Автор: Денис Аветисян
Новое исследование показывает, как мультимодальные модели могут преодолеть предвзятость и научиться связывать текст с визуальной информацией для более точного распознавания объектов и сущностей.
Предложена структура, обеспечивающая последовательное межмодальное рассуждение в мультимодальных моделях для повышения точности и согласованности определения именованных сущностей.
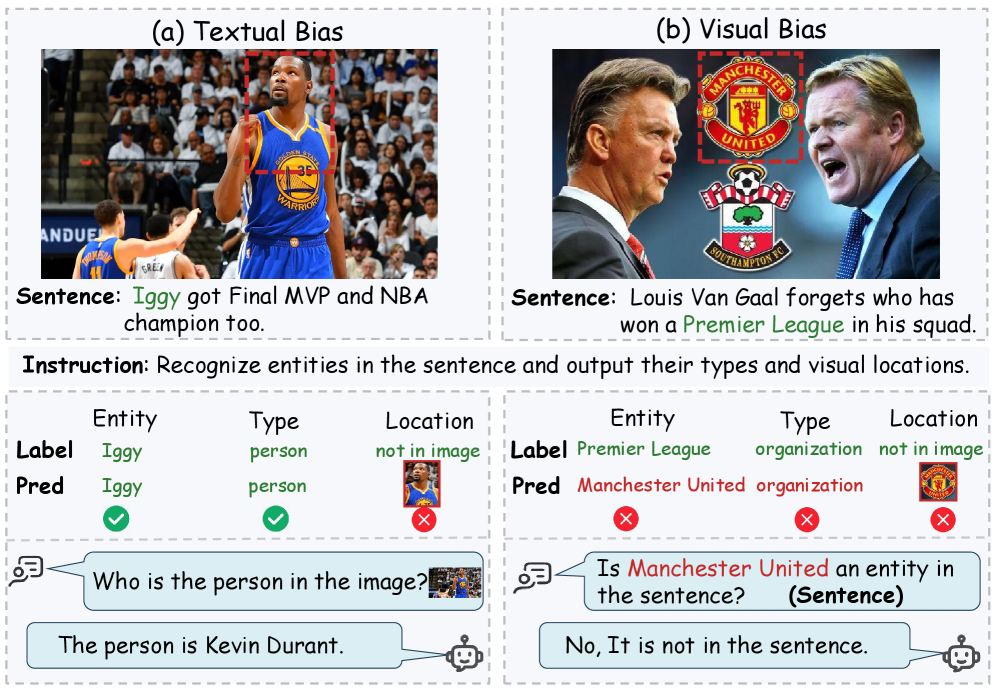
Несмотря на впечатляющие возможности больших мультимодальных языковых моделей, их склонность к использованию упрощенных, унимодальных «ярлыков» ограничивает точность извлечения именованных сущностей и их привязки к визуальным областям. В работе ‘Beyond Unimodal Shortcuts: MLLMs as Cross-Modal Reasoners for Grounded Named Entity Recognition’ исследуется потенциал этих моделей для выполнения задачи Grounded Multimodal Named Entity Recognition (GMNER) в сквозном режиме, и выявляется проблема модальной предвзятости. Для решения этой проблемы предложен фреймворк Modality-aware Consistency Reasoning (MCR), обеспечивающий структурированное кросс-модальное рассуждение и повышающий согласованность результатов. Способны ли предложенные методы MCR существенно улучшить надежность и точность мультимодальных моделей в задачах, требующих глубокого понимания и сопоставления различных типов данных?
Распознавание Именованных Сущностей: Преодоление Модальной Предвзятости
Распознавание именованных сущностей с привязкой к визуальному контексту (GMNER) играет ключевую роль в задачах, требующих совместного анализа изображений и текста. Эта способность позволяет системам не просто идентифицировать объекты или понятия, но и связывать их с конкретными элементами на визуальном представлении. Например, GMNER позволяет точно определить, какой именно объект на фотографии упоминается в текстовом описании, или наоборот, найти изображение, соответствующее конкретному текстовому запросу, содержащему именованные сущности. Такая интеграция визуальной и текстовой информации необходима для развития интеллектуальных систем, способных к полноценному пониманию окружающего мира и взаимодействию с ним, открывая перспективы для приложений в робототехнике, автоматизированном анализе контента и создании более интуитивно понятных интерфейсов.
Современные мультимодальные большие языковые модели (MLLM) демонстрируют значительный потенциал в задачах, требующих совместного анализа визуальной и текстовой информации. Однако, исследования показывают, что эти модели часто склонны к использованию поверхностных корреляций между модальностями, вместо глубокого, истинного кросс-модального рассуждения. Это означает, что MLLM могут успешно идентифицировать объекты или сущности, основываясь на случайных совпадениях между изображением и текстом, а не на реальном понимании взаимосвязи между ними. В результате, модель может дать правильный ответ в простых случаях, но легко ошибиться, когда условия меняются или требуются более сложные выводы, что ограничивает надежность и обобщающую способность системы.
