Автор: Денис Аветисян
Исследователи предлагают комплексный подход к оптимизации производительности и энергоэффективности больших языковых моделей, объединяя передовые алгоритмы и специализированное аппаратное обеспечение.
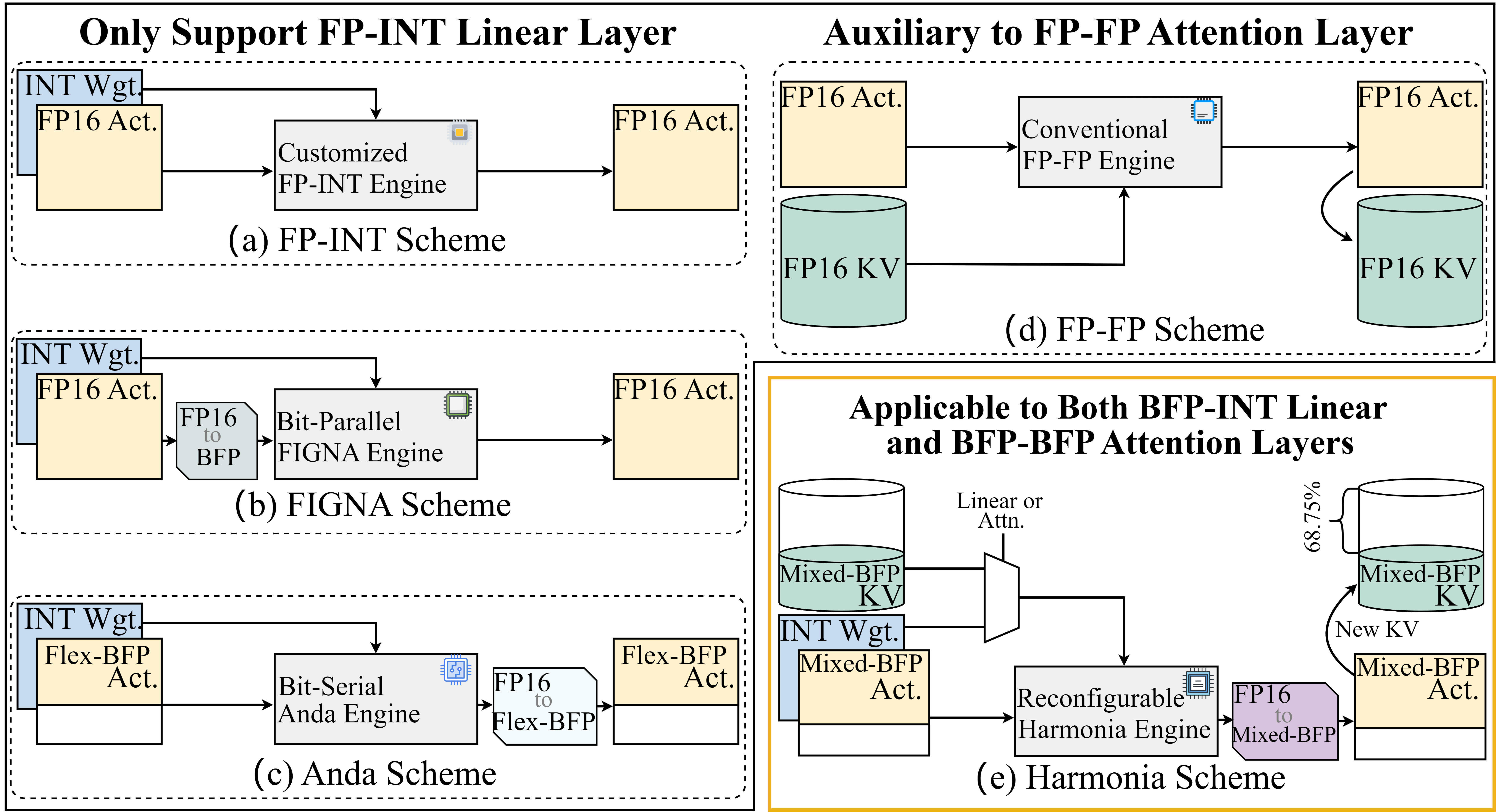
Представлена Harmonia — система, использующая блочную плавающую точку и смешанные вычисления для ускорения инференса больших языковых моделей с оптимизацией использования памяти.
