Автор: Денис Аветисян
Исследователи представляют AdaptMMBench — комплексную платформу для оценки способности моделей, объединяющих зрение и язык, к адаптивному выбору стратегий решения задач.

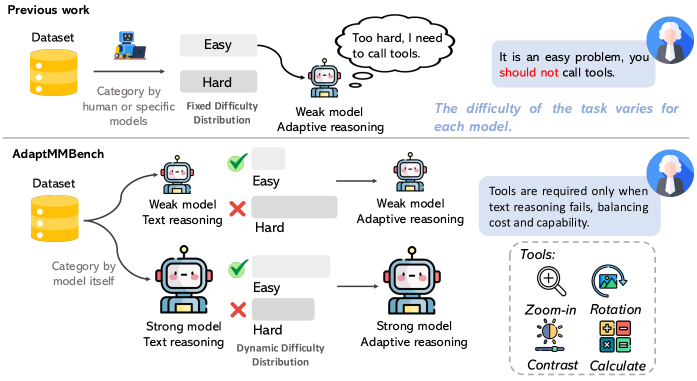
Представлен новый бенчмарк AdaptMMBench для оценки адаптивного мультимодального рассуждения и выбора режима работы моделей, использующих как текстовые, так и визуальные инструменты.
Существующие методы оценки моделей, основанные на фиксированных метриках сложности, зачастую не отражают динамическую природу адаптивного мультимодального мышления. В данной работе представлена платформа ‘AdaptMMBench: Benchmarking Adaptive Multimodal Reasoning for Mode Selection and Reasoning Process’, предназначенная для всесторонней оценки способности моделей выбора оптимальной стратегии рассуждений — текстового анализа или использования визуальных инструментов. Платформа позволяет не только измерять рациональность выбора режима, но и анализировать эффективность использования инструментов и покрытия ключевых этапов решения задачи, выявляя зависимость между адаптивностью и конечным результатом. Сможет ли AdaptMMBench стимулировать разработку действительно интеллектуальных систем, способных к гибкому и эффективному решению сложных задач?
Визуально-языковые модели: вызов адаптивного рассуждения
Визуально-языковые модели (ВЯМ) становятся все более важным компонентом современных систем искусственного интеллекта, однако демонстрируют ограниченные возможности при решении сложных задач, требующих одновременного понимания как визуальной, так и текстовой информации. Несмотря на значительный прогресс в области машинного обучения, ВЯМ часто испытывают трудности с выполнением задач, подразумевающих многоступенчатые рассуждения, анализ контекста и выявление скрытых связей между изображением и текстом. Эта проблема особенно актуальна в сценариях, где требуется не просто распознавание объектов на изображении или понимание смысла текста, а комплексный анализ и интерпретация взаимосвязанных данных, что ограничивает их применение в более сложных и реалистичных приложениях, таких как автономные системы или интеллектуальные помощники.
Традиционные модели, объединяющие зрение и язык, зачастую полагаются на единый, предопределённый путь рассуждений, что существенно ограничивает их возможности в решении разнообразных задач. Вместо того, чтобы динамически адаптироваться к конкретным требованиям каждой ситуации, такие модели применяют один и тот же алгоритм анализа, независимо от сложности или специфики входных данных. Это приводит к снижению эффективности при обработке неоднозначной информации, требует избыточных вычислительных ресурсов и препятствует достижению оптимальных результатов в сценариях, требующих гибкого подхода к рассуждениям. В результате, даже относительно небольшие изменения в характере задачи могут вызвать значительное падение производительности, подчеркивая необходимость разработки более адаптивных систем, способных выбирать наиболее подходящий метод анализа в зависимости от контекста.
