Автор: Денис Аветисян
Исследователи предлагают метод динамической компрессии токенов, позволяющий значительно ускорить обработку больших объемов текста без потери качества.
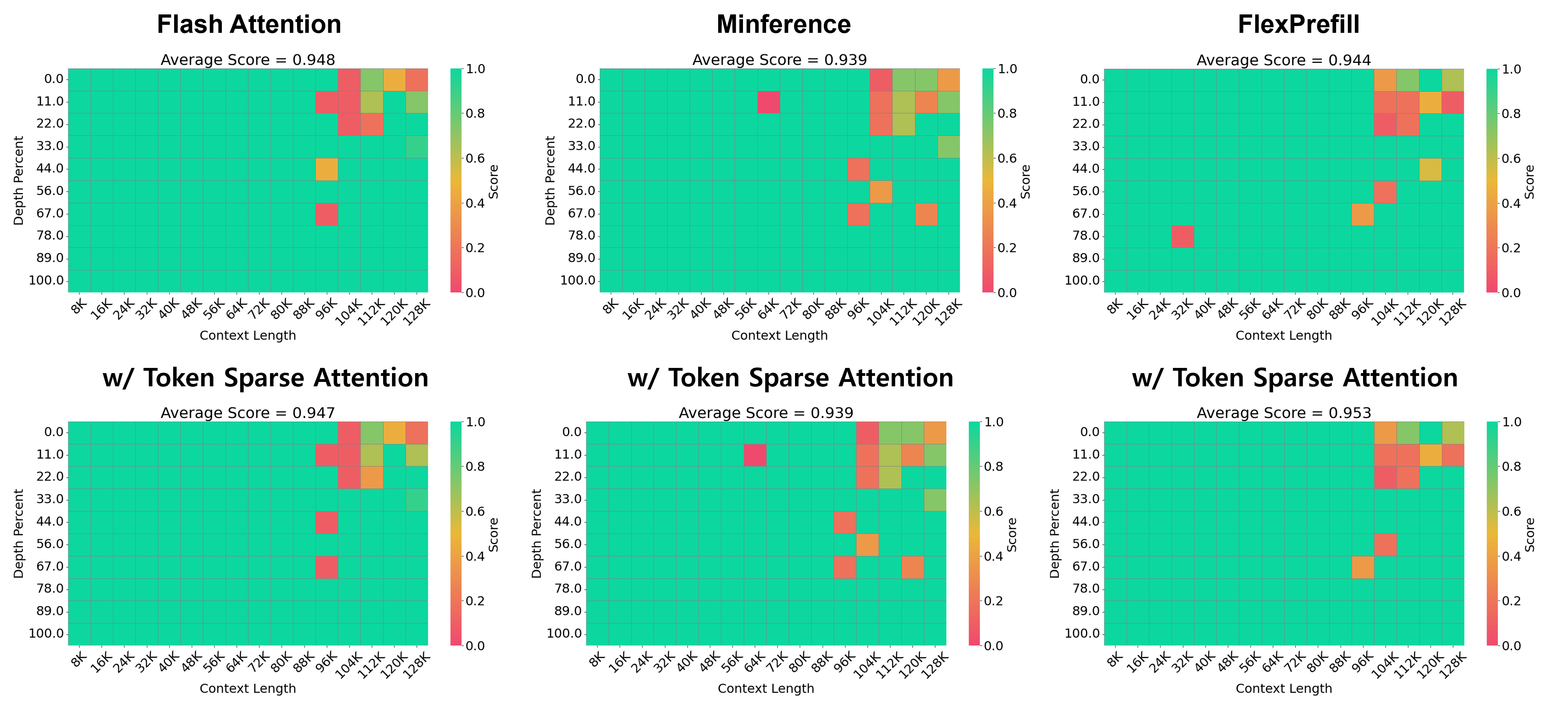
Предложенная техника Token Sparse Attention обеспечивает эффективную обработку длинных последовательностей за счет динамического отбора и сжатия токенов с возможностью обратного восстановления.
