Автор: Денис Аветисян
Исследователи предлагают метод, который позволяет создавать сложные задачи для обучения больших языковых моделей, разбивая процесс на последовательность взаимосвязанных навыков.
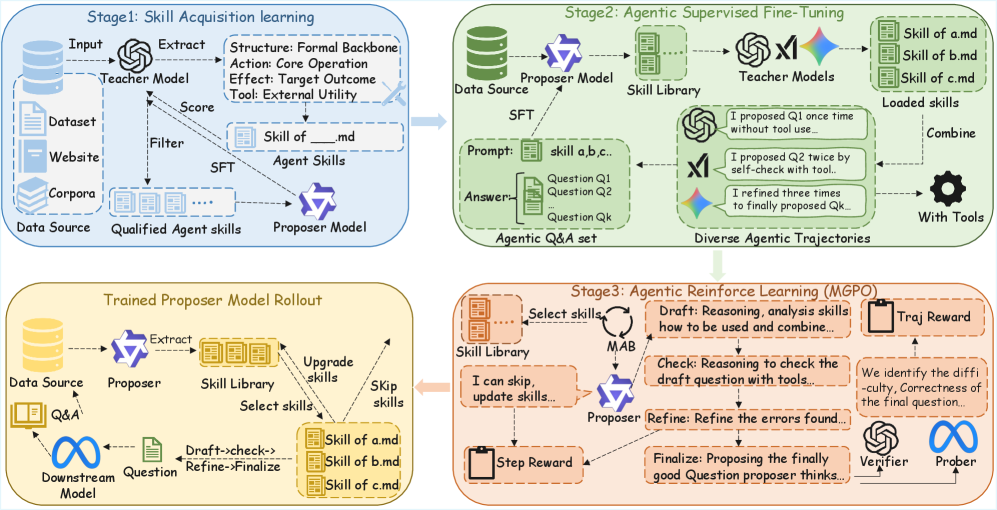
Предлагаемый фреймворк Agentic Proposing синтезирует сложные задачи, используя композицию навыков и обучение с подкреплением для повышения эффективности обучения и производительности моделей.
Современные подходы к повышению сложности рассуждений в больших языковых моделях часто сталкиваются с компромиссом между структурной корректностью и сложностью решаемых задач. В работе ‘Agentic Proposing: Enhancing Large Language Model Reasoning via Compositional Skill Synthesis’ предложен фреймворк Agentic Proposing, моделирующий синтез задач как последовательный процесс принятия решений, где агент динамически выбирает и компонует модульные навыки рассуждения. Разработанный на основе оптимизации политики мульти-гранулярности \mathcal{N}=4, Agentic-Proposer позволяет генерировать высокоточные и верифицируемые траектории обучения в областях математики, программирования и естественных наук. Может ли небольшой объем синтетических данных, сгенерированных таким образом, эффективно заменить огромные массивы размеченных вручную данных и обеспечить сопоставимую производительность даже с проприетарными моделями, такими как GPT-5?
