Автор: Денис Аветисян
Новый подход позволяет существующим робототехническим системам адаптироваться к новым задачам и окружению в реальном времени, используя возможности моделей, объединяющих зрение и язык.
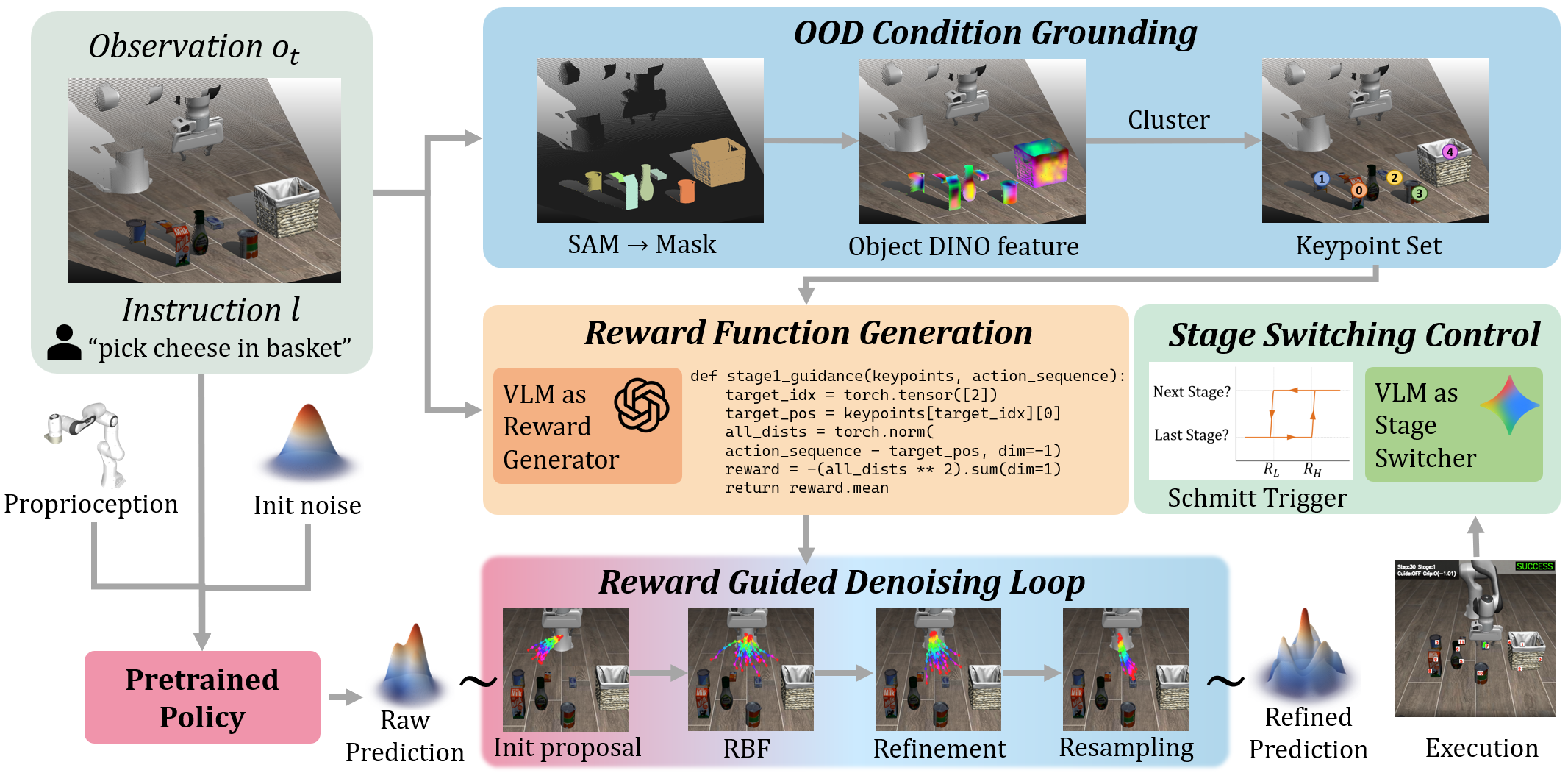
Метод Vision-Language Steering (VLS) позволяет направлять действия робота, генерируя дифференцируемые награды на основе визуального восприятия и языковых команд.
