Автор: Денис Аветисян
Новый подход объединяет мощь механистического моделирования с гибкостью машинного обучения для повышения точности и интерпретируемости прогнозов сложных динамических систем.
Исследование представляет фреймворк, сочетающий в себе разреженное обнаружение уравнений и машинное обучение для адаптации параметров во времени и получения надежных прогнозов с оценкой погрешности.
Сложность идентификации уравнений, описывающих динамические системы, особенно при неизвестных механизмах, долгое время являлась серьезной проблемой. В работе ‘Turning mechanistic models into forecasters by using machine learning’ предложен новый подход, сочетающий в себе обнаружение разреженных уравнений и машинное обучение для адаптации параметров во времени. Предложенная методика позволяет не только повысить точность моделирования, но и значительно улучшить прогнозные характеристики, достигая средней абсолютной ошибки менее 3% при обучении и менее 6% при прогнозировании на месяц вперёд. Может ли подобный подход стать основой для создания самообучающихся моделей, способных предсказывать поведение сложных систем в реальном времени?
Преодолевая Черный Ящик: Необходимость Механистического Понимания
Традиционные экологические и природоохранные модели зачастую основываются на эмпирических взаимосвязях, выявляемых на основе наблюдений, однако им свойственно недостаток глубокого понимания лежащих в их основе механизмов. Вместо того чтобы исследовать, как и почему происходят те или иные явления, эти модели концентрируются на описании что происходит. Это ограничивает их способность к точным прогнозам, особенно в условиях быстро меняющейся окружающей среды или при столкновении с новыми, ранее не встречавшимися ситуациями. Например, модель может точно предсказывать численность популяции в текущих условиях, но оказаться бесполезной при изменении климата или появлении нового хищника, поскольку она не учитывает фундаментальные биологические и экологические процессы, определяющие динамику популяции. Подобный подход, хотя и позволяет получить краткосрочные прогнозы, не обеспечивает надежной основы для долгосрочного планирования и управления природными ресурсами.
Ограничения в прогностической способности эмпирических моделей становятся особенно заметными при столкновении с новыми, ранее не встречавшимися условиями или стремительными изменениями окружающей среды. Когда привычные корреляции нарушаются из-за непредсказуемых факторов, такие модели демонстрируют значительное снижение точности, не позволяя адекватно оценить будущие состояния экосистем. Например, при изменении климата, когда температуры и осадки выходят за рамки исторических данных, основанные на прошлом опыте прогнозы могут оказаться совершенно неверными. Именно поэтому необходимо переходить к моделям, учитывающим фундаментальные механизмы, управляющие экологическими процессами, чтобы обеспечить надежные предсказания даже в условиях высокой неопределенности и динамичных изменений.
Переход к моделированию, основанному на данных и механизмах, представляется необходимым для получения надежных и устойчивых прогнозов в экологических и природоохранных исследованиях. Традиционные эмпирические модели, хотя и полезны для описания текущих тенденций, часто оказываются неспособными адекватно реагировать на новые, ранее не встречавшиеся условия или стремительные изменения окружающей среды. Механистическое моделирование, напротив, стремится выявить и интегрировать фундаментальные процессы, лежащие в основе наблюдаемых явлений, что позволяет не только предсказывать будущее состояние систем, но и понимать причины и механизмы, определяющие эти изменения. Использование больших объемов данных для калибровки и валидации таких моделей значительно повышает их точность и надежность, обеспечивая более обоснованные решения в области охраны окружающей среды и управления природными ресурсами.