Проблема модальной предвзятости существенно ограничивает надежность и устойчивость систем Распознавания Именованных Сущностей, основанных на совместном анализе текста и изображений (GMNER). Современные мультимодальные большие языковые модели (MLLM), несмотря на впечатляющие возможности, часто полагаются на поверхностные корреляции между визуальными и текстовыми данными, вместо глубокого понимания их взаимосвязи. Это приводит к тому, что модель может ошибочно идентифицировать сущности, основываясь на доминирующем режиме (например, игнорируя визуальную информацию при наличии сильного текстового сигнала, или наоборот). В результате, GMNER-системы становятся уязвимыми к изменениям в данных, таким как шум, искажения или неполнота информации в одном из режимов, что препятствует достижению стабильно высоких показателей производительности и ограничивает их применимость в реальных сценариях, требующих надежного и контекстуально-обоснованного анализа.
Согласованное Рассуждение с Учетом Модальности: Новый Подход
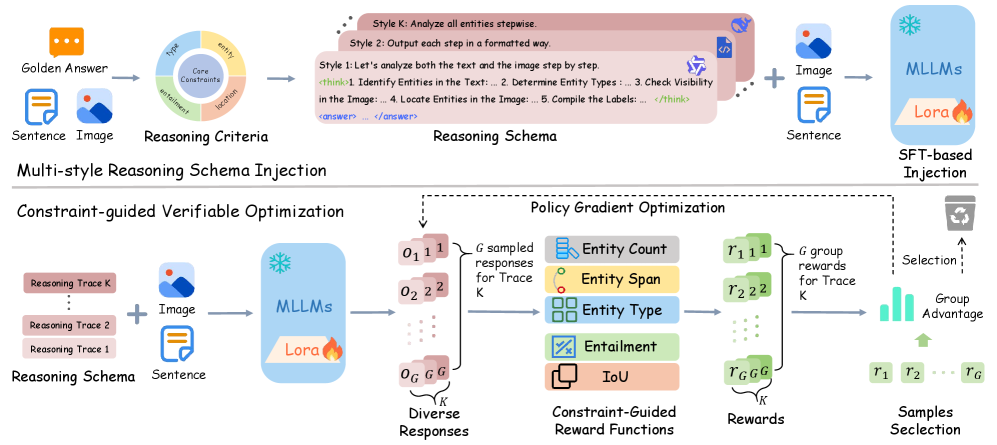
Метод согласованного рассуждения с учетом модальности (MCR) представляет собой новый подход к снижению модальной предвзятости в мультимодальных больших языковых моделях (MLLM). В отличие от традиционных методов, MCR не полагается на статическую обработку данных, а динамически оценивает согласованность рассуждений, генерируемых на основе различных модальностей (например, текста и изображений). Этот подход позволяет модели выявлять и корректировать несоответствия, возникающие из-за различной интерпретации информации в разных модальностях, тем самым повышая надежность и объективность результатов. Основная цель MCR — обеспечить, чтобы логические выводы модели не зависели от конкретной представленной модальности, а основывались на общей семантической согласованности.
Метод Modality-aware Consistency Reasoning (MCR) использует инъекцию мульти-стилевых схем рассуждений (Multi-style Reasoning Schema Injection — MRSI) для создания разнообразных путей логического вывода. MRSI предполагает генерацию нескольких вариантов рассуждений, отличающихся по стилю и подходу, что позволяет избежать чрезмерной зависимости от единственной эвристики или шаблона. Это достигается путем применения различных стратегий рассуждений к одному и тому же входному вопросу, что повышает устойчивость модели к модальным смещениям и улучшает общую надежность принимаемых решений. Использование множества путей рассуждений способствует более комплексному анализу информации и снижает вероятность ошибочных выводов, основанных на упрощенных или предвзятых логических цепочках.
Механизм Constraint-guided Verifiable Optimization (CVO), используемый в MCR, динамически согласовывает процесс рассуждений с заданными ограничениями. CVO использует направленные ограничения для сужения пространства поиска возможных решений, что позволяет модели фокусироваться на наиболее релевантных ответах. Этот процесс включает в себя верификацию промежуточных шагов рассуждений на соответствие этим ограничениям, обеспечивая тем самым, что итоговый ответ не только логически обоснован, но и соответствует заданным условиям. Эффективность CVO заключается в итеративном уточнении рассуждений и отбрасывании несовместимых вариантов, что приводит к более надежным и точным результатам, особенно в задачах, требующих соблюдения специфических правил или критериев.
