Автор: Денис Аветисян
Новый бенчмарк SpatiaLab проверяет способность современных моделей, объединяющих зрение и язык, к пониманию и решению задач, требующих пространственного мышления в реальном мире.
Исследование выявляет существенные пробелы в пространственном рассуждении у современных моделей и подчеркивает необходимость разработки более надежных 3D- и физически-обоснованных представлений.
Несмотря на успехи современных моделей «зрение-язык», пространственное рассуждение остается сложной задачей для искусственного интеллекта. В данной работе представлена платформа SpatiaLab: Can Vision-Language Models Perform Spatial Reasoning in the Wild?, предназначенная для всесторонней оценки способности этих моделей к пониманию и анализу пространственных взаимосвязей в реалистичных условиях. Эксперименты с использованием различных моделей, включая как открытые, так и закрытые источники, выявили существенный разрыв в производительности по сравнению с человеческим восприятием, особенно в задачах, требующих понимания глубины, ориентации и навигации. Какие новые архитектуры и методы обучения необходимы для создания моделей, способных к надежному и интуитивному пространственному мышлению, сопоставимому с человеческим?
Определение Пространственного Мышления в Визуально-Языковых Моделях
Визуально-языковые модели (ВЯМ) демонстрируют впечатляющий прогресс в обработке информации, однако сталкиваются с существенными трудностями при решении задач, требующих развитого пространственного мышления. В то время как ВЯМ превосходно справляются с распознаванием объектов и пониманием текстовых инструкций, способность к точному определению местоположения, ориентации и взаимосвязи объектов в пространстве остается слабой стороной. Это проявляется в неспособности адекватно отвечать на вопросы, связанные с описанием сцен, навигацией в виртуальных средах или манипулированием объектами, что ограничивает возможности применения ВЯМ в таких областях, как робототехника, дополненная реальность и автономные системы. Несмотря на кажущуюся простоту понимания пространственных отношений для человека, модели испытывают сложности в абстрагировании и применении этих знаний в различных контекстах, что подчеркивает необходимость разработки более совершенных методов обучения и оценки.
Точность пространственного мышления имеет решающее значение для широкого спектра задач, требующих взаимодействия с окружающим миром. Например, для успешной навигации роботов в сложных условиях необходимо точное определение местоположения объектов и взаимосвязей между ними. Понимание сцены, будь то анализ изображений для автономного вождения или интерпретация медицинских снимков, напрямую зависит от способности модели воспринимать и обрабатывать пространственные отношения. Более того, выполнение сложных инструкций, например, «поместите красный куб слева от синего», требует не просто распознавания объектов, но и понимания их относительного положения в пространстве. Таким образом, развитие надежного пространственного мышления является ключевым шагом к созданию действительно интеллектуальных систем, способных эффективно взаимодействовать с физическим миром.
Существующие оценочные тесты для визуально-языковых моделей (ВЯМ) часто оказываются недостаточно глубокими и сложными, что приводит к завышенной оценке их способностей к пространственному мышлению. В то время как ВЯМ демонстрируют успехи в решении простых задач, они испытывают трудности при столкновении с более сложными, многоступенчатыми сценариями, требующими понимания относительного положения объектов, их взаимосвязей и изменений в пространстве. Это связано с тем, что многие текущие тесты фокусируются на распознавании отдельных объектов или простых отношений, не затрагивая более тонкие аспекты пространственного восприятия. В результате, модели могут успешно проходить эти тесты, не обладая при этом реальным пониманием пространственных принципов, что создает иллюзию более высокой эффективности, чем есть на самом деле.
Для преодоления ограничений существующих оценочных методик, разработан SpatiaLab — комплексная платформа, включающая в себя 1400 пар вопрос-ответ. Данный набор тщательно спроектирован для всестороннего анализа способности моделей, работающих с визуальной и языковой информацией, к пространственному мышлению. SpatiaLab охватывает широкий спектр сценариев, представляя собой строгий тест, позволяющий выявить истинный уровень понимания пространственных отношений моделями и определить области, требующие дальнейшего совершенствования. Целью создания SpatiaLab является обеспечение более точной и надежной оценки, способствующей развитию действительно интеллектуальных систем, способных к эффективному взаимодействию с окружающим миром.
