Автор: Денис Аветисян
Новая система, основанная на интеллектуальных агентах, способна самостоятельно извлекать данные из научных публикаций и формировать высокоточные базы данных для изучения ползучести материалов.
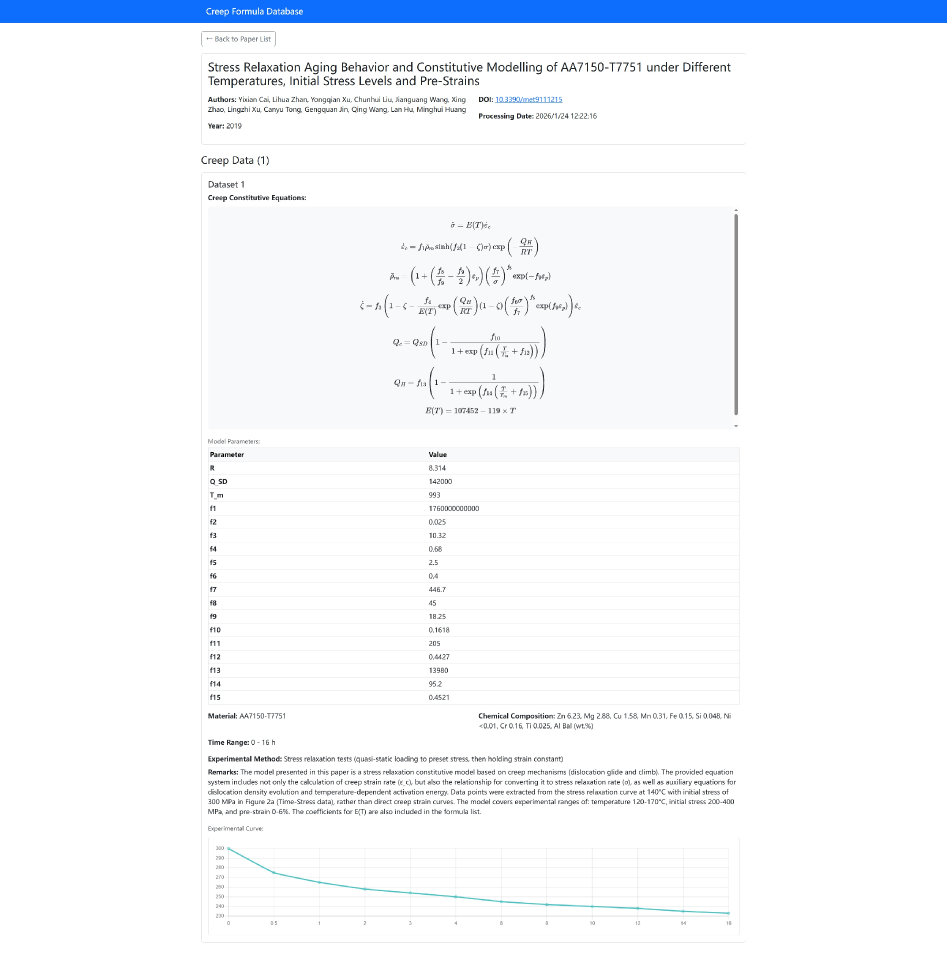
В статье представлен фреймворк, использующий агентов на базе больших языковых моделей и специализированные навыки для автоматического извлечения данных и преодоления проблемы нехватки данных в материаловедении.
