Автор: Денис Аветисян
Новое исследование представляет масштабный синтетический набор данных, призванный решить проблему нехватки данных для разработки и оценки технологий, обеспечивающих конфиденциальность.

Представлен Privasis — миллионный синтетический набор данных и инструменты для исследований в области сохранения приватности, стандартизирующие оценку и улучшение методов защиты данных.
Несмотря на растущую потребность в исследованиях, связанных с конфиденциальными данными, их доступность традиционно ограничена. В данной работе представлена ‘Privasis: Synthesizing the Largest «Public» Private Dataset from Scratch’ — первая в своем роде синтетическая база данных масштаба в миллион записей, созданная с нуля для решения этой проблемы. Privasis включает в себя 1.4 миллиона документов разнообразных типов — от медицинских карт до финансовых отчетов и личных сообщений — с 55.1 миллионом аннотированных атрибутов, и позволяет создавать параллельные корпуса для анонимизации текстов, превосходя по эффективности современные большие языковые модели. Возможно ли с помощью Privasis создать надежный и стандартизированный инструмент для оценки и улучшения методов защиты приватности в эпоху развития ИИ?
Преодолевая Дефицит Данных: Вызовы в Исследованиях Конфиденциальности
Разработка эффективных технологий, обеспечивающих конфиденциальность данных, существенно затруднена недостатком реалистичных и масштабных наборов данных. Существующие базы часто оказываются слишком малыми, не отражают должного разнообразия или не способны адекватно воспроизвести сложность реальных сценариев. Это препятствует не только созданию новых алгоритмов защиты информации, но и проведению тщательной оценки существующих методов обезличивания, создавая критическое ограничение для прогресса в данной области. Отсутствие репрезентативных данных приводит к тому, что разработанные решения могут демонстрировать высокую эффективность в лабораторных условиях, но оказаться неэффективными или даже уязвимыми при применении к реальным массивам информации, что подчеркивает острую необходимость в создании и использовании более качественных и объемных источников данных для исследований в области защиты приватности.
Существующие наборы данных, используемые для исследований в области конфиденциальности, зачастую оказываются недостаточно репрезентативными для адекватной оценки разрабатываемых технологий. Их ограниченный размер препятствует выявлению тонких закономерностей и уязвимостей, а недостаток разнообразия — будь то демографическое, географическое или поведенческое — не позволяет смоделировать реальные сценарии использования. Более того, упрощенное представление данных, необходимое для сохранения конфиденциальности, может искажать реальные взаимосвязи и приводить к неверным выводам о эффективности применяемых методов защиты. Это создает серьезную проблему для разработчиков, которым необходимо тестировать свои решения в условиях, максимально приближенных к реальным, чтобы обеспечить надежную защиту личной информации.
Недостаток адекватных данных создает существенное препятствие для разработки и тщательной проверки моделей санитизации, необходимых для защиты конфиденциальности. Отсутствие обширных и реалистичных наборов данных не позволяет исследователям эффективно оценивать, насколько хорошо эти модели способны маскировать чувствительную информацию, сохраняя при этом полезность данных для анализа. Это приводит к ситуации, когда разработанные методы могут оказаться неэффективными в реальных сценариях, что ставит под угрозу приватность пользователей и ограничивает возможности использования данных в различных областях, от здравоохранения до маркетинга. В результате, прогресс в области защиты приватности замедляется, а доверие к технологиям, использующим персональные данные, снижается.
Для преодоления дефицита данных в исследованиях конфиденциальности всё чаще рассматривается переход к генерации синтетических данных. Однако, поддержание реалистичности и одновременное обеспечение конфиденциальности представляет собой значительную проблему. Создание искусственных наборов данных, которые точно отражают сложность реальных сценариев, сохраняя при этом анонимность индивидуальной информации, требует инновационных подходов. Существующие методы часто сталкиваются с компромиссом между полезностью данных для анализа и уровнем защиты от повторной идентификации. Таким образом, разработка эффективных алгоритмов синтеза данных, способных генерировать высококачественные, реалистичные и конфиденциальные наборы данных, является ключевой задачей для дальнейшего прогресса в области технологий сохранения конфиденциальности.