Квадратичная сложность механизма внимания остается ключевым препятствием для эффективной обработки длинных контекстов в больших языковых моделях. В данной работе, посвященной ‘Token Sparse Attention: Efficient Long-Context Inference with Interleaved Token Selection’, предложен новый подход к разрежению внимания, основанный на динамическом отборе и компрессии токенов без их необратимого исключения. Предложенный метод Token Sparse Attention позволяет добиться существенного ускорения вычислений, сохраняя при этом высокую точность за счет пересмотра информации о токенах на последующих слоях. Возможно ли дальнейшее улучшение масштабируемости и эффективности обработки длинных контекстов за счет комбинирования динамического разрежения с другими методами оптимизации механизма внимания?
Преодоление Узкого Места Длинного Контекста: Ограничения Механизма Внимания
Современные большие языковые модели (LLM) совершают революцию в области обработки естественного языка, однако их эффективность значительно снижается при работе с длинными последовательностями входных данных. Эта проблема обусловлена квадратичной сложностью механизма внимания — ключевого компонента LLM. По мере увеличения длины последовательности, вычислительные затраты и потребление памяти растут пропорционально квадрату этой длины O(n^2), что делает обработку объемных текстов или выполнение сложных, многоступенчатых рассуждений чрезвычайно ресурсоемкой задачей. В результате, возможности LLM по эффективному анализу и пониманию длинных контекстов остаются ограниченными, несмотря на значительные успехи в других областях.
Ограничения, связанные с вычислительной нагрузкой, существенно влияют на способность больших языковых моделей эффективно обрабатывать обширные документы и выполнять сложные, многоступенчатые рассуждения. Вместо того чтобы полностью понимать взаимосвязи внутри длинных текстов, модели часто вынуждены упрощать анализ, фокусируясь на наиболее очевидных элементах или теряя важные детали в процессе обработки. Это приводит к снижению точности при ответах на вопросы, требующие глубокого понимания контекста, и к неспособности выводить логические заключения из разрозненных фрагментов информации. Фактически, увеличение длины входной последовательности не всегда приводит к улучшению результатов, а в некоторых случаях может даже ухудшить их, демонстрируя предел возможностей текущих архитектур при работе с действительно длинными текстами.
Несмотря на значительные улучшения в оптимизации работы с большими языковыми моделями, такие как FlashAttention, проблема масштабируемости механизма внимания остается нерешенной. Эти оптимизации, направленные в основном на ускорение операций ввода-вывода памяти, позволяют временно смягчить вычислительную нагрузку, но не устраняют фундаментальную причину: квадратичную сложность, возникающую при обработке длинных последовательностей. Это означает, что с увеличением длины входного текста вычислительные затраты растут экспоненциально, что препятствует возможности моделей эффективно анализировать обширные документы или осуществлять сложные, многоступенчатые рассуждения. Таким образом, хотя FlashAttention и подобные методы повышают производительность, они не обеспечивают прорыв в области истинной обработки длинного контекста, ограничивая потенциал больших языковых моделей в задачах, требующих глубокого понимания больших объемов информации.
