Автор: Денис Аветисян
Исследователи предлагают масштабируемый метод для выявления латентных концепций, формирующих решения современных языковых моделей.

В статье представлен VQLC — подход на основе векторной квантизации, обеспечивающий интерпретируемость и эффективное масштабирование при обнаружении латентных концепций в больших языковых моделях.
Несмотря на богатую семантическую информацию, скрытую в представлениях глубоких нейронных сетей, понимание принципов, по которым модели принимают решения, остается сложной задачей. В данной работе, озаглавленной ‘Vector Quantized Latent Concepts: A Scalable Alternative to Clustering-Based Concept Discovery’, предложен метод VQLC, основанный на векторной квантизации, для обнаружения латентных концепций в больших языковых моделях. VQLC обеспечивает масштабируемый и интерпретируемый подход к пониманию прогнозов моделей, превосходя традиционные методы кластеризации по эффективности. Какие перспективы открывает данный подход для дальнейшего развития области интерпретируемого машинного обучения и повышения доверия к искусственному интеллекту?
Раскрытие «Чёрного Ящика»: Потребность в Открытии Концепций
Современные модели глубокого обучения, несмотря на впечатляющую эффективность в решении сложных задач, часто функционируют как непрозрачные системы, известные как «чёрные ящики». Эта особенность представляет собой серьёзное препятствие для широкого внедрения и доверия к таким технологиям. Отсутствие возможности понять, как модель приходит к тому или иному решению, затрудняет выявление ошибок, предвзятостей и потенциальных уязвимостей. Пользователям и разработчикам становится сложно оценить надёжность и обоснованность результатов, что особенно критично в областях, связанных с безопасностью, здравоохранением и финансами. В результате, несмотря на свою мощь, «чёрные ящики» требуют разработки методов, позволяющих «заглянуть внутрь» и сделать процесс принятия решений более понятным и контролируемым.
Понимание внутренних представлений, своего рода «мышления» глубоких нейронных сетей, имеет первостепенное значение для обеспечения их надежности и безопасности. В отличие от традиционных алгоритмов, где логика работы понятна, «черный ящик» глубокого обучения требует анализа скрытых слоев для выявления потенциальных ошибок и уязвимостей. Изучение этих внутренних представлений позволяет не только отлаживать модели и повышать их точность, но и гарантировать, что принимаемые ими решения соответствуют ожидаемым стандартам, особенно в критически важных областях, таких как здравоохранение или автономное вождение. Без возможности «заглянуть внутрь» сложно определить, какие факторы влияют на решения модели и как предотвратить нежелательное поведение, что ставит под угрозу доверие к этим мощным технологиям.
Традиционные методы анализа внутренних представлений нейронных сетей часто оказываются неэффективными при извлечении понятных человеку концепций. Вместо четких, интерпретируемых признаков, алгоритмы, как правило, выявляют сложные, абстрактные паттерны, мало что говорящие о том, как именно модель «думает». Это связано с тем, что внутренние представления, формируемые в процессе обучения, оптимизированы для решения конкретной задачи, а не для удобства понимания человеком. Попытки применить существующие методы анализа данных, разработанные для более простых моделей, зачастую приводят к зашумленным или нерелевантным результатам, требуя значительных усилий для интерпретации и проверки. В результате, несмотря на впечатляющую производительность, внутренний «язык» глубоких нейронных сетей остается во многом загадкой, препятствуя дальнейшему развитию и безопасному внедрению этих технологий.
