Автор: Денис Аветисян
Исследователи предлагают инновационную систему, позволяющую интеллектуальным агентам более эффективно предвидеть последствия своих действий и принимать взвешенные решения в сложных интерактивных средах.
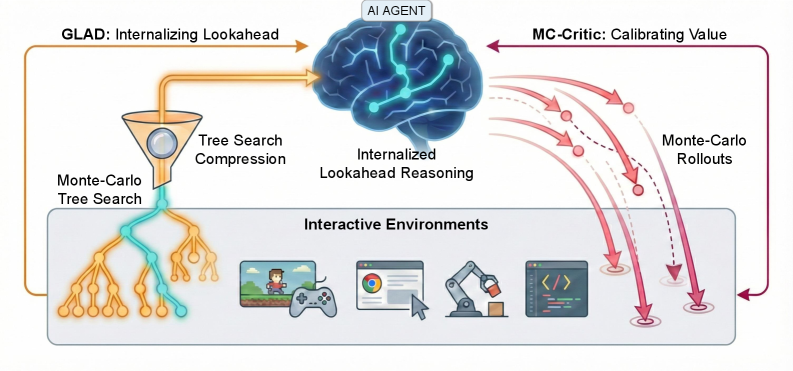
В статье представлена платформа ProAct, сочетающая в себе возможности больших языковых моделей и методы обучения с подкреплением для улучшения планирования на большие горизонты.
Существующие языковые модели, действующие как агенты, испытывают трудности в интерактивных средах, требующих долгосрочного планирования из-за накопления ошибок при прогнозировании будущих состояний. В работе ‘ProAct: Agentic Lookahead in Interactive Environments’ предложен фреймворк ProAct, позволяющий агентам усваивать точное предвидение за счет двухэтапного обучения, включающего дистилляцию с опорой на поиск в среде и Monte-Carlo критик для стабилизации обучения с подкреплением. Эксперименты в стохастических и детерминированных средах показали, что ProAct значительно повышает точность планирования, позволяя модели с 4B параметрами превосходить существующие open-source решения и конкурировать с state-of-the-art closed-source моделями. Сможет ли данный подход открыть новые горизонты в создании интеллектуальных агентов, способных эффективно действовать в сложных, динамичных средах?
Пределы Интуиции: LLM и Последовательное Принятие Решений
Несмотря на впечатляющую способность больших языковых моделей (БЯМ) распознавать закономерности и корреляции в данных, они часто демонстрируют ограниченные возможности в решении сложных задач, требующих последовательного принятия решений и планирования. БЯМ преуспевают в анализе статических данных и прогнозировании на основе прошлых наблюдений, однако, когда речь заходит о динамичных средах, где каждое действие влечет за собой долгосрочные последствия, их производительность заметно снижается. Это связано с тем, что БЯМ, в первую очередь, оперируют вероятностями и статистическими связями, а не глубоким пониманием причинно-следственных связей и способностью к стратегическому предвидению, что критически важно для успешного планирования и адаптации к меняющимся обстоятельствам.
Традиционные подходы к обучению языковых моделей, основанные на увеличении объемов данных, часто оказываются недостаточными для обеспечения надежного рассуждения в меняющихся условиях. Хотя увеличение масштаба обучения и позволяет моделям лучше распознавать закономерности в данных, это не гарантирует способности к последовательному принятию решений и прогнозированию последствий действий. Исследования показывают, что простого увеличения объема данных недостаточно для формирования у моделей способности адаптироваться к новым, непредсказуемым ситуациям и эффективно планировать действия на долгосрочную перспективу. Ограничения связаны с тем, что модели, обученные на больших объемах данных, часто демонстрируют поверхностное понимание причинно-следственных связей и не способны к гибкому применению знаний в динамичных средах, требующих стратегического планирования и адаптации.