Вызов автоматического создания задач: Сложность и глубина
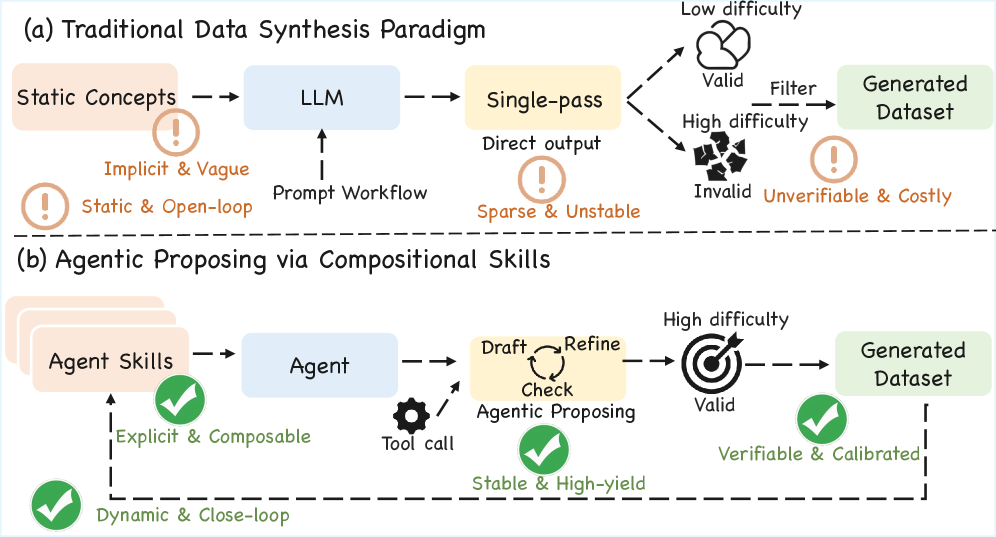
Существующие методы автоматической генерации математических задач зачастую страдают от недостатка глубины и логической связности, что приводит к созданию тривиальных или, что хуже, ошибочных упражнений. Многие современные системы полагаются на поверхностные комбинации известных элементов, не обеспечивая содержательной новизны или проверяя истинное понимание концепций. В результате, генерируемые задачи могут быть решены простым угадыванием или применением шаблонных алгоритмов, не требуя от решающего критического мышления или глубокого анализа. Например, задача, требующая лишь подстановки значений в уже известную \sum_{i=1}^{n} i = \frac{n(n+1)}{2}, вряд ли может считаться сложной или способствующей развитию математических навыков. Поэтому, для создания действительно эффективных и стимулирующих упражнений необходим принципиально новый подход, основанный на строгом логическом построении и верификации каждого шага решения.
Простое увеличение масштаба существующих языковых моделей недостаточно для генерации действительно сложных математических задач. Исследования показывают, что для создания нетривиальных упражнений необходим структурированный подход, включающий в себя этапы логического рассуждения и верификации. Вместо слепого воспроизведения паттернов, система должна уметь строить задачу, начиная с четко определенных целей и ограничений, а затем проверять ее корректность и сложность. Такой подход предполагает использование формальных методов и алгоритмов, способных гарантировать, что задача имеет решение, но требует значительных усилий для его нахождения. Это принципиально отличается от статистических моделей, которые могут генерировать грамматически правильные, но математически бессмысленные или излишне простые упражнения. E = mc^2 — пример концепции, требующей глубокого понимания для создания соответствующей задачи.
Одной из главных сложностей при автоматической генерации задач является точная калибровка их сложности. Необходимо найти баланс между доступностью решения и уровнем сложности, чтобы задача не оказалась ни слишком простой для целевой аудитории, ни настолько трудной, что вызовет разочарование и потерю мотивации. Проблема заключается в том, что сложность задачи — это не просто количество шагов или математических операций, но и глубина понимания необходимых концепций, а также способность к нестандартному мышлению. Автоматизированные системы часто испытывают трудности с оценкой этих факторов, генерируя либо тривиальные упражнения, либо, наоборот, чрезмерно сложные, требующие знаний, выходящих за рамки предполагаемого уровня подготовки. Достижение оптимальной сложности требует учета множества параметров, включая тип задачи, используемые концепции, структуру решения и когнитивные способности решающего, что делает задачу калибровки исключительно сложной для алгоритмической реализации.
Агентский синтез: Новый подход к построению задач
Предлагаемый нами фреймворк, Agentic Proposing, основан на декомпозиции процесса построения задач на отдельные, компонуемые навыки агента. Такой подход позволяет создать модульную и масштабируемую систему, в которой сложные задачи решаются путем объединения простых, специализированных навыков. Компонуемость обеспечивает гибкость и повторное использование компонентов, а модульность упрощает отладку, тестирование и расширение функциональности. Разделение задачи на составные части позволяет агенту эффективно управлять сложностью и сосредотачиваться на решении отдельных подзадач, что повышает общую производительность и надежность системы.
