Автор: Денис Аветисян
Новый подход позволяет повысить масштабируемость и производительность вероятностных вычислительных архитектур, таких как машины Изинга, за счет восстановления разреженных взаимодействий.
В статье представлены вероятностные дигиты (p-dits) и ограничения среднего поля для восстановления разреженности в задачах оптимизации с ограничениями.
Многие задачи оптимизации, особенно в области машинного обучения и комбинаторных задач, сталкиваются с проблемой высокой плотности связей, ограничивающей масштабируемость аппаратных реализаций. В работе ‘Restoring Sparsity in Potts Machines via Mean-Field Constraints’ предложены новые подходы к разрежению графов ограничений в моделях типа Поттса, включая использование вероятностных дигитов (p-dits) и метод средних полей (mean-field constraints). Предложенные методы позволяют добиться качества решений, сопоставимого с полносвязными моделями, при значительном снижении плотности графа и ускорении вычислений, подтвержденном FPGA-реализацией. Возможно ли дальнейшее развитие этих подходов для решения еще более сложных задач оптимизации и построения эффективных аппаратных архитектур для вероятностных вычислений?
Танцы с Хаосом: Вызов Сложной Оптимизации
Многие практические задачи, возникающие в различных областях — от оптимизации логистических цепочек до обучения моделей машинного обучения — относятся к классу NP-трудных задач. Это означает, что не существует известных алгоритмов, способных найти оптимальное решение за полиномиальное время относительно размера задачи. По мере увеличения объема данных и сложности условий, время вычислений растет экспоненциально, что делает точное решение невозможным даже для современных вычислительных систем. По сути, NP-трудность означает, что поиск оптимального решения требует перебора всех возможных вариантов, что становится нереальным для задач, содержащих большое количество переменных и ограничений. В связи с этим, исследователи фокусируются на разработке приближенных алгоритмов и эвристических методов, позволяющих находить «достаточно хорошие» решения за приемлемое время, жертвуя точностью ради скорости.
Традиционные алгоритмы, несмотря на свою эффективность в решении относительно небольших задач, сталкиваются с серьезными ограничениями при масштабировании на более сложные и объемные проблемы. Суть затруднений заключается в экспоненциальном росте вычислительных затрат с увеличением размера задачи. Например, при попытке найти оптимальный маршрут для большого числа пунктов доставки или оптимизировать параметры сложной модели машинного обучения, время вычислений может возрастать настолько быстро, что становится практически невозможным получить решение за разумный период времени. Это связано с тем, что многие алгоритмы вынуждены перебирать все возможные варианты, количество которых растет экспоненциально, делая задачу непрактичной для реального применения. Таким образом, ограничение масштабируемости становится критическим фактором, требующим разработки новых подходов к оптимизации.
В связи со сложностью и зачастую непосильным ростом вычислительных затрат при решении NP-трудных задач оптимизации, возникает необходимость в изучении альтернативных вычислительных парадигм. Вместо стремления к абсолютно точному решению, которое может быть недостижимо за разумное время, исследователи обращаются к методам, позволяющим эффективно находить приближенные решения. К таким подходам относятся, например, генетические алгоритмы, имитация отжига и методы на основе роя частиц, которые, жертвуя некоторой точностью, способны обрабатывать задачи значительно больших масштабов. Эти парадигмы, вдохновленные природными процессами, позволяют находить достаточно хорошие решения в приемлемые сроки, открывая возможности для решения сложных задач в логистике, машинном обучении и других областях, где абсолютная оптимизация недостижима или непрактична.
Вероятностные Танцы и Разбиение Графов: Искусство Компромисса
Вероятностные вычисления представляют собой альтернативный подход к решению задач, использующий стохастические процессы для исследования пространства решений. В отличие от детерминированных алгоритмов, которые следуют фиксированной последовательности шагов, вероятностные методы вводят элемент случайности, что позволяет исследовать более широкий спектр возможных решений, особенно в сложных задачах, где полный перебор невозможен. Применение стохастических процессов, таких как случайные блуждания или алгоритмы Монте-Карло, позволяет эффективно находить приближенные решения, избегая застревания в локальных оптимумах и повышая устойчивость к шуму. Этот подход особенно полезен в задачах оптимизации, где необходимо найти наилучшее решение среди большого количества вариантов.