SpatiaLab: Эталон для Оценки Пространственного Интеллекта
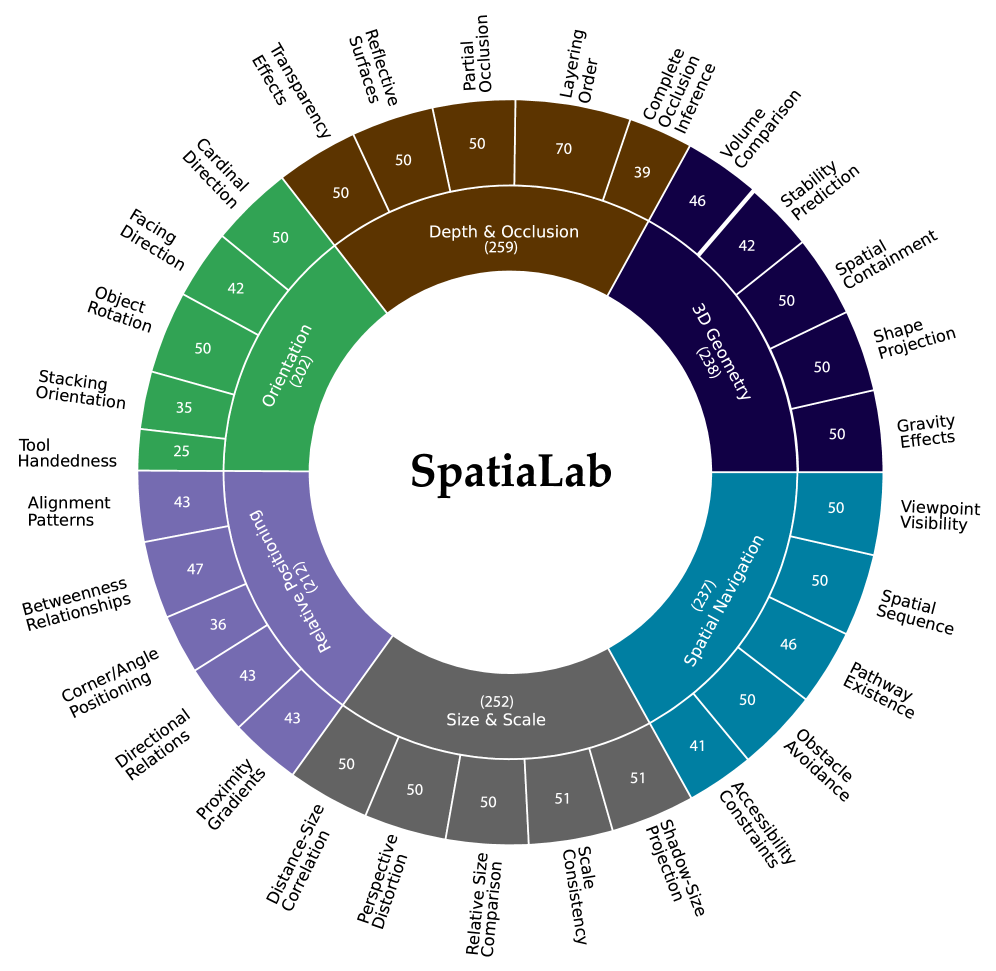
SpatiaLab — это новый эталон, состоящий из 1400 пар вопрос-ответ, разработанный для оценки пространственного мышления в мультимодальных моделях (VLM). Этот эталон предназначен для систематической проверки способности моделей понимать и рассуждать о пространственных отношениях, представленных на изображениях, и предоставлять точные ответы на вопросы, связанные с этими отношениями. Объем в 1400 вопросов обеспечивает статистически значимую оценку производительности различных VLM и позволяет проводить сравнительный анализ их возможностей в области пространственного интеллекта.
Спектр задач SpatiaLab охватывает шесть ключевых категорий пространственного мышления. Категория «Размер и масштаб» проверяет способность модели оценивать относительные размеры объектов и их пропорции. «3D-геометрия» включает в себя вопросы, требующие понимания трехмерных форм и их характеристик. «Глубина и окклюзия» оценивает способность модели определять глубину объектов и понимать, как они перекрывают друг друга. «Относительное положение» проверяет понимание пространственных отношений между объектами, например, «слева от», «над», «между». «Ориентация» оценивает способность модели определять и различать ориентацию объектов в пространстве. Наконец, «Пространственная навигация» проверяет способность модели понимать и решать задачи, связанные с перемещением в пространстве и определением маршрутов.