Несмотря на успехи предобученных политик робототехники, их производительность часто падает при незначительных изменениях окружающей среды или задачи. В данной работе, ‘VLS: Steering Pretrained Robot Policies via Vision-Language Models’, предлагается новый подход — Vision-Language Steering (VLS), позволяющий адаптировать замороженные генеративные политики роботов во время выполнения, без переобучения. VLS рассматривает адаптацию как задачу управления, используя модели «зрение-язык» для синтеза дифференцируемых функций вознаграждения, направляющих генерацию действий. Способен ли VLS обеспечить надежную и гибкую роботизированную манипуляцию в непредсказуемых условиях реального мира?
Разрыв между Симуляцией и Реальностью: Неизбежный Вызов
Одной из ключевых проблем в области робототехники является разрыв между симуляцией и реальностью, известный как “разрыв реальности”. Политики, разработанные и обученные в виртуальной среде, часто демонстрируют значительное снижение производительности при переходе к реальным условиям. Это связано с тем, что симуляции, несмотря на свою сложность, неизбежно упрощают физический мир, не учитывая все тонкости и непредсказуемые факторы, присутствующие в реальной среде. Такие факторы, как несовершенство сенсоров, неточности в моделировании трения, неожиданные изменения освещения или наличие немоделируемых объектов, могут существенно повлиять на работу робота, делая его поведение непредсказуемым и неэффективным. Преодоление этого разрыва требует разработки новых методов обучения, которые позволят роботам адаптироваться к неидеальным данным и неожиданным ситуациям, обеспечивая надежную и эффективную работу в реальном мире.
Роботизированные системы, обученные в контролируемых условиях симуляции, часто демонстрируют снижение производительности при столкновении с непредвиденными изменениями окружающей среды — так называемыми внераспределенными сценариями (OOD). Эти сценарии включают в себя вариации в освещении, текстурах поверхностей, наличии препятствий или даже незначительные изменения в физических параметрах объектов. В отличие от предсказуемой симуляции, реальный мир характеризуется непредсказуемостью, и даже небольшие отклонения от условий обучения могут привести к существенным ошибкам в работе робота. Например, изменение цвета объекта, на который робот должен ориентироваться, или появление не учтенной тени может привести к сбою в алгоритмах восприятия и, как следствие, к неверным действиям. Таким образом, способность робота сохранять работоспособность в условиях неопределенности и адаптироваться к новым, не предусмотренным ранее обстоятельствам является ключевой проблемой в области робототехники.
Существующие методы адаптации роботов к изменяющимся условиям зачастую оказываются хрупкими и неэффективными. В большинстве случаев, столкнувшись с незначительными отклонениями от запрограммированных сценариев или новыми, непредвиденными обстоятельствами, робот теряет способность эффективно функционировать. Это требует либо полной переподготовки системы, что является трудоемким и дорогостоящим процессом, либо сложной и ресурсоемкой переработки архитектуры управления. Подобная “негибкость” существенно ограничивает возможности широкого внедрения робототехники в динамичных и непредсказуемых реальных условиях, где даже небольшие изменения в окружающей среде могут привести к серьезным сбоям в работе.
Vision-Language Steering: Элегантное Решение Адаптации
Метод Vision-Language Steering (VLS) обеспечивает адаптацию предварительно обученных политик управления роботом в реальном времени, без необходимости дополнительного обучения или обновления весов модели. Это достигается за счет использования внешнего сигнала, основанного на интерпретации визуальных данных и языковых инструкций, что позволяет политике корректировать свое поведение непосредственно в процессе выполнения задачи. VLS позволяет роботу адаптироваться к новым условиям и целям без прерывания работы и без необходимости повторного обучения, что существенно повышает гибкость и эффективность системы в динамичной среде. Адаптация происходит “на лету”, используя текущие наблюдения и языковые указания для корректировки процесса выборки действий.
В основе Vision-Language Steering (VLS) лежит использование Визуально-Языковой Модели (VLM) для анализа визуальных данных, получаемых от робота, и генерации Дифференцируемой Функции Вознаграждения. VLM, обученная на больших объемах данных, способна сопоставлять визуальные признаки с текстовыми описаниями, позволяя интерпретировать текущее состояние окружающей среды и цели задачи. Сгенерированная функция вознаграждения представляет собой числовую оценку каждого действия робота, отражающую его соответствие заданным требованиям и визуальному контексту. Важно, что эта функция является дифференцируемой, что позволяет использовать градиентный спуск для оптимизации поведения робота без необходимости обновления весов самой модели VLM или базовой политики.
