Автор: Денис Аветисян
Новый подход использует самогенерируемые подсказки для повышения эффективности обучения больших языковых моделей в сложных средах с редким вознаграждением.
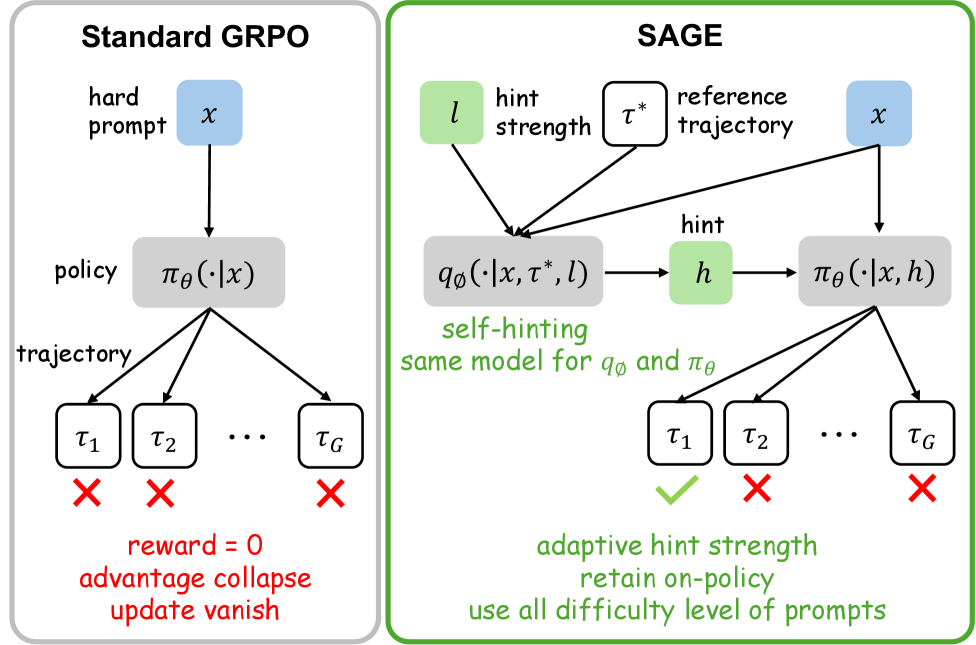
Предложен фреймворк SAGE, использующий самоподсказки для решения проблемы коллапса сигнала и улучшения обучения с подкреплением в задачах с разреженным вознаграждением.
Обучение больших языковых моделей с использованием обучения с подкреплением часто сталкивается с проблемой коллапса сигналов при разреженных терминальных вознаграждениях. В статье ‘Self-Hinting Language Models Enhance Reinforcement Learning’ предложен фреймворк SAGE, использующий самогенерируемые подсказки для повышения разнообразия траекторий и предотвращения исчезновения градиентов в процессе обучения. Эксперименты на шести бенчмарках с использованием трех LLM показали, что SAGE стабильно превосходит GRPO, демонстрируя прирост до +2.0 на Llama-3.2-3B-Instruct. Сможет ли данный подход к формированию подсказок стать ключевым элементом в создании более эффективных и надежных систем обучения с подкреплением для больших языковых моделей?
Суть Проблемы: Редкое Вознаграждение в Обучении с Подкреплением
Обучение с подкреплением (RL) играет ключевую роль в согласовании больших языковых моделей с намерениями человека, однако эффективность этого подхода существенно снижается в средах, где вознаграждение выдается лишь в конце выполнения задачи — так называемые “разреженные” вознаграждения. В таких условиях модели сталкиваются с трудностями в определении, какие действия приводят к положительному результату, поскольку обратная связь поступает крайне редко и запаздывает. Это затрудняет процесс исследования пространства возможных действий и приводит к неэффективному обучению, поскольку модель может долгое время не обнаруживать полезные стратегии, необходимые для достижения цели. Использование RL для согласования больших языковых моделей требует решения проблемы разреженных вознаграждений, чтобы обеспечить стабильное и быстрое обучение.
Традиционные методы обучения с подкреплением часто сталкиваются с трудностями в ситуациях, когда обратная связь поступает с задержкой или является редкой. Это приводит к неэффективному исследованию пространства состояний, поскольку агент тратит значительное время на действия, которые не приносят немедленного вознаграждения. В результате, процесс обучения может застопориться, особенно в сложных средах, где полезные сигналы трудно обнаружить среди множества возможных действий. Агент может застрять в локальных оптимумах или просто не суметь найти путь к желаемой цели из-за недостатка информации для корректировки своей стратегии. Таким образом, проблема редких и отложенных вознаграждений представляет собой существенное препятствие для успешного применения обучения с подкреплением в реальных задачах.
