Автор: Денис Аветисян
Исследователи предложили метод квантования кэша KV, позволяющий существенно снизить требования к памяти и создавать более длинные и качественные видеоролики.

Квантование кэша KV в авторегрессионных моделях видеогенерации для эффективного создания длинных видео с сохранением семантической целостности.
Несмотря на значительный прогресс в области авторегрессионной диффузии видео, узким местом является растущий объем памяти KV-кэша, ограничивающий как развертывание, так и возможности генерации. В работе ‘Quant VideoGen: Auto-Regressive Long Video Generation via 2-Bit KV-Cache Quantization’ представлен Quant VideoGen (QVG) — фреймворк, не требующий обучения, для квантизации KV-кэша в авторегрессионных моделях генерации видео. Используя семантически-ориентированное сглаживание и прогрессивную квантизацию остатков, QVG позволяет снизить потребление памяти в 7 раз, сохранив при этом высокое качество генерации видео. Какие перспективы открываются для дальнейшего повышения эффективности и масштабируемости авторегрессионной генерации видео с помощью методов квантизации?
Временные Изъяны: Вызовы Длинной Видеогенерации
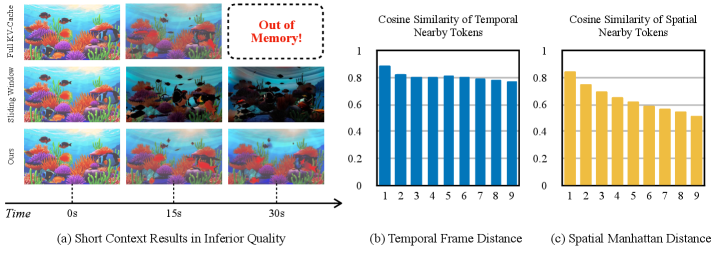
Генерация видеороликов с использованием диффузионных моделей сталкивается со значительными вычислительными трудностями при обработке длинных последовательностей, что приводит к проблеме, известной как «дрейф длинного горизонта». Суть явления заключается в постепенной потере когерентности и детализации изображения по мере увеличения длительности генерируемого видео. Изначально четкие и реалистичные кадры со временем становятся размытыми, искаженными или лишенными логической связи с предыдущими, что существенно снижает качество и правдоподобие конечного результата. Данная проблема обусловлена экспоненциальным ростом вычислительных затрат и требований к памяти по мере увеличения длительности генерируемой последовательности, что делает создание продолжительных и качественных видеороликов чрезвычайно сложной задачей.
Существующие методы генерации видео, такие как использование двунаправленного внимания, сталкиваются с трудностями в поддержании согласованности при создании длинных видеороликов. Несмотря на свою эффективность в обработке коротких последовательностей, эти подходы часто теряют контекст и детали по мере увеличения длительности генерируемого контента. Это приводит к постепенному искажению изображения, несоответствию действий и общей потере связности повествования. В результате, даже при использовании передовых алгоритмов, создание действительно качественных и продолжительных видео остается сложной задачей, требующей поиска новых решений для сохранения целостности визуальной информации на протяжении всего ролика.
Существенным ограничением при генерации длинных видеороликов с использованием диффузионных моделей является так называемый KV-Cache — механизм, накапливающий информацию о предыдущих кадрах для обеспечения последовательности. По мере увеличения длительности генерируемого видео, объем этой накопленной информации экспоненциально растет, приводя к значительному увеличению потребляемой памяти и вычислительной нагрузки. В результате, даже при использовании мощного оборудования, процесс генерации может замедляться или становиться невозможным из-за нехватки ресурсов. Эффективное управление и оптимизация KV-Cache является ключевой задачей для преодоления данного ограничения и создания действительно длинных и когерентных видеороликов с высоким качеством.
Квантование Видео: Новый Подход к Сжатию KV-Кэша
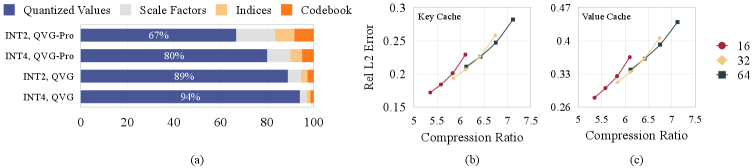
Quant VideoGen (QVG) представляет собой фреймворк для квантования KV-кэша, не требующий предварительного обучения. Данный подход позволяет значительно уменьшить занимаемый объем памяти без существенной потери качества генерируемого контента. В отличие от традиционных методов, QVG обеспечивает сжатие без необходимости в дополнительных тренировочных данных, что упрощает интеграцию и снижает вычислительные затраты. Это достигается за счет применения специализированных техник квантования, оптимизированных для сохранения семантической согласованности и визуального качества выходных данных. Фреймворк предназначен для эффективного сжатия KV-кэша в задачах генерации видео и других ресурсоемких приложений.
