Автор: Денис Аветисян
Новый подход к выявлению ключевых научных вопросов объединяет возможности искусственного интеллекта и экспертизу ученых, позволяя прогнозировать перспективные направления исследований.
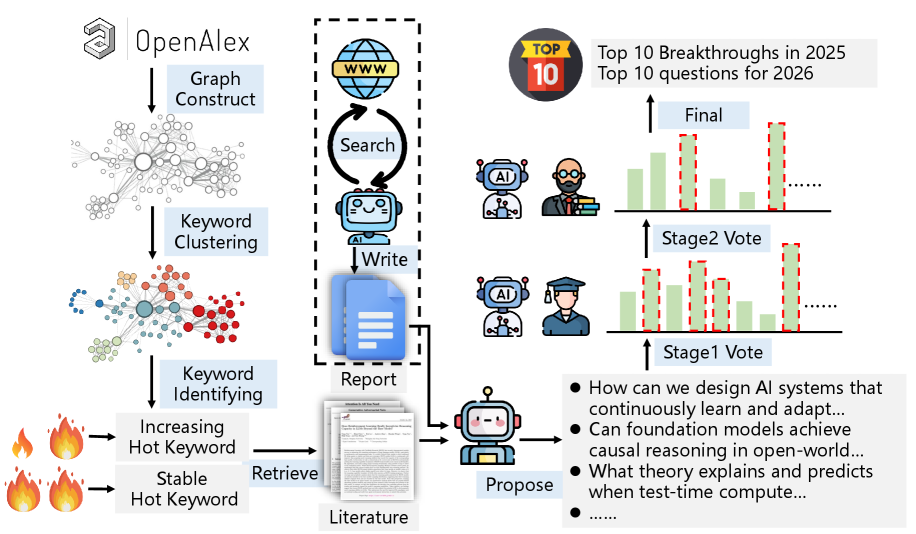
В статье представлена гибридная методология, сочетающая анализ научной литературы с помощью больших языковых моделей и критическую оценку специалистов для выявления прорывных научных задач.
Несмотря на стремительное развитие автоматизированных систем научных исследований, вопрос о способности искусственного интеллекта самостоятельно формулировать значимые исследовательские вопросы остается открытым. В работе ‘HybridQuestion: Human-AI Collaboration for Identifying High-Impact Research Questions’ предложен гибридный подход, объединяющий возможности масштабной обработки данных ИИ с экспертной оценкой человека, для выявления ключевых научных прорывов и перспективных задач. Полученные результаты показывают, что ИИ успешно идентифицирует признанные достижения, однако для прогнозирования будущих вызовов необходим критический анализ с участием человека. Возможно ли создание действительно автономной системы, способной не только анализировать научные данные, но и предвосхищать направления развития науки?
Раскрытие Динамики Науки: Новый Взгляд на Анализ
Традиционные обзоры научной литературы зачастую испытывают трудности в отслеживании динамических изменений в фокусе исследований, поскольку в значительной степени полагаются на субъективные оценки и интерпретации. Анализ существующих работ, как правило, основан на экспертном мнении, что может приводить к искажению картины развития науки и упущению новых, зарождающихся направлений. Сложность заключается в том, что научные тренды постоянно эволюционируют, и ручной анализ большого объема публикаций не позволяет оперативно выявлять эти изменения. В результате, существующие обзоры могут представлять лишь моментальный снимок, не отражающий текущую динамику и перспективные области исследований, что снижает их ценность для ученых и специалистов, стремящихся быть в курсе последних достижений.
Для объективной оценки динамики научных исследований и выявления перспективных направлений требуется переход к методам, основанным на анализе данных. Вместо субъективных оценок, традиционных для обзоров литературы, предлагается количественная оценка значимости исследований, базирующаяся на анализе больших объемов научной информации. Такой подход позволяет выявить не только наиболее цитируемые работы, но и отследить изменения в тематической структуре науки, определить быстрорастущие области и потенциальные точки роста. Анализ данных позволяет выявить закономерности, которые остаются незамеченными при ручной обработке информации, предоставляя возможность более точно прогнозировать будущие тренды и оптимизировать распределение ресурсов в науке. Это особенно важно в условиях экспоненциального роста научной литературы, когда ручной анализ становится невозможным.