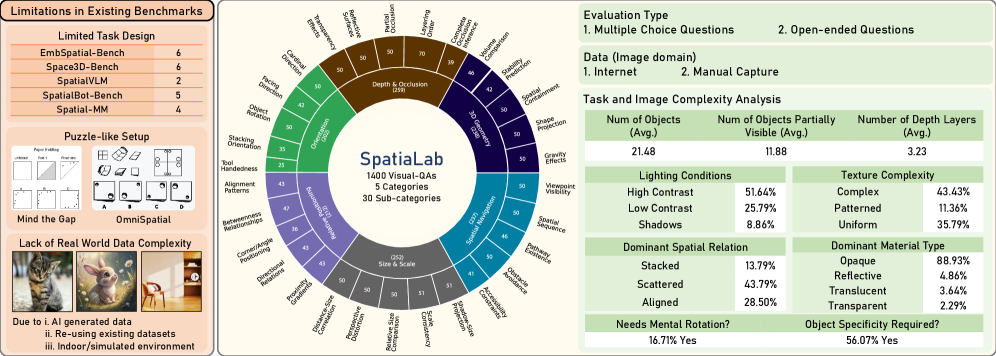
Сбор данных для SpatiaLab осуществлялся посредством комбинированного подхода, включающего автоматизированный веб-скрейпинг и ручную аннотацию. Веб-скрейпинг позволил собрать обширный набор визуальных стимулов из различных источников в сети Интернет. Для обеспечения высокого качества и разнообразия данных, полученные изображения подвергались ручной проверке и аннотации экспертами. Ручная аннотация включала в себя проверку корректности изображений, удаление нерелевантных или низкокачественных примеров, а также добавление необходимых метаданных и тегов для последующей обработки и анализа. Комбинация этих методов позволила сформировать датасет, характеризующийся как большим объемом, так и высокой степенью достоверности визуальных стимулов.
Оценка моделей в SpatiaLab осуществляется посредством комбинирования вопросов с множественным выбором ответов и вопросов с открытым ответом. Формат с множественным выбором позволяет быстро и эффективно оценивать способность модели к распознаванию и классификации пространственных отношений, в то время как вопросы с открытым ответом требуют более детального понимания и генерации ответов, что позволяет оценить способность модели к логическим выводам и решению сложных пространственных задач. Такое сочетание форматов обеспечивает многостороннюю оценку возможностей моделей в области пространственного мышления и позволяет выявить как сильные, так и слабые стороны различных подходов к решению задач пространственного интеллекта.
Выявление Разрыва в Производительности VLM и Анализ Ошибок
Оценка производительности современных визуально-языковых моделей (VLM) на наборе данных SpatiaLab выявила значительный разрыв в точности по сравнению с результатами, демонстрируемыми людьми. В то время как средняя точность человека при ответе на вопросы с множественным выбором составляет 87%, лучшие VLM достигают лишь 55%. Данный разрыв в 32 процентных пункта указывает на существенные ограничения текущих моделей в задачах, требующих понимания пространственных отношений и визуальной информации, и подчеркивает необходимость дальнейших исследований в данной области.
Анализ ошибок показал, что современные визуально-языковые модели (VLM) демонстрируют наибольшие трудности в задачах, требующих понимания глубины, окклюзии (частичного перекрытия объектов) и относительного позиционирования. Конкретно, модели испытывают сложности в определении расстояний между объектами в сцене, в интерпретации перекрывающихся объектов и в установлении пространственных взаимосвязей между ними. Данные ошибки возникают как в задачах с множественным выбором ответов, так и в задачах с открытым ответом, что указывает на фундаментальные ограничения в способности моделей к комплексному пространственному рассуждению.
Тестирование моделей визуального понимания (VLM) показало значительные трудности с обобщением на новые сцены и адаптацией к изменениям масштаба объектов и перспективы. В задачах с открытым ответом, точность моделей составила лишь 30-50%, в то время как средний показатель для людей достиг 65%. Данный разрыв в производительности указывает на ограниченные возможности текущих VLM в обработке вариаций в визуальных данных и требует дальнейших исследований в области улучшения их способности к обобщению и адаптации к различным условиям.
Полученные результаты на платформе SpatiaLab демонстрируют существенные ограничения современных визуально-языковых моделей (VLM) в решении задач, требующих комплексного пространственного рассуждения. Низкий уровень точности (55% для вопросов с вариантами ответов и 30-50% для открытых задач) по сравнению с человеческими показателями (87% и 65% соответственно) указывает на необходимость целенаправленной разработки и улучшения архитектур VLM. Основными направлениями для улучшения являются повышение способности к пониманию глубины, окклюзии, относительного расположения объектов, а также обеспечение более эффективной обобщающей способности и адаптации к изменениям масштаба и перспективы.

Пути Улучшения Пространственного Мышления: Методы и Перспективы
Исследования в рамках SpatiaLab демонстрируют, что применение контролируемого дообучения (SFT) является перспективным подходом к повышению эффективности решения задач, требующих пространственного мышления. В процессе SFT, предварительно обученные модели адаптируются к конкретным типам пространственных задач посредством обучения на размеченных данных. Этот метод позволяет значительно улучшить производительность в узкоспециализированных областях, таких как понимание относительного положения объектов, предсказание траекторий движения или интерпретация геометрических сцен. Результаты показывают, что SFT позволяет моделям более точно выявлять и использовать пространственные связи, что приводит к повышению точности и надежности решений. В частности, дообучение на тщательно подобранных наборах данных, содержащих разнообразные примеры пространственных взаимосвязей, позволяет достичь существенного улучшения показателей по сравнению с использованием только предварительно обученных моделей.