Quant VideoGen (QVG) реализует сжатие KV-кэша посредством двух основных техник. Первая — Semantic-Aware Smoothing — использует алгоритм K-Means для группировки семантически схожих токенов, что позволяет снизить вариативность данных и уменьшить требуемый объем памяти. Вторая техника, Progressive Residual Quantization, заимствует принципы из стриминговых видеокодеков, последовательно квантуя остаточные значения после каждой итерации. Такой подход позволяет более эффективно кодировать информацию, сохраняя при этом значимые детали и снижая потери качества, что в совокупности обеспечивает высокую степень сжатия без существенного влияния на производительность модели.
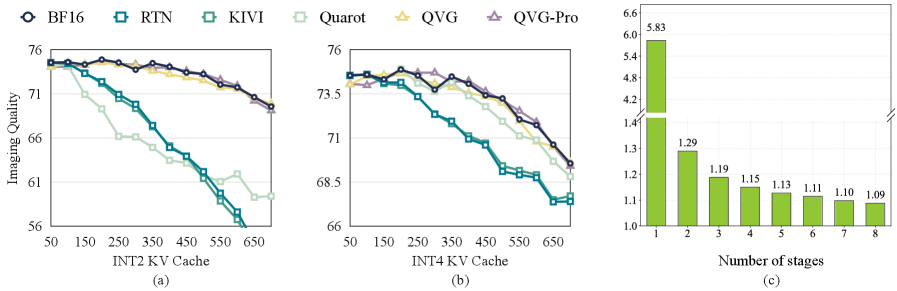
В отличие от традиционных методов квантизации, таких как RTN, KIVI и QuaRot, Quant VideoGen (QVG) ориентирован на сохранение перцептивного качества генерируемого видео, что обеспечивает превосходные результаты. Вместо простого снижения точности представления данных, QVG фокусируется на семантической связности токенов, что позволяет достичь сжатия памяти до 7.04x без существенной потери качества изображения. Такой подход, основанный на семантической когерентности, позволяет QVG превзойти существующие методы квантизации в задачах, где важна визуальная целостность и реалистичность генерируемого контента.
Эмпирическая Валидация и Бенчмаркинг Производительности
Для оценки эффективности предложенного метода квантизации видео (QVG) использовалась модель LongCat-Video, представляющая собой авторегрессивную диффузионную модель для генерации видео. Эксперименты с использованием LongCat-Video продемонстрировали способность QVG поддерживать высокое качество генерируемого видео при значительном снижении потребления памяти. Это достигается за счет эффективного сжатия данных без существенной потери визуальной информации, что подтверждает потенциал QVG для приложений с ограниченными ресурсами и высокой вычислительной нагрузкой.
Для валидации производительности QVG были проведены обширные эксперименты с использованием наборов данных MovieGen и VBench. Оценка проводилась на GPU H100 с применением метрик PSNR (пиковое отношение сигнал/шум), SSIM (структурное подобие) и LPIPS (воспринимаемое расстояние между изображениями). Использование данных наборов данных и указанных метрик позволило провести объективную оценку качества сжатия и реконструкции видео, подтвердив эффективность предложенного подхода QVG в сравнении с базовыми методами квантования.
Результаты экспериментов демонстрируют превосходство QVG над базовыми методами квантизации как по показателям перцептивного качества, так и по эффективности. Набор данных LongCat-Video-13B показал значение PSNR в 28.716, а HY-WorldPlay-8B — 29.174 при сжатии в 7.04 раза. При этом увеличение задержки (latency overhead) составило всего 4%, что подтверждает высокую производительность QVG при сохранении качества видео.