Большие языковые модели (LLM) демонстрируют впечатляющие возможности, однако их развертывание ограничено высокими требованиями к памяти и вычислительным ресурсам. В данной работе, ‘Harmonia: Algorithm-Hardware Co-Design for Memory- and Compute-Efficient BFP-based LLM Inference’, предложен инновационный алгоритмико-аппаратный подход, позволяющий значительно повысить эффективность вычислений за счет использования блочной плавающей точки (BFP) для всех слоев LLM и оптимизации аппаратной архитектуры. Разработанная система Harmonia обеспечивает сжатие данных и снижение энергопотребления без существенной потери точности, используя асимметричное распределение бит и технику сглаживания выбросов для кэша KV. Возможно ли дальнейшее повышение эффективности LLM за счет разработки специализированных аппаратных ускорителей для смешанных форматов данных и оптимизации потока данных?
Закон масштабирования: Препятствие на пути к прогрессу
Современные большие языковые модели, такие как Llama-3.1-405B, демонстрируют впечатляющие возможности в обработке и генерации текста, однако их дальнейшее развитие сдерживается так называемым законом масштабирования. Этот закон предполагает, что для достижения значительного улучшения производительности требуется экспоненциальный рост вычислительных ресурсов и объёма данных для обучения. Несмотря на постоянное совершенствование архитектуры моделей и алгоритмов обучения, увеличение масштаба становится всё более затратным и сложным. Таким образом, дальнейший прогресс в области больших языковых моделей напрямую зависит от преодоления ограничений, связанных с законом масштабирования, и поиска более эффективных способов использования доступных ресурсов для обучения и развёртывания этих мощных систем.
Авторегрессивная генерация, лежащая в основе работы больших языковых моделей, создает узкое место, связанное с пропускной способностью памяти. В процессе генерации текста модель последовательно предсказывает следующий токен, опираясь на все ранее сгенерированные. Это требует постоянного и многократного доступа к памяти для извлечения этих предыдущих токенов, что становится особенно проблематичным при работе с моделями огромных размеров и длинными последовательностями текста. По мере увеличения числа параметров модели и длины генерируемого текста, потребность в пропускной способности памяти растет экспоненциально, ограничивая скорость вычислений и затрудняя развертывание действительно масштабных и мощных языковых моделей. Таким образом, оптимизация доступа к памяти становится критически важной задачей для дальнейшего развития и эффективного использования потенциала больших языковых моделей.
Несмотря на постоянное совершенствование архитектуры больших языковых моделей, их широкое внедрение сталкивается с серьезным препятствием — нехваткой пропускной способности памяти. Этот узкий участок, возникающий в процессе авторегрессивной генерации, ограничивает скорость доступа к ранее сгенерированным токенам, что существенно замедляет работу модели. В результате, даже при наличии более мощных и сложных алгоритмов, потенциал крупных языковых моделей, таких как Llama-3.1-405B, остается нереализованным из-за физических ограничений аппаратного обеспечения. Таким образом, преодоление этой проблемы с пропускной способностью памяти является ключевым фактором для дальнейшего развития и повсеместного использования больших языковых моделей.
Квантизация: Путь к эффективности и экономии ресурсов
Квантизация является эффективным методом развертывания моделей, позволяющим снизить вычислительные затраты и объем памяти, необходимый для хранения и обработки данных. Суть метода заключается в преобразовании высокоточных числовых представлений (например, 32-битные числа с плавающей точкой) в форматы с более низкой битностью (например, 8-битные целые числа). Это достигается за счет уменьшения количества бит, используемых для представления каждого значения, что приводит к уменьшению размера модели и ускорению вычислений. В процессе квантизации происходит округление или усечение значений, что потенциально может привести к некоторой потере точности, однако при правильной реализации влияние на общую производительность модели может быть минимальным.
