствует о значительном прогрессе в области мультимодальных больших языковых моделей (MLLM) и их способности к комплексному анализу визуальной информации и ответам на вопросы, требующие глубокого понимания контекста. Несмотря на достигнутый успех, важно отметить, что даже самые передовые модели, такие как Gemini-3-pro, все еще сталкиваются с трудностями в области фактической точности, что подчеркивает необходимость дальнейших исследований и разработок в данной сфере.
Модель Kimi K2.5, являясь наиболее эффективным решением с открытым исходным кодом, продемонстрировала впечатляющий результат в 46.8% по метрике F-score на бенчмарке WorldVQA. Этот показатель свидетельствует о значительном прогрессе в области мультимодальных больших языковых моделей (MLLM) и подтверждает потенциал открытых разработок в конкуренции с проприетарными решениями. Несмотря на то, что результат Kimi K2.5 незначительно уступает показателю Gemini-3-pro, он подчеркивает важность доступности и возможности адаптации открытых моделей для широкого круга исследователей и разработчиков, способствуя дальнейшему развитию данной области искусственного интеллекта.
Исследования показали, что модель Kimi K2.5 демонстрирует наилучшую калибровку среди протестированных MLLM, достигая значения ошибки ожидаемой калибровки (ECE) в 37.9%. Этот показатель свидетельствует о высокой степени соответствия между уверенностью модели в своих ответах и их фактической точностью. В отличие от моделей, склонных к излишней самоуверенности или, наоборот, к недооценке своей способности, Kimi K2.5 обеспечивает более надежную оценку вероятности правильности ответа, что критически важно для приложений, где требуется принятие обоснованных решений на основе машинного обучения. Такая точность в оценке собственной уверенности позволяет более эффективно использовать модель в ситуациях, требующих взвешенного подхода к риску и принятию решений.
Конструкция бенчмарка WorldVQA, предусматривающая значительный “запас прочности” в плане производительности, обеспечивает его актуальность по мере развития моделей искусственного интеллекта. В отличие от многих других оценочных тестов, быстро насыщающихся по мере прогресса, WorldVQA изначально разработан с возможностью усложнения задач, что позволяет постоянно испытывать новые модели и выявлять слабые места даже у самых передовых систем. Этот подход гарантирует, что WorldVQA останется ценным инструментом для оценки и сравнения мультимодальных больших языковых моделей (MLLM) в будущем, стимулируя дальнейшие исследования в области искусственного интеллекта и компьютерного зрения.
Расширяя Горизонты Мультимодальной Оценки
Проект WorldVQA значительно расширяет возможности существующих бенчмарков визуального вопросно-ответного анализа (VQA), таких как SimpleVQA, делая акцент на проверке знаний об отдельных фактах. В отличие от предыдущих подходов, где модели могли полагаться на общие ассоциации или поверхностное понимание изображений, WorldVQA требует от систем точного извлечения и сопоставления конкретных деталей, представленных на визуальном материале. Такой подход позволяет более точно оценить способность искусственного интеллекта к фактическому рассуждению и пониманию мира, выявляя слабые места в представлении знаний и логическом выводе. Это, в свою очередь, стимулирует разработку более надежных и интеллектуальных систем VQA, способных к глубокому пониманию и точному ответу на вопросы о визуальной информации.
Бенчмарк WorldVQA, благодаря своей целенаправленной структуре, позволяет с высокой точностью выявлять слабые места существующих моделей визуального вопросно-ответного анализа. Вместо обобщенных оценок, этот подход обеспечивает детализированную диагностику, указывая на конкретные пробелы в представлении знаний и логических рассуждениях. Это, в свою очередь, направляет усилия исследователей на разработку более эффективных методов кодирования информации и алгоритмов, способных к более глубокому пониманию взаимосвязей между визуальными данными и языковыми запросами. Идентифицируя специфические типы вопросов, на которые модели не способны дать корректные ответы, WorldVQA стимулирует развитие как новых архитектур нейронных сетей, так и усовершенствование существующих подходов к обучению и представлению знаний, что является ключевым шагом на пути к созданию надежного искусственного интеллекта.
Разработка и совершенствование эталонных наборов данных, подобных WorldVQA, имеет первостепенное значение для создания надежных систем искусственного интеллекта. Способность достоверно связывать языковые запросы с визуальной информацией — это фундаментальный аспект истинного понимания, а не просто статистического сопоставления. Подобные бенчмарки позволяют не только оценить текущие возможности моделей, но и выявить слабые места в области представления знаний и логических выводов, направляя исследования к созданию ИИ, способного к осмысленному взаимодействию с окружающим миром. По мере усложнения задач, требующих понимания контекста и здравого смысла, подобные эталоны становятся необходимым инструментом для проверки и улучшения надежности и безопасности интеллектуальных систем.
Исследование показывает, что даже самые передовые мультимодальные большие языковые модели демонстрируют удивительные пробелы в фактических знаниях о мире. Авторы, создав WorldVQA, попытались отделить зерна от плевел, выявить, где модель действительно «видит» и «понимает», а где лишь строит правдоподобные, но ложные конструкции. Эта работа, по сути, демонстрирует, что модели часто оперируют не с истиной, а с вероятностями, и что кажущаяся уверенность в ответах может быть обманчивой. Как метко заметил Ян Лекун: «Машинное обучение — это искусство того, чтобы заставить компьютеры делать вещи, которые они не должны уметь делать». И WorldVQA — это яркое подтверждение этого, выявляющее границы магии, заключенной в нейронных сетях.
Куда же это всё ведёт?
Представленный здесь анализ, подобно трещине в зеркале, обнажил уязвимость даже самых мощных многомодальных моделей. WorldVQA — не просто набор вопросов, а зонд, выявляющий не столько знания, сколько иллюзию знания. Модели, как умелые заклинатели, виртуозно жонглируют данными, но стоит лишь попросить о четком указании на предмет, как магия рассеивается, обнажая пустоту. Кажется, что способность «видеть» и «понимать» — это лишь искусно замаскированная способность к статистическому предсказанию, а не истинное постижение мира.
Следующим шагом, вероятно, станет не просто увеличение объёма обучающих данных, но и поиск способов заставить модели признавать собственную неопределенность. Калибровка — это не косметический дефект, а фундаментальная проблема, указывающая на неспособность моделей адекватно оценивать достоверность собственных ответов. Возможно, ключом окажется отказ от стремления к абсолютной точности и принятие неизбежной доли хаоса, присущей любой системе, взаимодействующей с реальностью.
В конечном итоге, истинная проверка ждёт впереди — когда эти модели столкнутся не с аккуратно собранными датасетами, а с грязной, противоречивой, непредсказуемой реальностью. И тогда станет ясно, что даже самое сложное заклинание не способно укротить шепот хаоса.
Оригинал статьи: https://arxiv.org/pdf/2602.02537.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-04 08:44