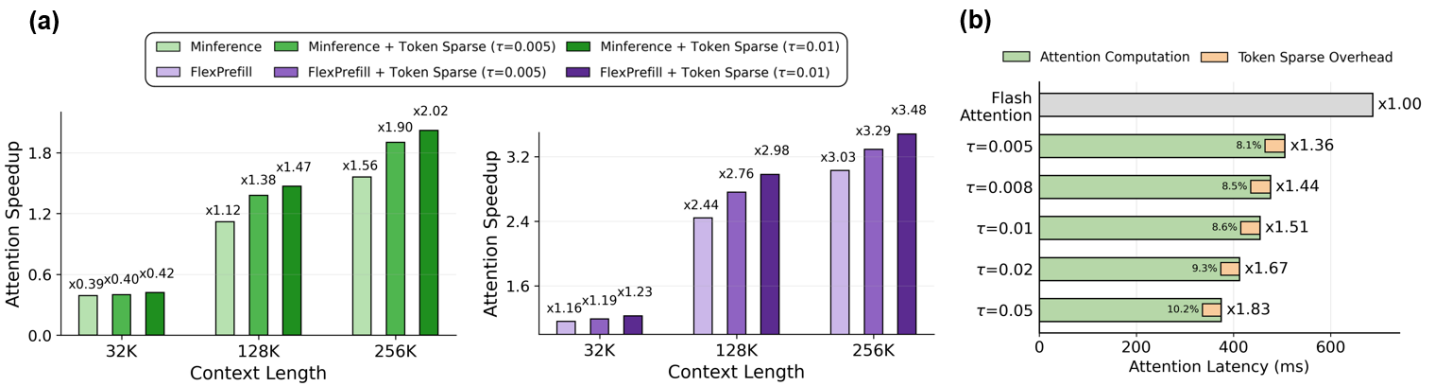
Разреженное Внимание: Новый Подход к Эффективности
Механизм разреженного внимания (Sparse Attention) предлагает решение для снижения вычислительных затрат за счет исключения вычислений для областей с низкой значимостью на карте внимания. Вместо обработки каждого элемента последовательности, этот подход фокусируется на наиболее важных участках, игнорируя те, которые вносят минимальный вклад в конечный результат. Это достигается путем определения порогового значения значимости, после чего вычисления выполняются только для элементов, превышающих этот порог. В результате, общая вычислительная сложность снижается, особенно при обработке длинных последовательностей, что позволяет повысить эффективность и скорость обработки данных.
Внимание, разреженное по токенам (Token-Sparse Attention), представляет собой усовершенствование подхода разреженного внимания, осуществляющее динамический отбор наиболее значимых токенов на уровне отдельных элементов последовательности. Этот механизм позволяет оптимизировать этап предварительного заполнения (prefill) за счет концентрации вычислительных ресурсов на критически важных токенах, игнорируя менее информативные. В отличие от фиксированных схем разреженного внимания, динамический отбор позволяет адаптироваться к различным входным данным и задачам, обеспечивая эффективное использование ресурсов и ускорение обработки без потери качества результатов. Реализация данного подхода предполагает использование метрик значимости токенов для определения приоритетов при вычислении внимания.
