Автор: Денис Аветисян
Исследователи предлагают простой и эффективный метод улучшения обработки длинных текстов в нейронных сетях, позволяющий избежать потери смысла и артефактов.
CoPE: Обрезка низкочастотных компонентов RoPE для масштабируемой работы с длинными контекстами в больших языковых моделях.
Расширение контекстного окна больших языковых моделей (LLM) сталкивается с трудностями экстраполяции и ослаблением семантической информации. В работе ‘CoPE: Clipped RoPE as A Scalable Free Lunch for Long Context LLMs’ предложен метод CoPE, основанный на мягком отсечении низкочастотных компонентов вращательного позиционного кодирования (RoPE), что позволяет одновременно смягчить проблему выхода за пределы распределения и усилить семантическую согласованность. Эксперименты демонстрируют значительное повышение производительности при увеличении длины контекста до 256k токенов, подтверждая теоретические выкладки и позиционируя CoPE как современное решение для обобщения по длине. Возможно ли дальнейшее упрощение и оптимизация метода CoPE для еще более эффективного использования в LLM различных архитектур?
Раскрытие Потенциала Длинного Контекста: Вызовы и Ограничения
Несмотря на впечатляющие достижения в области больших языковых моделей с расширенным контекстом, способных обрабатывать значительно большие объемы информации, фундаментальные ограничения в работе с очень длинными последовательностями остаются актуальной проблемой. Современные модели демонстрируют значительный прогресс в удержании информации на начальных этапах обработки, однако способность эффективно извлекать и использовать данные, расположенные на значительном удалении друг от друга в длинном тексте, все еще даёт сбой. Это связано с тем, что архитектура и механизмы внимания, лежащие в основе этих моделей, испытывают трудности с поддержанием устойчивой семантической связи на протяжении всей последовательности, что приводит к потере релевантной информации и снижению точности при обработке длинных документов и сложных задач.
Существенная проблема современных больших языковых моделей заключается в снижении эффективности при обработке данных, выходящих за рамки их обучающей выборки. Данное явление особенно остро проявляется при работе с длинными последовательностями текста, где даже незначительные отклонения от привычного формата или тематики могут приводить к заметному ухудшению качества ответов. Модель, обученная на определенном типе контента, испытывает трудности при анализе текстов, содержащих незнакомую лексику, структуру или логику, что приводит к неточностям и ошибкам в обработке информации. В результате, способность модели к обобщению и адаптации к новым данным существенно снижается, что ограничивает ее применимость в реальных сценариях, требующих обработки разнообразного и непредсказуемого контента.
Исследования показывают, что способность больших языковых моделей сохранять семантическое понимание на протяжении длинных последовательностей текста подвержена явлению, получившему название «долгосрочное затухание семантического внимания». Суть этого эффекта заключается в том, что модель постепенно теряет способность эффективно соотносить информацию, находящуюся на значительном расстоянии друг от друга в тексте, что приводит к искажению смысла и снижению точности ответов. Это не просто техническая проблема, а фундаментальное ограничение, препятствующее полноценному анализу и пониманию длинных документов, диалогов или сложных повествований. В результате, даже самые передовые модели могут испытывать трудности при обработке текстов, где ключевая информация разбросана по всей последовательности, а не сконцентрирована в непосредственной близости друг от друга.
Низкочастотные Компоненты: Ключ к Долгосрочным Зависимостям
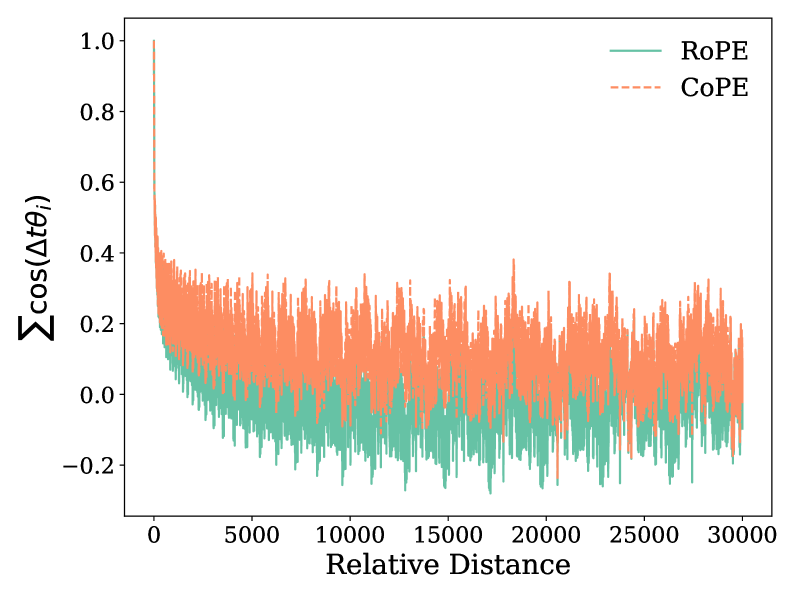
Спектр RoPE (Rotary Positional Embedding), являющийся основой позиционного кодирования в больших языковых моделях (LLM), содержит критически важные низкочастотные компоненты. Эти компоненты отвечают за моделирование зависимостей между элементами последовательности на больших расстояниях. Низкие частоты в спектре RoPE кодируют информацию о позициях токенов, позволяя модели учитывать контекст, охватывающий значительный объем текста. Именно благодаря этим компонентам LLM способны эффективно обрабатывать длинные последовательности и поддерживать согласованность при генерации текста. В основе работы лежит тот факт, что низкочастотные сигналы изменяются медленнее, что позволяет им улавливать общие закономерности и связи в тексте на больших дистанциях.