Для эффективной обработки мультимодальной информации требуется переход к адаптивному рассуждению — динамическому выбору оптимального подхода в зависимости от поставленной задачи. Вместо использования единого, фиксированного алгоритма, современные модели стремятся оценивать характеристики входных данных — как визуальных, так и текстовых — и, основываясь на этом анализе, активировать наиболее подходящий механизм логического вывода. Это позволяет им гибко реагировать на разнообразие запросов, избегать неэффективных вычислений и демонстрировать более высокую точность в сложных сценариях, где требуется интеграция информации из различных источников. Такой подход имитирует когнитивные способности человека, который также адаптирует стратегию решения задачи в зависимости от её специфики и доступных данных.
AdaptMMBench: строгий фреймворк для оценки адаптивности
AdaptMMBench — это новый оценочный набор данных, предназначенный для анализа адаптивного мультимодального рассуждения в визуально-языковых моделях (VLM) в различных сложных областях. Он разработан для систематической оценки способности моделей эффективно использовать и интегрировать информацию из нескольких модальностей (текст и изображения) при решении задач, требующих адаптации к новым условиям и типам вопросов. Набор данных включает в себя разнообразные сценарии, позволяющие оценить не только базовые возможности моделей, но и их способность к обобщению и адаптации к новым задачам, что критически важно для развития надежных и универсальных VLM.
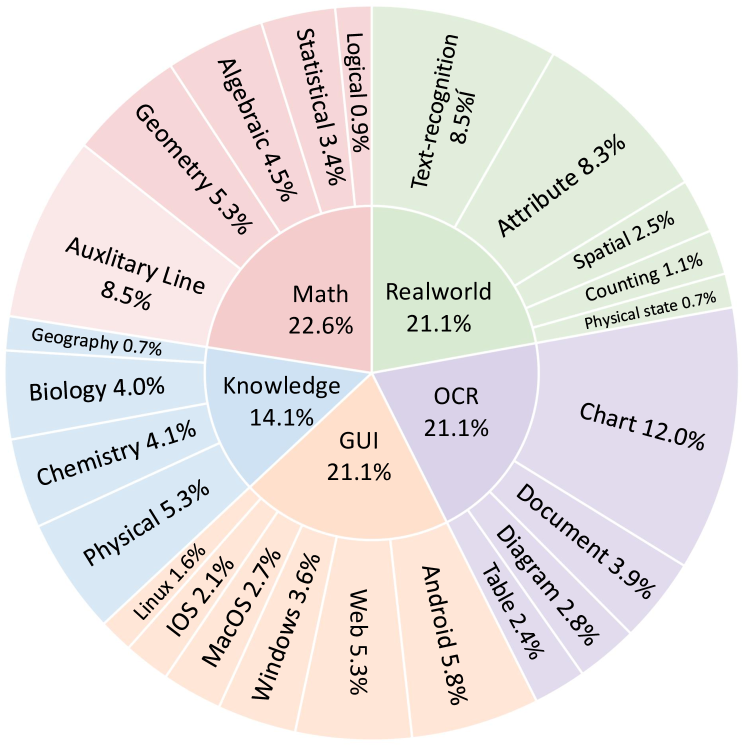
Бенчмарк AdaptMMBench включает в себя разнообразные задачи, охватывающие несколько ключевых областей визуально-вопросно-ответного поиска (VQA). К ним относятся задачи, требующие обработки текстов, содержащихся в изображениях (Text-Rich VQA), использование внешних знаний для ответа на вопросы (Knowledge VQA), анализ изображений реального мира (Real-World VQA), решение математических задач на основе визуальной информации (Math VQA) и взаимодействие с графическим интерфейсом пользователя (GUI VQA). Такое разнообразие позволяет комплексно оценить способность моделей к адаптивному мультимодальному рассуждению и обобщению знаний в различных сценариях.
Оценка моделей визуально-языковых моделей (VLM) в различных областях, таких как вопросы и ответы с богатым текстом, вопросы и ответы, требующие знаний, вопросы и ответы о реальном мире, математические вопросы и ответы, а также вопросы и ответы о графическом интерфейсе пользователя (GUI), позволяет комплексно оценить их способность к обобщению и адаптации к новым задачам рассуждения. Использование разнообразных доменов гарантирует, что производительность модели не будет переоценена из-за специализации на конкретном типе данных или задаче, а будет отражать её общую способность к решению проблем, требующих комбинирования визуальной и текстовой информации.
