Автор: Денис Аветисян
Исследователи предлагают инновационную систему для распределённого обучения, объединяющую методы кластеризации и агрегации, оптимизированную для гибридных классическо-квантовых моделей.
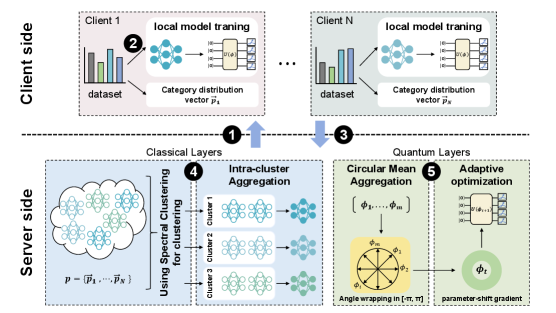
Представлен Fedcompass — фреймворк для федеративного обучения, использующий спектральную кластеризацию и круговое среднее для эффективной работы с неоднородными данными в гибридных системах.
Несмотря на перспективность федеративного обучения в условиях децентрализованных данных, его эффективность в гибридных классическо-квантовых моделях часто снижается при работе с неоднородными выборками. В данной работе представлена система ‘Fedcompass: Federated Clustered and Periodic Aggregation Framework for Hybrid Classical-Quantum Models’, предлагающая новый подход к агрегации параметров. Предложенная архитектура FEDCOMPASS использует спектральную кластеризацию для группировки клиентов и циклические средние для квантовых параметров, что позволяет повысить точность и стабильность обучения. Способно ли такое комбинирование методов обеспечить устойчивое развитие федеративного обучения в сложных квантово-классических системах?
Неидеальные данные: вызов федеративному обучению
Традиционные методы федеративного обучения (FL) основываются на предположении о независимом и одинаковом распределении данных (IID) между клиентами. Однако, в реальных сценариях это условие практически не выполняется. Например, данные, собранные с мобильных устройств пользователей, могут сильно отличаться в зависимости от их географического положения, интересов или демографических характеристик. Аналогично, медицинские учреждения в разных регионах могут специализироваться на различных заболеваниях, что приводит к несбалансированности данных. Эта гетерогенность данных создает значительные трудности для FL, поскольку модели, обученные на не-IID данных, могут демонстрировать существенное снижение производительности и предвзятость, ограничивая возможности практического применения федеративного обучения в разнообразных областях.
Неоднородность данных, или нарушение принципа независимого и одинакового распределения (Non-IID), является серьезной проблемой в федеративном обучении, приводящей к смещению модели и существенному снижению ее эффективности. Когда данные, хранящиеся на различных устройствах, значительно отличаются по своим характеристикам, глобальная модель, создаваемая в процессе обучения, теряет способность к обобщению и корректной работе на всех клиентах. Это явление, известное как «смещение модели», препятствует практическому внедрению федеративного обучения в реальных сценариях, где данные, как правило, распределены неравномерно и отражают индивидуальные особенности каждого пользователя или устройства. В результате, необходимо разрабатывать и применять специализированные методы, способные смягчить негативное влияние неоднородности данных и обеспечить стабильную производительность модели в гетерогенной среде.
Существующие методы федеративного обучения сталкиваются со значительными трудностями при работе с неоднородными распределениями данных, что препятствует созданию устойчивых и обобщенных моделей. В условиях, когда данные у каждого участника существенно отличаются по характеристикам и содержанию, стандартные алгоритмы, предполагающие независимое и одинаковое распределение (IID), демонстрируют существенное снижение производительности. Это связано с тем, что локальные обновления моделей, обусловленные спецификой данных каждого клиента, приводят к расхождению глобальной модели и ухудшению ее способности к обобщению на новые, ранее не встречавшиеся данные. В результате, глобальная модель может оказаться переобученной под конкретные особенности данных отдельных клиентов, что негативно сказывается на ее эффективности и надежности в реальных условиях эксплуатации. Поэтому, разработка новых подходов, способных эффективно справляться с гетерогенностью данных, является ключевой задачей для успешного внедрения федеративного обучения в практические приложения.