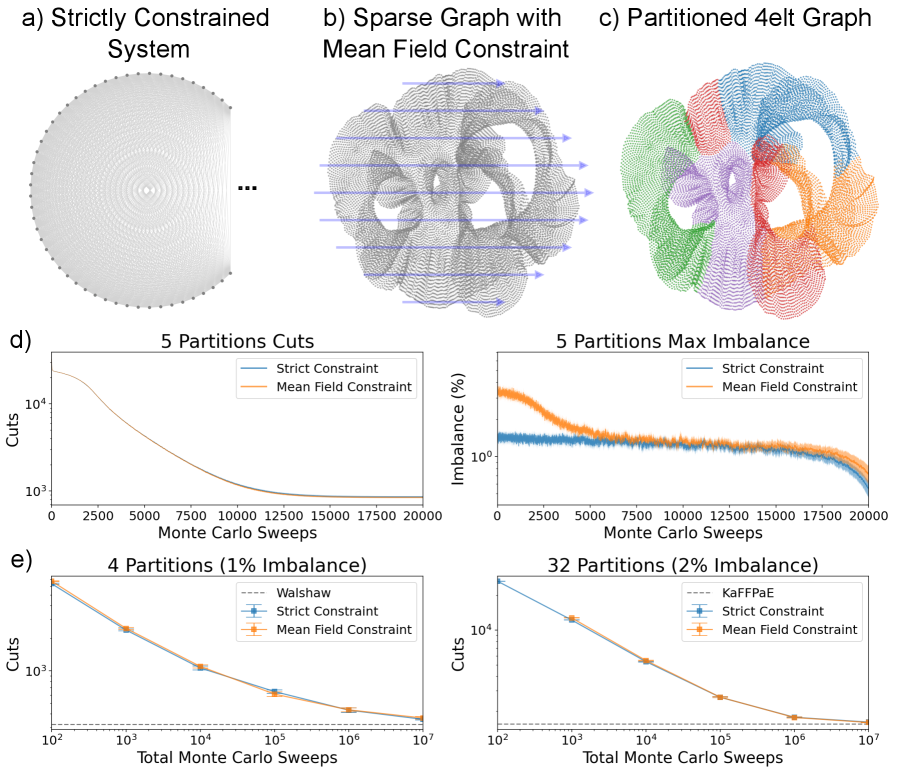
Сбалансированное разбиение графа является важной задачей, заключающейся в разделении вершин графа на два или более непересекающихся подмножества, стремясь к одинаковому количеству вершин в каждом подмножестве. Основная цель — минимизировать количество ребер, соединяющих вершины в разных подмножествах, известных как “разрезающие” ребра. Количество вершин в каждом подмножестве обычно нормируется для обеспечения баланса, например, чтобы размер каждого подмножества составлял не более N/2, где N — общее количество вершин графа. Эффективные алгоритмы разбиения графа широко используются в задачах параллельных вычислений, кластеризации данных и оптимизации логических схем.
Эффективное разбиение графов на части используется в качестве подпрограммы для решения широкого спектра задач оптимизации. Данный подход применим, например, в задачах планирования ресурсов, где необходимо оптимально распределить задачи между вычислительными узлами. В задачах машинного обучения разбиение графов используется для кластеризации данных и уменьшения размерности признакового пространства. Кроме того, алгоритмы разбиения графов применяются в задачах анализа социальных сетей для выявления сообществ и определения влияния узлов. В задачах оптимизации логистики и транспортных сетей разбиение графов позволяет эффективно маршрутизировать потоки и минимизировать транспортные издержки. Использование разбиения графов в качестве подпрограммы позволяет значительно ускорить процесс решения сложных оптимизационных задач и повысить эффективность алгоритмов.