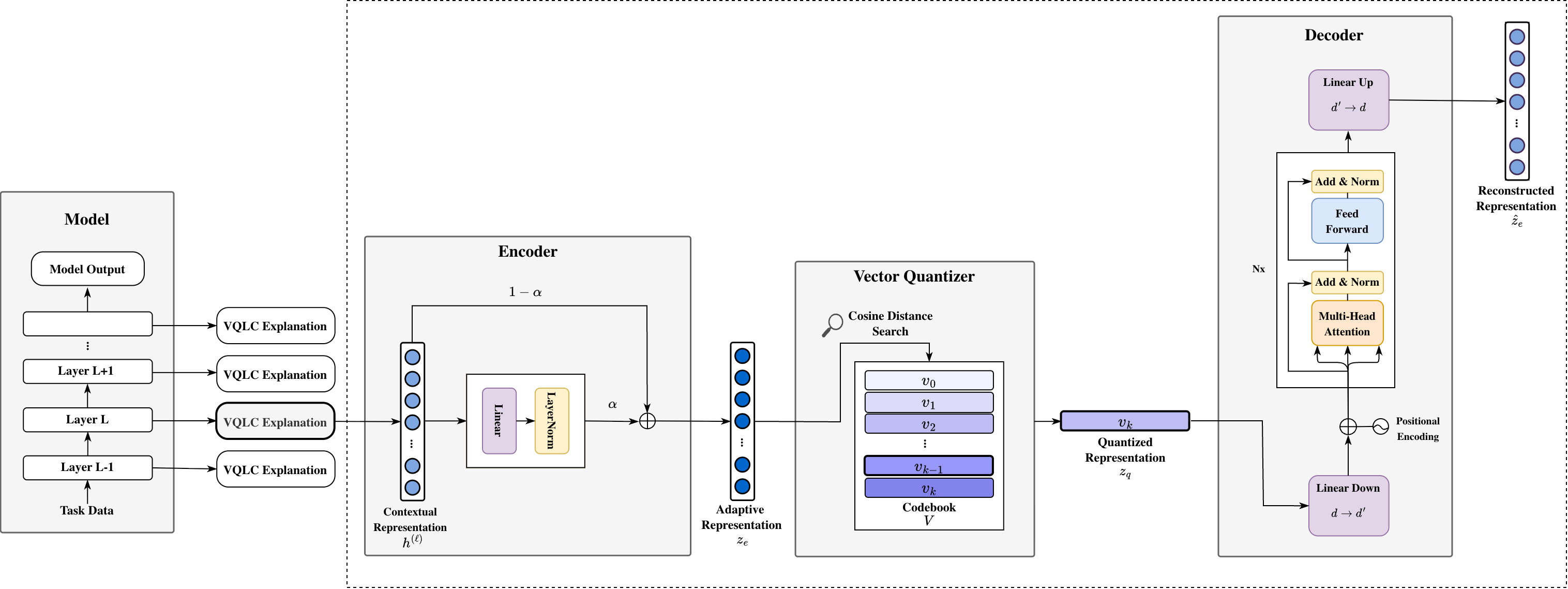
VQLC: Векторная Квантизация для Выявления Скрытых Концепций
Метод VQLC представляет собой новый подход к выявлению дискретных, интерпретируемых концепций, скрытых в контекстуальных представлениях данных. В основе лежит векторизация, позволяющая сопоставить непрерывные векторные представления с конечным набором дискретных концепций. Это достигается посредством обучения “codebook” — набора векторов, представляющих эти концепции — и последующего сопоставления входных данных с ближайшими векторами в этом codebook. Такой подход позволяет выделить и анализировать отдельные, четко определенные концепции, заложенные в сложных контекстуальных представлениях, обеспечивая более структурированное понимание данных.
Метод VQLC использует обучаемый ‘кодбук’ — дискретный набор векторов, для отображения непрерывных векторных представлений входных данных в конечное множество концептов. Каждый вектор в кодбуке представляет собой прототип определенной концепции, а процесс отображения заключается в нахождении ближайшего вектора в кодбуке для каждого входного вектора. Это позволяет проводить фокусированный анализ, поскольку каждое непрерывное представление заменяется дискретным идентификатором концепции, что упрощает интерпретацию и дальнейшую обработку данных. Размер кодбука является гиперпараметром, определяющим гранулярность представления концептов и влияющим на точность и интерпретируемость результатов.
Адаптивный остаточный энкодер (Adaptive Residual Encoder), используемый в VQLC, позволяет сохранить семантическую структуру данных, одновременно обеспечивая стабильную векторизацию, что способствует повышению чёткости выделяемых концептов. В ходе тестирования VQLC демонстрирует сопоставимую производительность с иерархической кластеризацией, однако значительно превосходит её по масштабируемости. В частности, при обработке 300 тысяч токенов, пиковое потребление памяти VQLC составляет 50 ГБ, что существенно меньше, чем у LACOAT — 300 ГБ при тех же условиях.