В основе предложенного подхода лежит моделирование процесса создания задач с использованием Частично Наблюдаемой Марковской Процессии Решения (POMDP). POMDP позволяет представить проблему конструирования задач как последовательность решений, принимаемых агентом в условиях неполной информации о логической согласованности и сложности формируемой задачи. Состояние POMDP отражает текущее представление о задаче, действия агента — операции по ее построению и уточнению, а награда — оценку логической корректности и сложности полученного результата. Использование POMDP позволяет формализовать поиск оптимальной стратегии конструирования задач, учитывая неопределенность и необходимость оценки промежуточных результатов для обеспечения логической непротиворечивости и достижения необходимого уровня сложности.
В основе предлагаемого подхода лежит итеративный процесс, включающий внутреннюю рефлексию и использование инструментов. Внутренняя рефлексия позволяет агенту оценивать собственные шаги рассуждений и выявлять потенциальные ошибки или неточности. Для верификации полученных результатов и подтверждения логической корректности, агент использует различные инструменты — как встроенные, так и внешние — для проверки гипотез, поиска противоречий и оценки сложности создаваемых проблем. Этот цикл самооценки и инструментальной проверки повторяется итеративно, обеспечивая повышение надежности и качества процесса построения проблем.
Оптимизация политики агента: Многогранулярный подход
Для уточнения политики агента используется многогранулярная оптимизация, объединяющая как терминальные, так и промежуточные награды для направления процесса обучения. Терминальные награды оценивают итоговый результат действия, в то время как промежуточные награды предоставляют обратную связь на каждом шаге взаимодействия, способствуя более быстрому обучению и улучшению стратегии агента в сложных задачах. Комбинирование этих двух типов наград позволяет агенту учитывать не только конечный успех, но и эффективность предпринятых действий на пути к цели, что повышает общую производительность и стабильность обучения.
Оптимизация, используемая при обучении агента, расширяет возможности обучения с подкреплением за счет внедрения детальной оценки преимущества (advantage estimation). Традиционные методы обучения с подкреплением часто сталкиваются с проблемой размытого сигнала при решении сложных задач, требующих многоступенчатого рассуждения. Детальная оценка преимущества позволяет более точно определить, насколько полезно конкретное действие в конкретном состоянии, по сравнению со средним ожидаемым результатом. Это достигается путем вычисления разницы между фактической полученной наградой и ожидаемой наградой, что приводит к более сильному и четкому сигналу для агента, позволяющему ему эффективно учиться и улучшать свою политику в сложных сценариях рассуждений.
Начальная инициализация политики агента осуществляется посредством обучения с учителем (supervised fine-tuning) на основе траекторий, полученных от экспертов. Этот процесс позволяет агенту быстро приобрести базовые навыки и сократить время, необходимое для обучения с подкреплением. Последующее обучение по учебному плану (curriculum learning) применяется для целенаправленной оптимизации политики в областях, где агент демонстрирует наименьшую эффективность. Это достигается путем последовательного усложнения задач и акцентирования внимания на примерах, в которых агент совершает ошибки, что позволяет повысить общую производительность и улучшить способность к решению сложных задач.