Генерируемая функция вознаграждения, основанная на анализе визуальных данных и языковых команд, напрямую влияет на процесс выборки действий политикой робота. Вместо традиционной переподготовки весов модели, эта функция изменяет вероятности выбора различных действий, направляя политику к более желаемому поведению в новых условиях. Это позволяет адаптировать политику «на лету», без необходимости хранения и обновления параметров модели, что значительно снижает вычислительные затраты и требования к памяти. По сути, функция вознаграждения выступает в роли динамически изменяющегося «руля», корректирующего траекторию поведения робота в процессе выполнения задачи.
Система использует пересемплирование Фейнмана-Каца (FK Resampling) для уточнения траекторий движения робота на основе сгенерированной функции вознаграждения. FK Resampling представляет собой метод Монте-Карло, позволяющий оценить интеграл, определяющий оптимальную траекторию. В данном контексте, функция вознаграждения, полученная от Визуально-Языковой Модели (VLM), используется как мера «желательности» каждой траектории. Алгоритм FK Resampling взвешивает различные траектории пропорционально экспоненте от интеграла функции вознаграждения вдоль этой траектории E[\in t_0^T r(s) ds], где r(s) — функция вознаграждения в момент времени s, а T — горизонт планирования. Это позволяет перераспределить вероятность между траекториями, отбирая наиболее перспективные и корректируя поведение робота без обновления весов модели.
Оценка Надежности в Сложных Условиях: Строгий Эксперимент
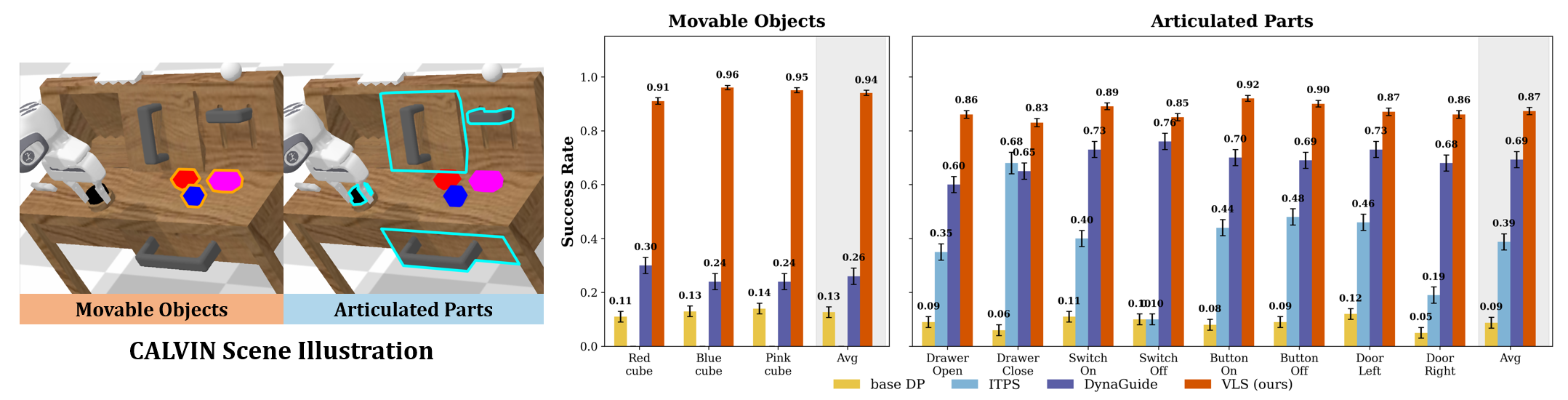
Система VLS проходила всестороннее тестирование на манипуляционных платформах CALVIN и LIBERO-PRO, разработанных специально для оценки способности к обобщению на данные, отличные от обучающей выборки (OOD generalization). Эти среды характеризуются высокой степенью вариативности в визуальных условиях и языковых инструкциях, что позволяет оценить устойчивость системы к непредсказуемым изменениям в реальных сценариях. Использование CALVIN и LIBERO-PRO позволило получить надежные данные о производительности VLS в условиях, выходящих за рамки стандартных бенчмарков, и сравнить её с другими методами адаптации к новым условиям.
