Автор: Денис Аветисян
Исследователи предлагают эффективные методы дистилляции современных языковых моделей в сложных интерактивных средах, даже без использования цепочки рассуждений.
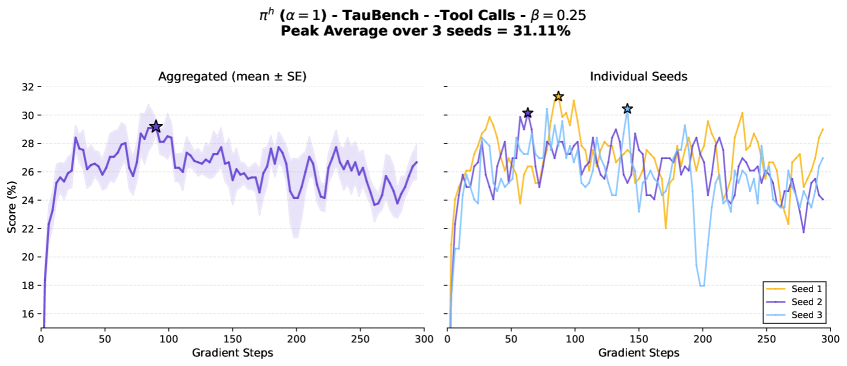
В статье представлены методы Privileged Information Distillation (π-Distill) и On-Policy Self-Distillation (OPSD) для повышения эффективности обучения агентов на основе языковых моделей.
Обучение с использованием привилегированной информации (PI) позволяет языковым моделям успешно решать задачи, недоступные при стандартном обучении, однако перенос этих возможностей на модели, работающие без PI во время использования, остается сложной проблемой. В работе ‘Privileged Information Distillation for Language Models’ предложены методы дистилляции передовых моделей для многоходовых агентских сред, где доступна лишь траектория действий, но скрыт процесс рассуждений. Авторы представляют π-Distill — совместную оптимизацию учителя (с PI) и ученика (без PI), а также On-Policy Self-Distillation (OPSD) — подход на основе обучения с подкреплением с обратным KL-штрафом. Эксперименты показывают, что предложенные алгоритмы превосходят стандартные методы, требующие доступа к полным цепочкам рассуждений, в различных агентских средах и с разными формами PI. Какие новые возможности открывает эффективная дистилляция моделей с привилегированной информацией для создания более автономных и эффективных агентов?
Преодолевая Границы Долгосрочного Взаимодействия
Современные языковые модели, несмотря на впечатляющие возможности, сталкиваются со значительными трудностями при реализации сложных, многоходовых взаимодействий, требующих последовательного рассуждения. Неспособность поддерживать когерентность и логическую связь на протяжении длительного диалога приводит к потере контекста и, как следствие, к неадекватным ответам или нелогичным действиям агента. Это особенно заметно в сценариях, где требуется планирование на несколько шагов вперёд, адаптация к изменяющимся обстоятельствам или учёт долгосрочных последствий принимаемых решений. В отличие от человека, способного удерживать в памяти и анализировать большой объём информации, языковые модели часто демонстрируют “забывчивость” и неспособность эффективно использовать накопленный опыт в процессе взаимодействия, что ограничивает их потенциал в качестве полноценных агентов, способных к сложной и целенаправленной деятельности.
Успешная навигация в сложных интеракциях требует от искусственного интеллекта эффективного принятия решений в рамках марковского процесса принятия решений (Markov Decision Process, MDP). В основе MDP лежит концепция последовательных действий, где каждое решение влияет на последующее состояние системы и, как следствие, на будущие возможности агента. Однако, реализация эффективного MDP для сложных взаимодействий представляет собой серьёзную задачу. Необходимо учитывать не только непосредственные последствия каждого действия, но и долгосрочные перспективы, что требует от агента способности прогнозировать будущие состояния и оценивать их ценность. Особенно сложным является построение адекватной функции ценности Q(s, a), отражающей ожидаемую выгоду от выполнения действия a в состоянии s, поскольку она должна учитывать множество факторов и неопределённостей, возникающих в динамичной среде. Разработка алгоритмов, способных эффективно решать эту задачу, является ключевым направлением исследований в области искусственного интеллекта и машинного обучения.