Валидация и производительность на AIME 2025: Новый уровень сложности
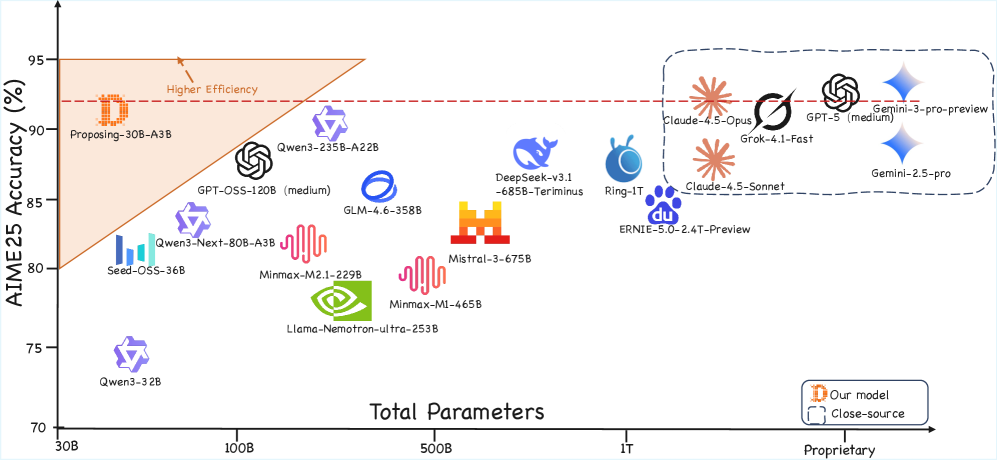
Агент продемонстрировал существенный прогресс в генерации валидных и сложных математических задач, что было подтверждено оценкой на бенчмарке AIME 2025. Достигнута передовая точность в 91.6%, что свидетельствует о значительном улучшении по сравнению с существующими решениями. Этот показатель отражает способность агента создавать задачи, требующие глубокого математического мышления и проверки знаний, а не простого применения заученных алгоритмов. Такой уровень производительности открывает новые возможности для автоматизированной генерации учебных материалов и оценки математической грамотности, обеспечивая более эффективный и персонализированный подход к обучению.
Обеспечение логической непротиворечивости является основополагающим аспектом в процессе генерации математических задач, поскольку именно это качество определяет способность задач эффективно оценивать навыки математического мышления. Агент, разработанный для создания таких задач, демонстрирует высокую степень согласованности в своих выводах, что позволяет формировать условия, не содержащие внутренних противоречий или двусмысленностей. Это критически важно, поскольку задачи с логическими ошибками могут ввести в заблуждение решающего, искажая истинную оценку его математической компетенции. В результате, способность агента к обеспечению логической целостности задач напрямую влияет на точность и достоверность оценки математических способностей, предоставляя надежный инструмент для тестирования и развития соответствующих навыков. Гарантируя корректность и последовательность математических рассуждений в сгенерированных задачах, система способствует формированию более глубокого и осознанного понимания математических принципов.
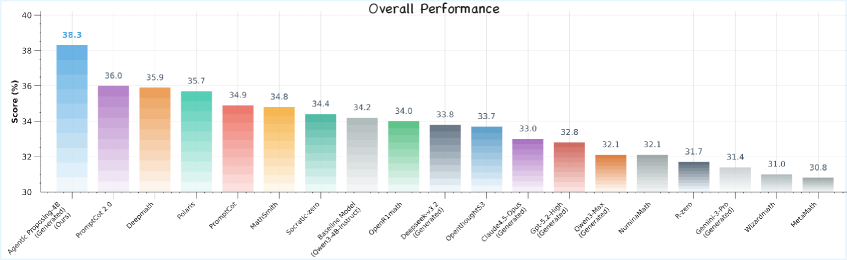
Сравнительный анализ продемонстрировал превосходство разработанного подхода в генерации математических задач над существующими методами, включая DeepSeek-Math, как по критерию валидности, так и по сложности. Полученные результаты указывают на способность системы создавать задачи, требующие глубокого математического мышления и при этом не содержащие логических ошибок. По показателям качества генерируемых задач, разработанная система сопоставима с передовыми моделями, такими как GPT-5 и Gemini-3-Pro, что подтверждает её потенциал в области автоматизированной генерации учебных и оценочных материалов. Это позволяет предположить, что система может эффективно использоваться для подготовки к олимпиадам и другим соревнованиям по математике, а также для создания персонализированных учебных программ.