Количественная Оценка Научного Актуалитета: Индекс «Горячести»
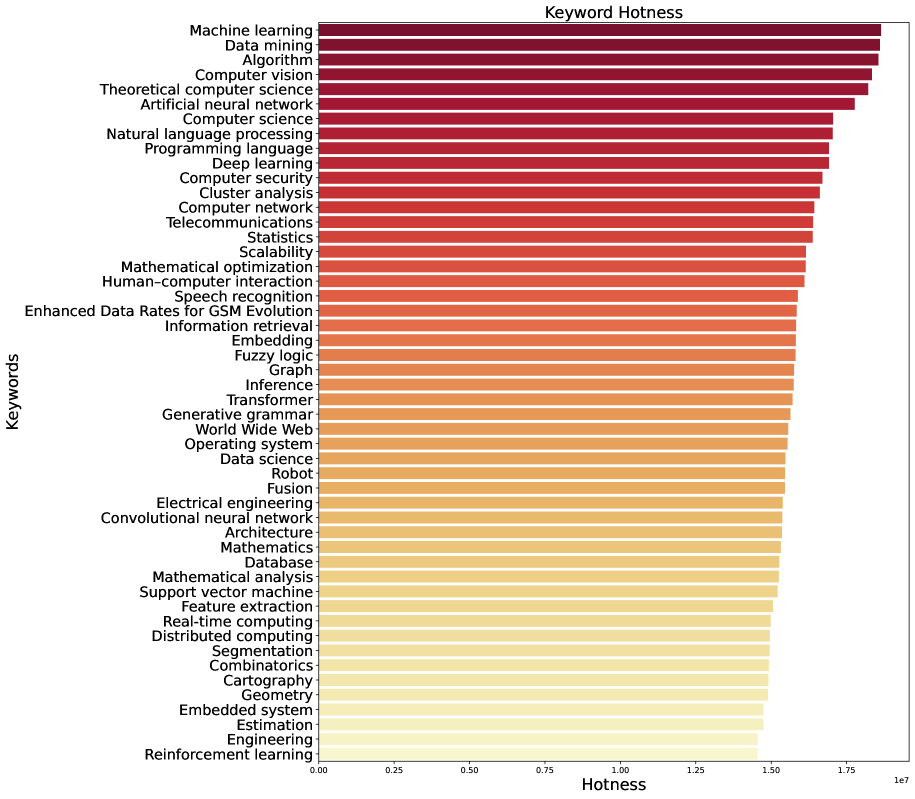
Для количественной оценки актуальности научных тем был разработан показатель «Индекс актуальности» (Hotness Score), основанный на использовании «встраиваний ключевых слов» (Keyword Embeddings). Эти встраивания генерируются на основе данных о публикациях, полученных из базы данных OpenAlex, и отражают семантическую плотность ключевых слов в научной литературе. По сути, данный показатель измеряет концентрацию и интенсивность использования определенных ключевых слов, что позволяет выявить темы, демонстрирующие рост популярности и, следовательно, повышенное внимание научного сообщества. Индекс актуальности представляет собой числовую оценку, отражающую степень «горячести» или актуальности конкретной научной области в определенный период времени.
Для уточнения семантического представления ключевых слов, частота их упоминания в публикациях взвешивается с использованием Gaussian Kernel. Этот метод придает больший вес более редким, но потенциально значимым терминам, в отличие от часто встречающихся, но менее информативных слов. Далее, алгоритм Node2vec применяется для создания векторных представлений (embeddings) этих взвешенных ключевых слов, учитывая их взаимосвязи и контекст в графе публикаций. Это позволяет получить более детальное и нюансированное семантическое представление, отражающее не только частоту, но и взаимосвязанность ключевых слов в научной литературе.
Оценка “температуры” (Hotness Score) позволяет объективно измерить ежегодную значимость ключевых слов в научной литературе. Данный показатель рассчитывается на основе анализа частоты употребления ключевых слов в публикациях, индексируемых в базе данных OpenAlex, и позволяет выявлять быстро развивающиеся области исследований. Высокие значения Hotness Score для определенного ключевого слова указывают на его возрастающую популярность и, следовательно, на растущий интерес научного сообщества к соответствующей теме. Таким образом, метрика служит инструментом для мониторинга трендов и выявления перспективных направлений научных исследований, предоставляя количественную оценку динамики развития тематик.