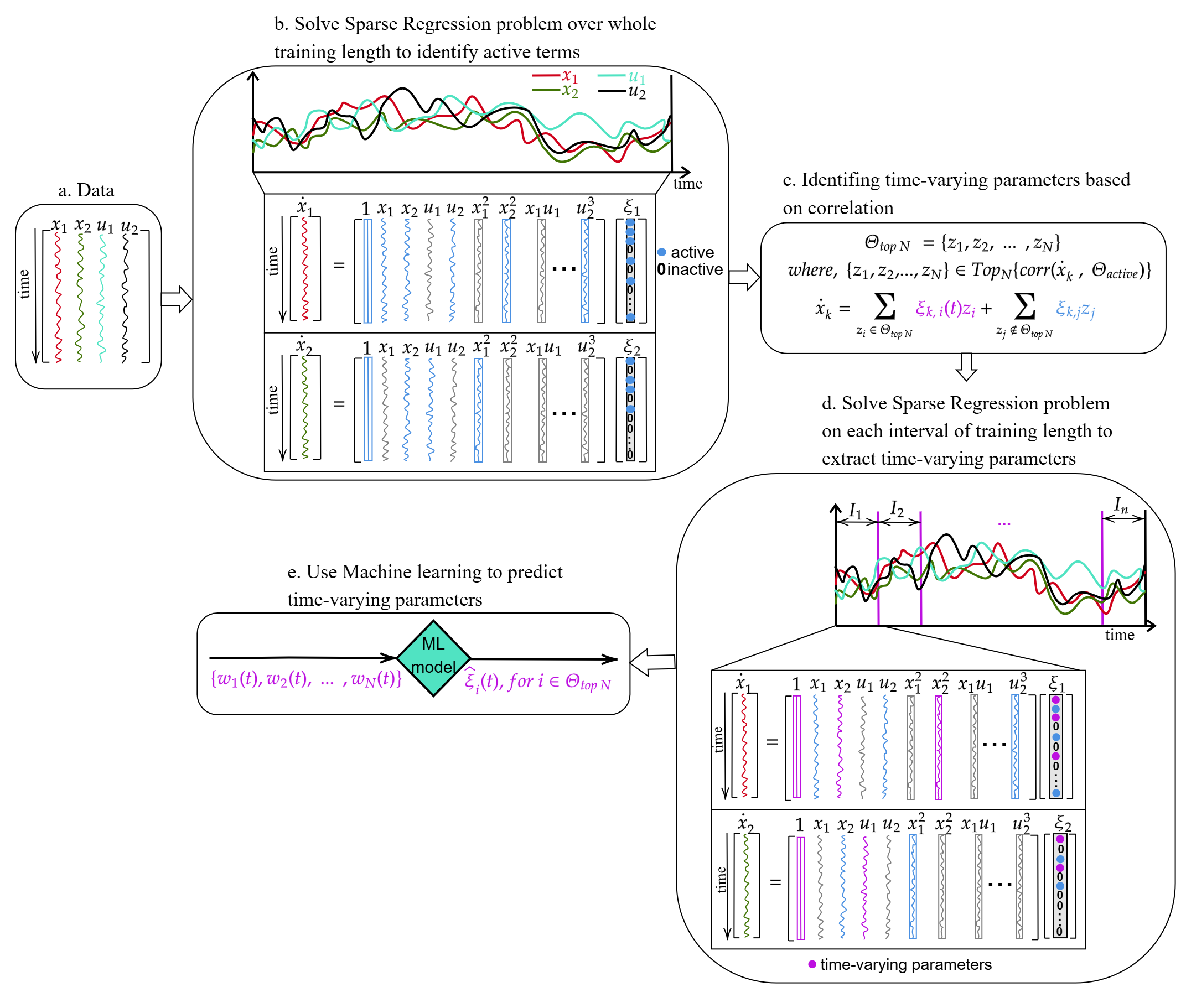
Выявление Механизмов из Данных: Переход к Пониманию
Метод Data-Driven Discovery позволяет отойти от априорных предположений и предварительно заданных моделей, выявляя управляющие уравнения непосредственно из наблюдательных данных. Традиционно, построение моделей опиралось на существующие знания о системе, что могло приводить к искажениям или упущениям важных факторов. В отличие от этого, Data-Driven Discovery использует алгоритмы машинного обучения и регрессионного анализа для автоматического поиска математических выражений, наилучшим образом описывающих взаимосвязи в данных. Этот подход особенно полезен в сложных системах, где явные уравнения неизвестны или трудновычислимы, позволяя идентифицировать скрытые зависимости и получить компактное представление динамики системы, например, в виде полиномиальных регрессий или нелинейных уравнений в частных производных. \frac{du}{dt} = f(u, v) — пример уравнения, которое может быть получено напрямую из данных без предварительных знаний о функции f .