К динамическому обучению и продвинутой оценке: За горизонтом возможностей
Предлагаемая структура позволяет создавать адаптивные системы обучения, способные подстраивать сложность задач под индивидуальные потребности каждого учащегося. Вместо предоставления всем одинакового набора упражнений, система динамически оценивает уровень знаний и навыков, предлагая задачи, оптимальные для текущего этапа обучения. Это достигается за счет алгоритмов, которые анализируют ответы студента и автоматически корректируют сложность последующих задач, обеспечивая постоянный, но достижимый вызов. Такой подход не только повышает эффективность обучения, но и способствует поддержанию мотивации, поскольку студент не сталкивается с задачами, которые заведомо слишком сложны или, наоборот, слишком просты.
Автоматизация процесса генерации задач представляет собой значительный шаг к снижению нагрузки на преподавателей и одновременному повышению качества обучения. Системы, способные самостоятельно создавать задачи различной сложности, адаптированные к индивидуальному уровню знаний каждого ученика, позволяют высвободить время педагогов для более важных аспектов образовательного процесса — индивидуального консультирования и развития критического мышления. Такой подход не только экономит ресурсы, но и обеспечивает более эффективное усвоение материала, поскольку ученик получает задачи, соответствующие его текущим возможностям, избегая как чрезмерной сложности, приводящей к разочарованию, так и излишней простоты, снижающей мотивацию. В результате, создается персонализированная образовательная среда, способствующая более глубокому пониманию и долгосрочному запоминанию материала.
Предстоящие исследования направлены на расширение возможностей агента за пределы текущей предметной области, включая такие дисциплины, как физика и информатика. Особое внимание будет уделено разработке более сложных методов приобретения навыков, выходящих за рамки простого решения задач. В частности, планируется исследовать подходы, позволяющие агенту самостоятельно формулировать гипотезы, проводить эксперименты и обобщать полученные знания для решения принципиально новых задач. Такой подход позволит создать систему, способную к непрерывному обучению и адаптации к изменяющимся требованиям, что откроет новые возможности для персонализированного и эффективного образования.
Представленная работа демонстрирует, что эффективное решение сложных задач требует не просто увеличения вычислительных мощностей, но и продуманной организации процесса. Методика Agentic Proposing, с её акцентом на декомпозицию проблемы на составные навыки и итеративное совершенствование, подтверждает идею о том, что структура определяет поведение системы. В этом контексте уместно вспомнить слова Винтона Серфа: «Интернет — это не просто технология, это способ организации информации». Как и в случае с Интернетом, Agentic Proposing предлагает не просто алгоритм, а способ структурирования процесса решения задач, позволяя создавать более сложные и валидные обучающие данные, что, в свою очередь, ведет к улучшению производительности модели. Оптимизация каждого навыка создает новые точки напряжения, требующие постоянного внимания и переосмысления общей архитектуры системы.
Куда Дальше?
Предложенный подход к синтезу задач, основанный на композиции навыков, демонстрирует потенциал для улучшения обучения больших языковых моделей. Однако, кажущаяся элегантность этой конструкции не должна заслонять фундаментальные вопросы. Оптимизация процесса построения задач — это не просто поиск более эффективного алгоритма, а осознание того, что сама постановка проблемы определяет возможные решения. Мы часто оптимизируем не то, что нужно, а то, что проще измерить.
Ключевым ограничением остаётся зависимость от предварительно определённого набора навыков. В реальности, граница между навыками размыта, и истинная гибкость требует способности к самообучению и адаптации этих самых навыков. Простота масштабируется, изощрённость — нет. Чем сложнее архитектура построения задач, тем менее устойчива она к новым, неожиданным ситуациям. Зависимости — настоящая цена свободы.
Будущие исследования должны сосредоточиться на разработке систем, способных к автоматическому открытию и синтезу новых навыков, а также к оценке логической валидности не только отдельных шагов, но и всей цепочки рассуждений. Хорошая архитектура незаметна, пока не ломается. И только тогда становится очевидно, где кроется истинная сложность и какие компромиссы были сделаны.
Оригинал статьи: https://arxiv.org/pdf/2602.03279.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-04 13:50