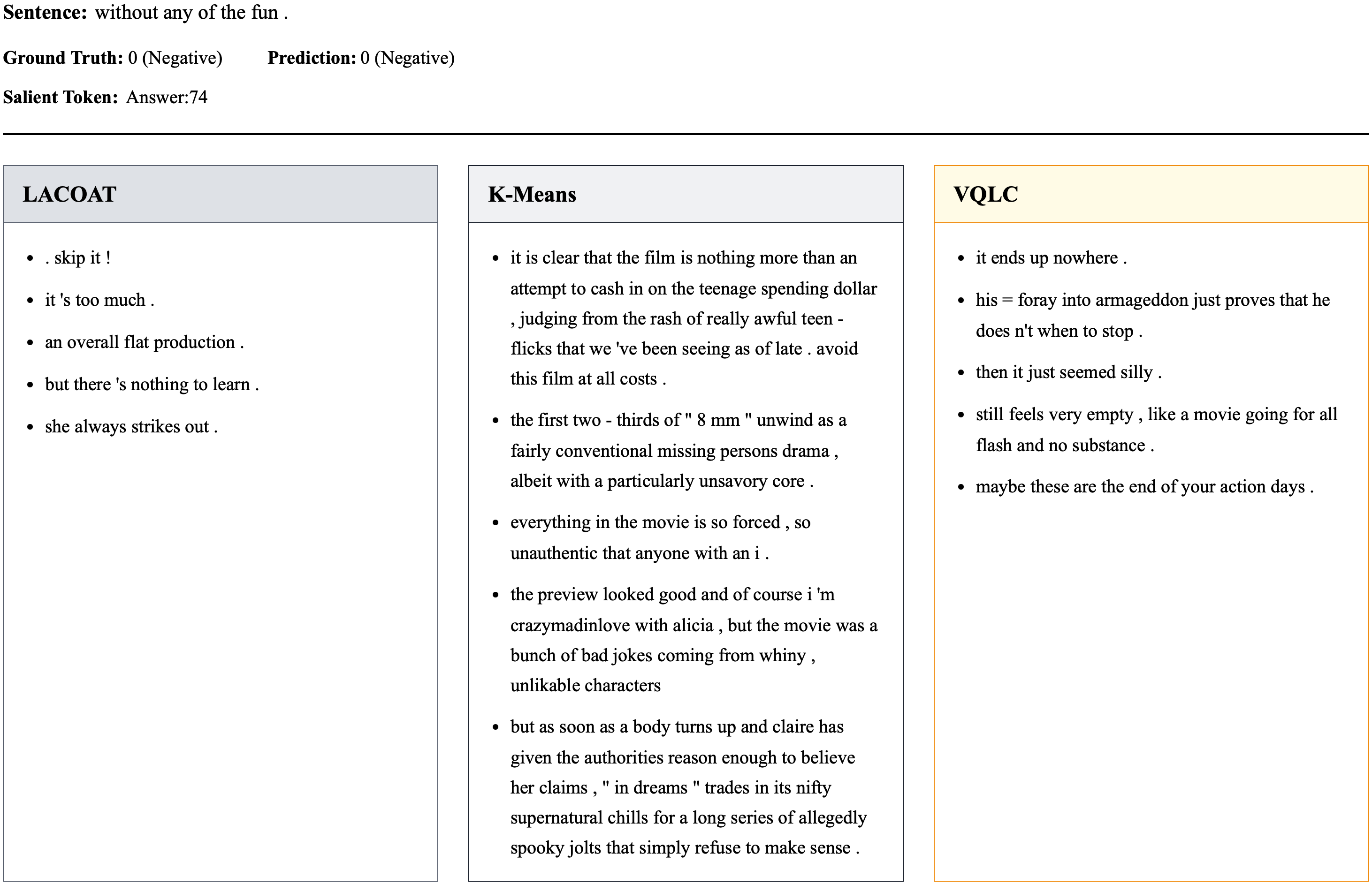
Оценка Достоверности Концепций: Гарантия Значимости Интерпретаций
Оценка достоверности (Faithfulness Evaluation) направлена на определение степени, в которой обнаруженные концепты точно отражают логику работы модели, а не являются результатом ложных корреляций. Данный процесс позволяет установить, действительно ли концепт используется моделью при принятии решений, или же он просто сопутствует этим решениям без какой-либо причинно-следственной связи. Отсутствие связи между концептом и фактическим процессом рассуждения модели указывает на его недостоверность и потенциальную бесполезность для интерпретации или улучшения работы модели. Оценка достоверности является ключевым этапом в проверке качества обнаруженных концепций и их пригодности для понимания внутренних механизмов модели.
Методы ортогональной проекции позволяют выделить вклад отдельных концепций в процесс принятия решений моделью, что необходимо для целенаправленного анализа и улучшения качества полученных представлений. Данные методы позволяют декомпозировать внутреннее представление модели, изолируя влияние конкретной концепции от других факторов. Это достигается путем проецирования активаций модели на вектор, представляющий интересующую концепцию, тем самым отделяя её вклад от остаточного шума и позволяя оценить её значимость и влияние на выходные данные. Использование ортогональной проекции упрощает процесс выявления нежелательных корреляций и позволяет уточнить определение концепций для повышения точности и интерпретируемости модели.