Сложность освоения обучения с подкреплением в средах с редкими наградами усугубляется присущими высокоразмерным пространствам действий и сложным окружениям трудностями в процессе исследования. Когда количество возможных действий огромно, а окружение представляет собой запутанную систему взаимосвязей, агент сталкивается с экспоненциально возрастающей задачей поиска эффективных стратегий. Исследование становится не просто выбором действия, но и навигацией по бесчисленным комбинациям, что требует огромного количества проб и ошибок. В таких условиях даже случайные попытки поиска оптимального решения могут оказаться неэффективными, поскольку полезный сигнал от редкой награды тонет в шуме случайных действий. Это создает серьезные препятствия для обучения, поскольку агент не получает достаточного количества информации для коррекции своей стратегии и прогресса в решении поставленной задачи.
В процессе обучения с подкреплением, особенно в сложных средах, возникает проблема, известная как “коллапс преимущества”. Суть ее заключается в том, что различия в эффективности между отдельными агентами (или элементами группы агентов) постепенно нивелируются. Изначально, небольшие преимущества в освоении навыков или стратегий могут казаться значимыми, однако при отсутствии достаточного сигнала вознаграждения, эти преимущества не закрепляются и не усиливаются. Вместо этого, агенты начинают демонстрировать схожие, часто неоптимальные, стратегии поведения, что приводит к стагнации процесса обучения. Данное явление особенно остро проявляется при редких и отложенных сигналах вознаграждения, когда агентам сложно определить, какие действия привели к успеху, и, соответственно, усилить соответствующие стратегии. В результате, процесс обучения может остановиться, даже если оптимальное решение существует, поскольку агенты не способны эффективно дифференцировать успешные и неудачные действия.
SAGE: Расширение GRPO с Использованием Само-Подсказок
SAGE — это методика, расширяющая алгоритм Group Relative Policy Optimization (GRPO) за счет внедрения само-подсказок (self-hinting) и динамического планировщика подсказок. Данный подход позволяет улучшить процесс обучения агента путем предоставления дополнительной информации, генерируемой самим агентом, а также адаптации интенсивности этих подсказок в зависимости от динамики обучения внутри групп агентов. В отличие от стандартного GRPO, SAGE использует механизм само-подсказок для формирования более эффективной стратегии исследования пространства состояний, что способствует достижению лучших результатов в сложных средах. Динамический планировщик подсказок оптимизирует использование ресурсов, активируя подсказки только в тех случаях, когда внутригрупповые награды демонстрируют тенденцию к сходимости, тем самым максимизируя влияние подсказок на процесс обучения.
Метод SAGE использует подход “Привилегированной подсказки” (Privileged Hinting) для предоставления дополнительной информации в процессе обучения агента. Это достигается путем обучения «привилегированного» агента, имеющего доступ к полному состоянию среды и оптимальной стратегии, для генерации подсказок, направляющих обучение основной политики. Данные подсказки, представляющие собой вероятностные распределения действий, эффективно формируют процесс исследования, стимулируя агента к посещению перспективных областей пространства состояний и ускоряя сходимость к оптимальной политике. В отличие от традиционных методов обучения с подкреплением, где исследование осуществляется случайным образом, привилегированные подсказки предоставляют целенаправленное руководство, улучшая эффективность обучения и позволяя агенту быстрее адаптироваться к сложным задачам.
Механизм динамической силы подсказок в SAGE активирует подсказки только при снижении внутригрупповых вознаграждений. Данный планировщик оценивает дисперсию вознаграждений внутри каждой группы агентов; при ее уменьшении, что свидетельствует о сходимости к субоптимальному решению, сила подсказок увеличивается. Это позволяет направлять исследование в областях пространства состояний, где агенты демонстрируют схожее поведение и нуждаются в дополнительной информации для диверсификации стратегий. Использование силы подсказок, зависящей от поведения агентов, максимизирует эффективность обучения и предотвращает ненужное вмешательство в процесс исследования при достаточном уровне диверсификации внутри группы.
