Автор: Денис Аветисян
Исследователи предлагают перейти от реактивного поиска вредоносных шаблонов к проактивному выявлению статистически атипичных данных для повышения безопасности больших языковых моделей.
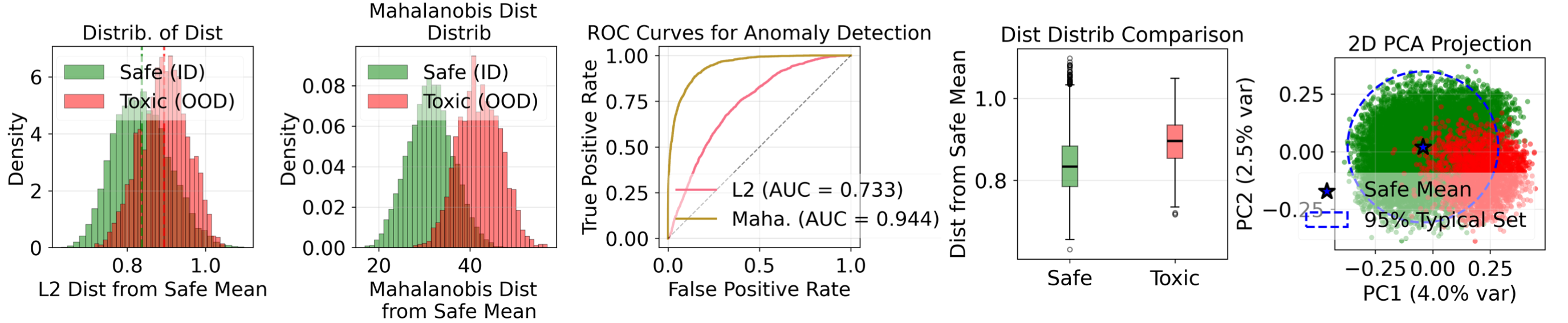
Представлен фреймворк T3, обеспечивающий передовую производительность и минимальные накладные расходы при обнаружении аномалий в тексте и интеграции с vLLM для защиты в реальном времени.
Современные подходы к обеспечению безопасности больших языковых моделей (LLM) часто сводятся к игре в кошки-мышки, основанной на блокировке известных угроз. В данной работе, озаренной названием ‘Trust The Typical’, предложен принципиально иной подход: надежная безопасность достигается не путем перечисления вредоносного, а путем глубокого понимания безопасного. Мы представляем Trust The Typical (T3) — фреймворк, рассматривающий безопасность как задачу обнаружения выходящих за рамки нормального (OOD) данных, демонстрирующий передовые результаты в 18 бенчмарках и снижающий количество ложных срабатываний до 40 раз, при этом требуя обучения исключительно на безопасных текстах. Возможно ли создание действительно надежных LLM, способных адаптироваться к различным доменам и языкам без постоянной перенастройки и затрат ресурсов?
За пределами сопоставления с образцами: Ограничения традиционной безопасности LLM
Современные подходы к обеспечению безопасности больших языковых моделей (LLM) в значительной степени опираются на реактивное сопоставление с образцами, то есть выявление и блокировку заранее известных вредоносных текстов и конструкций. Эта методика функционирует подобно фильтру, который эффективно задерживает известные угрозы, однако демонстрирует ограниченную эффективность при столкновении с новыми, ранее не встречавшимися атаками. Суть заключается в том, что система способна лишь реагировать на уже зафиксированные шаблоны, а не предвидеть и предотвращать появление принципиально новых видов злоумышленного контента. В результате, злоумышленники могут успешно обходить защиту, используя незначительные изменения в формулировках или создавая замаскированные запросы, которые не соответствуют известным вредоносным шаблонам, что подрывает надежность и безопасность LLM.
Существующие методы обеспечения безопасности больших языковых моделей (LLM) оказываются неэффективными при столкновении с новыми, специально разработанными примерами, так называемыми «атакующими примерами». Эти примеры, часто созданные с использованием сложных техник, таких как HILL-атаки, искусно маскируют вредоносное намерение, обходя стандартные фильтры и механизмы блокировки. Вместо прямого выражения опасного контента, злоумышленники используют тонкие манипуляции с текстом, которые эксплуатируют уязвимости в процессе обработки LLM, заставляя модель генерировать нежелательные или вредоносные ответы. Таким образом, стандартные подходы, основанные на обнаружении известных шаблонов, оказываются бессильными против этих изощренных атак, демонстрируя необходимость разработки более продвинутых и адаптивных систем безопасности.