Fedcompass: гармония классики и квантов
Предлагаемый нами Fedcompass представляет собой многоуровневую структуру оптимизации агрегации для гибридного классическо-квантового федеративного обучения, разработанную специально для работы с неоднородными данными (Non-IID). Данная структура позволяет эффективно объединять локальные обновления моделей, обученных на различных клиентских устройствах, учитывая статистическую разницу в их данных. Fedcompass обеспечивает оптимизацию процесса агрегации, минимизируя влияние смещения, вызванного неоднородностью данных, и повышая общую производительность и обобщающую способность глобальной модели. Архитектура позволяет динамически адаптировать веса при агрегации, основываясь на характеристиках локальных данных каждого клиента, что существенно улучшает сходимость и точность модели в условиях Non-IID распределения данных.
В Fedcompass для извлечения признаков используются классические нейронные сети, такие как ResNet-18 и LeNet. Эти архитектуры применяются для предварительной обработки данных, поступающих от распределенных клиентов. Извлеченные признаки затем передаются в квантовый классификатор, предназначенный для улучшения распознавания закономерностей и повышения точности модели. Комбинация классических и квантовых методов позволяет эффективно обрабатывать сложные данные и повышать общую производительность системы, особенно в условиях неоднородности данных (Non-IID).
Гибридный подход, сочетающий классические вычисления и квантовую обработку информации, позволяет повысить обобщающую способность модели при работе с неоднородными клиентами. Использование классических нейронных сетей для извлечения признаков, в сочетании с квантовым классификатором, обеспечивает синергетический эффект. Классические вычисления эффективно обрабатывают большие объемы данных для первичного анализа, в то время как квантовый классификатор оптимизирует распознавание сложных паттернов, что особенно важно при работе с данными, распределенными между различными клиентами с отличающимися характеристиками. Такое сочетание позволяет модели лучше адаптироваться к разнородным данным и демонстрировать более высокую точность прогнозов в условиях не-IID (non-independent and identically distributed) данных.
Выравнивание клиентов: спектральный подход
В Fedcompass для группировки клиентов используется алгоритм спектральной кластеризации, основанный на оценке схожести распределений данных. В качестве ключевой метрики для измерения расхождения между распределениями применяется дивергенция Дженсена-Шеннона JSD(P||Q). Этот подход позволяет количественно оценить разницу между вероятностными распределениями данных, принадлежащими разным клиентам, и на основе этих оценок формировать группы клиентов со схожими характеристиками данных. Дивергенция Дженсена-Шеннона, будучи симметричной мерой, обеспечивает более устойчивую оценку схожести, чем асимметричные метрики, такие как дивергенция Кульбака-Лейблера.
Процесс кластеризации, управляемый критерием Normalized Cut, позволяет разработать более обоснованную стратегию агрегации данных. Normalized Cut стремится минимизировать разрыв между кластерами, одновременно максимизируя внутрикластерную схожесть, что приводит к формированию групп клиентов с наиболее однородными данными. Это особенно важно в условиях гетерогенных данных, когда прямое усреднение моделей, построенных на различных наборах данных, может привести к снижению производительности. Использование Normalized Cut позволяет снизить влияние выбросов и различий в распределениях данных между клиентами, обеспечивая более стабильную и точную глобальную модель в процессе федеративного обучения.
Выравнивание клиентов по схожим характеристикам данных в Fedcompass позволяет снизить смещение модели (model drift) и повысить общую производительность процесса федеративного обучения. Неоднородность данных между клиентами является ключевым фактором, вызывающим расхождения в локальных моделях и, как следствие, ухудшение глобальной модели. Группируя клиентов с близкими распределениями данных, Fedcompass обеспечивает более согласованное обновление глобальной модели, минимизируя влияние выбросов и специфических особенностей данных каждого клиента. Это приводит к более быстрой сходимости, повышенной точности и стабильности глобальной модели в течение всего процесса обучения.