Ключевым аспектом SAGE является схема онлайн-подсказок (online self-hinting), обеспечивающая периодическое обновление распределения подсказок в процессе обучения. Это достигается путем регулярного повторного сбора данных о производительности агента и перестройки распределения подсказок на их основе. Обновление производится периодически, что позволяет поддерживать калибровку подсказок и предотвращать их устаревание по мере изменения политики агента. Регулярное обновление позволяет системе адаптироваться к новым ситуациям и поддерживать эффективность подсказок на протяжении всего обучения, избегая ситуации, когда подсказки становятся нерелевантными или контрпродуктивными.
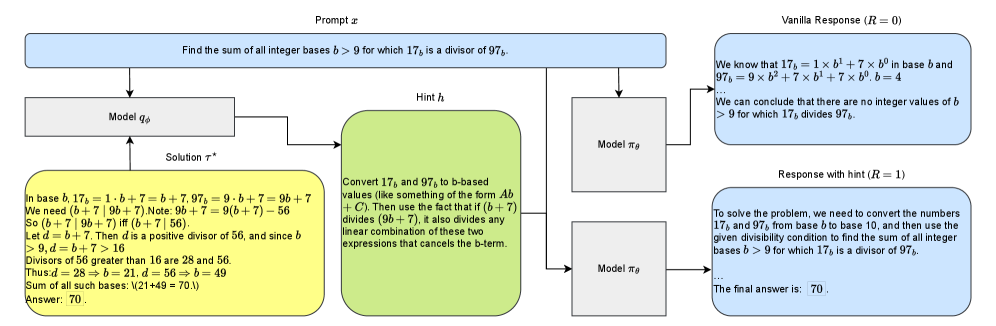
Стабилизация Обучения с Использованием Стандартизованных Преимуществ
Алгоритм SAGE использует стандартизованный метод GRPO (Generalized Advantage Estimation with Robust Policy Optimization) для повышения стабильности обучения и снижения дисперсии градиентов политики. Стандартизация предполагает нормализацию оценок преимущества, что позволяет масштабировать их и центрировать вокруг нуля. Это, в свою очередь, уменьшает влияние выбросов и предотвращает чрезмерно агрессивные обновления политики, что особенно важно в задачах обучения с подкреплением в высокоразмерных пространствах состояний и действий. Применение стандартизованного GRPO способствует более согласованной и предсказуемой сходимости обучения, уменьшая необходимость в тонкой настройке гиперпараметров и повышая общую надежность алгоритма.
В SAGE для стабилизации обучения используется центрирование оценок преимущества (Mean-Centered Advantages). Данный подход заключается в вычитании среднего значения из каждой оценки преимущества, что приводит к их центрированию вокруг нуля. Это позволяет нормализовать разброс оценок и уменьшить влияние выбросов на процесс обновления политики. Математически, центрированная оценка преимущества \hat{A}_t вычисляется как A_t - \mathbb{E}[A_t] , где A_t — исходная оценка преимущества, а \mathbb{E}[A_t] — её математическое ожидание. Центрирование способствует более стабильному и предсказуемому обучению, особенно в задачах с высокой размерностью пространства состояний и действий.
Стандартизация преимуществ в SAGE снижает влияние выбросов на процесс обучения, предотвращая чрезмерно агрессивные обновления политики. Выбросы в оценках преимуществ могут возникать из-за случайных факторов в окружающей среде или неточностей в оценке функции ценности. Без стандартизации эти выбросы могут привести к значительным изменениям в политике, дестабилизирующим обучение. Стандартизация, в частности, центрирование оценок преимуществ вокруг нуля, ограничивает диапазон возможных значений, уменьшая вероятность того, что отдельные выбросы будут непропорционально влиять на градиенты политики и, следовательно, на процесс обучения.
В высокоразмерном обучении с подкреплением (RL) часто возникает проблема «штрафа за дисперсию» (Variance Penalty), которая проявляется в нестабильности обучения и снижении производительности. Стандартизация преимуществ в SAGE значительно снижает восприимчивость к этому эффекту. Высокая дисперсия оценок преимуществ может приводить к чрезмерно агрессивным обновлениям политики, вызывая колебания и затрудняя сходимость алгоритма. Снижение дисперсии, достигаемое стандартизацией, обеспечивает более плавные и предсказуемые обновления, что приводит к более стабильному обучению и, как следствие, к более согласованным результатам в различных условиях и задачах.