Метод разреженного (sparse) выявления нелинейной динамики является эффективным инструментом в рамках подхода, основанного на данных, позволяя идентифицировать ключевые взаимодействия в сложных системах. Он базируется на предположении, что большинство взаимодействий в системе являются незначительными, и позволяет выделить лишь небольшое число доминирующих, определяющих поведение системы. Это достигается путем поиска разрешенных моделей, то есть моделей с минимальным количеством ненулевых параметров, которые наилучшим образом соответствуют наблюдаемым данным. Использование методов разреженного восстановления, таких как L_1-регуляризация, позволяет эффективно оценить эти доминирующие взаимодействия и упростить представление сложной системы, снижая вычислительную сложность и улучшая интерпретируемость модели.
Традиционное моделирование часто опирается на априорные знания и предположения о структуре системы, что может приводить к неточностям или упущениям. Подход, основанный на выявлении наблюдаемых причинно-следственных связей, позволяет строить модели непосредственно из данных, минуя необходимость в предварительных допущениях. Это достигается путем анализа данных для выявления переменных, которые статистически оказывают влияние друг на друга, и построения моделей, отражающих эти зависимости. В результате формируется модель, описывающая не предполагаемые, а фактически наблюдаемые взаимосвязи между элементами системы, что повышает ее точность и позволяет выявлять ранее неизвестные механизмы и закономерности. Такой подход особенно ценен при исследовании сложных систем, где априорные знания могут быть неполными или неточными.
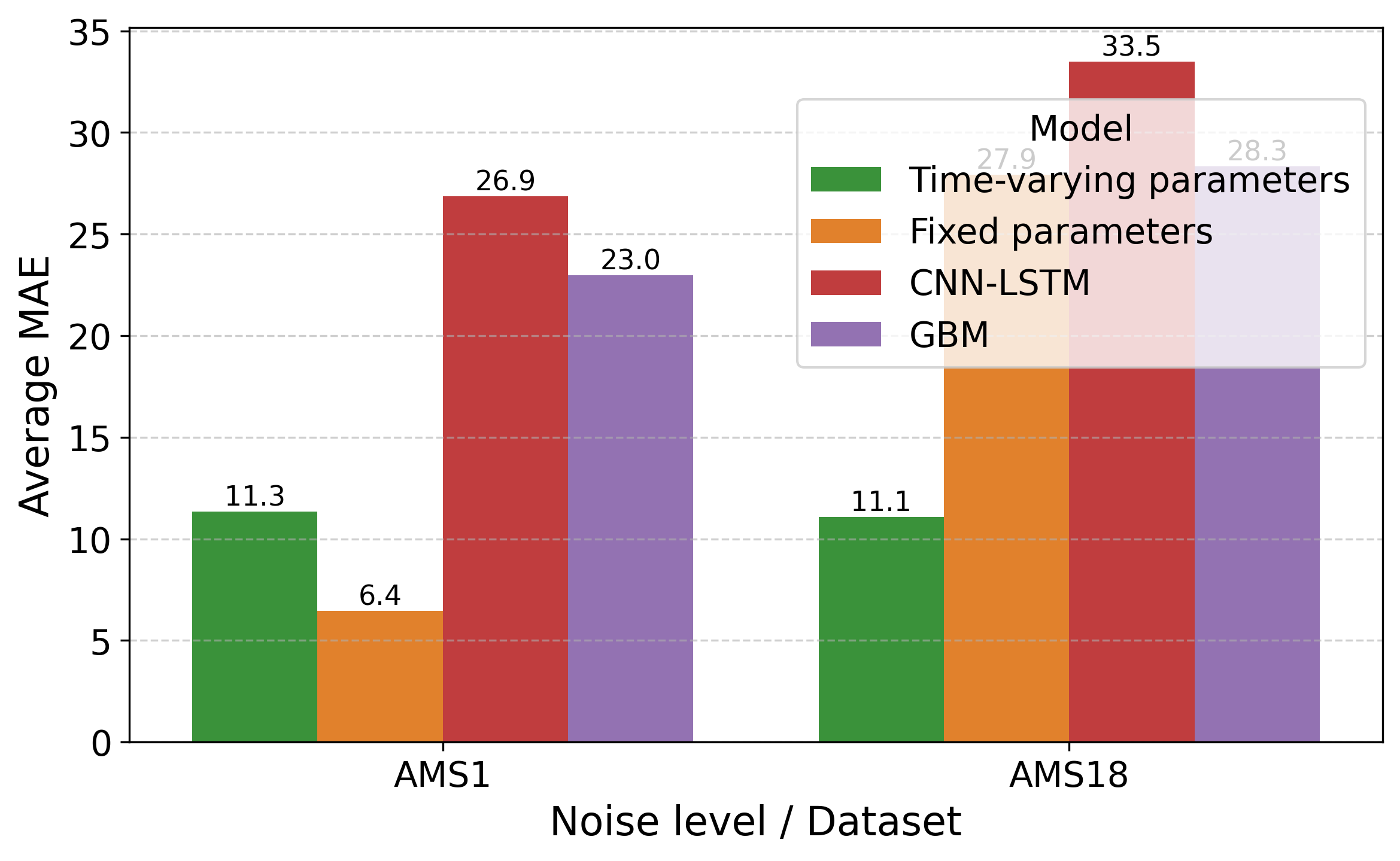
Строгая Проверка: Оценка Прогностической Силы и Неопределенности
Метод расширяющегося окна кросс-валидации (Expanding-Window Cross-Validation) обеспечивает надежную оценку производительности модели во времени, путем последовательного обучения на расширяющемся наборе данных и тестирования на последующих периодах. В отличие от стандартной кросс-валидации, которая предполагает случайное разделение данных, данный подход учитывает временную зависимость данных, что особенно важно для временных рядов и динамических систем. Каждая итерация включает обучение модели на начальном сегменте данных, предсказание для следующего периода, и оценку ошибки предсказания. Затем окно обучения расширяется, включая новые данные, и процесс повторяется. Этот метод позволяет оценить, как производительность модели изменяется со временем и выявить потенциальные проблемы с обобщающей способностью модели, а также оценить стабильность параметров модели во времени.