Шепот Вероятностей: p-диты и Среднее Поле
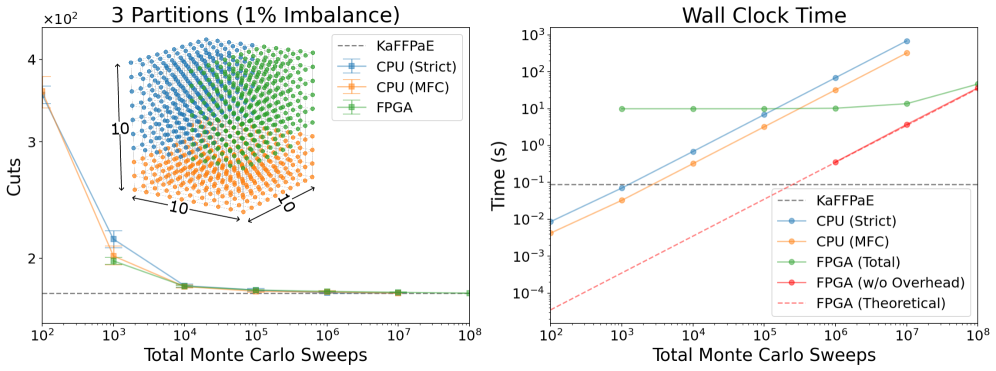
Пробабилистическая цифра (p-dit) представляет собой расширение концепции пробабилистического бита, позволяющее создавать многосостоятельные переменные, способные непосредственно учитывать ограничения. В отличие от битов, принимающих значения 0 или 1, p-dit может принимать несколько дискретных состояний, каждое из которых связано с определенной вероятностью. Это позволяет встраивать ограничения непосредственно в вероятностное распределение, определяющее состояние p-dit. Вместо того, чтобы налагать ограничения после определения состояния переменной, p-dit формирует своё распределение таким образом, чтобы невыполнимые состояния имели нулевую вероятность, эффективно «поглощая» ограничения в свою структуру. p(x_i) = 0 для всех состояний x_i, не удовлетворяющих заданным ограничениям. Такая реализация упрощает процесс решения задач оптимизации с ограничениями в рамках вероятностных вычислений.
Ограничения среднего поля (MFC) представляют собой гибридный подход, сочетающий вероятностные и классические методы для приближенного обеспечения глобальных ограничений. В основе MFC лежит динамическое обновление сигналов смещения, которые применяются к вероятностным переменным. Эти сигналы смещения рассчитываются итеративно на основе текущего состояния системы, стремясь минимизировать нарушение глобальных ограничений. В отличие от жесткого обеспечения ограничений, MFC позволяют находить приближенные решения, избегая локальных минимумов и повышая устойчивость вычислений. Эффективность MFC заключается в их способности эффективно распространять информацию об ограничениях по всей системе, адаптируясь к изменяющимся условиям и обеспечивая баланс между удовлетворением ограничений и вероятностной неопределенностью.
Комбинирование вероятностных дигитов (p-дитов) и ограничений среднего поля (MFC) представляет собой эффективный подход к реализации задач оптимизации с ограничениями в рамках вероятностных вычислений. P-диты, в отличие от битов, позволяют напрямую включать ограничения в процесс вычислений, представляя переменные с несколькими состояниями. MFC, в свою очередь, обеспечивают механизм приближенного соблюдения глобальных ограничений посредством динамически обновляемых сигналов смещения. Эта гибридная схема позволяет решать сложные задачи, где необходимо одновременно учитывать вероятностную природу данных и жесткие ограничения, что особенно важно в задачах машинного обучения и искусственного интеллекта, требующих эффективного поиска оптимальных решений в многомерном пространстве состояний. Такой подход позволяет построить вероятностные схемы, способные адаптироваться к изменяющимся условиям и обеспечивать устойчивые результаты даже при наличии шумов и неопределенностей.