Квантизация весов (Weight-Only Quantization) является методом оптимизации моделей, при котором веса сети преобразуются в формат пониженной точности, сохраняя при этом активации в формате с плавающей точкой (FP). Это позволяет значительно уменьшить размер модели, однако, не решает проблему размера KV-кэша, который продолжает занимать значительное количество памяти. Для эффективного сжатия KV-кэша и достижения максимального уменьшения размера модели, часто требуются дополнительные методы, такие как KIVI и Omniquant, специально разработанные для компрессии данных в KV-кэше.
Методы KIVI и Omniquant представляют собой расширения стандартной квантизации, направленные на сжатие KV-кэша (Key-Value cache) в моделях машинного обучения. В отличие от традиционной квантизации, которая может охватывать все параметры модели, KIVI и Omniquant фокусируются исключительно на уменьшении размера KV-кэша, критически важного для эффективной работы больших языковых моделей. По результатам тестирования, применение данных методов позволяет достичь сжатия KV-кэша до 31.25% от исходного размера, что существенно снижает требования к памяти и пропускной способности при развертывании моделей.
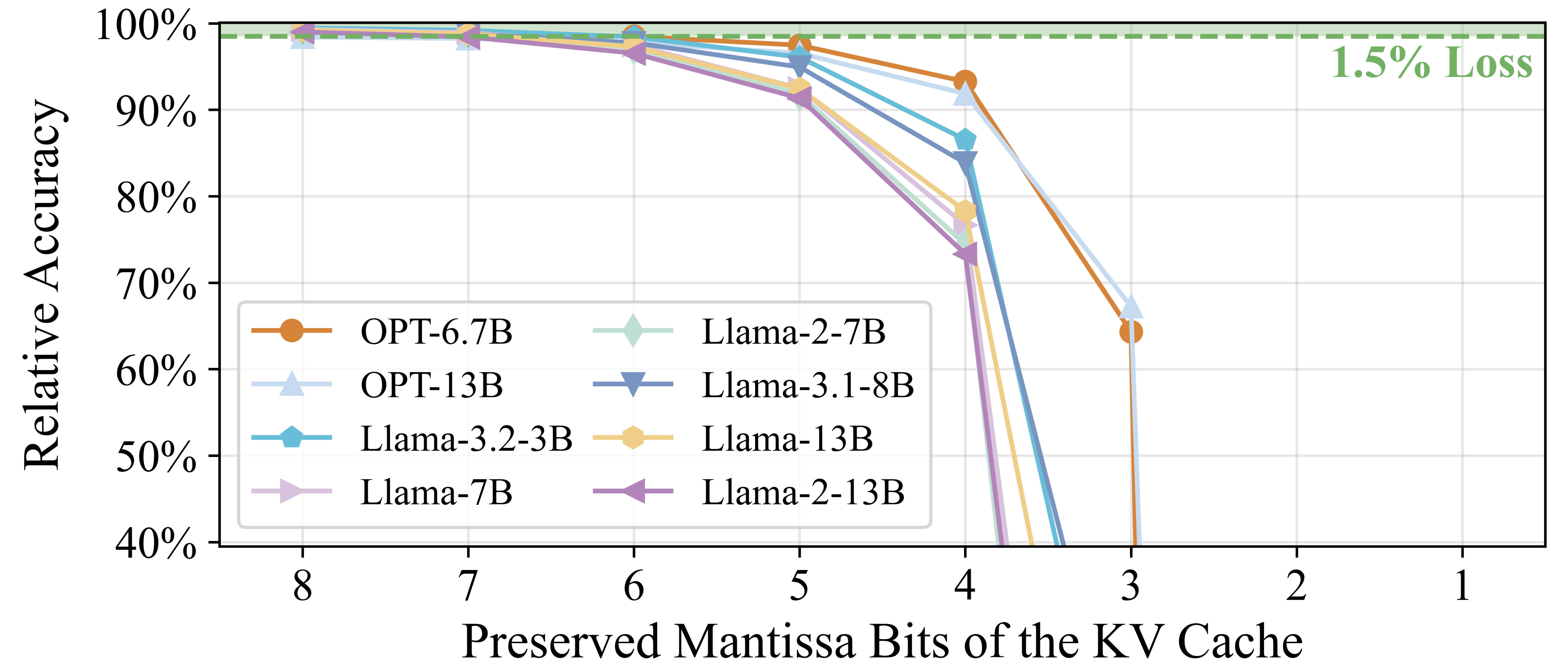
При грамотном управлении точностью, квантизация моделей с использованием 4-битных мантисс позволяет достичь в среднем падения точности всего в 0.3% по различным моделям. Это достигается за счет оптимизации представления чисел с плавающей точкой, уменьшая их разрядность без значительной потери информации. Важно отметить, что величина падения точности может варьироваться в зависимости от архитектуры модели и используемого набора данных, однако, среднее значение в 0.3% демонстрирует высокую эффективность метода квантизации для сохранения производительности при значительном снижении требований к памяти и вычислительным ресурсам.