В основе данного подхода лежит определение важности токенов, что позволяет динамически выделять наиболее значимые элементы для обработки. Для ускорения процесса используются методы сжатия и декомпрессии данных, позволяющие уменьшить объем вычислений без потери качества результата. Применение сжатия к менее важным токенам снижает вычислительную нагрузку, а декомпрессия восстанавливает информацию при необходимости, обеспечивая баланс между скоростью обработки и сохранением точности данных. Данная стратегия позволяет эффективно использовать вычислительные ресурсы и повысить производительность системы, особенно при работе с большими объемами информации.
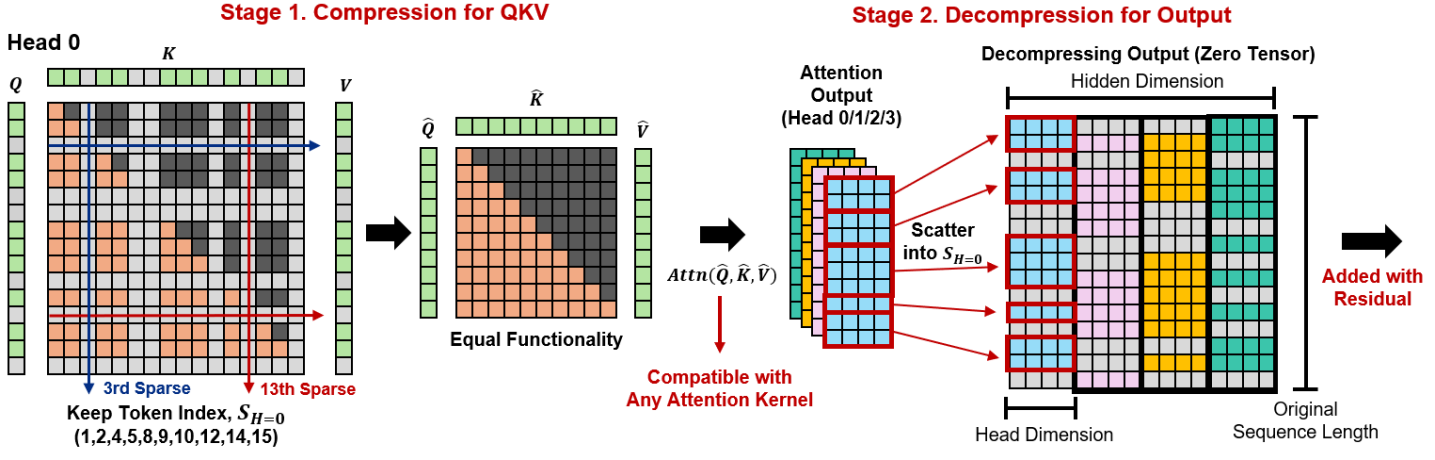
Динамическое Покрытие Токенов: Интеллектуальная Адаптация к Контексту
Политика динамического покрытия токенов (Dynamic Token Coverage) обеспечивает интеллектуальное определение бюджета разреженности во время инференса, автоматически адаптируя его к конкретному входному тексту. В отличие от статических методов, где бюджет разреженности фиксирован, данная политика анализирует важность каждого токена и динамически регулирует степень его усечения. Это достигается путем оценки вклада токена в выходные данные каждого слоя модели. Токены, признанные наиболее значимыми для текущего входного сигнала, сохраняются, а менее важные — отбрасываются, гарантируя, что модель всегда оперирует с наиболее релевантной информацией, минимизируя потери точности при одновременном повышении эффективности вычислений.
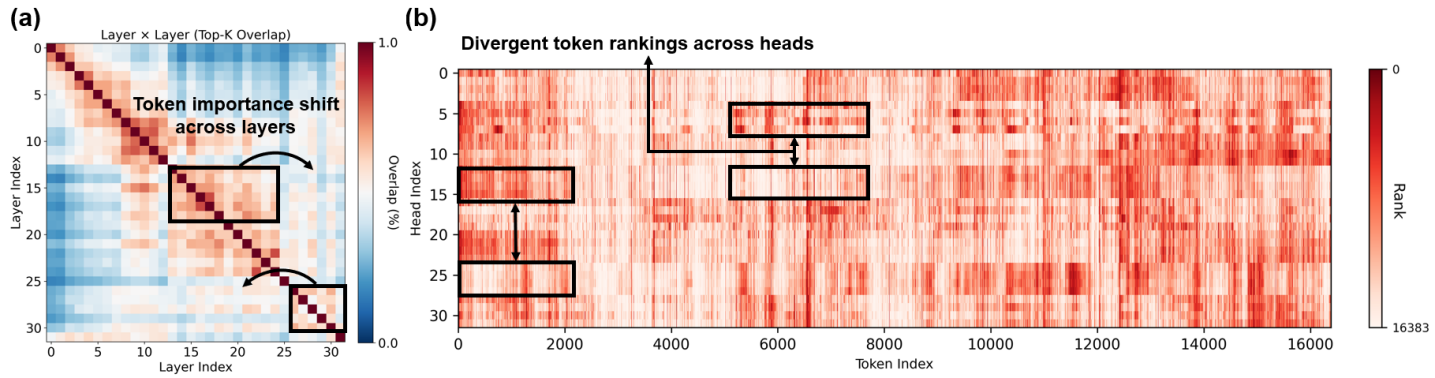
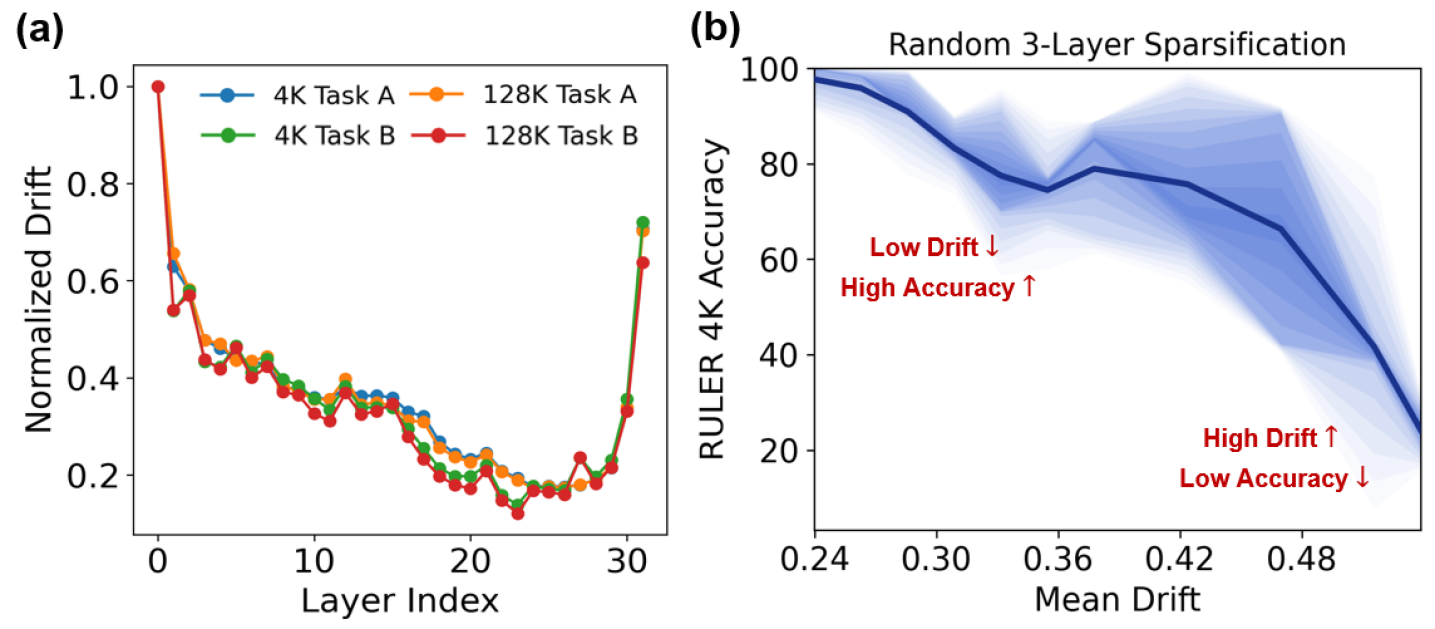