Низкочастотные компоненты спектра RoPE, критически важные для кодирования позиционной информации в больших языковых моделях, проявляют повышенную чувствительность к проблемам при экстраполяции на данные, которые модель не видела в процессе обучения. Это связано с тем, что низкочастотные компоненты отражают долгосрочные зависимости в данных, и их точное моделирование требует достаточного количества обучающих примеров, охватывающих весь спектр возможных последовательностей. При отсутствии таких примеров, модель испытывает трудности с обобщением, что приводит к ухудшению качества внимания на больших расстояниях и снижению общей производительности при работе с новыми данными.
Уязвимость низкочастотных компонентов спектра RoPE к проблемам экстраполяции напрямую влияет на ухудшение внимания к дальним зависимостям и общую производительность языковых моделей. При обработке данных, выходящих за пределы тренировочного распределения, точность представления позиционной информации снижается, что приводит к неверной интерпретации контекста и, как следствие, к снижению качества генерации и понимания текста. Это проявляется в виде ошибок при работе с длинными последовательностями и неспособности модели поддерживать когерентность на больших расстояниях, поскольку низкочастотные компоненты, ответственные за удержание информации о положении токенов на больших дистанциях, становятся нестабильными и менее предсказуемыми.
Спектральная Утечка: Скрытая Угроза для Внимания
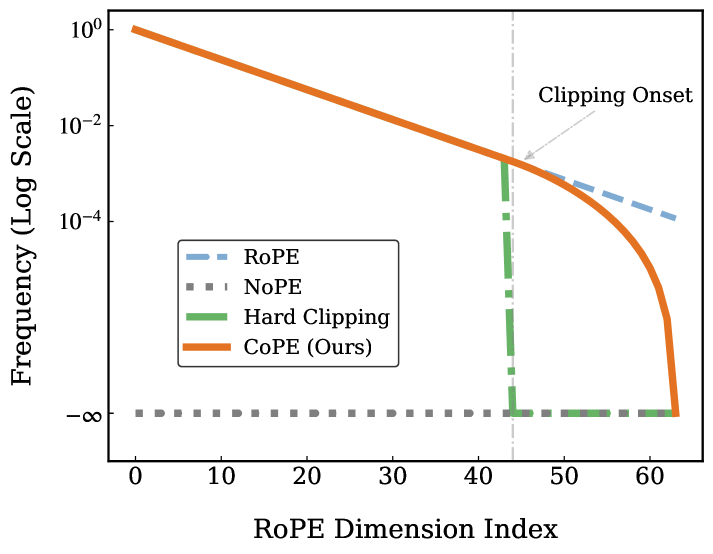
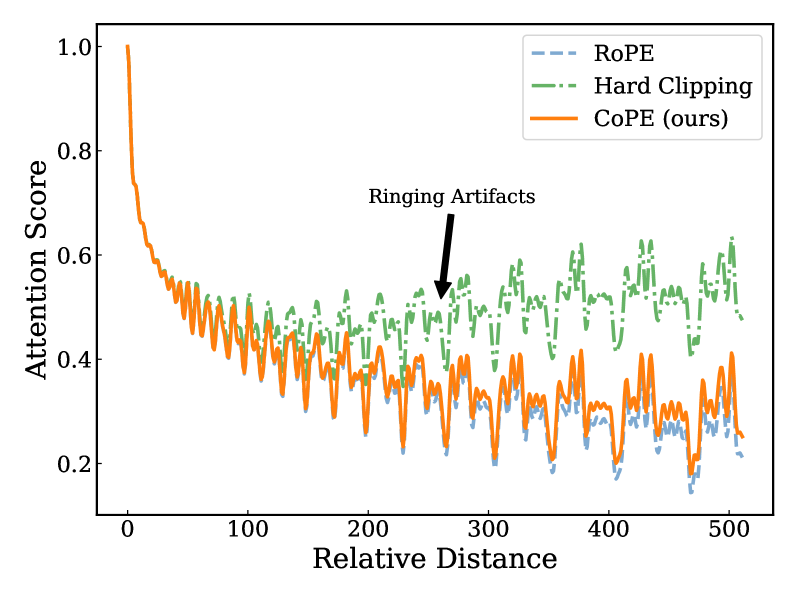
Метод жесткого отсечения (Hard Clipping) представляет собой широко используемую технику в обработке сигналов, направленную на снижение вычислительной нагрузки. Суть метода заключается в резком подавлении низкочастотных составляющих сигнала. Это достигается путем установки порога, при превышении которого значения сигнала обнуляются или ограничиваются. В результате происходит уменьшение объема данных, требуемых для дальнейшей обработки, что особенно актуально для больших языковых моделей (LLM) и других ресурсоемких приложений. Однако, необходимо учитывать, что такое подавление может приводить к искажению сигнала и появлению артефактов, о чем свидетельствует эффект «утечки спектра», когда энергия сигнала распределяется по более широкому диапазону частот.