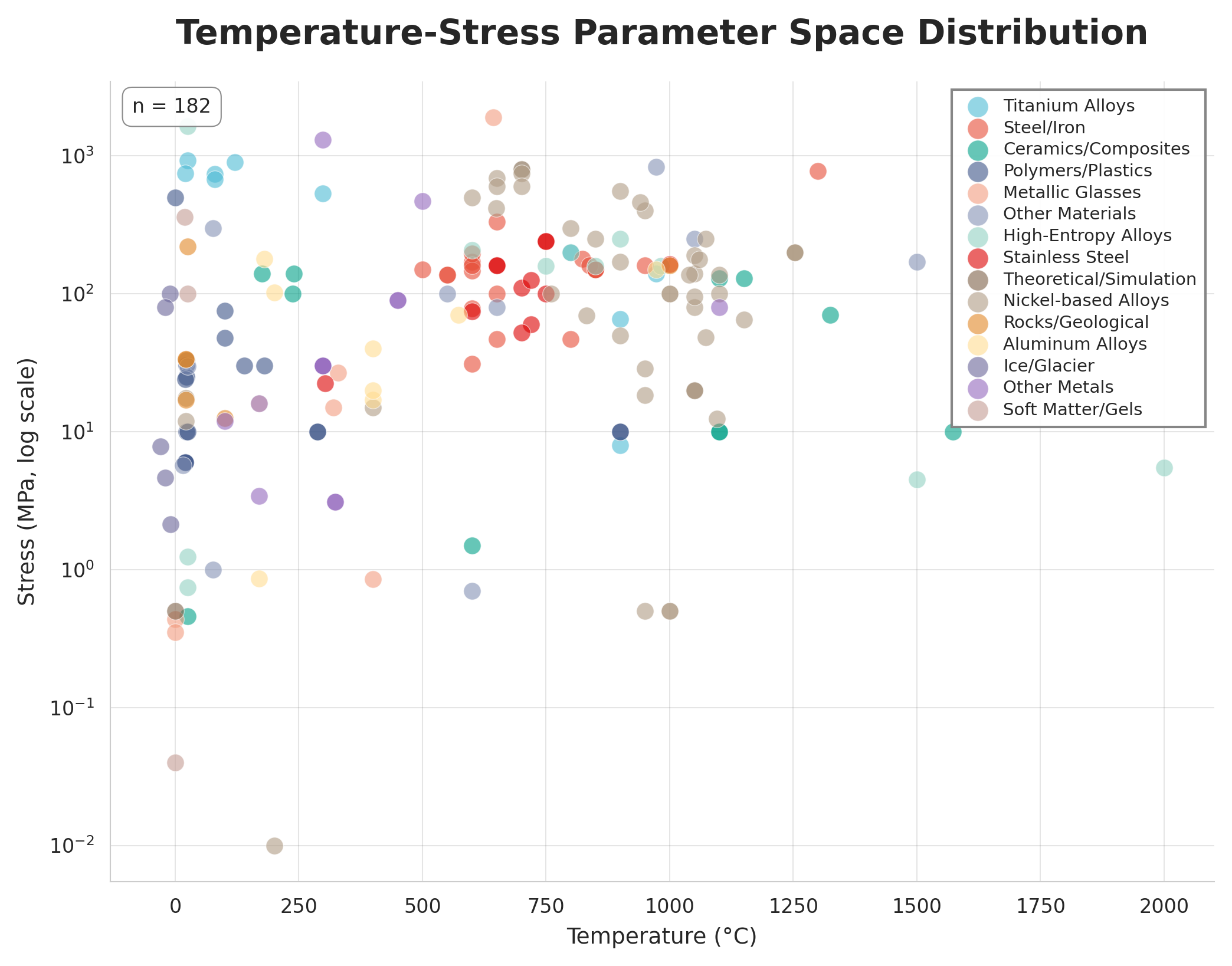
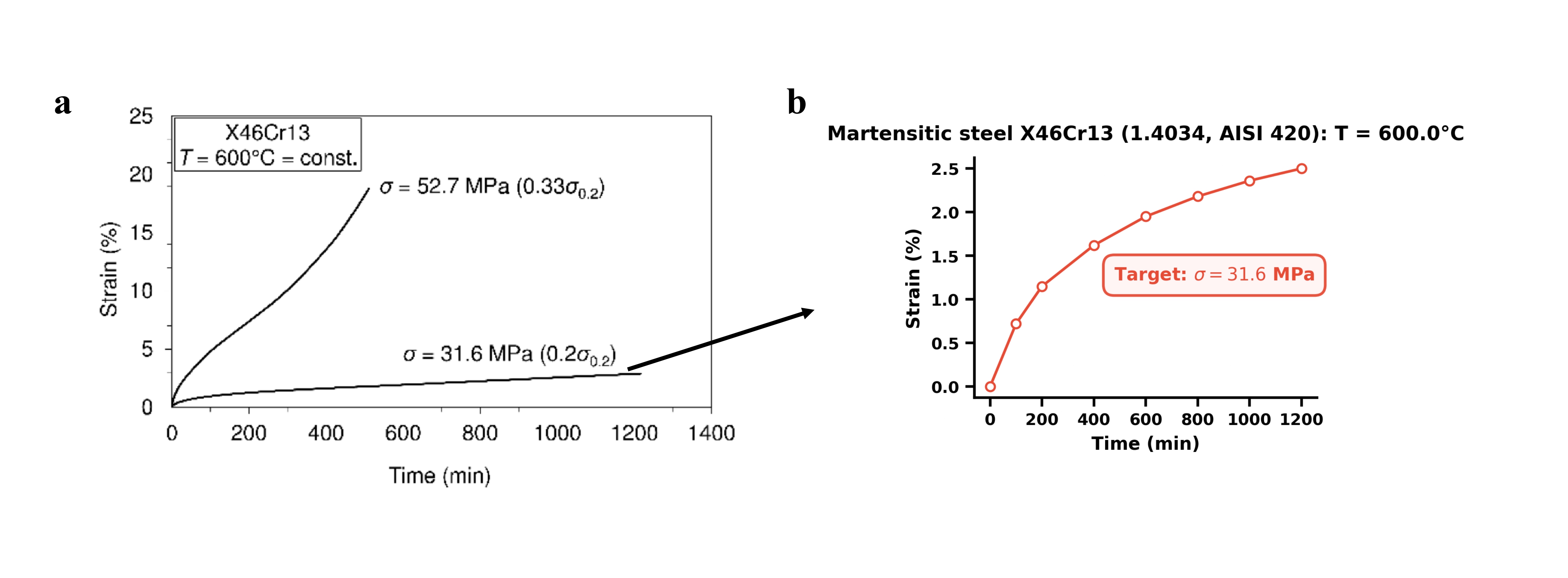
Несмотря на стремительное развитие материаловедения, значительная часть ценных экспериментальных данных остается заключенной в неструктурированных научных публикациях. В работе ‘Skill-Based Autonomous Agents for Material Creep Database Construction’ представлен инновационный подход к решению этой проблемы — автономный агент, основанный на больших языковых моделях (LLM) и модульной «skill-based» архитектуре, способный извлекать высококачественные данные из научных PDF-файлов без участия человека. Агент успешно построил физически согласованную базу данных для механики ползучести материалов, достигнув более 90% успешного извлечения графических данных и демонстрируя высокую корреляцию (R^2 > 0.99) между визуально и текстово извлеченными параметрами. Открывает ли это путь к созданию самообучающихся лабораторий и автоматизации процесса накопления знаний в материаловедении?
Преодолевая Информационный Тупик в Материаловедении
Традиционный процесс открытия новых материалов сталкивается с серьезным препятствием — так называемым «узким местом данных», заключающимся в ограниченном объеме структурированных, машиночитаемых данных. Исторически, информация о свойствах материалов и методах их получения часто фиксировалась в неформальном виде — в научных статьях, отчетах и лабораторных журналах, что затрудняет автоматизированный анализ и извлечение полезных сведений. Этот дефицит качественных данных существенно замедляет применение методов искусственного интеллекта и машинного обучения для предсказания свойств материалов, моделирования их поведения и, в конечном итоге, ускорения разработки новых, более совершенных материалов с заданными характеристиками. По сути, отсутствие легкодоступной и структурированной информации становится основным ограничивающим фактором в современной материаловедении.