Анализ перекрытия токенов по слоям и важности токенов по головам позволяет выявить, какие токены последовательно вносят вклад в понимание модели. Метод предполагает расчет степени перекрытия токенов, выбранных для каждого слоя, что указывает на наиболее стабильные и значимые элементы входной последовательности. Оценка важности токенов по головам внимания позволяет определить, какие токены наиболее активно используются различными механизмами внимания модели для принятия решений. Комбинирование этих двух метрик дает возможность идентифицировать критически важные токены, определяющие поведение модели и ее способность к обобщению, что является ключевым для оптимизации разреженности и повышения эффективности.
Анализ смещения представлений между слоями (Inter-Layer Representation Drift) позволяет уточнить процесс выбора токенов для динамического покрытия. Данный анализ выявляет, как значимость токенов изменяется при прохождении через последовательные слои нейронной сети. Выявляя токены, которые теряют свою информативность или, наоборот, приобретают ее на определенных слоях, алгоритм может динамически корректировать бюджет разреженности (sparsity budget). Это позволяет сосредоточить вычислительные ресурсы на наиболее релевантных токенах на каждом конкретном слое, что оптимизирует производительность модели и повышает эффективность использования памяти. Игнорирование Inter-Layer Representation Drift может привести к удержанию нерелевантных токенов на поздних слоях или преждевременному отбрасыванию важных токенов на ранних этапах обработки.