Влияние на Среды с Редким Вознаграждением
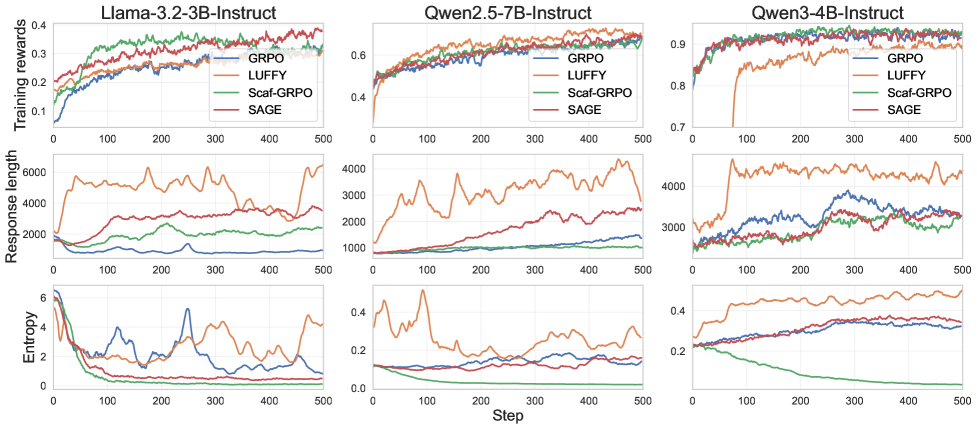
Экспериментальные результаты демонстрируют значительное улучшение скорости обучения и конечной производительности SAGE в условиях разреженного вознаграждения. В ходе исследований зафиксировано в среднем увеличение точности на 6.1% при использовании трех базовых моделей — Llama-3.2, Qwen2.5 и Qwen3. Данный прирост свидетельствует об эффективности SAGE в ситуациях, когда обратная связь поступает редко, что зачастую затрудняет процесс обучения. Повышение точности указывает на способность SAGE более эффективно извлекать полезную информацию из ограниченных сигналов вознаграждения и, как следствие, формировать более надежные и эффективные стратегии поведения.
Алгоритм SAGE успешно преодолевает трудности, связанные с коллапсом преимущества и задержкой обратной связи, что позволяет значительно повысить эффективность исследования и устойчивость обучения политик. Традиционные методы часто сталкиваются с проблемой, когда сигнал вознаграждения слишком редок, приводя к медленному обучению и нестабильным результатам. SAGE решает эту проблему, активно формируя полезные сигналы обучения даже в условиях скудного вознаграждения, что способствует более быстрому освоению сложных задач. Благодаря этому подходу, алгоритм способен адаптироваться к разнообразным средам и демонстрировать надежную производительность, что подтверждается экспериментальными данными и результатами, полученными на различных базовых моделях.
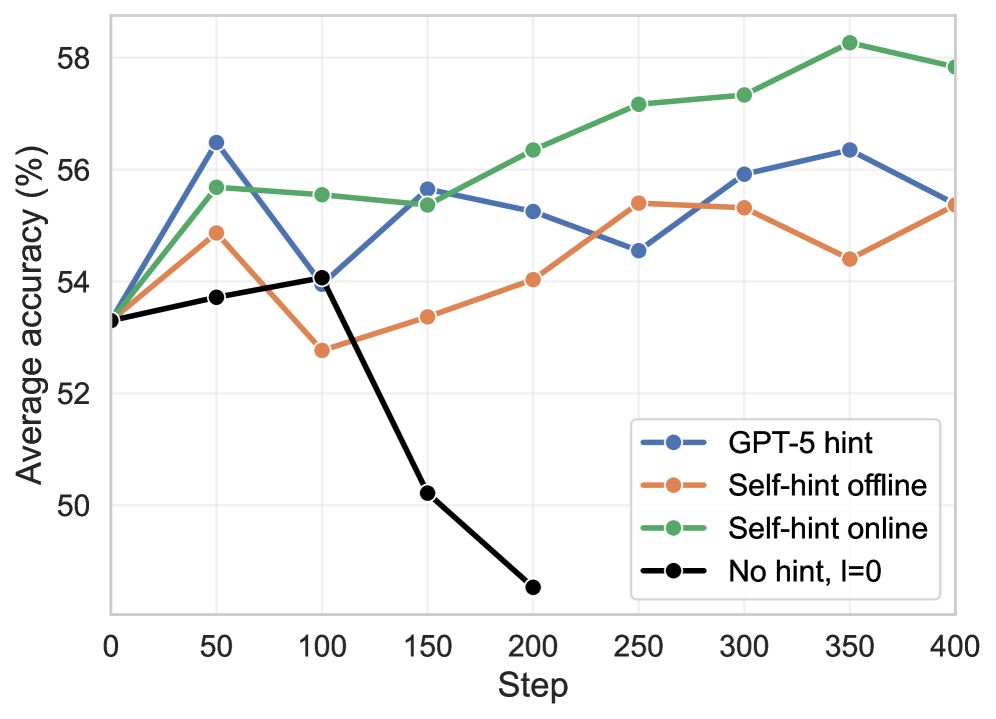
Адаптивный планировщик подсказок демонстрирует значительное повышение эффективности обучения, увеличивая количество успешно используемых подсказок на этапе тренировки на 10% при использовании модели Llama-3.2. Этот результат указывает на то, что система способна более эффективно извлекать полезную информацию из сложных примеров, которые традиционно представляют трудности для обучения с подкреплением. Вместо использования фиксированного расписания подсказок, данный подход динамически адаптируется к текущему состоянию обучения, предоставляя подсказки именно тогда, когда они наиболее необходимы для коррекции поведения модели и улучшения её способности к решению задач в условиях разреженного вознаграждения. Повышение количества успешно утилизированных подсказок свидетельствует о том, что модель получает больше осмысленных сигналов обучения, что, в свою очередь, приводит к более быстрому и надежному освоению сложных навыков.