Регуляризация представляет собой набор техник, используемых для предотвращения переобучения модели — ситуации, когда модель слишком хорошо адаптируется к обучающим данным и теряет способность к обобщению на новые, ранее не встречавшиеся данные. Методы регуляризации, такие как L1 (LASSO) и L2 (Ridge) регуляризация, добавляют штраф к функции потерь, ограничивая величину весов модели. Это способствует упрощению модели и снижению дисперсии, что приводит к улучшению её способности к обобщению и повышению точности прогнозов на новых данных. Выбор оптимальной силы регуляризации осуществляется с помощью методов перекрестной проверки, таких как k-fold cross-validation, для минимизации ошибки обобщения.
Оценка неопределенности прогноза с использованием границ погрешности прогноза на конечном горизонте является критически важной для принятия обоснованных решений. Данный подход позволяет определить диапазон возможных значений прогнозируемой величины с заданной вероятностью, что необходимо для оценки рисков и разработки стратегий управления. Границы погрешности, вычисляемые на основе статистических свойств модели и исторических данных, предоставляют количественную оценку надежности прогноза и позволяют учитывать потенциальные отклонения от ожидаемого значения. Использование границ погрешности особенно важно в сценариях, где последствия ошибок прогнозирования могут быть значительными, например, в управлении запасами, планировании ресурсов или принятии финансовых решений. \pm k \sigma , где k — коэффициент, определяющий уровень доверия, а σ — стандартное отклонение прогноза, является типичным способом представления границ погрешности.
В ходе тестирования разработанного фреймворка было установлено, что использование параметров, изменяющихся во времени, для модели SIR позволяет добиться снижения средней абсолютной ошибки (MAE) прогнозирования на 8% по сравнению с моделями, использующими фиксированные параметры. Данный результат демонстрирует эффективность подхода к адаптивному моделированию эпидемиологических данных и позволяет повысить точность краткосрочных прогнозов распространения инфекционных заболеваний. Снижение MAE свидетельствует о более адекватном описании динамики эпидемии с учетом изменения факторов, влияющих на скорость распространения инфекции.