Валидация Эффективности и Широкая Применимость
Оценка разработанного подхода проводилась с использованием общепризнанных бенчмарков для работы с длинным контекстом, таких как RULER, LongBench и InfiniteBench. Результаты демонстрируют высокую эффективность предложенной методики в задачах, требующих глубокого понимания и логического вывода на основе обширных объемов информации. Успешное прохождение этих тестов подтверждает способность системы эффективно обрабатывать длинные последовательности токенов, сохраняя при этом точность и скорость работы, что является критически важным для решения сложных задач в области искусственного интеллекта и обработки естественного языка.
Исследования с использованием больших языковых моделей, таких как LLaMA-3.1-8B-Instruct и Mistral-Nemo-12B-Instruct, подтверждают универсальность предложенного подхода к обработке длинных контекстов. Эксперименты показали, что разработанная техника эффективно интегрируется с различными архитектурами моделей, демонстрируя стабильные результаты и не требуя значительной перенастройки. Это указывает на то, что метод не зависит от специфических особенностей конкретной модели, что делает его применимым к широкому спектру задач и платформ, и открывает возможности для дальнейшего развития и адаптации в различных областях искусственного интеллекта.
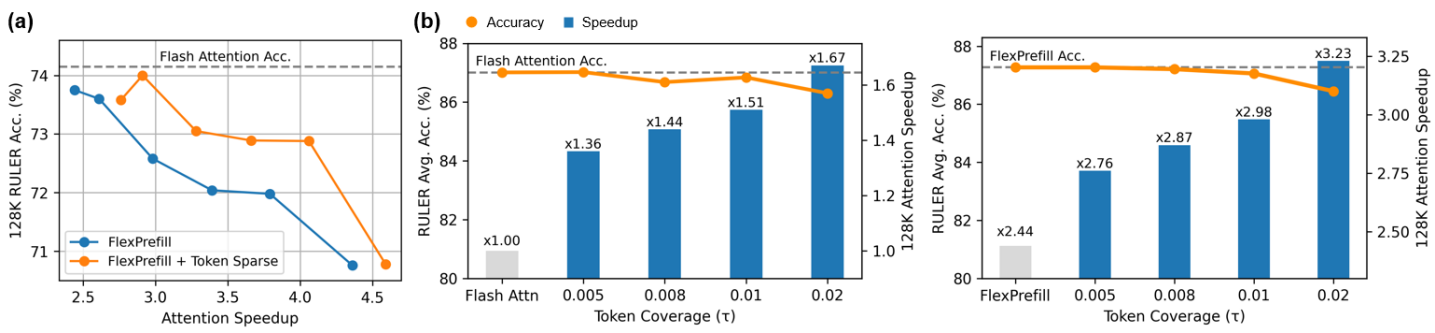
Исследования показали, что разработанный метод демонстрирует значительный потенциал в задачах, требующих извлечения информации из больших объемов данных, что подтверждается результатами, полученными на бенчмарке Needle-in-a-Haystack. В частности, при использовании модели LLaMA-3.1-8B-Instruct удалось достичь ускорения до 2.76x при сохранении высокой точности ответов на всех протестированных наборах данных. При этом накладные расходы, связанные с использованием Token Sparse Attention, остаются незначительными, составляя менее 11% от общей задержки, даже при работе с контекстом длиной до 128 тысяч токенов, что свидетельствует о высокой эффективности и масштабируемости предложенного подхода.
Перспективы Развития: Расширение Возможностей Разреженного Внимания
Дальнейшее изучение таких методов, как FlexPrefill, FastKV и GemFilter, представляет значительный потенциал для оптимизации реализации разреженного внимания, что, в свою очередь, способствует повышению его эффективности и масштабируемости. Эти техники направлены на сокращение вычислительных затрат и объема памяти, необходимых для обработки последовательностей, особенно длинных текстов. FlexPrefill, например, позволяет предварительно заполнять части входной последовательности, снижая нагрузку на процесс внимания. FastKV оптимизирует доступ к ключам и значениям, ускоряя вычисления. А GemFilter эффективно отсеивает несущественные элементы, уменьшая размер обрабатываемых данных. Совершенствование этих и подобных подходов является ключевым шагом к созданию более быстрых и экономичных моделей обработки естественного языка, способных эффективно работать с большими объемами информации.