Существующие методы анализа научной литературы сталкиваются с серьезными трудностями при извлечении полезной информации из огромного объема неструктурированных данных. Большая часть знаний о материалах содержится в научных статьях, отчетах и патентах, представленных в виде текста, таблиц и графиков, что требует значительных усилий для автоматической обработки. Традиционные подходы, такие как ручной сбор данных и основанный на правилах анализ, крайне неэффективны и не масштабируемы. Автоматическое извлечение информации, использующее методы обработки естественного языка, часто терпит неудачу из-за неоднозначности языка, разнообразия форматов представления данных и отсутствия стандартизации терминологии. В результате, ценные сведения о свойствах материалов, методах синтеза и взаимосвязях между структурой и функциональными характеристиками остаются скрытыми, замедляя процесс открытия и разработки новых материалов.
Ограниченность доступных данных существенно замедляет внедрение искусственного интеллекта в область материаловедения и разработки новых материалов. Несмотря на потенциал алгоритмов машинного обучения для прогнозирования свойств материалов и оптимизации их состава, недостаток структурированных и верифицированных данных становится критическим препятствием. Эффективное обучение моделей требует больших объемов информации, а извлечение знаний из разрозненных научных публикаций и отчетов — трудоемкий и ресурсозатратный процесс. В результате, возможности ИИ для ускорения материаловедческих инноваций остаются нереализованными, что сдерживает прогресс в различных областях, от энергетики до медицины. Преодоление этой информационной блокады является ключевой задачей для раскрытия полного потенциала искусственного интеллекта в материаловедении.