Визуальный языковой модуль (VLM) в системе использует модели Segment Anything Model (SAM) и DINOv2 для обеспечения надежного визуального восприятия и извлечения ключевых точек. SAM позволяет выполнять сегментацию изображений с высокой точностью, автоматически выделяя объекты на изображении, что критически важно для понимания сцены. DINOv2, в свою очередь, обеспечивает надежное обнаружение и описание объектов, а также извлечение ключевых точек, необходимых для планирования действий манипулятора. Комбинация этих моделей позволяет системе эффективно обрабатывать визуальную информацию и адаптироваться к различным условиям освещения и ракурсам, что повышает общую надежность системы в сложных средах.
Система продемонстрировала способность к адаптации как к возмущениям в визуальном вводе (Observation Perturbation), включающим изменения в освещении, шумы и окклюзии, так и к возмущениям в языковых инструкциях (Language Perturbation), таким как перефразировки, синонимичные замены и добавление несущественной информации. Эта устойчивость достигается за счет использования надежных методов визуального понимания и механизмов адаптации, позволяющих поддерживать высокую производительность даже при наличии помех в сенсорных данных или нечетких формулировках задач. Экспериментальные данные подтверждают, что система сохраняет работоспособность и обеспечивает успешное выполнение задач в условиях, имитирующих реальные, зашумленные среды.
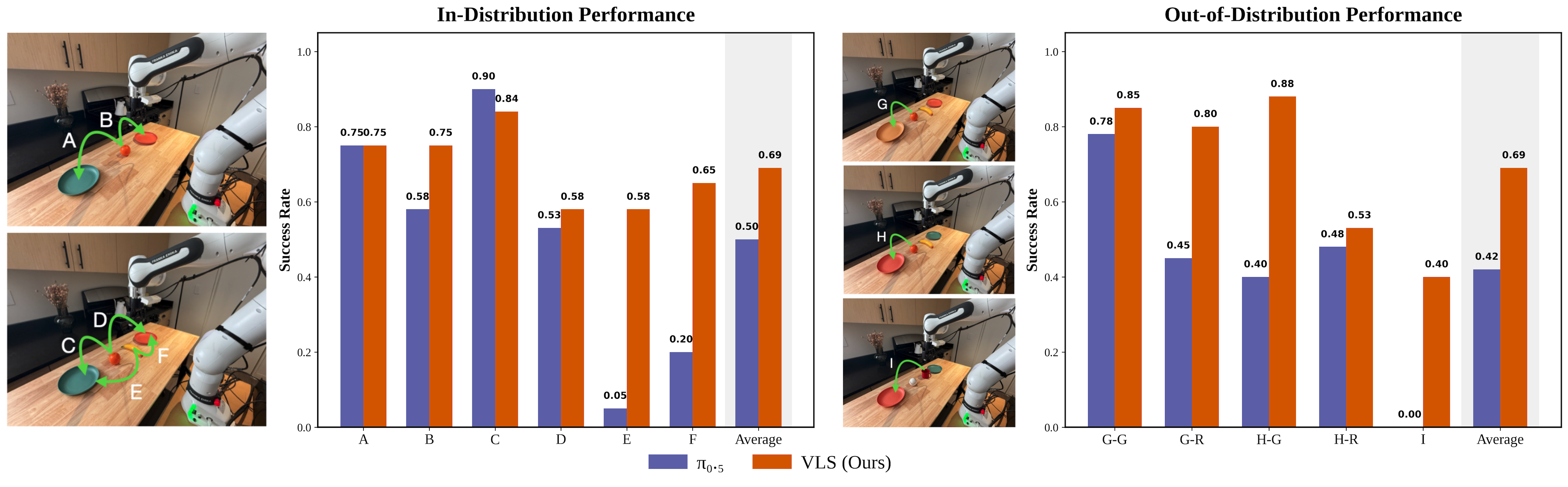
В ходе экспериментов, система VLS продемонстрировала превосходство над существующими методами адаптации во время выполнения, такими как DynaGuide и ITPS, в задачах с длинным горизонтом планирования. Наблюдается абсолютное увеличение показателя успешности до 31% по сравнению с альтернативными подходами. Данный результат подтверждает эффективность VLS в сценариях, требующих адаптации к изменяющимся условиям в процессе выполнения сложных манипуляций и демонстрирует значительный прогресс в области робототехники.