Оптимизация для Надежных и Проверяемых Рассуждений
CVO использует алгоритм Group Relative Policy Optimization (GRPO) для оптимизации процесса рассуждений. GRPO штрафует стратегии, которые находят упрощенные, одномодальные решения, не соответствующие заданным ограничениям, и, наоборот, поощряет последовательности рассуждений, согласующиеся с предоставленными условиями. Это достигается за счет оценки политики не в абсолютном значении, а относительно других политик в группе, что способствует формированию более надежных и проверяемых цепочек рассуждений, избегая ситуаций, когда модель находит обходные пути, игнорируя важные факторы.
Групповая относительная оптимизация (GRPO) способствует формированию более надежных и проверяемых цепочек рассуждений за счет акцента на относительную производительность внутри групп. Вместо абсолютной оптимизации каждой отдельной цепочки, GRPO оценивает ее эффективность в сравнении с другими цепочками, созданными в рамках одной группы. Такой подход позволяет снизить вероятность появления “унимодальных сокращений” — решений, которые кажутся оптимальными локально, но не соответствуют заданным ограничениям или общей логике задачи. В результате, GRPO стимулирует создание более устойчивых и обоснованных цепочек рассуждений, что, в свою очередь, повышает надежность и верифицируемость полученных результатов.
Экспериментальные результаты показали значительное повышение точности в задаче GMNER. Применение предложенного фреймворка MCR к модели Qwen2.5VL позволило добиться прироста показателя F1 на 11.87% по сравнению с предыдущим лучшим унифицированным методом, достигнув значения 85.63%. Данный результат демонстрирует эффективность предложенного подхода в контексте задач, требующих высокой точности и надежности вывода.
В ходе тестирования на задаче GMNER, предложенный метод продемонстрировал превосходство над лучшим методом, основанным на конвейерной обработке данных (SCANNER), достигнув прироста в 2.11% по метрике F1. Это указывает на более высокую точность и надежность предложенного подхода в задачах, требующих рассуждений и анализа, по сравнению с традиционными конвейерными системами обработки информации. Полученный результат подтверждает эффективность предложенной архитектуры и алгоритмов в контексте задач, связанных с многомодальным пониманием и рассуждениями.
Эффективная Адаптация и Перспективы Развития
Современные мультимодальные большие языковые модели (MLLM) требуют значительных вычислительных ресурсов для адаптации к конкретным задачам, таким как графическое обоснование естественного языка (GMNER). Однако, применение контролируемого обучения (Supervised Fine-Tuning, SFT) в сочетании с адаптацией низкого ранга (Low-Rank Adaptation, LoRA) позволяет эффективно обучать эти модели, избегая необходимости в дорогостоящих вычислительных мощностях. Данный подход позволяет оптимизировать процесс обучения, фокусируясь на внесении минимальных изменений в предварительно обученные веса модели, что существенно снижает потребность в памяти и времени обработки. В результате, даже относительно небольшие вычислительные ресурсы могут быть использованы для достижения высокой производительности в задачах GMNER, открывая возможности для более широкого внедрения и применения мультимодальных моделей в различных областях.
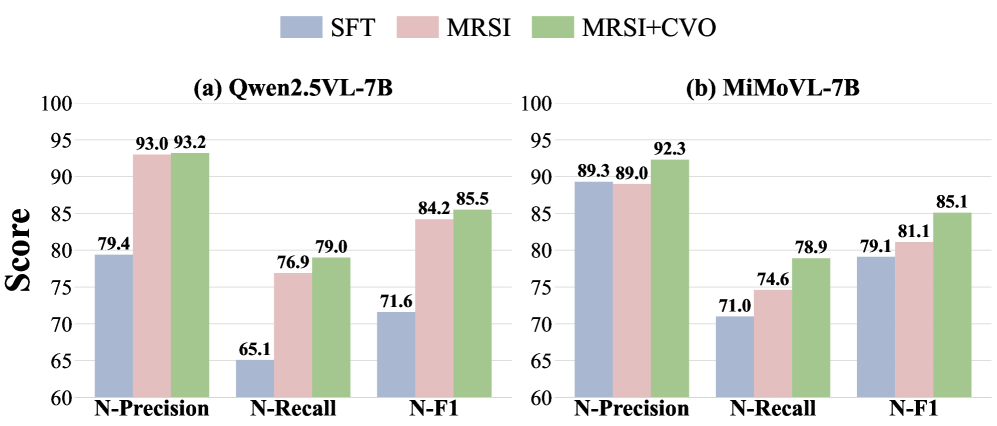
Исследования показали значительное снижение как текстовых, так и визуальных предубеждений в мультимодальных моделях благодаря применению разработанных методов. В частности, зафиксировано улучшение метрики N-F1 для текстовых предубеждений на 14% по сравнению с использованием только контролируемой тонкой настройки (SFT). При этом, уровень визуальных предубеждений, оцениваемый по показателю N-Rate, снижен до пренебрежимо малых значений. Эти результаты свидетельствуют о перспективном пути к созданию более надежных и объективных мультимодальных систем, способных к беспристрастному анализу и интерпретации информации из различных источников.