Недостаток способности больших языковых моделей (LLM) к последовательному принятию решений обусловлен отсутствием в их архитектуре механизмов, позволяющих явно предвидеть последствия действий и оценивать долгосрочные результаты. В отличие от человека, способного мысленно моделировать различные сценарии развития событий, LLM оперируют преимущественно на основе статистических закономерностей, выученных из огромных объемов данных. Это приводит к тому, что модель зачастую не способна адекватно оценить, как текущее действие повлияет на будущую ситуацию, особенно в динамичной и непредсказуемой среде. В результате, LLM испытывают трудности при решении задач, требующих планирования, стратегического мышления и учета отложенных во времени последствий, что ограничивает их применение в областях, где важна способность к долгосрочному прогнозированию и принятию обоснованных решений.
ProAct: Внедрение Дальновидного Рассуждения в LLM
ProAct решает проблему отсутствия явного планирования в больших языковых моделях (LLM) посредством расширения их возможностей многошагового прогнозирования. В отличие от традиционных LLM, которые генерируют ответы последовательно, основываясь на текущем состоянии, ProAct позволяет агенту моделировать несколько будущих ходов и оценивать их потенциальные последствия. Это достигается за счет реализации механизма “lookahead”, который позволяет агенту предвидеть развитие событий на несколько шагов вперед и выбирать действия, максимизирующие вероятность достижения желаемой цели. Такой подход обеспечивает более стратегическое поведение и позволяет агенту успешно решать задачи, требующие долгосрочного планирования и предвидения.
ProAct использует алгоритмы поиска, в частности, метод Монте-Карло с деревом поиска (MCTS), для исследования возможных будущих траекторий развития событий. MCTS позволяет агенту моделировать множество сценариев, расширяя дерево поиска на каждом шаге путем случайной выборки действий и оценки полученных результатов. Этот процесс позволяет оценить перспективность различных стратегий, выбирая наиболее оптимальные действия на основе статистической информации, полученной в ходе симуляций. Применение MCTS позволяет ProAct эффективно исследовать пространство состояний и планировать действия на несколько шагов вперед, что критически важно для решения задач с долгосрочным планированием.
В ходе тестирования на длинных игровых сценариях ProAct демонстрирует передовые результаты, превосходя показатели всех доступных открытых моделей. В частности, агент достигает более высокой оценки и стабильности в сложных игровых средах, требующих планирования на несколько ходов вперед. Сравнение с существующими open-source решениями показывает значительное улучшение метрик, таких как средняя награда за эпизод и процент успешно завершенных игр, что подтверждает эффективность подхода ProAct к долгосрочному планированию и принятию решений.
Проект ProAct позволяет агентам на базе больших языковых моделей (LLM) демонстрировать значительно более высокий уровень стратегического мышления за счет явного представления и анализа возможных будущих состояний. В отличие от традиционных LLM, полагающихся на предсказание следующего токена, ProAct использует механизм планирования, что позволяет агенту оценивать последствия своих действий на несколько шагов вперед. Достигнутые результаты демонстрируют сопоставимую производительность с закрытыми моделями, используя при этом модель с 4 миллиардами параметров, что подтверждает эффективность подхода к расширению возможностей LLM за счет планирования и моделирования будущих состояний.