Исследования альтернативных паттернов разреженности, в частности, блочной разреженности (Block-Sparse Attention), представляют значительный интерес для дальнейшей оптимизации производительности моделей обработки естественного языка. В отличие от традиционных подходов, где разреженность применяется к отдельным элементам матрицы внимания, блочная разреженность фокусируется на группах элементов, что позволяет более эффективно использовать аппаратные возможности современных процессоров и снижать накладные расходы, связанные с обработкой разреженных данных. Предварительные результаты показывают, что структурированная разреженность, как в случае блочной реализации, может значительно ускорить вычисления, особенно при работе с длинными последовательностями, и при этом сохранить высокую точность модели. Это открывает перспективы для создания более масштабируемых и эффективных языковых моделей, способных обрабатывать и понимать тексты значительно большей длины.
Представленные исследования создают основу для разработки более эффективных и мощных больших языковых моделей (LLM), способных успешно обрабатывать и понимать длинные тексты. Ограничения, связанные с обработкой объемной информации, исторически сдерживали прогресс в области обработки естественного языка, но оптимизация механизмов внимания, таких как разреженное внимание, открывает новые перспективы. Это позволяет LLM не только анализировать более длинные документы и контексты, но и извлекать из них более глубокий смысл, что, в свою очередь, может привести к существенным прорывам в таких областях, как автоматический перевод, суммаризация текстов, ответы на вопросы и генерация креативного контента. Возможность эффективной обработки длинных текстов является ключевым шагом на пути к созданию действительно интеллектуальных систем, способных к полноценному пониманию и взаимодействию с человеческим языком.
В представленной работе демонстрируется элегантный подход к разрежению внимания, позволяющий эффективно обрабатывать длинные контексты. Авторы предлагают реверсивную технику, динамически выбирающую и сжимающую токены, что соответствует принципу математической чистоты и непротиворечивости. Эта методика, позволяющая ускорить процесс вывода модели без значительной потери точности, подчеркивает важность доказуемости алгоритма. Как однажды заметила Ада Лавлейс: «То, что может быть выражено в математической форме, имеет основу в логике, и его нельзя опровергнуть». Данный принцип находит своё отражение в стремлении к созданию алгоритмов, чья эффективность подтверждается не только эмпирически, но и теоретически, что особенно актуально при работе с механизмами внимания и длинными последовательностями токенов.
Куда Ведет Этот Путь?
Представленная работа, хоть и демонстрирует ощутимый прогресс в области эффективной обработки длинных контекстов, оставляет ряд вопросов без окончательного ответа. Достижение ускорения за счет динамической выборки токенов — это, безусловно, шаг вперед, но истинная элегантность кроется в предсказуемости. В конечном итоге, любое решение, основанное на случайной выборке, подвержено влиянию начальных условий. Воспроизводимость результата, особенно в критически важных приложениях, остается камнем преткновения. Нельзя просто «ускорить» процесс, если при этом теряется гарантия детерминированного исхода.
Дальнейшие исследования должны быть сосредоточены не только на оптимизации скорости, но и на разработке методов, позволяющих формально доказать корректность алгоритма выборки. Вместо эмпирической оценки «небольшой потери точности», необходимо стремиться к строгому математическому обоснованию. Иначе говоря, необходимо разработать критерии, позволяющие заранее определить, какие токены можно исключить без ущерба для общей логической структуры последовательности. Иначе, это лишь временное решение, маскирующее фундаментальную проблему.
Очевидно, что направление исследований в сторону разреженной обработки информации перспективно. Однако, необходимо помнить, что скорость — это лишь один из параметров. В конечном счете, значение имеет не то, как быстро система обрабатывает информацию, а то, насколько надежно и предсказуемо она это делает. Любая оптимизация, ведущая к неопределенности, является шагом назад, а не вперед.
Оригинал статьи: https://arxiv.org/pdf/2602.03216.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-05 01:39