Автор: Денис Аветисян
Новый алгоритм LUSPO позволяет снизить зависимость от длины генерируемых текстов, повышая стабильность и эффективность обучения больших языковых моделей.
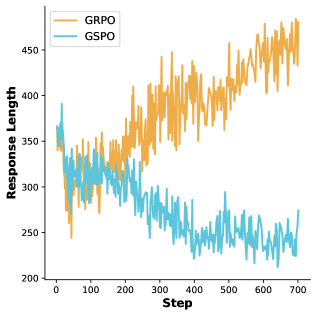
В статье представлена методика Length-Unbiased Sequence Policy Optimization для смягчения смещения, связанного с длиной ответов, в процессе обучения с подкреплением.
Несмотря на успехи обучения с подкреплением с проверяемыми наградами (RLVR) в повышении рассудительных способностей больших языковых и мультимодальных моделей, наблюдается значительная вариативность в изменении длины генерируемых ответов. В данной работе, посвященной ‘Length-Unbiased Sequence Policy Optimization: Revealing and Controlling Response Length Variation in RLVR’, проведен глубокий анализ основных компонентов современных RLVR-алгоритмов. Предложено решение в виде алгоритма LUSPO, устраняющего систематическую ошибку, связанную с длиной ответа, и обеспечивающего более стабильное обучение и повышение производительности. Сможет ли предложенный подход стать основой для новых стратегий оптимизации последовательностей и дальнейшего улучшения возможностей языковых моделей в сложных задачах?
Математические модели: когда «революция» оборачивается головной болью
Несмотря на впечатляющие возможности в обработке естественного языка, современные большие языковые модели (LLM) часто демонстрируют слабость в решении сложных математических задач. Эта проблема существенно ограничивает их применимость в областях, требующих высокой точности и логической последовательности, таких как научные исследования, финансовый анализ и инженерные расчеты. Неспособность LLM надежно оперировать математическими концепциями и выполнять многоступенчатые вычисления подрывает доверие к ним в критически важных приложениях, где даже незначительная ошибка может привести к серьезным последствиям. Например, при решении задач, требующих ∫x^2 dx или доказательстве теорем, модели часто допускают логические ошибки или предоставляют неверные ответы, демонстрируя недостаток истинного понимания математических принципов.
Попытки повышения способности больших языковых моделей (LLM) к решению математических задач путём простого увеличения их размера демонстрируют закономерное снижение эффективности. Несмотря на значительные вычислительные затраты, дальнейшее масштабирование перестаёт приносить существенные улучшения в логических рассуждениях и решении сложных уравнений. Данное явление указывает на необходимость поиска альтернативных подходов, направленных на оптимизацию архитектуры и алгоритмов обучения, а не только на увеличение количества параметров. Разработка более эффективных методов, способных качественно улучшить математические навыки LLM при меньших вычислительных ресурсах, представляется ключевой задачей для дальнейшего развития искусственного интеллекта в этой области. Вместо слепого увеличения масштаба, акцент смещается на разработку принципиально новых стратегий, способных обеспечить более глубокое понимание математических концепций и более точное выполнение расчетов.
Современные методы обучения с подкреплением для верификации (RLVR) нередко демонстрируют предвзятость, обусловленную длиной генерируемого ответа, что негативно сказывается на качестве получаемых решений. Исследования показывают, что модели, обученные с использованием RLVR, склонны отдавать предпочтение более длинным ответам, даже если они не содержат корректного решения задачи. Эта тенденция приводит к заметному снижению точности на специализированных бенчмарках, таких как AIME24, где требуется высокая степень математической строгости и лаконичности. Таким образом, простое увеличение длины ответа ошибочно воспринимается моделью как признак более полного и, следовательно, верного решения, что подчеркивает необходимость разработки методов, устойчивых к подобным искажениям и ориентированных на фактическую корректность и оптимальность представленного решения.