Автономные Агенты: Новый Взгляд на Научные Открытия
Предлагается фреймворк, использующий автономных агентов, функционирующих на базе больших языковых моделей, таких как Qwen3-235B-A22B, для автоматизации извлечения данных. В рамках данной системы, агенты способны самостоятельно анализировать научные тексты и извлекать релевантную информацию без непосредственного участия человека. Модель Qwen3-235B-A22B обеспечивает высокую производительность в задачах обработки естественного языка, необходимую для точного и эффективного извлечения данных из сложных научных документов. Автономность агентов достигается за счет использования механизмов планирования и выполнения действий, позволяющих им итеративно исследовать текст и идентифицировать требуемые данные.
Парадигма ReAct (Reason + Act) позволяет агентам, основанным на больших языковых моделях, взаимодействовать с внешними инструментами и итеративно уточнять понимание сложных научных текстов. В рамках этой парадигмы, агент чередует фазы рассуждения (Reasoning), где формулирует промежуточные выводы и планирует дальнейшие действия, и фазы действия (Acting), где использует внешние инструменты, такие как поисковые системы или базы данных, для получения дополнительной информации. Результаты действий затем анализируются и используются для уточнения рассуждений, формируя замкнутый цикл, который позволяет агенту последовательно углублять свое понимание текста и извлекать из него необходимые данные. Этот итеративный процесс позволяет агенту эффективно справляться с неоднозначностью и сложностью научных текстов, а также адаптироваться к новым данным и контексту.
Архитектура, основанная на навыках (Skill-Based Architecture), предполагает декомпозицию сложной задачи автоматизированного извлечения данных на отдельные, специализированные модули — «навыки агента» (Agent Skill). Каждый модуль отвечает за выполнение конкретной подзадачи, например, поиск информации, анализ текста или форматирование результатов. Такой подход обеспечивает повышенную модульность системы, упрощая разработку, тестирование и отладку отдельных компонентов. Кроме того, декомпозиция способствует масштабируемости, позволяя добавлять новые навыки или улучшать существующие без внесения изменений в остальную часть системы. Использование отдельных навыков также способствует повторному использованию кода и повышению эффективности работы агента.
Автоматизированный Конвейер: Извлечение и Валидация Знаний
Начальный этап конвейера обработки научной литературы включает в себя сбор публикаций из различных источников и автоматизированный отбор релевантных материалов. Сбор литературы осуществляется посредством систематического поиска в научных базах данных, цифровых библиотеках и открытых репозиториях. Автоматизированный отбор использует алгоритмы обработки естественного языка и машинного обучения для фильтрации публикаций на основе заданных критериев, таких как ключевые слова, темы исследований и цитируемость. Этот этап позволяет существенно сократить объем обрабатываемой информации, фокусируясь на наиболее значимых и соответствующих задачам исследования публикациях.
Для извлечения данных из научных текстов используется комбинация инструментов: \text{MatScholar} и \text{ChemDataExtractor}. Первый предназначен для автоматического извлечения химической информации, такой как названия соединений, реакции и свойства, из текстовых публикаций. \text{ChemDataExtractor}, в свою очередь, специализируется на извлечении химических структур и данных, представленных в текстовом формате. Для обработки данных, представленных в виде изображений, таких как графики, диаграммы и схемы, применяется технология оптического распознавания символов (OCR), позволяющая преобразовать визуальную информацию в машиночитаемый текст и, далее, извлечь из него необходимые данные.