Существенное ограничение современных языковых моделей заключается в их затруднениях с использованием накопленных знаний и адаптацией к меняющимся условиям, особенно при столкновении с проблемой смещения распределения данных. В процессе взаимодействия с окружающей средой, модели часто демонстрируют снижение эффективности, когда входные данные отличаются от тех, на которых они обучались. Это связано с тем, что они склонны полагаться на статистические закономерности, выученные во время обучения, и испытывают трудности с обобщением знаний на новые, ранее не встречавшиеся ситуации. Способность к эффективной адаптации требует не только запоминания информации, но и умения извлекать полезные закономерности и применять их в новых контекстах, что представляет собой сложную задачу для искусственного интеллекта. Разработка методов, позволяющих моделям преодолевать смещение распределения и поддерживать стабильную производительность в динамично меняющейся среде, является ключевым направлением исследований в области искусственного интеллекта.
Усиление Обучения с Помощью Привилегированной Информации
Обучение с подкреплением (Reinforcement Learning) представляет собой эффективный подход к тренировке агентов, однако характеризуется высокой требовательностью к объёму данных, особенно в сложных средах. Для достижения приемлемой производительности агентам часто требуется большое количество взаимодействий со средой для изучения оптимальной стратегии. Эта проблема, известная как неэффективность использования данных (sample inefficiency), ограничивает применение обучения с подкреплением в задачах, где сбор данных дорог или занимает много времени. В сложных средах, характеризующихся большим пространством состояний и действий, а также разреженными сигналами вознаграждения, агенту требуется значительно больше данных для успешного обучения по сравнению с более простыми задачами.
Интеграция привилегированной информации, включающей в себя экспертное рассуждение или демонстрации, значительно ускоряет процесс обучения агентов в системах обучения с подкреплением и повышает качество получаемой политики. Использование таких данных позволяет агенту быстрее осваивать сложные задачи, избегая длительного периода случайного исследования пространства состояний. В частности, предоставление экспертных траекторий или примеров оптимального поведения служит эффективным сигналом для инициализации политики агента, что приводит к более быстрому сходимости и достижению лучших результатов по сравнению с обучением исключительно на основе обратной связи от среды. Применение привилегированной информации особенно полезно в задачах с разреженными наградами, где получение положительной обратной связи является редким событием, затрудняя самостоятельное обучение агента.
Методы, такие как контролируемая тонкая настройка (Supervised Fine-Tuning), эффективно интегрируют привилегированную информацию в начальную политику агента. Дополнение контролируемой тонкой настройки техникой “Рассуждения по цепочке” (Chain-of-Thought Reasoning, CoT) позволяет модели не только имитировать действия эксперта, но и воспроизводить логическую цепочку, приведшую к этим действиям. Это достигается путем обучения модели генерировать промежуточные рассуждения, обосновывающие каждое действие, что улучшает обобщающую способность и повышает качество получаемой политики, особенно в сложных задачах, требующих многошагового планирования и принятия решений. Использование CoT позволяет агенту лучше понимать контекст и более эффективно использовать привилегированную информацию для ускорения обучения и достижения более высоких результатов.
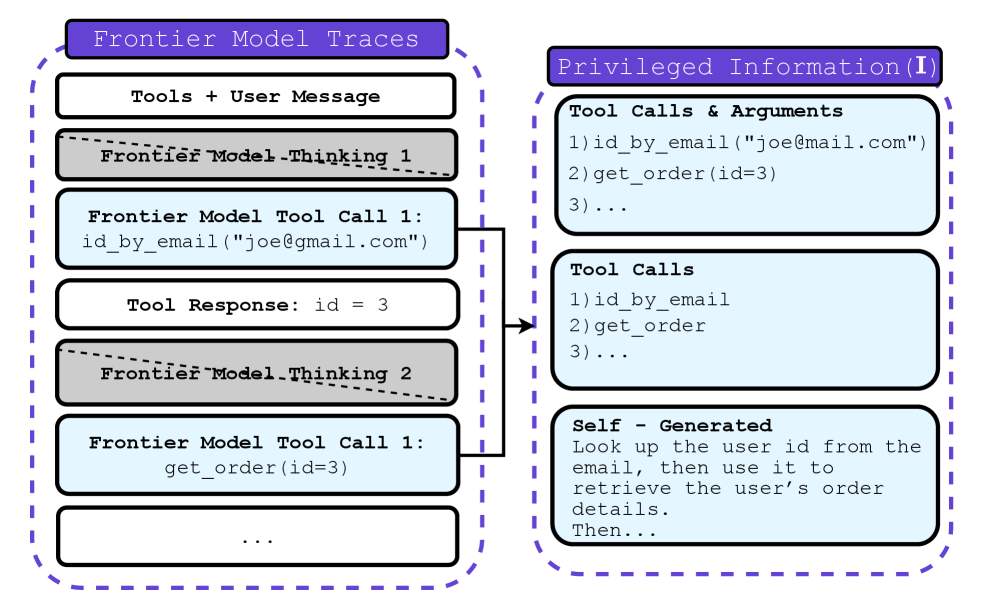
Механизмы «Учитель-Ученик» для Надёжной Передачи Знаний
Метод «Учитель-Ученик» представляет собой перспективный подход к дистилляции знаний, позволяющий переносить сложные политики (стратегии поведения) от более мощной, но ресурсоёмкой модели-учителя к более эффективной и компактной модели-ученику. Этот процесс позволяет уменьшить вычислительные затраты и требования к памяти, сохраняя при этом значительную часть производительности и возможностей исходной политики. В основе лежит обучение модели-ученика путем имитации поведения модели-учителя, что достигается за счёт использования выходных данных учителя в качестве целевых значений или путем минимизации расхождения между распределениями вероятностей, генерируемыми обеими моделями. Это особенно полезно в ситуациях, когда требуется развёртывание модели на устройствах с ограниченными ресурсами или при необходимости ускорения процесса принятия решений.