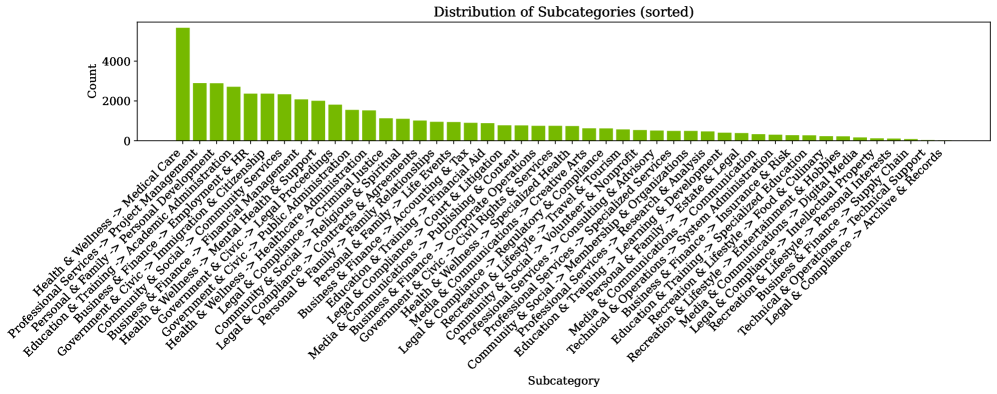
Privasis: Решение для Генерации Миллионов Синтетических Данных
Privasis использует вспомогательные контрольные переменные для управления процессом синтеза данных, что позволяет создавать разнообразные и реалистичные записи. Эти переменные служат направляющими для алгоритмов генерации, обеспечивая соответствие синтетических данных заданным характеристикам исходного распределения. В отличие от методов, генерирующих данные случайным образом, Privasis позволяет целенаправленно влиять на свойства сгенерированных записей, такие как возраст, пол, местоположение и другие релевантные параметры. Это достигается за счет использования статистических моделей, которые учитывают взаимосвязи между контрольными переменными и другими атрибутами данных, обеспечивая высокую степень реалистичности и репрезентативности сгенерированного набора данных.
Платформа Privasis обеспечивает точное управление характеристиками синтетических данных, позволяя создавать наборы данных, адаптированные к конкретным исследовательским задачам. Контроль осуществляется посредством использования вспомогательных переменных, определяющих распределение синтезируемых значений и обеспечивающих соответствие заданным критериям. Это позволяет исследователям указывать требуемые параметры, такие как возраст, пол, географическое положение и другие релевантные атрибуты, формируя данные, оптимальные для тестирования гипотез и проведения статистического анализа. Возможность точной настройки характеристик данных снижает необходимость в адаптации существующих наборов данных, экономя время и ресурсы, а также повышая достоверность полученных результатов.
В основе создания синтетического набора данных Privasis лежит приоритет конфиденциальности. Для минимизации рисков реидентификации личной информации применяются методы дифференциальной приватности. Данная технология предполагает внесение контролируемого шума в данные, что позволяет сохранить статистические свойства набора данных, при этом затрудняя установление личности конкретного человека, представленного в исходных данных. Применение дифференциальной приватности гарантирует, что любой анализ, проведенный на синтетическом наборе данных, не раскроет информацию о конкретном индивидууме, присутствующем в обучающей выборке, обеспечивая соответствие нормативным требованиям и защиту частной жизни.