Практическое Внедрение и Перспективы Развития: Горизонты Автоматизации
Разработанная система обучения с подкреплением, обозначенная как VLS, была успешно протестирована и внедрена в работу с промышленным роботом Franka Emika. Это демонстрирует не только теоретическую обоснованность подхода, но и его практическую применимость в реальных задачах манипулирования объектами. Интеграция с роботом-манипулятором позволила подтвердить эффективность алгоритма в динамической среде, где требуется точное управление и адаптация к изменяющимся условиям. Успешное развертывание на Franka Emika подчеркивает потенциал VLS для автоматизации сложных производственных процессов и повышения гибкости роботизированных систем.
Для обеспечения стабильности процесса адаптации и предотвращения непредсказуемого поведения системы, в архитектуре VLS был реализован триггер Шмитта. Данное устройство выполняет функцию фильтрации входного сигнала, определяя четкий порог переключения между стадиями адаптации. Вместо мгновенного реагирования на незначительные колебания, триггер Шмитта требует превышения определенного значения для изменения состояния, что эффективно подавляет случайные переключения и обеспечивает плавный переход между этапами обучения. Благодаря этому решению система демонстрирует повышенную надежность и устойчивость в динамичных условиях реального мира, гарантируя предсказуемое и эффективное выполнение манипулятивных задач.
В основе стабильности и эффективности разработанной системы лежит принцип использования отталкивающей силы. Этот механизм играет ключевую роль в стимулировании исследования пространства возможных решений, предотвращая застревание алгоритма в локальных оптимумах. Вместо того чтобы стремиться исключительно к немедленному вознаграждению, система, благодаря отталкивающей силе, вынуждена постоянно оценивать альтернативные стратегии. Такой подход позволяет избежать коллапса политики в субоптимальных решениях, обеспечивая более надежное и гибкое поведение в различных условиях. По сути, отталкивающая сила действует как своего рода «внутренний критик», побуждая систему к поиску действительно оптимальных путей, а не довольствоваться первым попавшимся решением.
В ходе практических испытаний, система VLS продемонстрировала впечатляющие результаты в реальных задачах манипулирования. При выполнении стандартных операций, показатель успешного завершения составил 69%, что на 19% превосходит результаты базовой модели. Особенно примечательна устойчивость системы к изменениям в окружающей среде: даже при замене объектов, представляющих собой новые, не встречавшиеся ранее условия, VLS сохраняет 40%-ный уровень успешности. Данный результат свидетельствует о высокой адаптивности и надежности системы в условиях, требующих гибкого подхода к решению задач, и открывает перспективы для её применения в широком спектре робототехнических приложений.
Исследование демонстрирует элегантность подхода, основанного на математической точности. Авторы предлагают метод Vision-Language Steering (VLS), позволяющий предобученным робототехническим политикам адаптироваться к новым условиям без дополнительного обучения. Этот подход, использующий дифференцируемые награды, генерируемые моделями, обрабатывающими зрение и язык, напоминает стремление к безупречной логике в алгоритмах. Бертранд Рассел однажды сказал: «Всякая вера является в конечном счете несостоятельной, если она не может выдержать критику разума». Аналогично, VLS требует строгого определения наград для обеспечения корректного поведения робота в различных ситуациях, подчеркивая важность логической основы для достижения надежных результатов в робототехнике.
Что Дальше?
Представленный подход, безусловно, демонстрирует элегантность в обходе необходимости переобучения политик роботов. Однако, истинная проверка метода заключается не в успешной демонстрации на заранее подготовленных сценариях, а в его устойчивости к непредсказуемым, действительно новым условиям. Неизбежно возникает вопрос: насколько надёжно генерируемые языковой моделью “дифференцируемые награды” отражают истинные цели, особенно в ситуациях, где неоднозначность неизбежна? Простое решение, позволяющее роботу адаптироваться, не обязательно является коротким, оно должно быть непротиворечивым и логически завершённым.
Очевидным направлением дальнейших исследований представляется формализация понятия “доверия” к генерируемым наградам. Необходимо разработать метрики, позволяющие количественно оценить степень соответствия между языковым описанием задачи и фактическим поведением робота. Интересным представляется исследование возможности интеграции механизмов самопроверки, позволяющих роботу выявлять и корректировать потенциально ошибочные указания.
В конечном счёте, успех данного направления зависит от способности преодолеть фундаментальное противоречие: стремление к гибкости и адаптивности, с одной стороны, и необходимость сохранения детерминированности и предсказуемости поведения робота, с другой. Истинная элегантность алгоритма заключается не в скорости его работы, а в его математической чистоте и доказуемости.
Оригинал статьи: https://arxiv.org/pdf/2602.03973.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-05 09:54