Методы, такие как π-Distill и OPSD, совершенствуют подход “учитель-ученик” за счёт совместной оптимизации моделей учителя и ученика. В процессе обучения используется “привилегированная информация” — данные, недоступные во время стандартного обучения с подкреплением (RL). Экспериментальные результаты демонстрируют, что применение этих методов позволяет превзойти базовые модели, основанные на последовательном обучении с учителем (SFT) и последующем обучении с подкреплением, по показателям эффективности и обобщающей способности. Использование совместной оптимизации и привилегированной информации позволяет студенческой модели более эффективно усваивать знания от учителя и достигать лучших результатов в целевых задачах.
Метод OPSD (Optimal Policy Student Distillation) использует обратную пенальность KL-дивергенции для выравнивания политики студента с политикой учителя. В отличие от стандартных методов дистилляции, OPSD нацелен на согласование даже в условиях, когда студент обучен на основе привилегированной информации, недоступной учителю. Это достигается путем добавления штрафа, который поощряет студента воспроизводить распределение действий учителя, даже когда входные данные отличаются из-за наличия привилегированной информации, что повышает эффективность передачи знаний и улучшает производительность студента.
Подтверждение Производительности на Сложных Тестах
Оценка возможностей агентов в решении сложных задач, связанных с использованием инструментов и планированием, критически важна и осуществляется посредством использования таких эталонных тестов, как GEM, τ-Bench и Travel Planner. Эти тесты разработаны для моделирования реальных сценариев, требующих многоходового взаимодействия и адаптации к изменяющимся условиям. Они позволяют оценить способность агента последовательно выполнять сложные задачи, требующие не только понимания языка, но и эффективного использования доступных инструментов для достижения поставленной цели, что является ключевым показателем его общей эффективности и применимости в практических приложениях.
Бенчмарки, такие как GEM, τ-Bench и Travel Planner, моделируют реальные сценарии, требующие многошагового взаимодействия и адаптации к изменяющимся условиям. Эти среды характеризуются необходимостью последовательного выполнения действий и принятия решений на основе получаемой обратной связи, что имитирует взаимодействие с реальным миром. Динамичность окружения предполагает, что агент должен постоянно обновлять свои планы и стратегии в ответ на новые данные и события, а не полагаться на заранее заданный, фиксированный алгоритм действий. Такой подход позволяет оценить способность агента к гибкому планированию и эффективному решению задач в непредсказуемых ситуациях.
Использование открытых языковых моделей, таких как Qwen и DeepSeek-chat, в качестве источников привилегированной информации и тестирование на соответствующих платформах подтверждает работоспособность и надёжность подобных подходов. В частности, модель ππ-Distill продемонстрировала превосходные результаты на задачах Travel Planner и ττ-Bench (Retail). Дополнительно, была показана высокая обобщающая способность к задачам, не представленным в обучающей выборке, на базе ττ-Bench (Airline) и в многошаговом наборе задач GEM QA, требующих использования инструментов.