Harmonia: Унифицированная точность для ускоренного вывода
Harmonia представляет собой совместно разработанную алгоритмическую и аппаратную платформу, использующую унифицированное представление BFP (Brain Floating Point) для всех активаций в архитектуре Transformer. В отличие от традиционных подходов, требующих различных форматов представления данных, Harmonia обеспечивает согласованность на протяжении всего процесса вычислений, что упрощает проектирование и повышает эффективность. Это достигается за счет интеграции алгоритмических оптимизаций с низкоуровневой аппаратной реализацией, позволяя динамически адаптировать точность вычислений в соответствии с требованиями задачи и доступными ресурсами. Унифицированное представление BFP охватывает все типы данных, включая входные данные, веса и промежуточные результаты, что снижает накладные расходы на преобразование типов и повышает общую производительность.
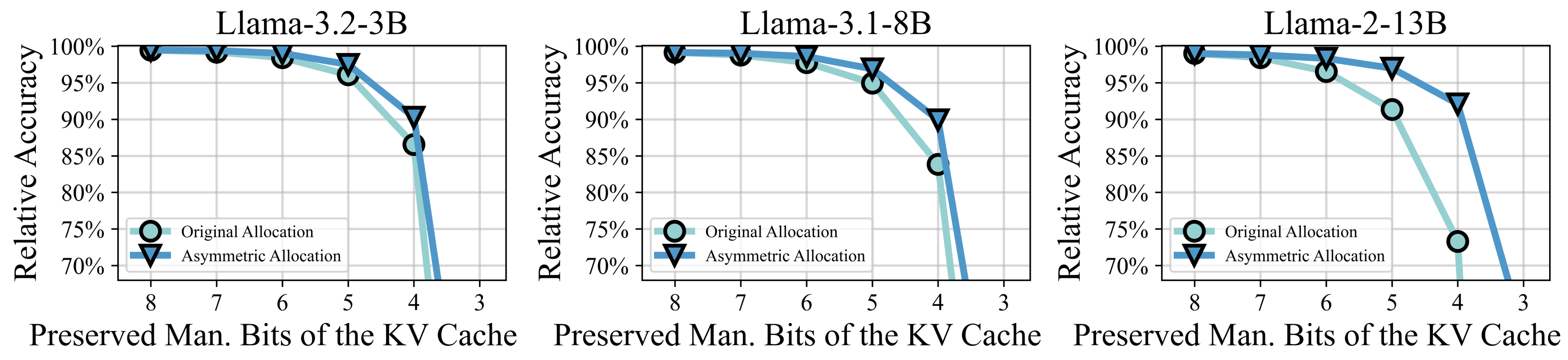
В основе Harmonia лежит асимметричное распределение бит (Asymmetric Bit Allocation), которое динамически регулирует точность представления данных в KV-кэше в зависимости от их значимости. Этот подход позволяет назначать больше битов наиболее важным данным, обеспечивая высокую точность вычислений, и меньше битов менее значимым данным, что снижает вычислительную нагрузку и потребление энергии. Динамическая адаптация точности осуществляется на основе анализа важности данных в процессе инференса, что позволяет оптимизировать производительность и эффективность использования ресурсов для больших языковых моделей.