Раскрытие Тематических Кластеров: Гибридный Подход к Анализу
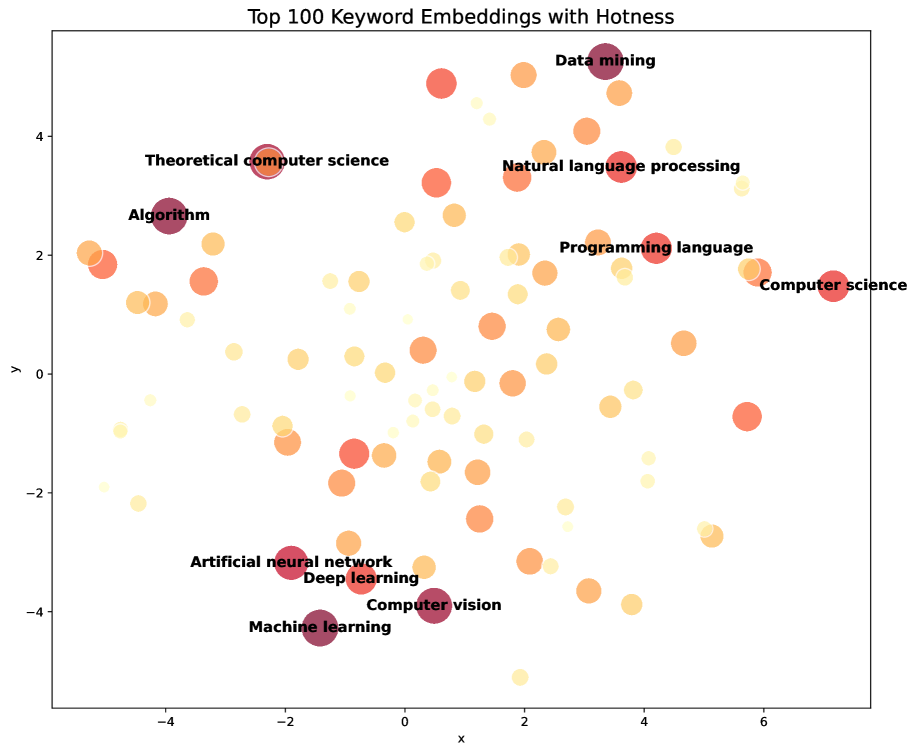
Для выявления тематических связей между ключевыми словами, как внутри отдельных дисциплин, так и между ними, был применен алгоритм ‘Hotness-Priority Greedy Clustering’. Данный метод группирует ключевые слова на основе их ‘Hotness Scores’ — показателей, отражающих актуальность и востребованность темы. Алгоритм итеративно объединяет ключевые слова с наибольшими показателями ‘Hotness’, формируя кластеры, которые представляют собой тематические группы. Применение данного подхода позволило автоматизировать процесс выявления тематических областей и установить взаимосвязи между различными научными направлениями, основываясь на количественной оценке актуальности ключевых слов.
Для уточнения и интерпретации кластеров ключевых слов, полученных в результате алгоритма ‘Hotness-Priority Greedy Clustering’, была использована схема гибридного интеллекта, объединяющая возможности больших языковых моделей (LLM) и экспертную валидацию. Данный подход предполагает последовательное применение LLM для предварительной обработки и анализа кластеров, за которым следует оценка и корректировка результатов экспертами в предметной области. Эксперты использовали различные методы голосования, включая ‘Approval Voting’ и ‘Limited Voting’, для оценки релевантности и значимости кластеров, а степень согласованности между результатами, полученными LLM и экспертами, измерялась с помощью метрики Jensen-Shannon (JS) Distance. Целью использования гибридного подхода являлось повышение точности и надежности интерпретации тематических кластеров, а также снижение влияния потенциальных искажений, присущих как автоматическим алгоритмам, так и субъективным оценкам экспертов.
В рамках предложенной системы для определения тематических кластеров использовались различные методы голосования, включая “Approval Voting” (утверждающее голосование), позволяющее экспертам одобрять несколько вариантов, и “Limited Voting” (ограниченное голосование), где каждый эксперт имеет фиксированное количество голосов для распределения между предложенными темами. Для оценки согласованности между результатами, полученными от экспертов и алгоритмов машинного обучения, применялась метрика Jensen-Shannon (JS) Distance. JS(P||Q) = \frac{1}{2}D(P||\frac{P+Q}{2}) + \frac{1}{2}D(Q||\frac{P+Q}{2}), где D — divergence (расхождение) Кульбака-Лейблера. Использование нескольких методов голосования и количественная оценка согласованности с помощью JS Distance позволили повысить надежность и валидность выделенных тематических кластеров.