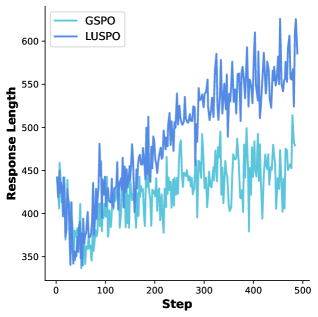
LUSPO: как обуздать «многословие» и заставить модель мыслить лаконично
Алгоритм LUSPO, новый подход в обучении с подкреплением, непосредственно решает проблему предвзятости к длине ответа, характерную для существующих методов RLVR. В отличие от традиционных подходов, LUSPO масштабирует функцию потерь последовательности на длину генерируемого ответа. Это означает, что более длинные ответы штрафуются сильнее, чем короткие, что способствует генерации лаконичных и точных решений. Такая корректировка функции потерь позволяет алгоритму более эффективно оптимизировать модель для получения ответов оптимальной длины, избегая тенденции к излишнему удлинению ответа без улучшения его точности.
Алгоритм LUSPO способствует генерации лаконичных и точных ответов за счет масштабирования потерь последовательности на ее длину. Данная корректировка позволяет снизить предвзятость, связанную с длиной ответа, что часто встречается в методах обучения с подкреплением для решения задач, требующих рассуждений. Уменьшение влияния длины ответа на оценку позволяет модели сосредоточиться на фактической корректности и логической последовательности рассуждений, что, в свою очередь, повышает надежность математических вычислений и улучшает общую производительность в задачах, требующих логического вывода.
Эксперименты с использованием моделей Qwen2.5-7B-Base, Qwen3-30B-A3B-Instruct и Qwen2.5-VL-7B-Instruct продемонстрировали эффективность LUSPO на различных архитектурах. В частности, на датасете AIME24 LUSPO показал до 6,9%-ного прироста точности по сравнению с алгоритмом GSPO. Данный результат подтверждает способность LUSPO улучшать качество математического рассуждения и повышать надежность генерируемых ответов, независимо от базовой модели.
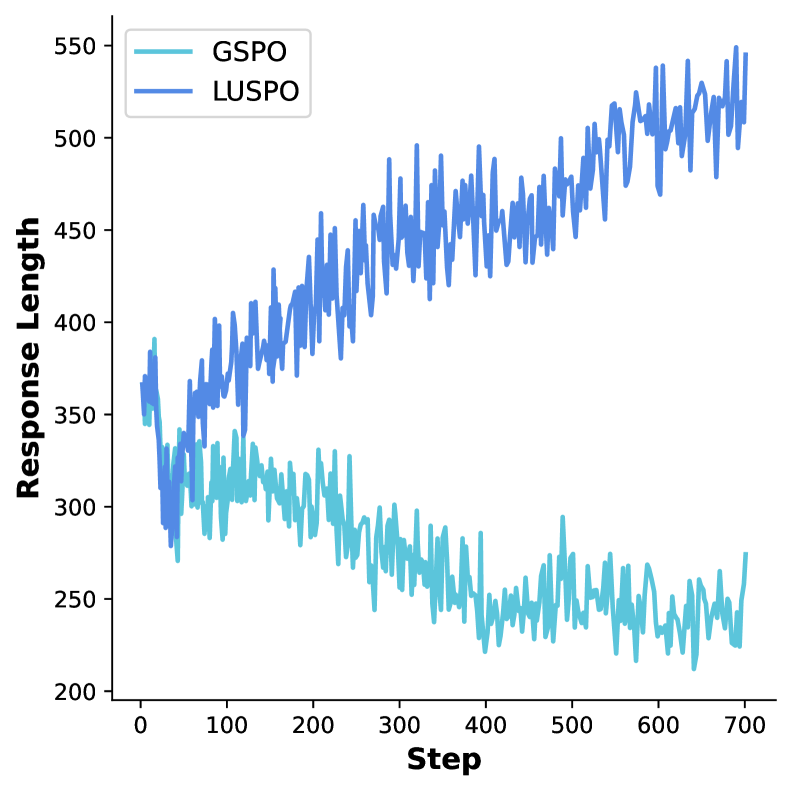
Проверка на прочность: LUSPO в действии на разнообразных математических тестах
Эффективность LUSPO была всесторонне проверена на разнообразных наборах данных, включая AIME24, MATH500, MathVista, DAPO-MATH-17K и ViRL39k. Использование этих наборов, отличающихся по объему, сложности и типу математических задач, подтверждает широкую применимость алгоритма к различным задачам математического моделирования и решения. Результаты валидации демонстрируют способность LUSPO успешно справляться с задачами, охватывающими различные области математики, что указывает на его универсальность и надежность в различных сценариях.