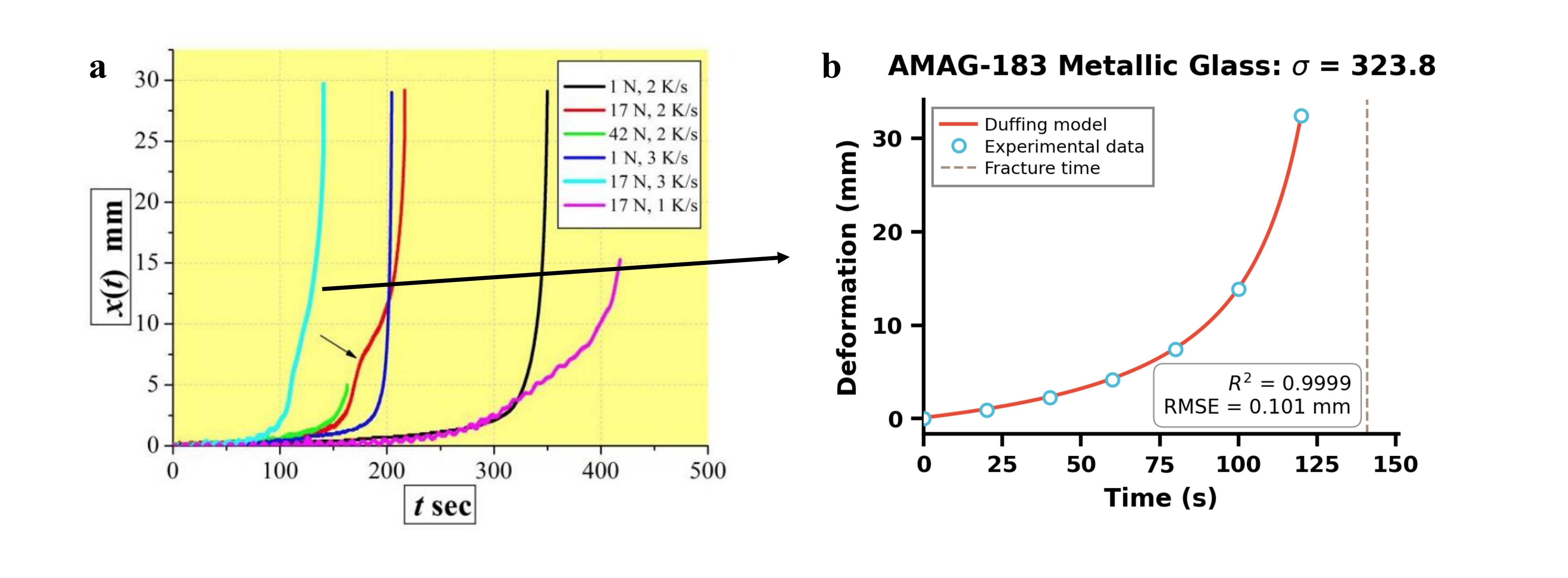
Извлеченная информация подвергается многомодальной обработке, включающей анализ данных, полученных из различных источников, таких как текст и изображения. Для верификации формул используется инструмент Duffing Oscillator, позволяющий оценить соответствие извлеченных формул известным физическим законам и моделям. Качество валидации оценивается с помощью метрики R-squared, отражающей степень объяснения дисперсии данных моделью, что позволяет количественно оценить надежность извлеченных и проверенных формул. Высокое значение R-squared указывает на более точную и надежную валидацию, в то время как низкое значение может потребовать дополнительной проверки и коррекции извлеченных данных. R^2 является ключевым показателем для оценки адекватности валидации формул.
Структурированные Знания для Ускоренного Дизайна Материалов
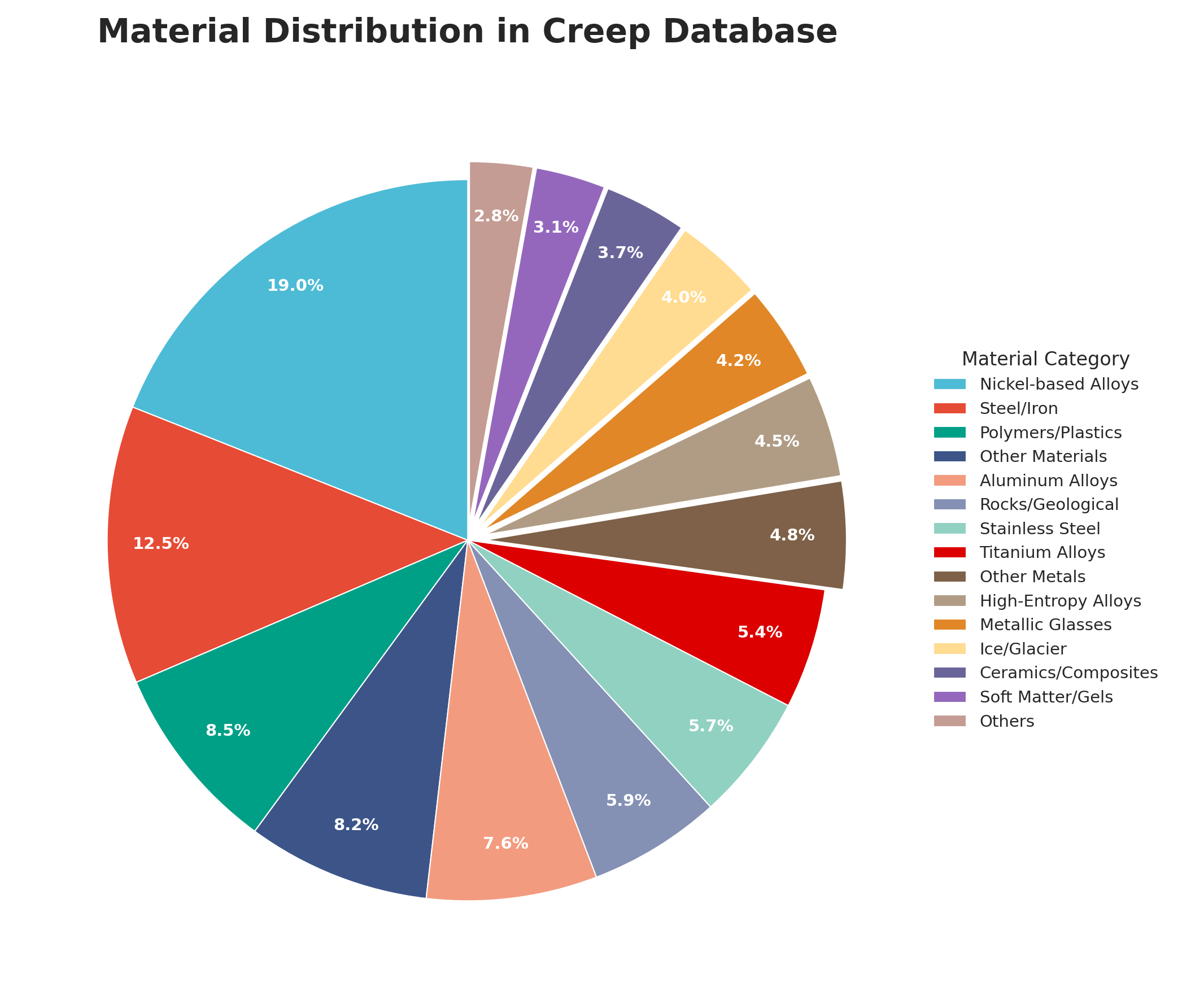
Извлеченные данные аккумулируются в структурированном хранилище — реляционной базе данных, что позволяет эффективно организовать и анализировать информацию о материалах. Особое внимание уделяется отслеживанию происхождения данных: для каждой записи используется ‘Digital Object Identifier’ (DOI), гарантирующий надежную идентификацию источника и обеспечивающий возможность верификации и воспроизводимости результатов. Такая организация, в отличие от работы с неструктурированными данными, значительно ускоряет процесс поиска и сопоставления информации, создавая прочную основу для дальнейшего применения методов машинного обучения и моделирования, направленных на ускорение открытия новых материалов с заданными характеристиками.