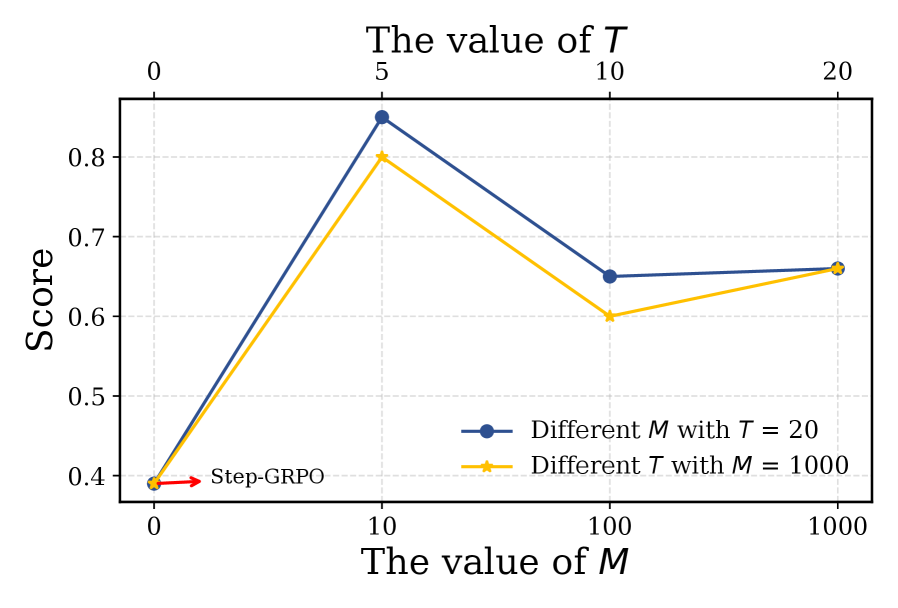
GLAD: Сжатие Поиска в Явные Цепочки Рассуждений
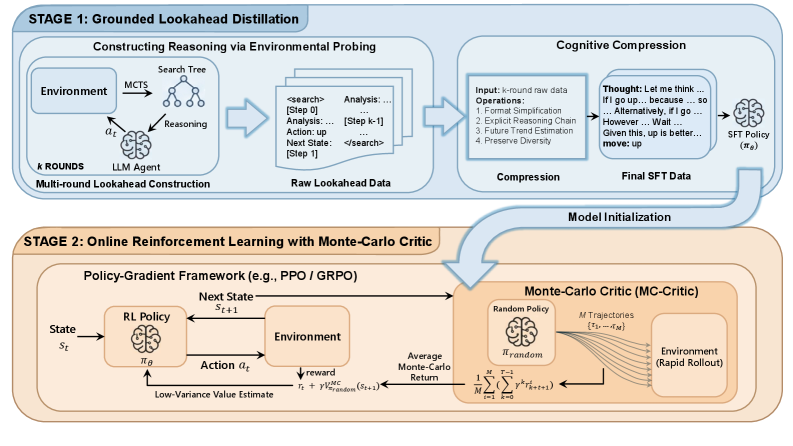
Метод GLAD представляет собой новый подход к интернализации динамики среды посредством сжатия траекторий, полученных в результате поиска на основе Monte Carlo Tree Search (MCTS), в явные цепочки рассуждений (Reasoning Chains). Вместо непосредственного использования результатов поиска, GLAD преобразует последовательность действий и состояний, сгенерированных MCTS, в структурированную последовательность логических шагов, которые могут быть обработаны и использованы языковой моделью. Это позволяет агенту не просто воспроизводить успешные траектории, но и понимать причинно-следственные связи в среде, что способствует обобщению и адаптации к новым ситуациям. Такое сжатие обеспечивает более компактное представление опыта и позволяет языковой модели эффективнее использовать накопленные знания.
Сжатие траекторий поиска, генерируемых методом Monte Carlo Tree Search (MCTS), достигается посредством контролируемой тонкой настройки (Supervised Fine-Tuning) большой языковой модели (LLM). В процессе тонкой настройки LLM обучается предсказывать последовательность действий и соответствующие результаты, основываясь на данных, полученных в ходе процесса поиска. В качестве обучающих данных используются пары “состояние — действие — результат”, извлеченные из траекторий MCTS. Это позволяет LLM интернализировать динамику окружающей среды и эффективно воспроизводить логику принятия решений, демонстрируемую алгоритмом поиска, что приводит к повышению производительности и обобщающей способности агента.