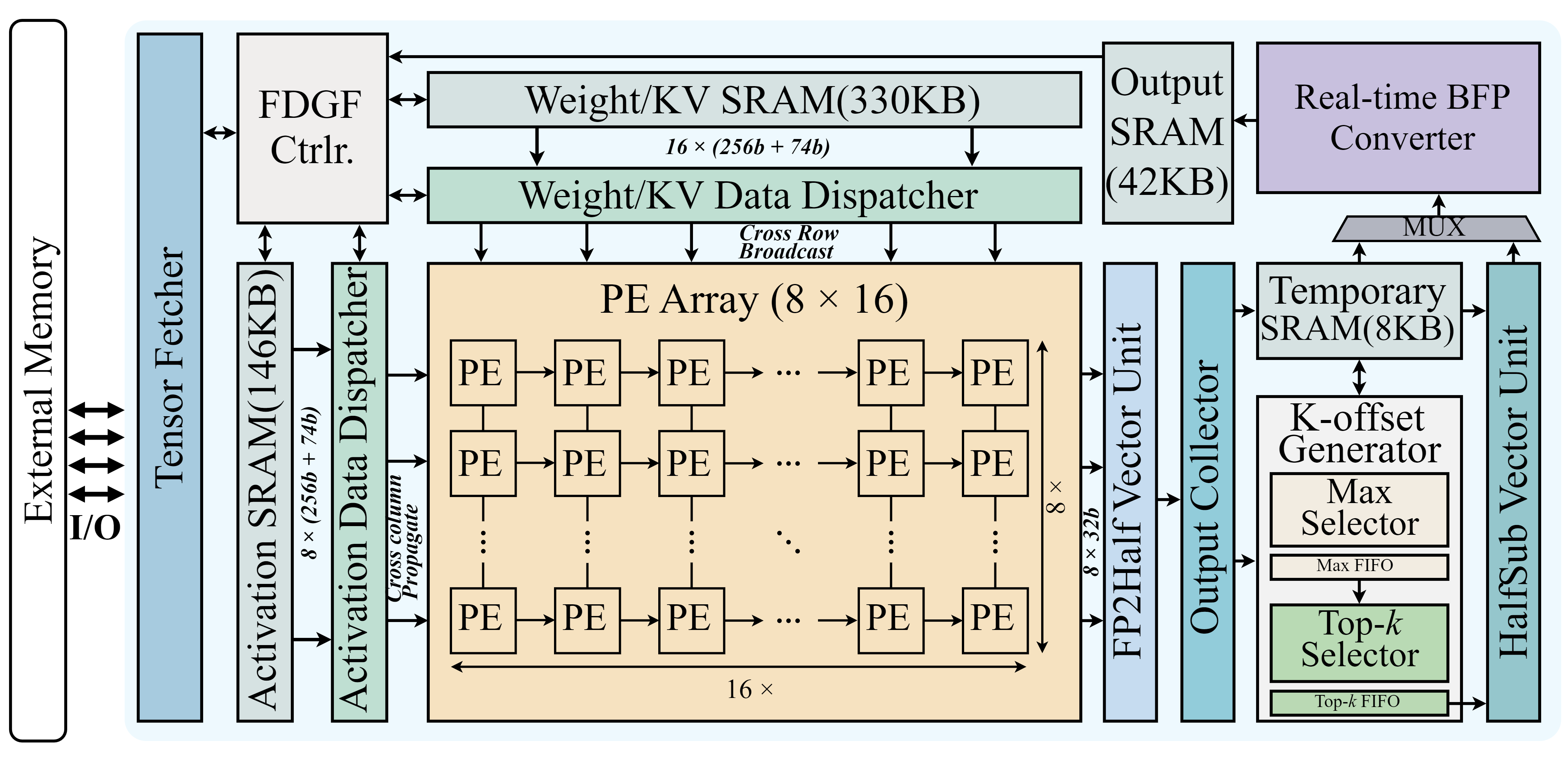
Реализация Harmonia опирается на реконфигурируемый вычислительный блок (PE Unit), способный выполнять операции как с BFP (Brain Floating Point) и целыми числами (INT), так и между различными представлениями BFP. Оптимизация доступа к памяти достигается за счет Tiling-Aware Dataflow — стратегии, разбивающей данные на плитки для повышения локальности и минимизации задержек при обращении к памяти. Данная архитектура позволяет динамически адаптировать вычислительный блок к требованиям конкретных операций и форматам данных, обеспечивая высокую эффективность и производительность при выводе больших языковых моделей.
В ходе тестирования Harmonia продемонстрировала значительное повышение производительности при выводе больших языковых моделей (LLM). Зафиксировано ускорение в 3.08 раза по сравнению с базовыми решениями. Кроме того, Harmonia обеспечивает улучшение эффективности использования площади на 3.84 раза и снижение энергопотребления на 2.03 раза. Эти показатели подтверждают, что разработанный алгоритм-аппаратный комплекс позволяет существенно оптимизировать ресурсы, необходимые для работы LLM, без потери точности и скорости обработки.
При обработке последовательностей длиной от 2048 до 16384 токенов, Harmonia демонстрирует прирост производительности в диапазоне от 2.50 до 4.14 раза по сравнению с базовыми методами. Одновременно с этим, потребление энергии снижается на 1.54-3.35 раза. Данные результаты получены в ходе тестирования и показывают значительное повышение эффективности при работе с длинными контекстами, что особенно важно для современных больших языковых моделей и задач, требующих обработки больших объемов информации.