Структурированное хранение данных позволяет эффективно извлекать и анализировать накопленные знания о материалах, что принципиально отличает данный подход от работы с неструктурированной информацией. В отличие от традиционных методов, где поиск релевантных данных затруднен из-за их разрозненности и отсутствия четкой организации, данная система обеспечивает быстрый доступ к необходимым параметрам и взаимосвязям. Это достигается за счет использования реляционной базы данных, где информация представлена в виде структурированных таблиц, что позволяет задавать сложные запросы и оперативно получать результаты. Такой подход не только ускоряет процесс анализа, но и повышает точность полученных выводов, открывая новые возможности для целенаправленного дизайна материалов с заданными свойствами.
Предложенная структура данных открывает возможности для применения методов символьной регрессии и нейронных сетей, учитывающих физические законы. Символьная регрессия, в отличие от традиционного машинного обучения, стремится выявить аналитические зависимости между параметрами материала и его свойствами, предоставляя не просто предсказания, но и формулы, описывающие наблюдаемые явления. В свою очередь, нейронные сети, «обогащенные» физическими принципами, способны обучаться на меньшем объеме данных и демонстрируют повышенную устойчивость к шумам и экстраполяции. Такое сочетание позволяет значительно ускорить процесс открытия новых материалов с заданными характеристиками, минимизируя необходимость дорогостоящих экспериментов и оптимизируя поиск перспективных соединений. E = mc^2 — пример фундаментальной зависимости, которую подобные модели могут воспроизводить и расширять, адаптируясь к сложным материаловедческим задачам.