Результаты тестирования алгоритма демонстрируют устойчивое повышение производительности на различных математических бенчмарках. В частности, зафиксировано улучшение точности до 5,1% на наборе данных Wemath и до 6,0% на LogicVista по сравнению с алгоритмом GSPO. Данные показатели свидетельствуют о высокой надежности и способности алгоритма эффективно решать задачи различной сложности, охватывающие широкий спектр математических дисциплин и форматов представления.
Внедрение сигнала вознаграждения за точность является дополнительным механизмом, направленным на повышение корректности генерируемых решений. Этот сигнал, в сочетании со стратегией смягчения предвзятости к большей длине ответа, позволяет модели LUSPO более эффективно фокусироваться на получении правильных результатов. Сигнал вознаграждения за точность оценивает правильность каждого шага решения, поощряя генерацию корректных промежуточных и конечных результатов, что способствует повышению общей надежности и точности модели при решении математических задач.
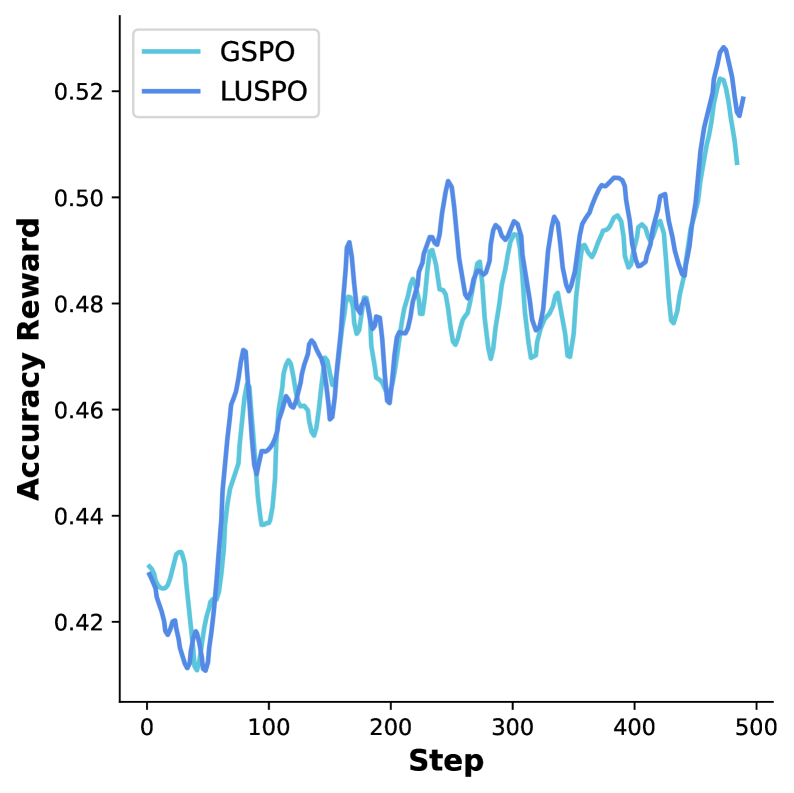
Оптимизация процесса рассуждений: как GSPO и GRPO дополняют LUSPO
Метод GSPO использует взвешивание важности на уровне последовательностей, что значительно повышает стабильность обучения моделей, основанных на Mixture-of-Experts. В отличие от традиционных подходов, GSPO динамически оценивает вклад каждого элемента последовательности в процесс решения задачи, придавая больший вес наиболее значимым частям. Это позволяет модели более эффективно фокусироваться на ключевых аспектах проблемы и избегать расхождений в процессе обучения, что, в конечном итоге, приводит к генерации более качественных и точных решений. Благодаря такому подходу, модель не только быстрее сходится к оптимальному решению, но и демонстрирует повышенную устойчивость к шумам и неполноте данных.