Гибридное сглаживание выбросов (Hybrid Outlier Smoothing) в Harmonia предназначено для повышения устойчивости и предотвращения снижения производительности при обработке данных с аномальными значениями. Данный механизм минимизирует влияние отдельных выбросов, которые могут искажать результаты вычислений и приводить к ошибкам. Алгоритм динамически адаптирует точность представления данных, снижая чувствительность к экстремальным значениям без значительной потери общей точности. Это достигается путем комбинирования различных стратегий обработки выбросов, обеспечивающих надежную работу системы даже в условиях неидеальных входных данных и предотвращающих деградацию производительности при обработке последовательностей различной длины.
За пределами текущих ограничений: Влияние и перспективы
Подход Harmonia успешно преодолевает ограничения, ранее накладываемые так называемым «узким местом пропускной способности памяти» (Memory Bandwidth Bottleneck). Эффективное управление точностью вычислений и доступом к памяти позволяет значительно снизить требования к пропускной способности, что достигается за счет оптимизации использования ресурсов. Вместо традиционного подхода, требующего высокой пропускной способности для обработки больших объемов данных, Harmonia динамически адаптирует точность вычислений, сохраняя при этом необходимую производительность. Такая оптимизация позволяет эффективно использовать доступные ресурсы и открывает возможности для развертывания сложных моделей, ранее недоступных на платформах с ограниченными ресурсами. Данная технология позволяет существенно повысить эффективность обработки информации и расширить возможности применения больших языковых моделей.