При синтезе данных Privasis демонстрирует превосходные показатели разнообразия, достигая значений MATTR (Metric for Assessing True Tag Rate) в диапазоне от 0.807 до 0.823. Это значительно выше, чем у существующих наборов синтетических данных, где значения MATTR обычно находятся в пределах 0.700-0.794. Кроме того, Privasis поддерживает итеративное улучшение качества и реалистичности данных посредством автоматизированной оценки, что позволяет непрерывно совершенствовать синтезированные наборы и адаптировать их под конкретные задачи и требования.
Валидация Эффективности Санитизации с Облегченными Моделями
Для повышения эффективности процесса санитаризации была реализована схема декомпозиции, разбивающая записи на управляемые фрагменты. Этот подход позволяет обрабатывать большие объемы данных, уменьшая требования к вычислительным ресурсам и времени обработки. Декомпозиция позволяет параллельно обрабатывать отдельные фрагменты записей, что значительно ускоряет общий процесс санитаризации по сравнению с обработкой всей записи целиком. Разбиение на фрагменты также упрощает масштабирование системы, позволяя добавлять дополнительные вычислительные ресурсы для обработки большего количества данных одновременно.
Для создания облегченных моделей для санитаризации персональных данных был использован параллельный корпус, сгенерированный компанией Privasis. Данный подход позволяет эффективно решать задачу защиты конфиденциальной информации в средах с ограниченными вычислительными ресурсами. Использование параллельного корпуса обеспечивает возможность обучения моделей на большом объеме данных, что повышает их точность и надежность, при этом снижая требования к аппаратному обеспечению. Облегченные модели, обученные таким образом, представляют собой практичное решение для устройств и систем, где использование ресурсоемких алгоритмов не представляется возможным.
При тестировании на стандартном наборе данных (vanilla test set) разработанные облегченные модели продемонстрировали полный успех в 72,5% случаев. Этот показатель превышает результат, достигнутый моделью o3, которая показала 70,3% успешных проходов. Полученные данные подтверждают эффективность предложенного подхода к санитаризации данных, особенно в условиях ограниченных вычислительных ресурсов, и свидетельствуют о превосходстве разработанных моделей над существующими аналогами в данной конфигурации тестирования.
При тестировании на усложненном наборе данных, разработанные модели продемонстрировали полный успех в 12,4% случаев. Данный показатель сопоставим с результатами, полученными для модели GPT-5, которая достигла 13,1% полного успеха при аналогичном тестировании. Сопоставимость результатов подтверждает эффективность предложенного подхода к санитаризации данных даже в условиях повышенной сложности и требований к точности.
Расширяя Горизонты: Применение и Перспективы Развития
Создание синтетических данных, обеспечивающих конфиденциальность, таких как те, что генерируются Privasis, становится ключевым фактором для развития инноваций в областях федеративного обучения и безопасных многосторонних вычислений. В традиционных подходах, требующих доступа к реальным данным, возникают серьезные препятствия, связанные с защитой личной информации и соблюдением нормативных требований. Синтетические данные, воссоздающие статистические характеристики исходного набора, позволяют проводить исследования и разрабатывать модели без раскрытия конфиденциальной информации. Это особенно важно для организаций, работающих с чувствительными данными в сферах здравоохранения, финансов и государственного управления. Возможность обмениваться и использовать синтетические данные стимулирует сотрудничество и ускоряет прогресс в разработке алгоритмов и приложений, сохраняя при этом высокий уровень защиты персональных данных.
Тонкая настройка больших языковых моделей (LLM) на синтетических данных, сгенерированных Privasis, демонстрирует значительный потенциал для повышения надежности и обобщающей способности приложений, ориентированных на сохранение конфиденциальности. Исследования показывают, что модели, обученные на таких данных, способны лучше адаптироваться к различным сценариям и демонстрировать более устойчивые результаты, даже при наличии шума или неполноты исходной информации. Этот подход позволяет создавать более эффективные и безопасные решения в областях, где защита персональных данных является приоритетом, например, в федеративном обучении и безопасных многосторонних вычислениях, расширяя возможности применения LLM в чувствительных областях без компромиссов с конфиденциальностью.