Исследования показали, что частота активации подсказок — величина, определяемая как произведение количества эпизодов обучения (G) на вероятность успешного выполнения действия (p) — демонстрирует линейную зависимость. Это указывает на прямое соответствие между частотой использования подсказок и интенсивностью обучающего сигнала. Повышение частоты активации, обусловленное более эффективным исследованием пространства состояний, способствует более быстрому обучению агента. При этом, в отличие от некоторых других методов, SAGE поддерживает умеренную энтропию в процессе обучения, что, согласно данным, представленным на рисунке 4, позволяет избежать преждевременной сходимости к локальным оптимумам и обеспечивает более устойчивое и эффективное освоение сложных задач в условиях редкого вознаграждения.
Исследование демонстрирует стремление к математической чистоте в области обучения с подкреплением. Предложенный фреймворк SAGE, использующий самогенерируемые подсказки для борьбы с коллапсом сигнала в разреженных средах, напоминает о необходимости доказуемости алгоритмов. Как однажды заметил Давид Гильберт: «В математике нет спектра. Есть только математика.» Это высказывание отражает суть подхода, представленного в статье: стремление к элегантности и точности, где каждая подсказка, каждый шаг алгоритма должен быть обоснован и предсказуем. Использование самогенерируемых подсказок для улучшения эффективности обучения подтверждает, что алгоритм должен быть доказуем, а не просто «работать на тестах».
Что Дальше?
Представленная работа, безусловно, демонстрирует элегантность подхода к проблеме разреженности вознаграждения. Однако, стоит признать, что генерация «подсказок» самим агентом — это лишь смещение проблемы, а не её решение. Истинная проверка — это доказательство, что эти «подсказки» действительно отражают некую внутреннюю структуру задачи, а не являются случайным шумом, замаскированным под полезный сигнал. В противном случае, мы имеем дело с изящной, но все же иллюзией прогресса.
Очевидным следующим шагом представляется формализация понятия «хорошей подсказки». Необходимо разработать метрики, позволяющие объективно оценивать качество генерируемых подсказок вне зависимости от наблюдаемого поведения агента. Более того, представляется интересным исследовать возможность обучения модели генерировать подсказки, не опираясь на непосредственный опыт обучения с подкреплением, а используя лишь априорные знания о задаче — в идеале, формальную спецификацию.
В конечном счете, задача не в том, чтобы научить агента «хитрить» и обходить трудности с помощью подсказок, а в том, чтобы создать алгоритм, способный к истинному обобщению и адаптации. Пока же, это лишь очередная демонстрация того, что даже самые сложные системы могут быть уязвимы к искусственно созданным артефактам, скрывающим фундаментальные недостатки в самом подходе.
Оригинал статьи: https://arxiv.org/pdf/2602.03143.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Экзотические разложения: новые грани цилиндрической алгебры
- Навыки агентов: Новый уровень интеллекта ИИ
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Иллюзия Компетентности: Как ИИ Переоценивает Себя
2026-02-05 06:34