Возможность развертывания значительно более крупных языковых моделей, таких как Llama-3.1-405B, на платформах с ограниченными ресурсами открывает новые перспективы для широкого спектра приложений. Ранее подобные модели требовали мощных серверных кластеров, делая их недоступными для многих пользователей и устройств. Благодаря оптимизации доступа к памяти и повышению точности вычислений, Harmonia позволяет эффективно использовать ограниченные ресурсы, такие как мобильные устройства или встроенные системы. Это означает, что передовые возможности обработки естественного языка, ранее доступные лишь в облаке, могут быть реализованы локально, обеспечивая более высокую скорость отклика, конфиденциальность данных и независимость от сетевого подключения. Подобный прогресс может существенно расширить область применения больших языковых моделей, включая персональных ассистентов, автономных роботов и интеллектуальных устройств интернета вещей.
Дальнейшие исследования направлены на разработку адаптивных схем точности, позволяющих динамически регулировать число бит, используемых для представления параметров модели, в зависимости от конкретной задачи и доступных ресурсов. Это позволит еще более эффективно использовать вычислительные мощности и память, открывая возможности для развертывания больших языковых моделей на устройствах с ограниченными возможностями. Кроме того, планируется расширение фреймворка Harmonia для поддержки более широкого спектра архитектур больших языковых моделей, включая трансформаторы с разреженной структурой и модели, использующие альтернативные методы квантования, что обеспечит универсальность и масштабируемость разработанного подхода.
Исследование, представленное в данной работе, демонстрирует подход к проектированию систем, где алгоритм и аппаратная часть разрабатываются совместно, что позволяет добиться значительного повышения эффективности. Подобный симбиоз напоминает попытку расшифровать сложный код, где понимание структуры необходимо для оптимизации каждого элемента. Как заметил Джон фон Нейманн: «В науке не бывает абсолютной истины, только приближения». Именно к этому принципу стремится Harmonia, оптимизируя представление данных в формате BFP и аппаратную архитектуру для смешанных вычислений, чтобы приблизиться к идеальной эффективности вывода больших языковых моделей. Ключевым моментом является не только разработка нового алгоритма, но и его тесная интеграция с аппаратным обеспечением, что позволяет максимально использовать ресурсы и добиться оптимальной производительности.
Куда же дальше?
Представленная работа, по сути, лишь зондирует поверхность. Преобразование активаций в формат блочной плавающей точки и оптимизация аппаратной части — это, безусловно, шаг вперёд, но истинный вызов заключается не в ускорении вычислений как таковых, а в преодолении фундаментальных ограничений представления информации. Забота об эффективности — это всегда поиск компромисса между точностью и скоростью, но где проходит эта граница? Следующий этап потребует более глубокого анализа влияния квантования на семантическую целостность модели, и, возможно, разработки новых, нетривиальных форматов представления данных, игнорирующих привычные дихотомии.
Особое внимание следует уделить обработке выбросов. Сглаживание — это паллиатив, а не решение. Более элегантным подходом представляется разработка алгоритмов, изначально устойчивых к аномалиям, способных извлекать смысл даже из «шума». Иными словами, необходимо переосмыслить саму концепцию «ошибки» — возможно, то, что мы считаем помехами, на самом деле содержит скрытую информацию. Аппаратная реализация такой системы потребует не просто оптимизации существующих блоков, а создания принципиально новых архитектур, способных к адаптивному обучению и самокоррекции.
И, наконец, следует помнить, что вся эта гонка за эффективностью — лишь инструмент. Главный вопрос остаётся открытым: что мы собираемся делать с полученной мощностью? Использовать её для создания ещё более сложных и непрозрачных моделей, или же направить усилия на понимание и интерпретацию существующих? Ответ на этот вопрос определит будущее не только больших языковых моделей, но и всего искусственного интеллекта в целом.
Оригинал статьи: https://arxiv.org/pdf/2602.04595.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Робот-исследователь: новый подход к автономной навигации
2026-02-06 02:58