Оценка обнаруженных концепций с использованием больших языковых моделей (LLM) предоставляет автоматизированный и масштабируемый метод для оценки их качества и связности, позволяя проводить более тонкий анализ. В ходе оценки достоверности, VQLC демонстрирует сопоставимое с LACOAT снижение точности, что указывает на аналогичную достоверность концепций. Кроме того, VQLC имеет более низкий средний рейтинг, присвоенный LLM, по сравнению с методом K-Means, что свидетельствует о лучшей интерпретируемости полученных концепций.
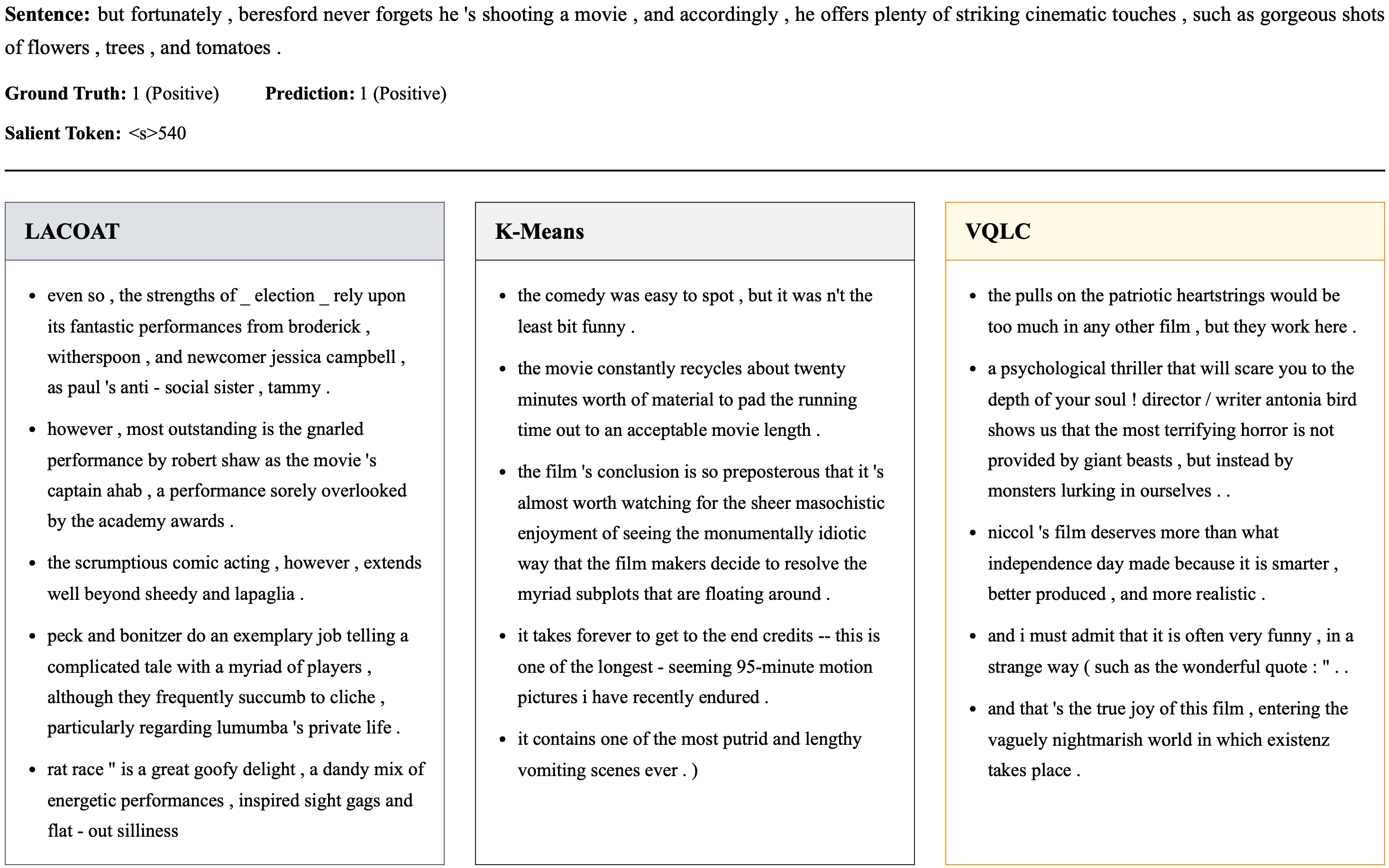
За Пределами VQLC: Расширение Обнаружения Концепций с LACOAT
Метод LACOAT представляет собой альтернативный подход к обнаружению концепций, использующий иерархическую кластеризацию для объединения токенов и выделения значимых понятий. В отличие от других методов, LACOAT не полагается на предварительно заданное количество концепций, а динамически определяет их структуру, основываясь на взаимосвязях между токенами в контекстуальных представлениях, полученных из глубоких нейронных сетей. Этот процесс позволяет выявлять не только очевидные, но и более тонкие, скрытые концепции, которые могут быть упущены при использовании фиксированного числа кластеров. Иерархический подход также обеспечивает возможность анализа концепций на разных уровнях абстракции, что полезно для понимания сложных взаимосвязей в данных и получения более полного представления о содержании.