Оптимизация квантовой агрегации параметров
Квантовые параметры, в отличие от классических, демонстрируют периодичность, обусловленную свойствами квантово-механических состояний. Эта периодичность создает специфические трудности при использовании федеративного обучения, поскольку наивное усреднение параметров от различных клиентов может приводить к неконсистентным результатам и дестабилизации процесса обучения. Возникающие расхождения обусловлены тем, что одинаковые физические значения могут быть представлены различными значениями параметров из-за периодичности, что приводит к смещению усредненного параметра. Для корректной агрегации необходимо применять специализированные методы, учитывающие эту периодичность и обеспечивающие согласованное обновление параметров на всех клиентах.
Для обеспечения точных и стабильных обновлений параметров в условиях федеративного обучения квантовых моделей используется метод циркулярного среднего (Circular Mean). В отличие от стандартного усреднения, которое может приводить к искажениям из-за периодичности квантовых параметров, циркулярное среднее оперирует с векторами, представленными в виде углов на единичной окружности. Это позволяет корректно учитывать фазовые соотношения и избежать проблем, связанных с «перескакиванием» через 2\pi. Формула для вычисления циркулярного среднего для набора углов {\theta_1, \theta_2, ..., \theta_n} выглядит следующим образом: \bar{\theta} = \arctan2(\sum_{i=1}^{n} \sin(\theta_i), \sum_{i=1}^{n} \cos(\theta_i)). Использование этого метода гарантирует, что агрегированные параметры сохраняют корректную ориентацию в квантовом пространстве состояний, что критически важно для сходимости и производительности обучения.
Использование оптимизатора Adam в сочетании с распределенной вычислительной платформой, такой как Ray, значительно повышает эффективность и масштабируемость обучения гибридных классическо-квантовых моделей. Adam обеспечивает адаптивную скорость обучения для каждого параметра, что ускоряет сходимость и улучшает качество получаемых моделей. Ray, в свою очередь, позволяет распараллелить процесс обучения на множество вычислительных узлов, эффективно распределяя нагрузку и обрабатывая большие объемы данных. Это позволяет обучать модели на значительно больших наборах данных и с использованием более сложных архитектур, чем было бы возможно на одном вычислительном устройстве. \nabla L(w) — градиент функции потерь, используемый Adam для обновления весов w .
Результаты и перспективы
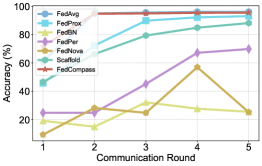
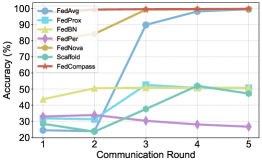
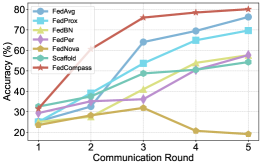
Экспериментальные результаты однозначно демонстрируют превосходство Fedcompass над современными методами федеративного обучения, включая такие алгоритмы, как FedAvg, FedProx, FedBN, FedPer, FedNova и Scaffold. Данное превосходство подтверждено на различных наборах данных, таких как MNIST, Fashion-MNIST и CIFAR-10, что указывает на устойчивость и обобщающую способность предложенного подхода. В ходе исследований установлено, что Fedcompass демонстрирует более высокую точность и эффективность в условиях децентрализованного обучения, обеспечивая значительный прирост производительности по сравнению с существующими решениями в данной области. Полученные данные свидетельствуют о перспективности использования Fedcompass для решения широкого спектра задач федеративного обучения, требующих высокой точности и надежности.
В ходе экспериментов, система Fedcompass продемонстрировала значительное превосходство в точности тестирования на наборе данных CIFAR-10. При значении параметра α, равном 0.3, достигнута точность в 77.00%, что на 10.22% выше, чем у широко используемого алгоритма FedAvg. Этот результат указывает на способность Fedcompass более эффективно обобщать данные и повышать надежность модели в условиях распределенного обучения, что особенно важно для сложных задач классификации изображений.