Существенное ограничение современных систем безопасности больших языковых моделей (LLM) заключается в их неспособности к обобщению и адаптации к новым, ранее не встречавшимся угрозам. Вместо глубокого понимания намерений, LLM полагаются на сопоставление с известными образцами вредоносного контента. Это делает их уязвимыми перед постоянно эволюционирующими векторами атак, когда злоумышленники разрабатывают новые способы маскировки вредоносных запросов. Поскольку LLM не способны предвидеть и эффективно реагировать на неизвестные угрозы, они остаются восприимчивыми к обходу систем безопасности и потенциальному нанесению вреда, что подчеркивает необходимость разработки более продвинутых, проактивных методов обеспечения безопасности.
Существующие методы обеспечения безопасности больших языковых моделей (LLM) зачастую ограничиваются реактивным подходом, выявляющим и блокирующим уже известные вредоносные шаблоны. Однако, такая стратегия резко контрастирует с необходимостью проактивных мер безопасности, направленных на предвидение и предотвращение потенциального ущерба до его возникновения. Вместо пассивного реагирования на проявленные угрозы, требуется разработка систем, способных анализировать намерения и контекст запросов, выявляя скрытые злонамеренные цели, даже если они представлены в новой, ранее не встречавшейся форме. Такой подход позволит перейти от борьбы с последствиями к предотвращению возникновения опасных ситуаций, обеспечивая более надежную и устойчивую защиту языковых моделей.
T3: Статистический подход к безопасности LLM
Подход T3 переосмысливает задачу обеспечения безопасности больших языковых моделей (LLM) как проблему обнаружения данных, выходящих за пределы распределения (out-of-distribution detection). Вместо непосредственного определения вредоносного контента, T3 фокусируется на выявлении входных данных, существенно отклоняющихся от ожидаемого распределения безопасного и типичного языкового использования. Это означает, что система обучена распознавать паттерны нормального, безопасного текста и сигнализирует об аномалиях, которые могут указывать на потенциально опасный или вредоносный запрос, даже если этот запрос не был явно представлен в обучающих данных. Такой подход позволяет проактивно выявлять новые и неизвестные угрозы, не полагаясь исключительно на заранее заданный список запрещенных слов или фраз.
В основе подхода T3 лежит принцип статистической типичности, заключающийся в построении модели распределения безопасного языкового использования. Данная модель позволяет идентифицировать отклонения от нормативного образца, рассматривая редкие или необычные входные данные как потенциально опасные. Фактически, T3 оценивает вероятность появления конкретного текста в рамках смоделированного распределения безопасного языка; низкая вероятность указывает на аномалию и, следовательно, на потенциальную угрозу. Этот процесс не требует явного определения опасных фраз или паттернов, а опирается исключительно на статистические характеристики безопасных данных.
В основе T3 лежит фреймворк Forte, использующий методы представления и многомерного обучения для создания надежной модели безопасного текста в пространстве вложений. Представление обучения (representation learning) позволяет преобразовать текстовые данные в векторные представления, отражающие семантическое содержание. Многомерное обучение (manifold learning) затем применяется для снижения размерности этих векторов, сохраняя при этом важные характеристики, определяющие безопасный язык. В результате, Forte формирует компактное и эффективное представление безопасного текста, позволяющее точно идентифицировать отклонения от ожидаемой нормальной языковой модели.
В рамках оценки эффективности, предложенный подход T3 продемонстрировал передовые результаты, достигнув значения AUROC (Area Under the Receiver Operating Characteristic curve) в 0.8882 на тестовом наборе WildGuardMix. Этот показатель превосходит результаты, полученные с использованием традиционных методов оценки безопасности больших языковых моделей. Достигнутое значение AUROC указывает на значительно более высокую способность T3 к точному выявлению потенциально опасных или нежелательных входных данных, что свидетельствует о существенном улучшении общей безопасности системы.