Количественная оценка качества рассуждений: метрики адаптивной производительности
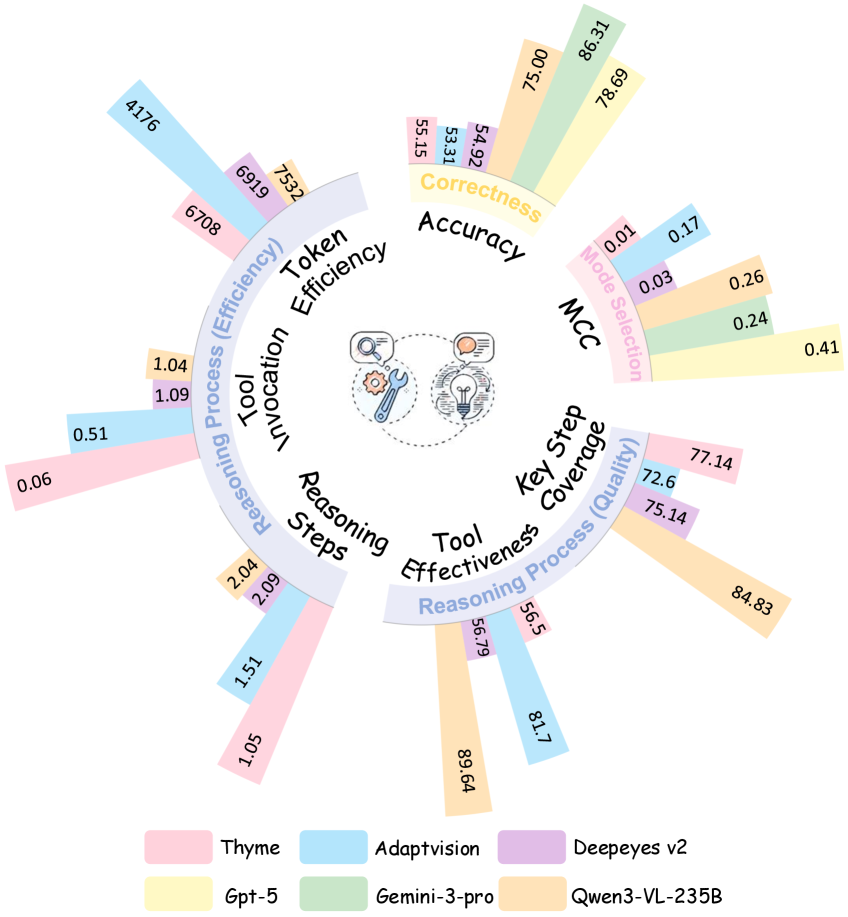
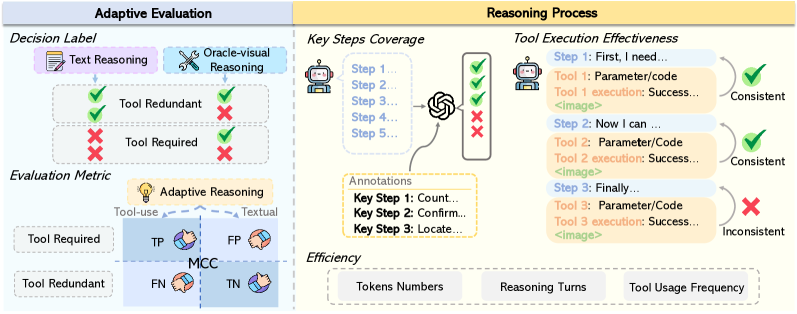
AdaptMMBench использует метрику «Покрытие ключевых шагов» (Key Step Coverage) для оценки соответствия хода рассуждений модели человеческим аннотациям ключевых этапов решения задачи. Данная метрика позволяет определить, насколько логически последовательны действия модели при достижении ответа. Оценка производится путем сопоставления шагов, предпринятых моделью, с заранее определенными экспертами ключевыми шагами, необходимыми для корректного решения. Высокое значение покрытия ключевых шагов указывает на то, что модель следует логически обоснованному пути, что является важным критерием оценки качества рассуждений, особенно в задачах, требующих сложных логических выводов и анализа.