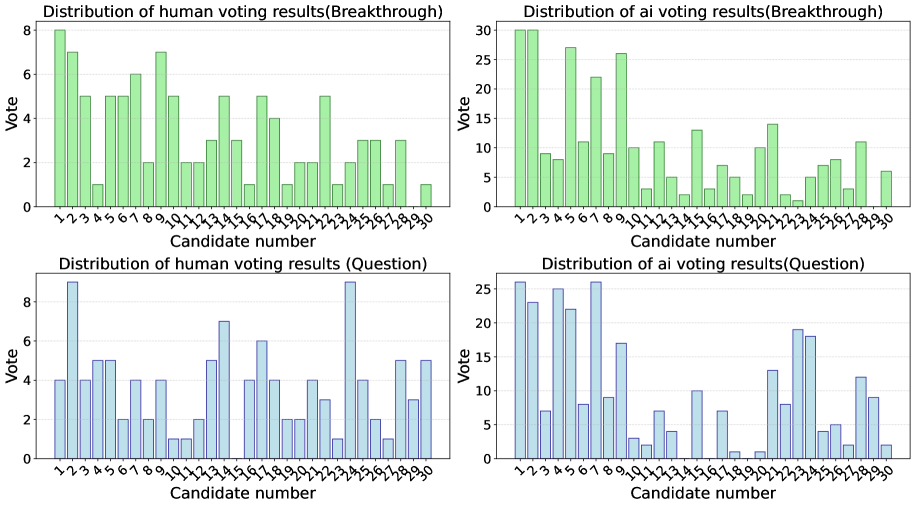
При анализе результатов кластеризации, использовался показатель расхождения Йенсена-Шеннона (JS Distance) для оценки согласованности между голосованием экспертов и алгоритмов искусственного интеллекта. На первом этапе (Stage 1), при выявлении общепризнанных прорывов, значение JS Distance составило 0.394, что указывало на умеренное расхождение в оценках. Однако, на втором этапе (Stage 2), после применения механизмов уточнения и интеграции знаний, данный показатель снизился до 0.209. Данное снижение демонстрирует улучшение согласованности между экспертными оценками и результатами, полученными с помощью искусственного интеллекта, что свидетельствует о повышении эффективности гибридного подхода к выявлению тематических кластеров.
Для снижения предвзятости и повышения надежности генерации предложений использовались методы ‘Ensemble Voting’ (ансамблевое голосование) и ‘Deep Research’ (глубокое исследование). ‘Ensemble Voting’ предполагает агрегацию результатов голосования различных моделей и экспертов, что позволяет снизить влияние отдельных ошибок или субъективных оценок. ‘Deep Research’ включает в себя многоуровневый анализ данных, охватывающий как количественные показатели, так и качественную оценку релевантности и новизны, что способствует более обоснованному отбору предложений и минимизации рисков, связанных с неполной или искаженной информацией. Комбинация этих подходов позволила сформировать более устойчивый и репрезентативный набор предложений, отражающий широкий спектр перспективных направлений исследований.
От Прорывов к Будущим Вопросам: Оценка Влияния и Перспектив
Анализ позволил выделить ключевые научные прорывы, подтвердив их значимость благодаря подходу, основанному на данных. Вместо субъективных оценок, методика позволила объективно идентифицировать наиболее влиятельные достижения, используя количественные показатели и статистический анализ. Этот процесс выявил не только общепризнанные вехи в науке, но и прорывы, которые, возможно, не сразу получили широкое признание, но оказали существенное влияние на дальнейшее развитие исследований. Выделение этих прорывов обеспечивает ценную отправную точку для понимания текущего состояния науки и определения направлений для будущих открытий, предлагая надежную основу для дальнейших исследований и инноваций.
Предложенный метод анализа не только подтверждает значимость давно установленных направлений научных исследований, но и эффективно выявляет области, демонстрирующие стремительный рост и повышенный интерес. Этот подход позволяет отследить динамику развития науки, выявляя перспективные темы и перспективные научные группы. В результате, становится возможным более точно оценить текущее состояние различных дисциплин, определить ключевые тренды и прогнозировать будущие направления научных изысканий, что особенно ценно для планирования финансирования и распределения ресурсов в научной сфере. Такая способность к выявлению как устоявшихся, так и быстро развивающихся областей делает данный метод незаменимым инструментом для исследователей, политиков и всех, кто заинтересован в будущем науки.
Анализ выявил ключевые научные вопросы, определяющие перспективы исследований в различных областях. В то время как согласованность между результатами, полученными человеком и искусственным интеллектом, оказалась высокой при определении уже состоявшихся прорывов, показатель расхождения, измеренный с помощью дистанции Дженсена-Шеннона и составивший 0.352 на втором этапе анализа, указывает на необходимость дальнейшего привлечения экспертной оценки при выявлении наиболее перспективных направлений будущих исследований. Это подчеркивает, что, несмотря на успехи искусственного интеллекта в анализе накопленных знаний, способность предвидеть и формулировать принципиально новые научные задачи пока остается прерогативой человеческого интеллекта и критического мышления.