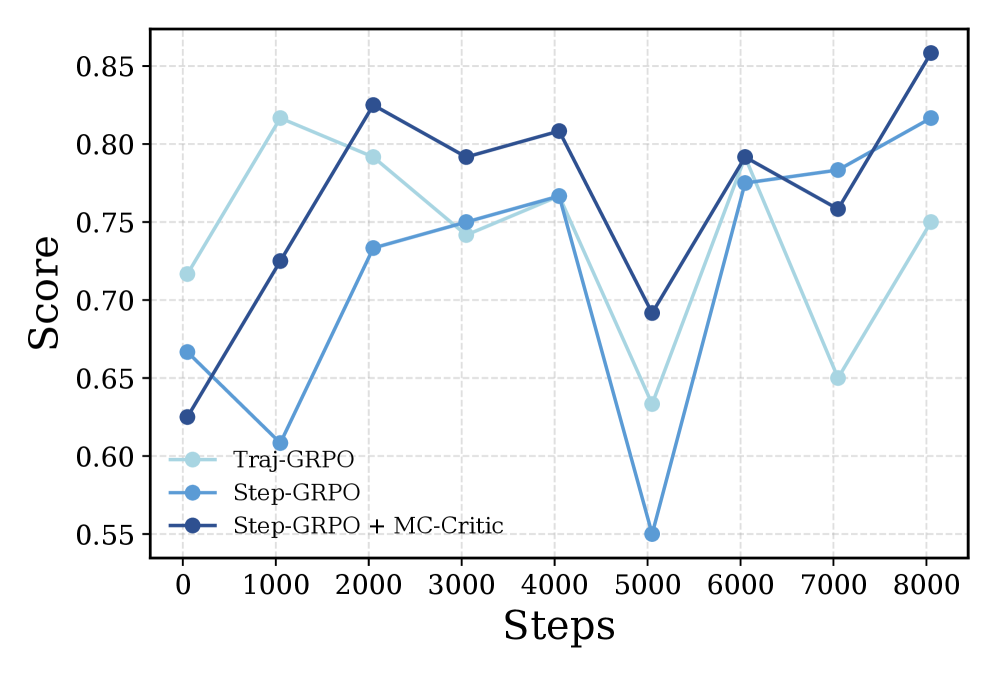
В ходе тестирования на бенчмарке 2048, GLAD продемонстрировал высокую способность к обобщению на ранее не встречавшихся конфигурациях игрового поля. В сравнительных тестах GLAD превзошел производительность открытых альтернативных решений (open-source baselines), показывая более стабильные и эффективные стратегии решения задачи. Это свидетельствует о том, что метод позволяет агенту успешно адаптироваться к новым условиям, не требуя дополнительного обучения или настройки для каждой конкретной конфигурации.
Метод GLAD использует MC-Critic (Monte Carlo Critic) для получения оценок функции ценности с низкой дисперсией. Традиционные методы оценки функции ценности, такие как временные различия (TD), могут страдать от высокой дисперсии, что приводит к нестабильному обучению. MC-Critic использует выборки из траекторий Монте-Карло для вычисления функции ценности, что обеспечивает более надежные и точные оценки. Снижение дисперсии в оценке функции ценности приводит к улучшению сигнала обучения, позволяя агенту быстрее и эффективнее осваивать оптимальную стратегию в среде. Это, в свою очередь, положительно сказывается на общей производительности агента, особенно в сложных и динамичных условиях.

За Пределами Планирования: Влияние на Надёжных и Интерпретируемых Агентов
В основе GLAD лежит принципиально новый подход к принятию решений, заключающийся в формировании чётких и прозрачных цепочек рассуждений. В отличие от большинства LLM-агентов, чьи действия часто кажутся непрозрачными и труднообъяснимыми, GLAD предоставляет возможность проследить логику, приведшую к конкретному выбору. Каждый шаг в процессе принятия решения сопровождается явным обоснованием, что позволяет не только понять, почему агент поступил именно так, но и выявить потенциальные ошибки или предвзятости в его рассуждениях. Эта способность к интерпретации открывает новые возможности для отладки, улучшения и сертификации LLM-агентов, особенно в критически важных областях, где необходима высокая степень надежности и ответственности.
Прозрачность, обеспечиваемая чёткой логикой принятия решений, имеет решающее значение для формирования доверия к системам искусственного интеллекта, особенно в критически важных областях, таких как робототехника и здравоохранение. В этих сферах понимание почему система пришла к определенному выводу не менее важно, чем сам результат. В робототехнике, например, прозрачность позволяет предвидеть и корректировать действия робота, обеспечивая безопасность взаимодействия с человеком. В медицине — это возможность для врачей оценить обоснованность диагностических или терапевтических рекомендаций, что необходимо для принятия ответственных решений, касающихся здоровья пациентов. Отсутствие такой прозрачности может привести к недоверию и, как следствие, к отказу от использования потенциально полезных технологий, даже если они демонстрируют высокую эффективность.