Значение и Перспективы Развития
Новая методика QVG позволяет значительно расширить возможности генерации видеопоследовательностей, преодолевая ограничения, связанные с узким местом — кэшем KV (ключ-значение). Традиционно, объем этого кэша ограничивал длину генерируемого видео, поскольку для каждого кадра требовалось хранить информацию о предыдущих. QVG, благодаря оптимизации работы с этим кэшем, снижает потребность в его объеме, что позволяет создавать более длинные и сложные видео без потери качества или скорости генерации. Это открывает перспективы для создания действительно захватывающих иммерсивных опытов, виртуальной реальности нового поколения и инструментов для редактирования видео в реальном времени, где продолжительность и динамика контента больше не являются препятствием.
Данное нововведение открывает широкие перспективы для развития иммерсивных технологий, виртуальной реальности и систем редактирования видео в реальном времени. Возможность генерации более длинных и сложных видеопоследовательностей позволяет создавать принципиально новые пользовательские опыты, где виртуальные миры становятся более реалистичными и динамичными. В частности, это актуально для интерактивных повествований, где действия пользователя напрямую влияют на развитие сюжета, а также для создания детализированных и правдоподобных виртуальных сред, требующих обработки больших объемов визуальной информации. Более того, упрощение процесса редактирования видео в реальном времени позволит специалистам создавать контент более высокого качества с меньшими затратами времени и ресурсов, что особенно важно для таких областей, как кинематограф и трансляции.
Дальнейшие исследования направлены на интеграцию QVG с другими передовыми методами оптимизации, такими как CausVid и Self-Forcing. Ожидается, что синергия между QVG и этими архитектурами позволит значительно повысить производительность и масштабируемость систем генерации видео, преодолевая существующие ограничения. Сочетание преимуществ QVG в снижении нагрузки на KV-Cache с возможностями CausVid по моделированию причинно-следственных связей и Self-Forcing по управлению процессом генерации, позволит создавать более сложные, динамичные и продолжительные видеопоследовательности, открывая новые горизонты для иммерсивных технологий и редактирования видео в реальном времени. Исследователи планируют изучить различные стратегии комбинирования этих методов, чтобы добиться максимальной эффективности и расширить возможности применения в различных областях.
Исследование, представленное в данной работе, демонстрирует стремление к оптимизации систем генерации видео, что перекликается с идеей о неизбежном старении любой системы. Авторы, подобно инженерам, сталкивающимся с ограничениями ресурсов, ищут способы продлить «жизнь» модели, уменьшая её «возраст» в виде потребляемой памяти. Как гласит известная фраза Бертрана Рассела: «Страх — это следствие воображения». В контексте данной работы, страх перед неэффективностью и ограничениями памяти преодолевается посредством инновационной квантизации KV-кэша. Подобный подход позволяет системе не просто существовать, но и «созревать», генерируя более длинные и качественные видеоролики, демонстрируя, что даже в условиях ограниченных ресурсов, система способна к развитию и адаптации.
Что Дальше?
Представленная работа, несомненно, демонстрирует умение обуздать растущие требования к памяти в генеративных моделях видео. Однако, оптимизация — лишь временная победа над энтропией. Квантование KV-кэша — элегантный, но все же компромисс. Истинный вызов заключается не в уменьшении следа, а в переосмыслении самой архитектуры, в создании систем, способных к самовосстановлению и адаптации к изменяющимся условиям. Каждый артефакт, каждое искажение в сгенерированном видео — это не ошибка, а момент истины во временной кривой, свидетельство несовершенства модели и ее уязвимости перед течением времени.
Очевидно, что дальнейшие исследования должны быть направлены на изучение возможностей семантически осознанного сглаживания, но не как инструмента для маскировки недостатков, а как способа интеграции принципов адаптивности в саму структуру генерации. Технический долг, накопленный в виде упрощений и оптимизаций, — это закладка прошлого, которую мы платим настоящим. Необходимо искать подходы, позволяющие не просто генерировать длинные видео, а создавать системы, способные к долгосрочному обучению и эволюции.
В конечном счете, все системы стареют — вопрос лишь в том, делают ли они это достойно. Время — не метрика, а среда, в которой существуют системы. Истинный прогресс заключается не в увеличении продолжительности жизни модели, а в создании систем, способных к изящному и осмысленному старению, сохраняя при этом свою целостность и способность к творчеству.
Оригинал статьи: https://arxiv.org/pdf/2602.02958.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Робот-исследователь: новый подход к автономной навигации
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Наука на Автопилоте: Система для Самостоятельных Исследований
2026-02-06 04:45