Метод последовательного мышления, или “Chain-of-Thought” подсказки, представляет собой инновационный подход к обучению языковых моделей, направленный на повышение точности и прозрачности процесса рассуждения. Вместо простого предоставления вопроса и ожидания ответа, модели предлагается последовательно излагать шаги, необходимые для решения задачи. Этот процесс имитирует человеческое мышление, где решение возникает не мгновенно, а в результате последовательного анализа и логических выводов. Исследования показывают, что артикуляция промежуточных шагов не только повышает вероятность получения правильного ответа, но и позволяет исследователям лучше понять, как модель приходит к своим заключениям, что открывает возможности для выявления и исправления ошибок в логике рассуждений. Такой подход особенно полезен при решении сложных задач, требующих многоэтапного анализа и учета различных факторов, поскольку он позволяет модели структурировать свои мысли и избегать поверхностных или ошибочных выводов.
Интеграция геометрического обоснования и представления, учитывающего физические законы, в архитектуру моделей представляется перспективным путем к более надежному пониманию пространственных взаимосвязей. Вместо обработки пространственных данных как абстрактных координат, такой подход предполагает встраивание знаний о геометрических свойствах объектов — форме, размере, ориентации — и принципах их физического взаимодействия. Это позволяет моделям не просто «видеть» расположение объектов, но и «понимать», как они могут перемещаться, взаимодействовать и влиять друг на друга в рамках физически правдоподобной среды. Например, понимание принципов гравитации и инерции позволяет предсказывать траектории движения объектов или оценивать устойчивость конструкций. Такое углубленное представление пространственных данных способствует повышению точности и обобщающей способности моделей при решении задач, связанных с навигацией, планированием и взаимодействием с объектами в трехмерном пространстве.
Дальнейшие исследования направлены на создание моделей, способных к обобщенному пространственному мышлению, то есть к анализу сложных сцен и адаптации к незнакомым условиям. Вместо узкой специализации на конкретных задачах, разрабатываемые алгоритмы стремятся к пониманию общих принципов пространственных отношений, что позволит им успешно функционировать в разнообразных и непредсказуемых средах. Особое внимание уделяется способности к переносу знаний — умению применять опыт, полученный в одном контексте, к совершенно новым ситуациям. Такой подход предполагает отход от жестко запрограммированных правил и переход к более гибким системам, способным к обучению и самосовершенствованию, что критически важно для создания действительно интеллектуальных систем, способных к полноценному взаимодействию с окружающим миром.
Исследование, представленное в статье, демонстрирует, что современные модели, работающие с визуальной и языковой информацией, испытывают трудности с пространственным мышлением в реальных условиях. Это подчеркивает потребность в более совершенных представлениях трехмерного пространства и физических законов. Как однажды заметил Эндрю Ын: «Мы можем добиться большего, если будем стремиться к более глубокому пониманию принципов, лежащих в основе машинного обучения». Эта цитата отражает суть представленной работы, ведь для создания действительно интеллектуальных систем необходимо не просто «научить» модель работать с данными, а обеспечить ее способностью к логическому и пространственному анализу, что является ключевым аспектом для развития embodied AI и навигации в сложных трехмерных средах.
Что Дальше?
Представленный анализ, зафиксированный в SpatiaLab, обнажил не столько недостатки конкретных моделей, сколько фундаментальную хрупкость пространственного рассуждения в системах, полагающихся на корреляции данных. Пусть N стремится к бесконечности — что останется устойчивым? Очевидно, не простое сопоставление изображений и языковых описаний. Необходим переход к представлениям, укорененным в геометрии и физике, а не в статистике. Иначе, любое, даже незначительное изменение условий, вызовет коллапс всей системы.
Вопрос не в увеличении объемов обучающих данных, а в изменении принципов представления знаний. Обучение на миллионах примеров, не способных обобщить даже простейшие пространственные отношения, лишь подтверждает тщетность эмпирического подхода. Требуется формализация пространственных отношений, позволяющая алгоритму не просто «видеть», но и «понимать» геометрию сцены, а также предсказывать последствия действий в этой геометрии.
Попытки обойти необходимость в физическом моделировании, заменяя его статистическими приближениями, обречены на провал. Истинное понимание пространства требует не просто распознавания объектов, но и понимания их взаимосвязей, их массы, их инерции. Иначе, система останется лишь сложным инструментом для сопоставления пикселей, лишенным подлинного интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2602.03916.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Текстуры обмана: Как взломать ИИ, управляющий роботами
- Быстрый поиск смыслов: оптимизация векторных баз данных для больших языковых моделей
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Пространственно Связанные Коды: Новый Взгляд на Надежность Связи
2026-02-05 13:19