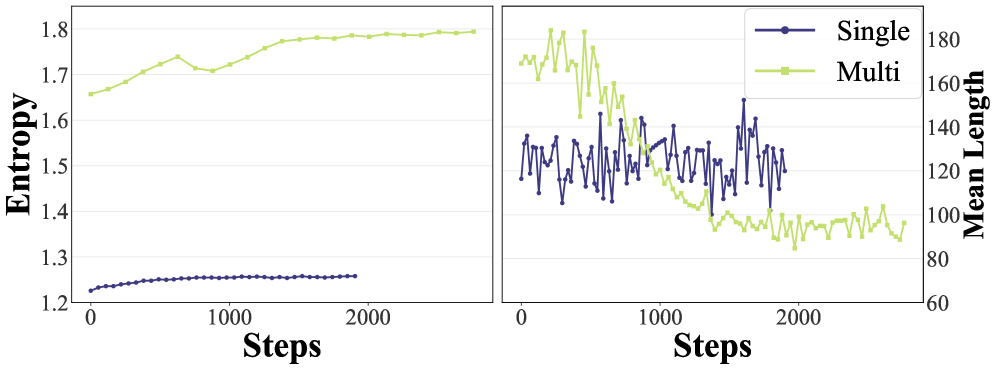
Интеграция метода Chain-of-Thought (CoT) с вышеописанными техниками обучения значительно углубляет способность мультимодальных моделей к рассуждениям и повышает прозрачность принимаемых ими решений. CoT побуждает модель не просто выдавать ответ, но и последовательно излагать ход своих мыслей, что позволяет отследить логику рассуждений и выявить потенциальные ошибки. Такой подход не только улучшает точность ответов, но и делает систему более понятной и надежной, поскольку пользователь может оценить, насколько обоснованным является полученный результат. По сути, CoT обеспечивает своего рода «внутренний монолог» модели, раскрывая её мыслительный процесс и способствуя развитию доверия к искусственному интеллекту.

Исследование демонстрирует, что существующие мультимодальные большие языковые модели склонны к предвзятости, полагаясь на доминирующую модальность. Предложенный фреймворк акцентирует внимание на структурированном кросс-модальном рассуждении, что позволяет моделям более последовательно и точно идентифицировать именованные сущности. Как отмечал Марвин Минский: «Лучший способ понять, что нужно сделать, — это просто сделать это». Эта простота, в контексте данной работы, проявляется в стремлении к созданию алгоритма, который не просто работает на тестовых данных, но и демонстрирует устойчивость и масштабируемость за счёт последовательного анализа информации из различных модальностей. Важно, что предложенный подход позволяет верифицировать согласованность информации, что является ключевым аспектом для надёжного распознавания именованных сущностей.
Что Дальше?
Представленная работа, хоть и демонстрирует улучшение в задаче привязки именованных сущностей к визуальному контексту, не решает фундаментальной проблемы: доверия к логике, заключенной в больших мультимодальных языковых моделях. Достигнутая устойчивость к модальным искажениям — лишь частичное решение. Необходимо переходить от эмпирической оценки «работы» алгоритма к доказательству его корректности. Попытки усилить кросс-модальное рассуждение с помощью обучения с подкреплением — это, по сути, аппроксимация идеального дедуктивного вывода. Вопрос в том, насколько близко эта аппроксимация может подойти к истине.
Следующим шагом видится разработка формальных методов верификации мультимодальных моделей. Необходимо определить инварианты, которые гарантируют согласованность между текстовым и визуальным представлением информации. Асимптотическая сложность таких методов может оказаться высокой, но это цена, которую необходимо заплатить за надежность. Оценка лишь на тестовых данных — это ненадежный критерий. Алгоритм должен быть доказуемо верен, а не просто успешно проходить тесты.
Игнорирование математической строгости в области искусственного интеллекта — это опасная тенденция. В конечном итоге, системы, основанные на непроверенных алгоритмах, обречены на ошибки, которые могут иметь серьезные последствия. Истинная элегантность заключается не в скорости работы, а в математической чистоте и доказуемой корректности.
Оригинал статьи: https://arxiv.org/pdf/2602.04486.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Моделирование биомолекул: новый импульс от нейросетей
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- БиоАгент: Проверка ИИ на прочность в мире геномики
- Тонкий SVD в смешанной точности: ускорение вычислений без потери качества
- Командная работа агентов: обучение без обновления модели
- Квантовые Загадки и Финансовые Реалии
2026-02-06 01:01