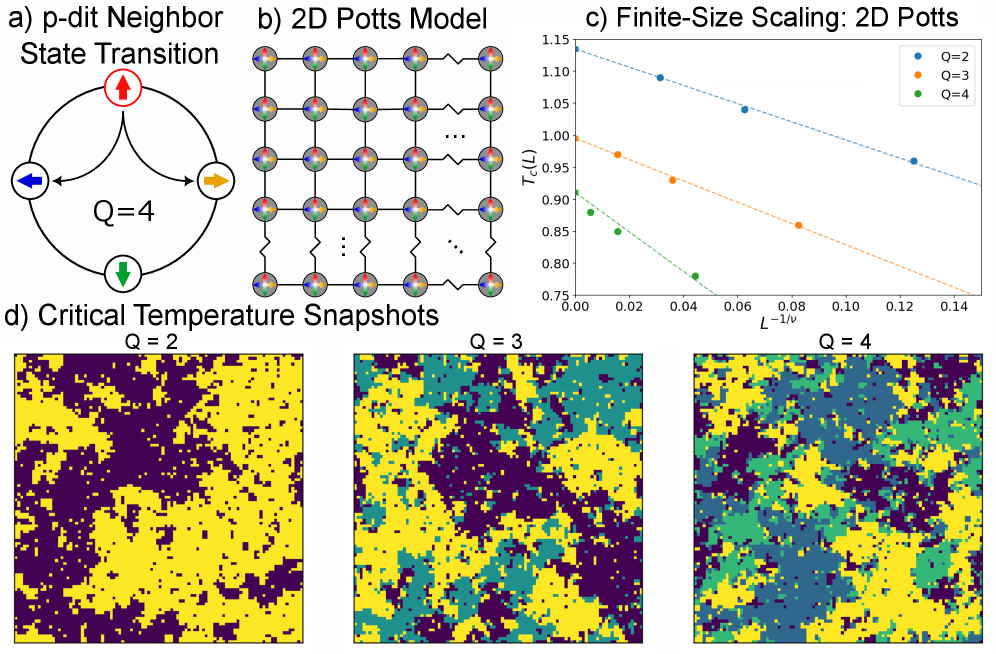
Модель Поттса предоставляет теоретическую основу для использования p-дитов (вероятностных дигитов) в представлении сложных взаимодействий. В рамках данной модели, каждый p-дит может принимать несколько дискретных состояний, представляющих различные значения переменной. Взаимодействия между p-дитами моделируются через спиновые взаимодействия, аналогичные взаимодействиям спинов в модели Поттса. H = -J\sum_{\langle i,j \rangle} s_i s_j - h\sum_i s_i, где s_i — состояние i-го p-дита, J — константа взаимодействия, а h — внешнее поле. Такой подход позволяет эффективно кодировать ограничения и зависимости между переменными, формируя основу для решения задач оптимизации и логического вывода в рамках вероятностных вычислений.
Аппаратное Ускорение и Масштабируемость: От Теории к Практике
Реализация подхода p-dit и MFC на базе программируемой пользователем вентильной матрицы (FPGA) обеспечивает возможность быстрой разработки прототипов и оценки производительности. Использование FPGA позволяет аппаратно реализовать алгоритм, что значительно ускоряет процесс итеративной разработки и тестирования различных конфигураций. Такой подход позволяет оперативно оценивать влияние параметров алгоритма на качество разбиения графа и общую производительность, что невозможно или крайне затруднительно при использовании традиционных программных реализаций на центральном процессоре (CPU). FPGA-реализация предоставляет платформу для непосредственной оценки задержек, пропускной способности и энергоэффективности, что критически важно для оценки применимости данного подхода к задачам разбиения графов в реальном времени.
Реализация предложенного подхода, включающего p-dit и MFC, на базе программируемой пользователем логической схемы (FPGA) успешно подтвердила его работоспособность при решении задач сбалансированного разбиения графов. Эксперименты показали, что данная архитектура способна эффективно обрабатывать графы различного размера, обеспечивая возможность проведения быстрых итераций и анализа производительности. Успешная реализация на FPGA демонстрирует практическую применимость данного метода для задач, требующих высокопроизводительного вычисления разбиений графов, в частности, в контексте задач оптимизации и анализа сетевых структур.