Расширение Горизонтов: Приложения и Перспективы Развития
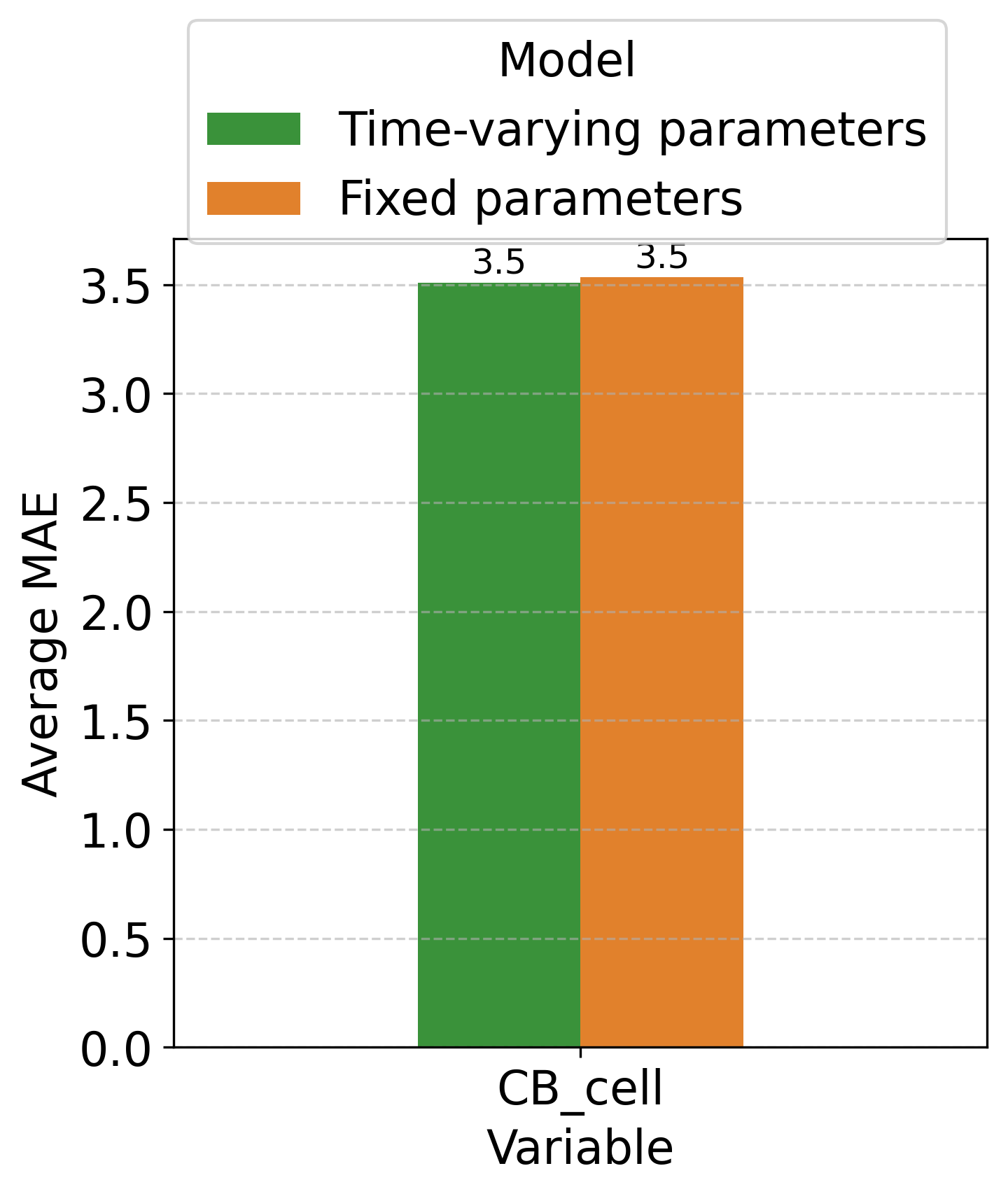
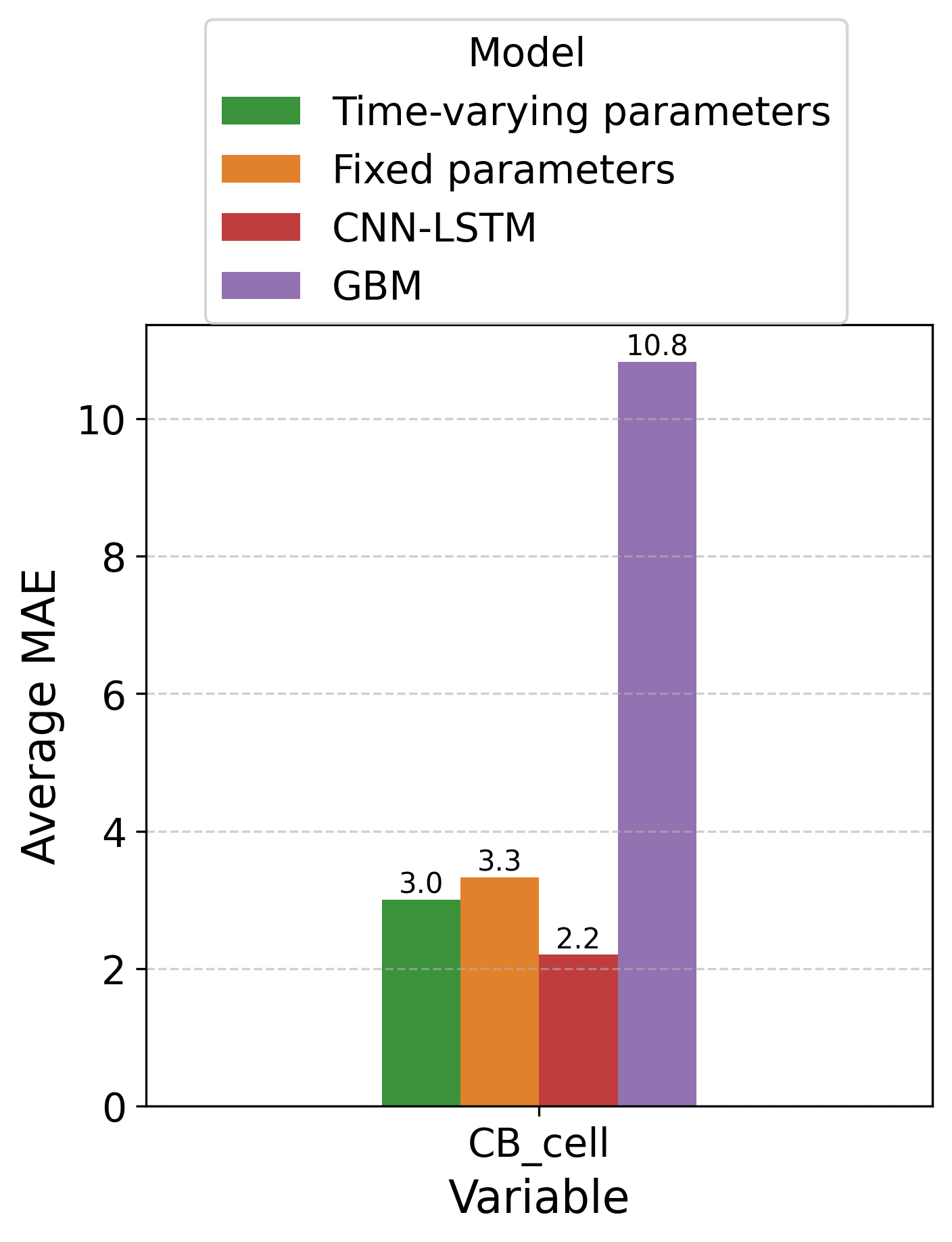
Предложенный подход демонстрирует свою универсальность, находя применение в моделировании и анализе широкого спектра сложных систем. В частности, методы, разработанные в рамках данного исследования, успешно применяются к классическим эпидемиологическим моделям типа “Восприимчивые-Зараженные-Выздоровевшие” (SIR), позволяя более точно прогнозировать динамику распространения инфекций. Помимо этого, разработанные алгоритмы эффективно оптимизируют управление ресурсами в моделях “Потребитель-Ресурс”, что имеет значение для анализа экологических взаимодействий и устойчивого использования природных ресурсов. Возможность адаптации к различным типам моделей подчеркивает потенциал данного подхода для решения широкого круга задач в областях от здравоохранения до экологии и экономики.