Оценка разнообразия синтетических данных является критически важной задачей, поскольку недостаточная вариативность может привести к предвзятости и снижению эффективности моделей, обученных на этих данных. В связи с этим, показатель Vendi Embedding Score представляет собой ценный инструмент для количественной оценки этого аспекта. Данный показатель анализирует распределение данных в пространстве встраиваний, выявляя степень их разнообразия и позволяя сравнивать различные наборы синтетических данных. Высокий показатель Vendi Embedding Score свидетельствует о том, что синтетические данные охватывают широкий спектр возможных вариантов, что способствует более надежному и обобщающему обучению моделей. Использование Vendi Embedding Score в процессе генерации синтетических данных позволяет итеративно улучшать их качество, обеспечивая максимальное соответствие реальному распределению данных и снижая риск возникновения проблем, связанных с недостаточной вариативностью.
В дальнейшем, исследования будут направлены на полную автоматизацию итеративного процесса совершенствования синтетических данных. Это предполагает разработку алгоритмов, способных самостоятельно оценивать качество генерируемых наборов данных и автоматически корректировать параметры генерации для достижения оптимальных результатов. Параллельно планируется расширение спектра вспомогательных управляющих переменных, что позволит создавать еще более реалистичные и разнообразные наборы данных, точно отражающие сложность и нюансы реальных данных. Такой подход позволит значительно упростить процесс генерации синтетических данных, сделать его более эффективным и доступным для широкого круга пользователей, а также повысить надежность и применимость полученных данных в различных областях, таких как машинное обучение и анализ данных.
Исследование представляет собой не просто создание синтетического набора данных, но и попытку взломать саму концепцию приватности, подвергнув её глубокому анализу. Авторы, подобно инженерам, занимающимся реверс-инжинирингом, создали Privasis, чтобы понять границы возможного в области защиты данных. Как однажды заметил Клод Шеннон: «Теория коммуникации имеет дело с точным определением, что такое информация». Подобно тому, как Шеннон стремился к точному определению информации, Privasis стремится к точному определению и измерению приватности, создавая платформу для оценки и улучшения методов защиты данных. Этот подход позволяет не только создавать более безопасные системы, но и выявлять уязвимости, которые ранее оставались незамеченными.
Куда же дальше?
Создание Privasis, пусть и масштабного, синтетического набора данных, лишь обнажает глубину проблемы: достаточно ли вообще «безопасных» данных? Ведь сама идея «синтеза» подразумевает построение модели реальности, а любая модель — это упрощение, неизбежно искажающее истину. Следующий шаг — не просто генерация данных, а разработка методов верификации их истинной приватности, не полагаясь на статистические метрики, а, возможно, используя принципы теории информации или даже квантовой криптографии. Проверка на прочность существующим алгоритмам защиты данных — это, конечно, необходимо, но гораздо интереснее — найти принципиально новые подходы, основанные на понимании природы информации.
Ирония заключается в том, что, стремясь создать «безопасные» данные для обучения ИИ, исследователи неизбежно сталкиваются с задачей моделирования человеческого поведения и, следовательно, с его непредсказуемостью. Успех в этой области потребует не только технических инноваций, но и философского переосмысления самой концепции «приватности» в эпоху тотальной цифровизации. Необходимо понять, что защита данных — это не просто техническая задача, а постоянная игра в кошки-мышки, требующая от исследователей изобретательности и готовности к постоянному пересмотру своих методов.
В конечном счете, Privasis — это лишь отправная точка. Настоящий вызов — создание систем, способных к самообучению и адаптации в условиях постоянно меняющихся угроз. И, возможно, самое интересное — это не создание идеальных «безопасных» данных, а разработка алгоритмов, способных обнаруживать и нейтрализовывать утечки информации в режиме реального времени, превращая саму попытку взлома в источник знаний и улучшений.
Оригинал статьи: https://arxiv.org/pdf/2602.03183.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-05 04:53