Алгоритм GRPO представляет собой инновационный подход к оптимизации процесса рассуждений, позволяющий значительно снизить вычислительную сложность и ускорить обучение моделей. В отличие от традиционных методов, требующих наличия отдельной оценочной модели для определения ценности каждого решения, GRPO вычисляет относительное преимущество каждого варианта внутри группы, напрямую сравнивая их между собой. Такой подход не только избавляет от необходимости обучения и поддержания дополнительной модели, но и повышает эффективность процесса принятия решений, позволяя моделям быстрее находить оптимальные решения и демонстрировать улучшенную производительность в задачах, требующих сложного логического мышления.
Разработанные алгоритмы, включающие GSPO, GRPO и LUSPO, представляют собой значительный прорыв в создании более эффективных и надёжных систем математического рассуждения. Внедрение LUSPO позволило смягчить предвзятость, связанную с длиной ответа, что позволило моделям генерировать решения в 1,5 раза длиннее, чем при использовании только GSPO, при этом сохраняя высокую точность. Такое сочетание методов открывает новые возможности для решения сложных математических задач, обеспечивая не только правильный ответ, но и более детальное и понятное объяснение процесса рассуждения. Этот подход способствует созданию интеллектуальных систем, способных не просто выдавать результат, но и демонстрировать логику своих действий, что крайне важно для доверия и понимания.

Исследование показывает, что даже самые передовые алгоритмы обучения с подкреплением склонны к систематическим ошибкам, когда дело касается оценки последовательностей разной длины. Авторы предлагают LUSPO — попытку обуздать эту непредсказуемость, но история подсказывает: каждое элегантное решение порождает новые сложности. Как будто мы не деплоим — мы отпускаем новую порцию проблем в продакшен. Барбара Лисков однажды заметила: «Программы должны быть разработаны так, чтобы их можно было расширять без изменения основных структур». Здесь же, кажется, мы пытаемся наложить порядок на хаос, понимая, что «скрам — это просто способ убедить людей, что хаос управляем». Попытка стабилизировать обучение языковых моделей путем учета смещения длины — это, по сути, признание того, что «багтрекер — это дневник боли», где каждая ошибка — лишь симптом более глубокой проблемы.
Что дальше?
Представленный алгоритм LUSPO, безусловно, элегантно решает проблему смещения длины в оптимизации последовательностей. Однако, не стоит обольщаться. Вспомните, как все начиналось — с простого bash-скрипта, а теперь это сложный механизм с Mixture-of-Experts. Сейчас это назовут AI и получат инвестиции, но, скорее всего, проблема технического долга просто переоденется в новую форму. Устойчивость обучения — это хорошо, но кто-нибудь проверил, как эта оптимизация масштабируется на действительно огромные языковые модели, где градиентный спуск превращается в мучительный процесс?
Вероятно, следующим шагом станет попытка объединить LUSPO с другими методами регуляризации, чтобы создать нечто вроде “супер-оптимизатора”. Хотя, честно говоря, начинаю подозревать, что они просто повторяют модные слова. Ключевым вопросом остаётся, как контролировать не только длину, но и качество генерируемых последовательностей. Ведь короткий, но бессмысленный ответ ничем не лучше длинного и бессвязного.
И, напоследок, документация снова соврала, не так ли? В любом случае, через пару лет это всё равно будет переписано с нуля. Каждая «революционная» технология завтра станет техдолгом. И так будет всегда.
Оригинал статьи: https://arxiv.org/pdf/2602.05261.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Облачные вычисления для науки: гибкость и масштабируемость
2026-02-06 12:56