Эффективность выполнения инструментов (Tool Execution Effectiveness) оценивает семантическую корректность и уместность вызовов инструментов, что является критически важным аспектом в задачах визуального рассуждения, дополненного использованием инструментов. Данная метрика измеряет, насколько правильно и целесообразно модель выбирает и применяет доступные инструменты для решения поставленной задачи. Оценка включает проверку соответствия вызовов инструментов логической структуре решения и фактической необходимости их применения для получения корректного ответа. Низкое значение метрики указывает на проблемы с выбором инструментов или некорректную интерпретацию результатов их работы, что негативно сказывается на общей производительности системы.
Коэффициент корреляции Мэтьюса (MCC) используется для оценки качества выбора адаптивного режима работы модели. В ходе тестирования с GPT-5 был получен показатель MCC, равный 0.41. Данное значение свидетельствует о хорошей способности модели правильно определять оптимальный режим работы в различных ситуациях, что подтверждает эффективность механизма адаптации к изменяющимся условиям и задачам. Высокий показатель MCC указывает на сбалансированную производительность модели в задачах, требующих выбора между различными стратегиями решения.
Результаты тестирования на AdaptMMBench демонстрируют существенную разницу в производительности модели GPT-5 в адаптивном режиме (точность 78.69%) по сравнению с режимом «oracle-visual» (точность 90.08%). Данный разрыв указывает на потенциальные возможности для оптимизации стратегий вызова инструментов и улучшения адаптивности модели к различным задачам визуального рассуждения. Анализ результатов позволяет предположить, что более эффективное использование инструментов может значительно повысить общую точность модели в реальных условиях, где заранее заданный «oracle» недоступен.
Данные и методы: фундамент для оценки
Для оценки адаптивного мультимодального рассуждения AdaptMMBench использует существующие наборы данных и методологии, специализированные для каждой области. Для задач VQA с текстом и графиками применяются ChartQA и DocVQA, обеспечивающие анализ визуальной информации в контексте текстовых данных. Оценка знаний осуществляется с использованием SciVerse и MMMU, позволяющих проверить способность моделей к пониманию и применению научных знаний. Для задач VQA, связанных с реальным миром, используется Visual Probe, предназначенный для оценки понимания визуальных сцен и взаимодействия объектов в них. Использование этих проверенных наборов данных гарантирует надежность и сопоставимость результатов оценки.
Набор тестов AdaptMMBench предоставляет стандартизированную и воспроизводимую основу для оценки адаптивного мультимодального рассуждения. Это достигается за счет четкого определения протоколов оценки и использования общедоступных наборов данных, что позволяет исследователям независимо воспроизводить результаты и сравнивать производительность различных моделей на единой платформе. Стандартизация включает в себя унифицированные метрики оценки и процедуры обработки данных, что минимизирует влияние субъективных факторов и обеспечивает объективную оценку возможностей моделей в области мультимодального анализа.
Использование разнообразных и устоявшихся бенчмарков, таких как ChartQA, DocVQA, SciVerse, MMMU и Visual Probe, обеспечивает обобщаемость и надёжность результатов оценки. Применение этих стандартизированных наборов данных позволяет протестировать модели адаптивного мультимодального рассуждения в различных сценариях и областях, минимизируя риск переобучения на специфичных данных. Это, в свою очередь, повышает уверенность в том, что полученные результаты оценки отражают истинные возможности модели и могут быть применены к новым, ранее не встречавшимся данным, а также обеспечивает возможность справедливого сравнения различных моделей.