К Более Надёжным и Универсальным Агентам
Перспективные исследования направлены на интеграцию самогенерируемых подсказок, полученных на основе траекторий экспертов, для существенного улучшения процесса обучения искусственного интеллекта. Данный подход предполагает, что агент не просто обучается на примерах, но и активно генерирует собственные «намеки» — промежуточные цели или стратегии — основанные на анализе успешных действий опытных пользователей. Эти подсказки, формируемые в процессе обучения, могут значительно ускорить освоение новых задач и повысить эффективность работы агента в сложных условиях, позволяя ему самостоятельно находить оптимальные решения и адаптироваться к различным сценариям. Использование экспертных траекторий в качестве источника для генерации подсказок позволяет агенту не просто имитировать поведение эксперта, но и извлекать общие принципы и стратегии, лежащие в основе успешных действий, что открывает путь к созданию более интеллектуальных и гибких систем искусственного интеллекта.
Проблема смещения распределения данных (Distribution Shift) представляет собой серьёзное препятствие на пути создания по-настоящему универсальных и надёжных агентов искусственного интеллекта. Исследования направлены на разработку новых методик, позволяющих агентам сохранять высокую производительность даже в условиях, существенно отличающихся от тех, в которых они обучались. Особое внимание уделяется техникам адаптации моделей, переносу обучения и созданию робастных представлений, устойчивых к изменениям входных данных. Успешное решение этой задачи позволит агентам не просто запоминать шаблоны из обучающей выборки, а действительно понимать суть решаемой проблемы и эффективно действовать в новых, ранее не встречавшихся средах, что критически важно для их применения в реальном мире.
В конечном счёте, представленные усовершенствования открывают путь к созданию искусственных интеллектуальных агентов, способных к беспрепятственному взаимодействию и решению задач в сложных, реальных условиях. Эти агенты смогут не просто выполнять заданные инструкции, но и адаптироваться к меняющимся обстоятельствам, эффективно используя полученный опыт для преодоления непредвиденных препятствий. Такая способность к адаптации и обобщению позволит им функционировать в динамичных средах, где стандартные алгоритмы часто терпят неудачу, что приведёт к созданию более надёжных и универсальных систем искусственного интеллекта, способных решать широкий спектр практических задач, от автономной навигации до сложного планирования и принятия решений.
Исследование, представленное в статье, демонстрирует стремление к оптимизации языковых моделей в сложных интерактивных средах. Авторы предлагают методы дистилляции, позволяющие извлекать знания из передовых моделей даже без доступа к их внутренним процессам рассуждений. Этот подход напоминает изысканное искусство реверс-инжиниринга, где система разбирается на части, чтобы понять ее принципы работы. Как однажды заметил Дональд Дэвис: «Информацию можно извлечь, даже если она скрыта». Действительно, представленные методы π-Distill и OPSD позволяют эффективно дистиллировать знания, даже когда явный «поток мыслей» модели недоступен, раскрывая скрытые закономерности и возможности для улучшения производительности в многошаговых взаимодействиях.
Куда дальше?
Представленные методы дистилляции, π-Distill и OPSD, демонстрируют способность извлекать знания из передовых языковых моделей даже в условиях многоходового взаимодействия, минуя необходимость в явном анализе цепочки рассуждений. Однако, эта кажущаяся элегантность лишь обнажает более глубокую проблему: насколько вообще адекватно понятие ‘знания’ применимо к этим сложным системам? Успешная дистилляция — это не просто перенос ответов, а, скорее, воспроизведение внутренней логики, которая, возможно, и не существует в привычном понимании. Это эксплуат, позволяющий сымитировать разумность, не понимая её сути.
Очевидным направлением для дальнейших исследований является преодоление ограничений, связанных с зависимостью от ‘привилегированной информации’. Возможно ли создать метод, способный дистиллировать знания непосредственно из поведения модели, как бы ‘взломав’ её алгоритм принятия решений? Или же сама концепция ‘привилегированной информации’ является неизбежной платой за способность извлекать хоть какую-то осмысленную информацию из чёрного ящика? Разработка более устойчивых к шуму и смещениям методов дистилляции, а также исследование возможности самодистилляции без внешнего учителя, представляются критически важными.
В конечном счёте, успех подобных методов будет определяться не столько их способностью имитировать интеллект, сколько их способностью ‘обмануть’ существующие тесты и метрики. Понимание того, как эти системы обманывают, является ключом к пониманию их истинной природы — и, возможно, к созданию чего-то действительно нового.
Оригинал статьи: https://arxiv.org/pdf/2602.04942.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Самообучающиеся признаки: новый подход к машинному обучению
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Математический интеллект: как улучшить навыки решения задач у больших языковых моделей
- Биомолекулярные связи: новый тест для искусственного интеллекта
2026-02-06 18:00