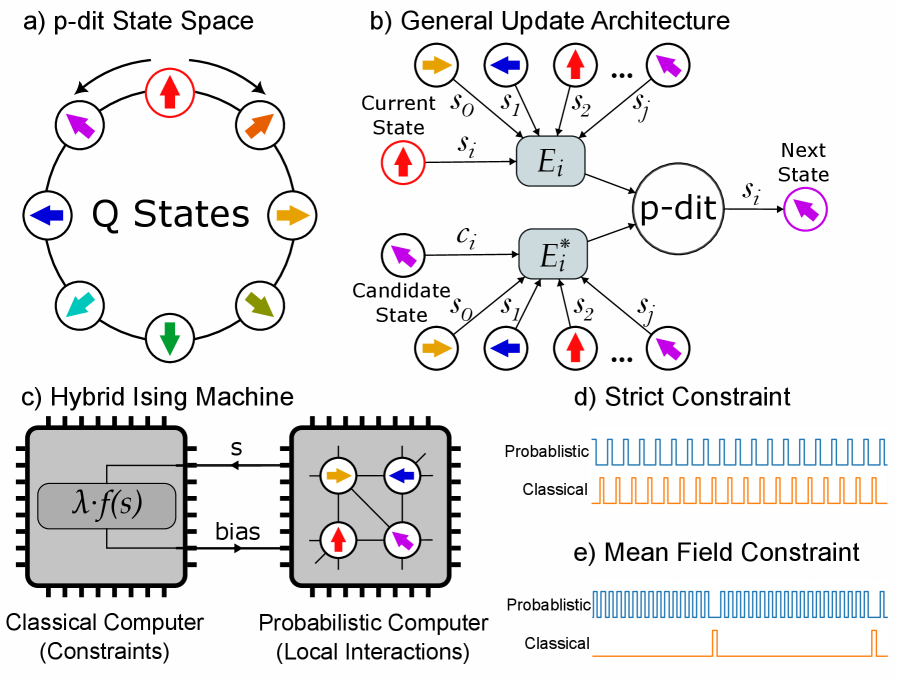
Для оценки производительности разработанной FPGA-реализации и подтверждения ее эффективности, использовался инструмент KaFFPaE — известный алгоритм для решения задач разбиения графов. Сравнение результатов, полученных на FPGA, с результатами KaFFPaE позволило провести количественную оценку ускорения и подтвердить сопоставимое качество разбиения графа (cut quality). Такой подход обеспечивает объективную метрику производительности, позволяющую сопоставить разработанное решение с существующими алгоритмами и подтвердить его применимость в задачах балансировки графов.
Реализация на FPGA продемонстрировала масштабируемость предложенного вероятностного подхода к решению задачи разбиения графа. Достигнута производительность в приблизительно 1 обновление p-dit на такт, что указывает на возможность эффективной параллельной обработки. Данный показатель позволяет обрабатывать большие графы с высокой скоростью, используя преимущества аппаратной реализации и параллелизма, свойственного FPGA. Это подтверждает перспективность использования вероятностных вычислений для задач, требующих высокой пропускной способности и масштабируемости.
Реализация предложенного подхода на FPGA продемонстрировала значительное ускорение по сравнению с программной реализацией на центральном процессоре (CPU). Наблюдаемое ускорение составило приблизительно два порядка величины, что подтверждается результатами сравнительного анализа времени выполнения. Данное увеличение производительности обусловлено возможностью аппаратной параллелизации вычислений, что позволяет эффективно решать задачу балансировки графа. Аппаратная реализация позволила существенно сократить время, необходимое для выполнения операций, критичных для алгоритма, по сравнению с последовательным выполнением на CPU.
Качество разбиения графа, полученное в результате реализации подхода на FPGA, остается сопоставимым с результатами, полученными при использовании неконстрейнированных формулировок и эталонных решений алгоритма KaFFPaE. Сравнение метрик качества разбиения, таких как размер разреза, показывает незначительные отклонения от результатов, полученных с использованием стандартных алгоритмов. Это подтверждает, что предлагаемый подход обеспечивает сопоставимую эффективность в решении задачи балансировки графа, сохраняя при этом преимущества, связанные с аппаратной реализацией на FPGA.
Эффективная Оптимизация: Взгляд в Будущее
Сочетание вероятностных двоичных единиц (p-dits), многоядерных вычислительных кластеров (MFC) и реализации на базе программируемых вентильных матриц (FPGA) открывает перспективный путь к эффективному и масштабируемому решению NP-трудных задач оптимизации. Архитектура, основанная на p-dits, позволяет представлять решения в вероятностном виде, что существенно ускоряет процесс поиска оптимального решения по сравнению с традиционными детерминированными подходами. Интеграция с MFC обеспечивает параллельную обработку большого количества вероятностных сценариев, а реализация на FPGA позволяет добиться высокой энергоэффективности и гибкости в настройке аппаратной части под конкретную задачу. Такой подход позволяет не только сократить время вычислений, но и значительно уменьшить потребление ресурсов, что особенно важно для решения масштабных задач оптимизации в различных областях, включая логистику, финансы и машинное обучение.