Реализация в реальном времени: Интеграция T3 в vLLM
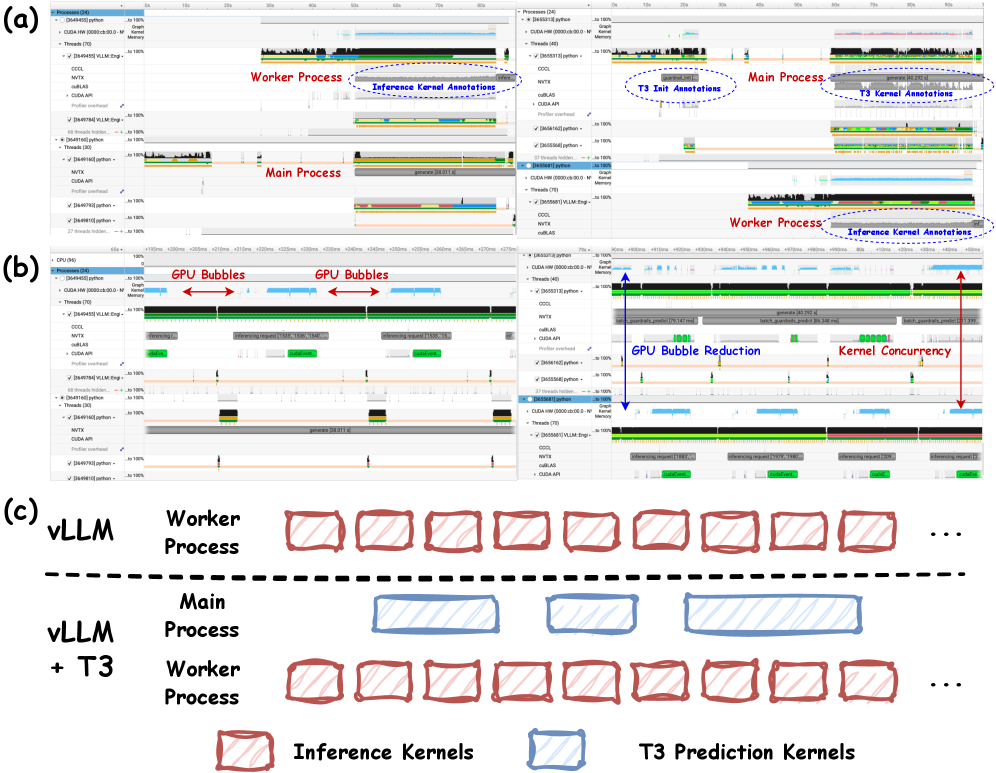
vLLM выступает в качестве инфраструктуры для инференса, обеспечивая бесшовную интеграцию T3 в процессы генерации больших языковых моделей (LLM) в режиме реального времени. Данный фреймворк позволяет внедрить T3 как часть конвейера инференса LLM, что дает возможность осуществлять проверку входных данных и блокировку потенциально опасного контента непосредственно перед генерацией текста. vLLM предоставляет необходимые инструменты и API для эффективного взаимодействия T3 с LLM, гарантируя низкую задержку и высокую пропускную способность при обработке запросов.
Эффективность фреймворка vLLM достигается за счет использования методов ‘PagedAttention’ и ‘Batching’. ‘PagedAttention’ оптимизирует управление памятью внимания, динамически выделяя и освобождая блоки памяти в процессе генерации, что снижает фрагментацию и повышает скорость доступа. ‘Batching’ позволяет обрабатывать несколько запросов параллельно, максимизируя использование ресурсов GPU и увеличивая пропускную способность системы. Комбинация этих техник обеспечивает высокую производительность и масштабируемость vLLM при работе с большими языковыми моделями.
Механизм T3 осуществляет проактивную блокировку потенциально вредоносного контента путем оценки статистической типичности каждого входного токена. Данный подход позволяет определить, насколько вероятно появление конкретного токена в контексте нормального языкового использования. Токены, демонстрирующие низкую статистическую типичность, классифицируются как потенциально опасные и блокируются до генерации ответа языковой моделью. Такая предварительная фильтрация позволяет предотвратить создание нежелательного контента на этапе формирования ответа, а не после его генерации.
Интеграция T3 в систему vLLM обеспечивает добавление надежного уровня безопасности без существенного снижения производительности. Согласно проведенным тестам, на нагрузке в 5000 запросов, использование T3 с высокой частотой оценки (каждые 20 токенов) приводит к увеличению задержки всего на 6%. Это означает, что добавление механизма фильтрации вредоносного контента не оказывает критического влияния на скорость генерации ответов, что делает данное решение применимым в реальных системах, требующих как высокой производительности, так и безопасности.
Система T3 демонстрирует высокую устойчивость к семантически схожим атакам, что подтверждается значением AUROC (Area Under the Receiver Operating Characteristic curve) более 0.98 при тестировании на наборе данных HILL (Harmful Instructions and LLM Attacks). Данный показатель свидетельствует о способности системы эффективно различать безопасный и вредоносный контент даже при незначительных изменениях в формулировках запросов, направленных на обход механизмов безопасности. Высокое значение AUROC указывает на низкий уровень ложноположительных и ложноотрицательных срабатываний при обнаружении потенциально опасных запросов.
За горизонтом обнаружения: Обещание безопасности «из коробки»
В основе подхода T3 лежит статистический анализ языковых закономерностей, что позволяет модели демонстрировать возможности “обучения без учителя” (zero-shot learning). Вместо того, чтобы полагаться на размеченные примеры вредоносного контента, T3 выявляет потенциально опасные тексты, опираясь на общие статистические характеристики языка. Это означает, что модель способна эффективно обнаруживать вредоносный контент даже в тех контекстах, с которыми она ранее не сталкивалась, что существенно расширяет её применимость и надежность в динамично меняющейся онлайн-среде. Такой подход позволяет не только идентифицировать известные типы угроз, но и адаптироваться к новым, ранее не встречавшимся формам злоумышленного контента, обеспечивая более всестороннюю защиту.