Методы VQLC и LACOAT объединяет анализ контекстных представлений, полученных из глубиннных нейронных сетей. Эти представления, кодирующие семантическую информацию о словах и фразах в зависимости от их окружения, служат основой для выявления концепций. В то время как VQLC фокусируется на выявлении концепций через анализ вариативности в этих представлениях, LACOAT использует иерархическую кластеризацию для группировки токенов и выявления более общих тем. Такой подход позволяет получить взаимодополняющие результаты: VQLC предоставляет информацию о тонких нюансах, а LACOAT — о широких категориях, что значительно расширяет возможности автоматического обнаружения концепций в больших текстовых корпусах и способствует более глубокому пониманию содержания.
Анализ контекстных представлений, полученных из моделей глубокого обучения, оказался удивительно гибким инструментом для выявления скрытых концепций. Помимо алгоритма LACOAT и VQLC, для этой цели успешно применяются и другие методы кластеризации, в частности, алгоритм K-Means. Этот подход позволяет автоматически группировать схожие токены, выявляя семантические связи и обобщения, которые могут быть неочевидны при прямом анализе данных. Применение K-Means демонстрирует, что возможность извлечения осмысленных концепций из контекстных представлений не ограничивается конкретным алгоритмом, а представляет собой универсальный подход, применимый в различных задачах обработки естественного языка, включая анализ текста, машинный перевод и создание интеллектуальных систем.

Представленное исследование демонстрирует стремление к математической чистоте в области интерпретируемости больших языковых моделей. Авторы предлагают метод VQLC, основанный на векторной квантизации, как способ обнаружения латентных концепций, что позволяет не просто наблюдать за результатами, но и доказывать их корректность. Как заметил Г.Х. Харди: «Математика — это наука о том, что можно доказать». Эта фраза отражает суть подхода, изложенного в статье: вместо эмпирического поиска концепций, предлагается метод, позволяющий формально обосновать их существование и влияние на поведение модели. Доказательство корректности алгоритма, а не просто его работа на тестовых данных, является ключевым аспектом данной работы.
Куда же дальше?
Представленный подход, использующий векторизованную квантизацию для выявления латентных концептов, безусловно, представляет интерес. Однако, если полученные «концепты» оказываются непонятны, следует помнить: если решение кажется магией — значит, не раскрыт инвариант. Необходимо углубиться в вопросы стабильности и воспроизводимости этих концептов при изменении архитектуры модели или обучающих данных. Просто «работать на тестах» недостаточно; требуется доказательство корректности.
Особое внимание следует уделить масштабируемости метода. Эффективность векторизованной квантизации — это хорошо, но её применимость к моделям, содержащим сотни миллиардов параметров, — вопрос открытый. Необходимо исследовать возможности асимптотической оптимизации и параллелизации вычислений, дабы избежать ситуации, когда «концепт» оказывается недостижим из-за вычислительных ограничений.
И, наконец, нельзя забывать о философском аспекте. Что есть «концепт» для языковой модели? Является ли он отражением объективной реальности или лишь артефактом обучающего процесса? Ответ на этот вопрос, возможно, потребует привлечения не только специалистов в области машинного обучения, но и философов, когнитивных учёных и даже лингвистов. В противном случае, рискуем просто переименовать «чёрный ящик» в «немного более прозрачный чёрный ящик».
Оригинал статьи: https://arxiv.org/pdf/2602.02726.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-04 15:39