Для повышения точности прогнозирования динамических систем, таких как эпидемиологические или экологические модели, активно применяются методы машинного обучения, в частности, алгоритм Random Forest. Данный подход позволяет эффективно учитывать изменения параметров во времени, что особенно важно для систем, характеризующихся нелинейным поведением и подверженных внешним воздействиям. В отличие от традиционных методов, предполагающих постоянство параметров, Random Forest способен адаптироваться к изменяющимся условиям, выявляя сложные зависимости и закономерности в данных. Это приводит к более реалистичным и надежным прогнозам, что подтверждается результатами исследований, демонстрирующими улучшение точности предсказаний в различных моделях — от SIR-моделей распространения инфекций до моделей динамики газов и потребительско-ресурсных взаимодействий.
Применение разработанного подхода к изучению динамики парниковых газов и динамике цианобактерий открывает новые перспективы для понимания ключевых экологических процессов. Анализ этих систем, характеризующихся сложными взаимодействиями и нелинейным поведением, позволяет получить более точные прогнозы изменений в окружающей среде. Исследования показали, что данный фреймворк способен выявлять скрытые закономерности в данных о концентрации метана и других парниковых газов, а также прогнозировать распространение цианобактерий в водных экосистемах. Это, в свою очередь, способствует разработке более эффективных стратегий смягчения последствий изменения климата и поддержания здоровья водных ресурсов, представляя собой значимый шаг в направлении устойчивого развития.
Предложенный аналитический подход продемонстрировал значительное повышение точности прогнозирования в различных моделях. В частности, применительно к модели SIR (Susceptible-Infected-Recovered), удалось снизить среднюю абсолютную ошибку (MAE) прогноза инфицированного населения на 2,5%. Улучшения также наблюдались при моделировании динамики потребителя в модели «Потребитель-Ресурс» (1,3% снижение MAE) и при прогнозировании концентрации метана (CH_4) в наборе данных о газах (5,7% снижение MAE). Эти результаты свидетельствуют о высокой эффективности разработанного фреймворка в решении задач прогнозирования в сложных системах и открывают возможности для его дальнейшего применения в различных областях науки и практики, где требуется точное предсказание динамики процессов.
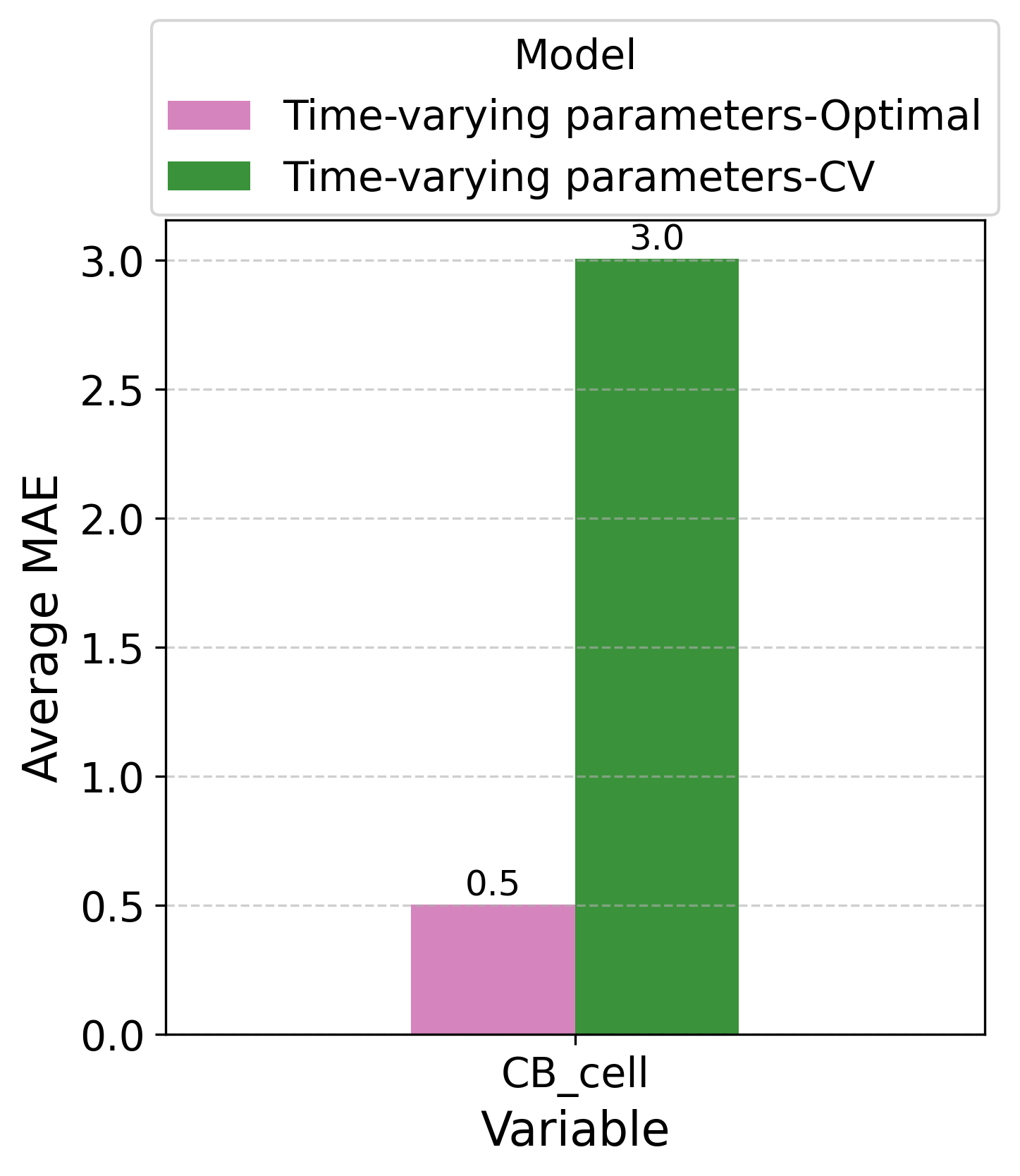