В отличие от традиционных подходов к обеспечению безопасности больших языковых моделей, основанных на обучении на размеченных данных, система T3 использует принципиально иной механизм. Вместо запоминания конкретных примеров вредоносного контента, она анализирует фундаментальные статистические закономерности, присущие самому языку. Такой подход позволяет T3 выявлять потенциально опасный текст, даже если он сформулирован новыми способами или касается ранее не встречавшихся тем. Система не нуждается в предварительном ознакомлении с конкретным типом угрозы, поскольку её защита строится на выявлении отклонений от нормативных языковых паттернов, обеспечивая, таким образом, более широкую и гибкую оборону от разнообразных видов вредоносного контента.
Исследования показывают, что способность модели T3 к обобщению значительно снижает количество ложных срабатываний по сравнению со специализированными моделями безопасности. В то время как традиционные подходы требуют обучения на большом количестве размеченных примеров для каждого конкретного типа вредоносного контента, T3 анализирует статистические свойства языка, что позволяет ей эффективно выявлять потенциально опасный текст даже в ранее не встречавшихся ситуациях. Результаты тестов демонстрируют, что эта способность приводит к снижению частоты ложных срабатываний в 10-40 раз, что особенно важно для практического применения и повышения доверия к большим языковым моделям. Такое существенное уменьшение количества ошибочных предупреждений позволяет более свободно развертывать LLM в различных приложениях, не опасаясь необоснованных блокировок и ограничений.
Результаты тестирования T3 на наборе данных WildGuardMix демонстрируют значительный прогресс в обеспечении безопасности больших языковых моделей. Достигнутый показатель FPR@95, равный 0.3663%, указывает на крайне низкий уровень ложных срабатываний — случаев, когда безобидный текст ошибочно классифицируется как вредоносный. Такая точность, превосходящая показатели специализированных моделей безопасности, открывает возможности для более широкого и надежного внедрения LLM в различные сферы, где критически важна защита от нежелательного контента и повышение доверия пользователей к этим технологиям. Это существенный шаг к созданию более безопасных и ответственных систем искусственного интеллекта.
Исследование демонстрирует, что попытки построить абсолютно безопасные системы на основе реактивного обнаружения аномалий обречены на провал. Авторы предлагают концепцию T3, фокусирующуюся на выявлении статистической атипичности входных данных, что соответствует принципу: системы — это не инструменты, а экосистемы. Вместо того чтобы пытаться предвидеть все возможные атаки, T3 стремится понять, что является нормальным поведением системы. Как однажды заметил Винтон Серф: «Интернет — это не просто технология, это способ организации информации». Это наблюдение перекликается с подходом T3: вместо того, чтобы рассматривать безопасность как отдельную функцию, необходимо интегрировать её в саму структуру системы, понимая её статистические свойства и границы нормального поведения. Акцент на выявлении атипичности, а не на перечислении известных угроз, позволяет системе адаптироваться к новым, ранее неизвестным атакам, что соответствует принципам эволюционной устойчивости.
Что Дальше?
Представленный подход, фокусируясь на выявлении статистической атипичности, лишь отчасти примиряет необходимость в надёжности больших языковых моделей и неизбежный хаос, присущий любой сложной системе. Иллюзия стабильности, достигаемая за счёт кэширования и реактивных мер, рано или поздно рассеивается. Гарантии, как и любая договорённость с вероятностью, остаются хрупкими. Следующим шагом видится не создание более изощрённых фильтров, а развитие методов, способных органично встраивать неопределённость в саму архитектуру модели.
Особое внимание следует уделить исследованию нелинейных пространств признаков, где атипичность не является абсолютной, а представляет собой градиент отклонения от типичного. Манифольд обучения, как инструмент, способен лишь частично отразить эту сложность. Истинным вызовом является разработка систем, которые не просто детектируют отклонения, а адаптируются к ним, извлекая пользу из непредсказуемости.
В конечном счёте, системы безопасности — это не инструменты, а экосистемы. Их нельзя построить, только взрастить. Вместо того чтобы стремиться к абсолютному контролю, необходимо научиться доверять типичному, признавая, что хаос — это не сбой, а язык природы. Следующее поколение систем безопасности должно не подавлять атипичность, а учиться на ней.
Оригинал статьи: https://arxiv.org/pdf/2602.04581.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Робот-исследователь: новый подход к автономной навигации
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Самообучающиеся признаки: новый подход к машинному обучению
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Искусственный интеллект: хрупкость визуального мышления
2026-02-06 06:17