Рассмотренная архитектура GLAD демонстрирует способность к эффективной компрессии информации, получаемой в процессе поиска решений. Этот механизм позволяет значительно сократить объем данных, необходимых для обучения агента с подкреплением, что открывает возможности для масштабирования обучения на более сложные задачи и в условиях ограниченных вычислительных ресурсов. Вместо обработки огромного количества промежуточных результатов, система концентрируется на наиболее релевантной информации, тем самым ускоряя процесс обучения и повышая эффективность алгоритмов. Подобный подход позволяет создавать более компактные и быстрые модели, способные адаптироваться к новым условиям и решать задачи в реальном времени, что особенно важно для приложений в робототехнике и автономных системах.
Разработка GLAD знаменует собой важный прорыв в создании агентов на базе больших языковых моделей, которые отличаются не только интеллектом, но и понятностью и надёжностью. В отличие от традиционных “черных ящиков”, где процесс принятия решений остаётся непрозрачным, GLAD стремится к созданию агентов, способных обосновать свои действия и продемонстрировать логику, лежащую в основе выбора. Такая прозрачность критически важна для применения в областях, требующих высокой степени ответственности, таких как робототехника и здравоохранение, где понимание причинно-следственных связей является обязательным условием для доверия и эффективного взаимодействия. Таким образом, GLAD открывает перспективы для создания интеллектуальных систем, которые не просто выполняют задачи, но и позволяют человеку понять, как и почему они это делают, повышая уровень контроля и уверенности в их работе.
Исследование представляет собой очередную попытку приручить непредсказуемость больших языковых моделей. ProAct, с его внутренним прогнозированием и стабилизацией обучения с подкреплением, выглядит элегантно на бумаге. Однако, как показывает опыт, любая система, стремящаяся к долгосрочному планированию, неизбежно сталкивается с хаосом реального мира. Карл Фридрих Гаусс однажды заметил: «Если бы я должен был выбирать между предсказанием и объяснением, я бы выбрал объяснение». В данном случае, ProAct пытается предсказать последствия действий, но истинная ценность, вероятно, кроется в способности объяснить, почему агент принял то или иное решение, особенно когда всё пошло не по плану. Неизбежно, найдётся способ сломать эту «элегантную теорию» под нагрузкой.
Куда Ведет Эта Дорога?
Представленная работа, несомненно, добавляет ещё один слой сложности в и без того перегруженную архитектуру «разумных» агентов. Внедрение «взгляда вперед» и стабилизация обучения с помощью Монте-Карло критика — это, скорее, изящный способ замаскировать фундаментальную проблему: долгосрочное планирование в интерактивной среде неизбежно сталкивается с экспоненциальным ростом неопределенности. Каждый «прогресс» в этой области — это лишь отсрочка неизбежного столкновения с реальностью, где энтропия всегда побеждает.
Будущие исследования, вероятно, сконцентрируются на ещё более изощренных методах аппроксимации ценности и снижении вычислительных затрат. Однако, стоит задаться вопросом: не является ли эта гонка за эффективностью лишь попыткой отполировать алгоритм, который изначально не способен понять суть происходящего? Возможно, настало время признать, что нам не нужно больше микросервисов — нам нужно меньше иллюзий о том, что мы можем предсказать будущее.
В конечном счете, «разумные» агенты останутся лишь сложными автоматами, реагирующими на входные данные. И, как показывает история, каждая «революционная» технология завтра станет техдолгом. Прод всегда найдёт способ сломать элегантную теорию. Эта работа — ещё один кирпичик в фундаменте, который, вероятно, рано или поздно обрушится под тяжестью практической реализации.
Оригинал статьи: https://arxiv.org/pdf/2602.05327.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Поймать Мгновение: Эволюция Детекторов Времени
- Мгновенная расшифровка: Voxtral Realtime на службе у скорости
2026-02-06 16:17