Перспективы развития: к более разумным мультимодальным системам
Разработка AdaptMMBench представляет собой важный шаг на пути к созданию более надежных и адаптируемых моделей, объединяющих зрение и язык. Эта платформа призвана оценить способность моделей эффективно справляться со сложными задачами, возникающими в реальном мире, где данные могут быть неполными, неоднозначными или подвержены изменениям. Акцент делается на проверке не просто способности распознавать объекты на изображениях и понимать текст, но и на умении модели адаптироваться к новым ситуациям и применять полученные знания для решения нестандартных задач. Таким образом, AdaptMMBench способствует развитию искусственного интеллекта, способного к гибкому и эффективному взаимодействию с окружающим миром, что открывает новые перспективы для широкого спектра приложений, от автономных систем до интеллектуальных помощников.
В дальнейшем планируется существенное расширение AdaptMMBench за счет включения более разнообразных областей знаний и задач, требующих сложного логического мышления. Это позволит не только проверить существующие Визуально-Языковые Модели (VLM) в новых условиях, но и стимулировать разработку новых алгоритмов, способных к адаптации и решению более сложных проблем. Расширение охватит не только увеличение объема данных, но и включение задач, требующих понимания контекста, здравого смысла и способности к абстрактному мышлению, что, в конечном итоге, позволит создать более интеллектуальные и универсальные системы искусственного интеллекта, способные к эффективному взаимодействию с реальным миром.
Развитие адаптивного мультимодального рассуждения, стимулируемое платформой AdaptMMBench, открывает перспективы для создания более интеллектуальных и универсальных систем искусственного интеллекта. Данный подход позволяет моделям не просто обрабатывать информацию из различных источников — зрения и языка — но и гибко адаптироваться к новым задачам и доменам, демонстрируя способность к обобщению и переносу знаний. Благодаря этому, будущие ИИ-системы смогут более эффективно взаимодействовать с окружающим миром, понимать сложные запросы и решать разнообразные проблемы, приближая эру действительно разумных машин, способных к самостоятельному обучению и творческому мышлению.
Представленный труд демонстрирует неизбежную эволюцию систем обработки информации. Авторы предлагают AdaptMMBench — инструмент для оценки способности моделей выбирать оптимальный подход к решению задач — текстовое рассуждение или использование визуальных инструментов. Это напоминает о фундаментальной истине: любая архитектура, даже самая элегантная, рано или поздно сталкивается с необходимостью адаптации к реальным условиям. Как метко заметил Дэвид Марр: «Интеллект — это не магия, а набор вычислительных механизмов». Иными словами, способность выбирать подходящий инструмент — это не прорыв, а скорее эволюционный шаг, обусловленный вычислительными ограничениями и необходимостью оптимизации ресурсов. Продюсер всегда найдёт способ заставить систему работать, даже если это потребует дополнительных «костылей».
Что дальше?
Представленный в работе набор данных AdaptMMBench, безусловно, фиксирует важный момент: способность моделей к выбору инструментария для рассуждений. Однако, не стоит обольщаться иллюзией «интеллектуального» выбора. Скорее, это просто очередная функция потерь, которую рано или поздно найдут способ обойти, оптимизируя модель под конкретный набор тестов. Архитектура, в конце концов, — это не схема, а компромисс, переживший деплой.
Более глубокая проблема заключается не в самом выборе инструмента, а в его адекватности. Модель может «выбрать» визуальный инструмент, но интерпретация полученных данных остаётся узким местом. Ведь, что есть визуальное рассуждение, как не преобразование одной формы шума в другую? И рано или поздно, всё, что оптимизировано, оптимизируют обратно, добавляя ещё один уровень абстракции, ещё больше шума.
Перспективы? Вероятно, нас ждёт бесконечный цикл: новые бенчмарки, новые архитектуры, новые способы обхода ограничений. Мы не рефакторим код — мы реанимируем надежду. И, возможно, в конечном итоге, придётся признать, что самое сложное — это не научить машину рассуждать, а смириться с тем, что она рассуждает иначе, чем мы.
Оригинал статьи: https://arxiv.org/pdf/2602.02676.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-04 13:45