Экспериментальные результаты демонстрируют значительное превосходство Fedcompass в задачах классификации изображений. В частности, при использовании параметра α равного 0.7, точность тестирования на наборе данных CIFAR-10 достигла 80.10%, что на 3.80% выше, чем у широко используемого алгоритма FedAvg. Не менее впечатляющими оказались результаты на наборе данных MNIST, где Fedcompass приблизился к теоретическому пределу точности, достигнув показателя в 99.7%. Данные цифры свидетельствуют о высокой эффективности предложенного подхода и его потенциале для решения сложных задач машинного обучения в условиях федеративного обучения.
Разработанная платформа, основанная на инструментах Flower и PennyLane, демонстрирует перспективность интеграции классических и квантовых вычислений в контексте федеративного обучения. Использование квантовых алгоритмов позволяет значительно повысить устойчивость и эффективность процесса обучения, особенно при работе с распределенными данными, сохраняя при этом конфиденциальность. Такой подход открывает новые возможности для построения более надежных и производительных систем федеративного обучения, способных решать сложные задачи в различных областях, от обработки изображений до анализа медицинских данных. Сочетание преимуществ обеих вычислительных парадигм позволяет преодолеть ограничения традиционных методов и приблизиться к созданию интеллектуальных систем, способных обучаться на больших объемах данных, не нарушая при этом приватность пользователей.
Дальнейшие исследования будут сосредоточены на разработке адаптивных стратегий кластеризации, направленных на повышение эффективности алгоритма Fedcompass при работе с неоднородными данными. Особое внимание уделяется масштабируемости системы, чтобы обеспечить ее работоспособность с еще более крупными и сложными наборами данных. Планируется оптимизация алгоритмов кластеризации для динамической адаптации к изменяющимся характеристикам данных, что позволит снизить вычислительные затраты и повысить точность модели. Эти улучшения позволят расширить область применения Fedcompass, сделав его пригодным для решения задач в различных областях, требующих обработки больших объемов децентрализованных данных.
Исследование, представленное в данной работе, демонстрирует стремление к пониманию внутренней структуры данных, даже когда они распределены и неоднородны. Авторы предлагают Fedcompass — систему, которая, по сути, пытается разобрать сложный механизм на составные части, чтобы затем собрать его заново, но уже более эффективно. Это напоминает подход, который однажды сформулировал Пол Эрдёш: «Математика — это искусство находить закономерности в хаосе». Fedcompass, используя спектральное кластерирование для классических признаков и круговое среднее для квантовых параметров, как бы пытается выявить эти закономерности, несмотря на не-IID данные, что позволяет создавать более устойчивые и эффективные гибридные классическо-квантовые модели.
Что дальше?
Представленный подход, хоть и демонстрирует способность к адаптации в условиях неоднородных данных и гибридных вычислительных систем, лишь обнажает глубину нерешенных проблем. Утверждение о преодолении трудностей, связанных с не-IID данными, скорее напоминает временный патч, чем фундаментальное решение. Каждый новый алгоритм агрегации, как и каждый новый слой абстракции, неизбежно вносит собственные искажения, собственные «баги» в картину реальности. Истина, как известно, погребена под слоями оптимизаций.
Перспективы дальнейших исследований лежат в плоскости рекурсивного реверс-инжиниринга. Необходимо не просто разрабатывать новые методы агрегации, но и создавать инструменты для оценки степени искажения, вносимого каждым этапом обработки. Возможно, ключ к устойчивости лежит в отказе от централизованного агрегирования как такового, переходе к принципиально децентрализованным моделям, где каждый узел формирует собственное представление о реальности, а согласование происходит на уровне мета-данных, а не численных значений.
И, конечно, нельзя игнорировать философский аспект. Каждый патч — это молчаливое признание несовершенства системы, а стремление к идеальной модели — это утопия, обреченная на провал. Лучший хак — это осознание того, как всё работает, понимание ограничений и готовность к постоянной адаптации. Ведь в конечном итоге, реальность — это не то, что мы видим, а то, что мы можем взломать.
Оригинал статьи: https://arxiv.org/pdf/2602.03052.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-04 10:34