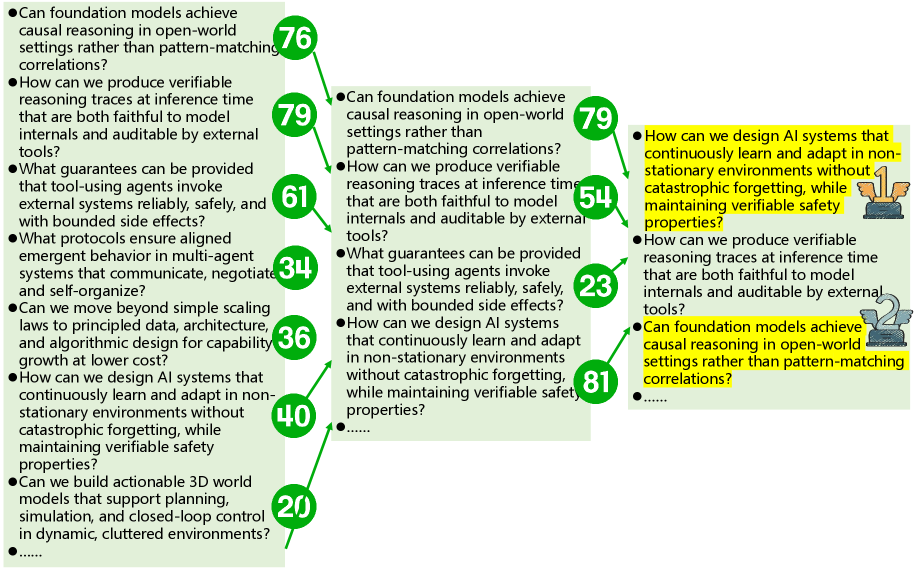
Исследование, представленное в статье, демонстрирует, что искусственный интеллект превосходно анализирует прошлые научные достижения, выявляя закономерности и тренды. Однако, когда речь заходит о прогнозировании будущих прорывов, требуется критический взгляд человека. Этот симбиоз, где машина обрабатывает огромные объемы данных, а разум оценивает перспективы, позволяет выделить действительно значимые вопросы для науки. Как однажды заметил Линус Торвальдс: «Плохой код похож на плохую шутку: если тебе нужно объяснить её, она не смешная.». Аналогично, если ИИ не может самостоятельно определить важность вопроса, его анализ требует осмысления человеком, чтобы выявить истинный потенциал научного поиска.
Куда Дальше?
Представленная работа, по сути, лишь обнажила краешек айсберга. Искусственный интеллект, безусловно, продемонстрировал впечатляющую способность к ретроспективному анализу — распознаванию уже свершившихся прорывов. Однако, предсказание истинно значимых вопросов, стоящих перед наукой, требует не просто обработки данных, но и интуитивного понимания контекста, способности к абдуктивному мышлению — качества, пока еще слабо поддающегося алгоритмизации. Это не недостаток машины, но напоминание о том, что сама структура знания не линейна, а представляет собой сеть взаимосвязанных, часто противоречивых гипотез.
Очевидным направлением дальнейших исследований представляется разработка более сложных метрик для оценки “значимости” научного вопроса. Существующие показатели, как правило, опираются на косвенные свидетельства — цитируемость, частоту упоминаний — и не учитывают потенциальную революционность идеи. Возможно, потребуется интеграция элементов теории игр, моделирование взаимодействия между научными группами, анализ “шума” в научной литературе — тех самых аномалий, которые часто предвещают прорыв.
В конечном счете, задача заключается не в создании искусственного “ученого”, способного самостоятельно генерировать гениальные идеи, а в построении симбиотической системы, в которой машина будет выступать в роли мощного инструмента для расширения когнитивных возможностей человека. Ведь, как показывает опыт, хаос — не враг, а зеркало архитектуры, отражающее скрытые связи. И именно умение видеть этот порядок в беспорядке и отличает настоящего исследователя.
Оригинал статьи: https://arxiv.org/pdf/2602.03849.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Искусственный интеллект: хрупкость визуального мышления
- Квантовая механика: скрытый детерминизм?
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
- Текстуры обмана: Как взломать ИИ, управляющий роботами
2026-02-05 06:39