Исследование демонстрирует, что без четкого определения структуры динамической системы, попытки прогнозирования обречены на неточность. Авторы предлагают подход, сочетающий в себе обнаружение разреженных уравнений и машинное обучение для адаптации параметров во времени, что позволяет значительно улучшить точность прогнозов. Как заметил Брайан Керниган: «Простота — это высшая степень совершенства». Этот принцип находит отражение в стремлении к лаконичным и интерпретируемым моделям, способным адекватно описывать сложные системы. Данная работа подчеркивает важность математической строгости и корректности при построении моделей, поскольку именно это обеспечивает надежность и предсказуемость результатов.
Куда Ведет Этот Путь?
Представленная работа, хотя и демонстрирует элегантное соединение детерминированных моделей с мощью машинного обучения, лишь приоткрывает завесу над истинной сложностью динамических систем. Заманчиво говорить о “точности прогнозов”, однако необходимо помнить: любое приближение — это компромисс между детализацией и обобщением. Поиск разреженных представлений, безусловно, ценен, но вопрос о “правильной” разреженности — вопрос, требующий дальнейшего, строгого математического обоснования. Недостаточно просто “найти” модель, необходимо доказать её устойчивость и предсказательную силу в условиях, отличных от тех, что использовались при обучении.
Очевидным направлением для будущих исследований представляется разработка методов, позволяющих оценивать не только точность прогноза, но и его надежность — границы погрешности, которые не являются произвольными, а вытекают из структуры самой модели. Следует также обратить внимание на проблему идентификации нелинейностей в высокоразмерных системах, где стандартные методы могут оказаться неэффективными. И, конечно, нельзя забывать о необходимости разработки алгоритмов, способных адаптироваться к меняющимся условиям, — система, которая “застывает” во времени, теряет всякую ценность.
В конечном счете, успех этого направления исследований будет определяться не количеством достигнутых “рекордов” в точности прогнозов, а глубиной понимания фундаментальных принципов, управляющих сложными системами. Истинная красота заключается не в иллюзии предсказания будущего, а в осознании его неопределенности.
Оригинал статьи: https://arxiv.org/pdf/2602.04114.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Экзотические разложения: новые грани цилиндрической алгебры
- Поймать Мгновение: Эволюция Детекторов Времени
- Память для разума: Архитектура коллективного интеллекта
- Самообучающиеся решатели уравнений: новый подход к научным вычислениям
2026-02-05 18:45