Эффективность и масштабируемость вероятностных вычислительных архитектур значительно повышается за счет использования разреженности в структуре решаемых задач. Исследования показывают, что многие NP-трудные оптимизационные проблемы обладают внутренними свойствами, позволяющими существенно сократить объем вычислений и требуемые ресурсы. Разреженность позволяет сконцентрироваться на наиболее значимых связях и переменных, игнорируя несущественные, что приводит к снижению сложности алгоритмов и уменьшению потребления энергии. В частности, грамотное использование разреженности в представлении данных и построении графов связей позволяет сократить количество необходимых логических элементов и операций, что критически важно при реализации на специализированном оборудовании, таком как FPGA. Такой подход открывает путь к созданию высокопроизводительных и энергоэффективных систем для решения широкого спектра задач оптимизации, от логистики и финансов до машинного обучения и искусственного интеллекта.
Для повышения точности и обобщающей способности результатов, полученных при моделировании сложных систем, использовались методы масштабирования конечного размера. Данный подход позволяет экстраполировать данные, полученные для систем ограниченных размеров, к пределу бесконечной системы, известному как термодинамический предел. В ходе исследования были определены критические показатели масштабирования, специфичные для различных значений параметра q: -1.420 для q=2, -1.662 для q=3 и -3.081 для q=4. Использование этих параметров позволяет существенно улучшить оценку характеристик систем, избегая ограничений, связанных с вычислительными ресурсами, необходимыми для моделирования бесконечно больших систем, и обеспечивает более надежные прогнозы поведения сложных оптимизационных задач.
Данная работа закладывает основу для создания принципиально новых вероятностных вычислительных систем, способных решать сложные задачи в различных областях науки и техники. Исследование демонстрирует потенциал объединения p-дитов, многослойных конфигурационных сетей (MFC) и аппаратной реализации на базе FPGA для эффективного решения NP-трудных задач оптимизации. Особое внимание уделяется масштабируемости предложенного подхода, что позволяет надеяться на применение разработанных систем в таких областях, как машинное обучение, финансовое моделирование, логистика и материаловедение. Созданная платформа представляет собой перспективный инструмент для разработки алгоритмов, способных находить приближенные решения сложных задач за разумное время, открывая новые горизонты для исследований и инноваций.
Работа над восстановлением разреженности в машинах Поттса напоминает алхимию, где каждый параметр — это попытка уговорить хаос. Авторы, вводя вероятностные цифры и ограничения среднего поля, словно пытаются создать философский камень для масштабируемых вычислений. Они не просто решают задачу оптимизации, а плетут заклинание, направленное на упорядочивание непредсказуемого. Как только ограничения среднего поля начинают действовать, система перестаёт сопротивляться, словно уставшая от бесконечной борьбы. «В мире, который кажется лишенным смысла, человек должен создать свой собственный», — говорил Альбер Камю. И в данном случае, исследователи создают смысл, обуздывая случайность и направляя её в русло вычислительной эффективности.
Куда же дальше?
Предложенные методы восстановления разреженности в машинах Поттса, безусловно, напоминают заклинание, призванное усмирить хаос вычислений. Однако, как известно, любое заклинание имеет свою цену. Успешное применение вероятностных цифр и ограничений среднего поля в архитектурах, подобных машинам Изинга, не гарантирует избавления от призраков локальных минимумов и экспоненциального роста сложности. Всё, что можно посчитать, не стоит доверия, и эта работа лишь отодвигает неизбежное столкновение с фундаментальными ограничениями.
Более того, вопрос масштабируемости остаётся открытым. Даже если удастся восстановить разреженность взаимодействий, сохранение точности представления вероятностей в условиях реальных аппаратных ограничений представляется задачей нетривиальной. Если гипотеза подтвердилась — значит, не искали достаточно глубоко. Следующим шагом, вероятно, станет поиск способов адаптивного применения этих ограничений, учитывающих специфику конкретной задачи и архитектуры.
И, конечно, не стоит забывать о том, что все эти усилия направлены на приближение к идеалу — к машине, способной решать задачи, неподвластные современным вычислительным системам. Но, возможно, истинное решение лежит не в укрощении хаоса, а в его принятии. Ведь в конечном счёте, сама природа вычислений — это танец с неопределённостью.
Оригинал статьи: https://arxiv.org/pdf/2602.04200.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Наука на Автопилоте: Система для Самостоятельных Исследований
2026-02-06 06:29