К Самообучающейся Экосистеме Научных Открытий
Автоматизация процесса извлечения знаний открывает новые возможности для ускорения научного прогресса. Вместо традиционного ручного анализа огромных массивов научной литературы, система, способная самостоятельно выявлять закономерности, связи и ключевые факты, позволяет значительно сократить время, необходимое для получения новых результатов. Такой подход не только упрощает работу исследователей, но и позволяет обнаруживать неочевидные взаимосвязи, которые могли бы остаться незамеченными при ручном анализе. В результате, гипотезы формируются быстрее, исследования проводятся эффективнее, а темпы научного открытия экспоненциально возрастают, создавая благоприятную среду для инноваций и прорывных открытий в различных областях науки.
Предложенная система, изначально разработанная для анализа научной литературы, обладает потенциалом к расширению на другие области знаний, формируя самообучающуюся научную экосистему. Принцип автоматического извлечения знаний и установления связей между данными может быть адаптирован для обработки информации в медицине, инженерии, материаловедении и других дисциплинах. Это позволит создавать базы знаний, способные самостоятельно выявлять закономерности, генерировать гипотезы и предлагать новые направления исследований, значительно ускоряя процесс накопления и применения знаний. В перспективе, такая система может стать ключевым инструментом для решения сложных научных задач, требующих анализа огромных объемов разнородной информации и выявления неочевидных взаимосвязей.
Дальнейшие исследования направлены на углубление способностей агента к анализу научной информации, что включает в себя совершенствование алгоритмов извлечения знаний и повышение точности валидации данных. Особое внимание уделяется интеграции системы с источниками экспериментальных данных, что позволит не только анализировать опубликованные результаты, но и автоматически обрабатывать информацию, полученную непосредственно из экспериментов. Это позволит создать замкнутый цикл научного открытия, где система самостоятельно формулирует гипотезы, проверяет их на экспериментальных данных и, на основе полученных результатов, генерирует новые направления исследований, значительно ускоряя темпы научного прогресса.
Исследование демонстрирует, что создание специализированных навыков для агентов, основанных на больших языковых моделях, позволяет преодолеть ограничения в построении научных баз данных. Этот подход, позволяющий автономно извлекать данные из научной литературы, напоминает о словах Алана Тьюринга: «Можно считать, что машина думает, если она способна имитировать интеллект человека». В данном случае, агенты, обученные конкретным навыкам, имитируют процесс анализа и извлечения информации, свойственный исследователю-материаловеду. Создание такой системы, как показано в статье, открывает возможности для автоматизации трудоёмкого процесса сбора и структурирования данных о ползучести материалов, устраняя давний ‘узкий участок’ в материаловедении и позволяя сосредоточиться на более глубоком анализе и открытиях.
Что дальше?
Представленная работа, по сути, взламывает устоявшуюся систему сбора данных в материаловедении. Однако, стоит задуматься: что произойдёт, если автоматизированный сбор информации станет настолько эффективным, что начнёт генерировать новые парадоксы? Если система, лишенная человеческой интуиции, обнаружит закономерности, которые окажутся ложными, но статистически значимыми? Очевидно, что ключевой задачей становится не только извлечение данных, но и разработка механизмов для критической оценки полученных результатов, способных выявлять артефакты и нефизичные корреляции.
Архитектура, основанная на специализированных навыках агентов, открывает путь к созданию систем, способных не просто собирать информацию, но и формировать гипотезы. Но что, если эти гипотезы окажутся слишком узкими, ограниченными рамками заданных навыков? Следующим шагом видится переход к системам, способным к самообучению и адаптации навыков, к построению моделей, которые смогут самостоятельно определять, какие данные наиболее важны и как их интерпретировать. Другими словами, необходимо создавать агентов, способных к «неудобным» вопросам.
В конечном счете, успех подобного подхода зависит не только от совершенствования алгоритмов, но и от понимания фундаментальных ограничений автоматизации научного поиска. Можно ли полностью автоматизировать процесс открытия? Или всегда будет существовать потребность в человеческом разуме, способном к творческому мышлению и интуитивным прозрениям? Этот вопрос остаётся открытым, и ответ на него, возможно, станет определяющим для будущего материаловедения.
Оригинал статьи: https://arxiv.org/pdf/2602.03069.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-04 12:06