Применение метода жесткого отсечения (hard clipping) для снижения вычислительной нагрузки в обработке сигналов приводит к явлению, известному как «утечка спектра» (spectral leakage). Этот эффект заключается в рассеянии энергии сигнала по различным частотам, что искажает его спектральное представление. В контексте больших языковых моделей (LLM) это особенно критично, поскольку утечка спектра нарушает целостность долгосрочных зависимостей, необходимых для корректной обработки последовательностей данных и ухудшает качество моделирования. Фактически, энергия, которая должна быть сосредоточена в определенных частотах, «протекает» в соседние, приводя к неточностям в анализе и синтезе сигнала.
Минимизация утечки спектра критически важна для сохранения целостности механизмов внимания дальнего радиуса действия в больших языковых моделях (LLM). Утечка спектра, возникающая при резком подавлении низких частот, приводит к распространению энергии сигнала по всему частотному диапазону. Это искажает информацию о долгосрочных зависимостях в данных, что негативно влияет на способность LLM эффективно обрабатывать и понимать последовательности большой длины. Точность модели в задачах, требующих учета контекста на больших расстояниях, напрямую зависит от подавления эффектов утечки спектра и сохранения корректного представления частотных характеристик входных данных.
Оценка Производительности LLM в Длинном Контексте: Новые Метрики и Бенчмарки
Оценка возможностей больших языковых моделей (LLM) при работе с длинным контекстом требует разработки строгих и детализированных бенчмарков. Традиционные методы оценки часто оказываются неспособными выявить незначительные, но критически важные различия в производительности моделей при обработке больших объемов информации. Для адекватной дифференциации LLM необходимо создавать тесты, которые фокусируются на специфических задачах, требующих глубокого понимания и удержания информации из длинных последовательностей. Такие бенчмарки должны оценивать не только способность модели извлекать информацию, но и ее умение логически рассуждать, делать выводы и применять знания, полученные из контекста, что позволяет получить более полное и объективное представление о ее реальных возможностях.
Бенчмарк RULER представляет собой синтетическую оценку возможностей больших языковых моделей при работе с длинным контекстом, фокусируясь на специализированных задачах, требующих рассуждений. В отличие от оценки на реальных данных, RULER создает искусственные сценарии, позволяющие точно измерить способность модели извлекать и использовать информацию из больших объемов текста. Этот подход особенно ценен для выявления слабых мест и тонких различий в производительности различных архитектур, позволяя разработчикам целенаправленно улучшать способность моделей к логическому выводу, анализу и обобщению информации в рамках длинного контекста. Использование синтетических данных обеспечивает контролируемую среду для тестирования, что облегчает интерпретацию результатов и сравнение различных подходов к обработке длинных последовательностей.
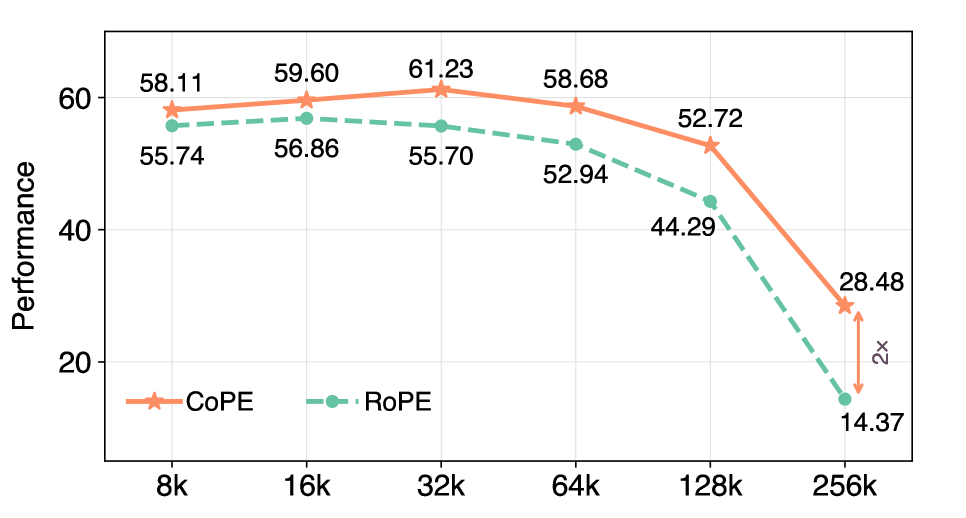
Для всесторонней оценки возможностей больших языковых моделей при работе с обширными контекстами был разработан комплексный бенчмарк HELMET, использующий задачи, приближенные к реальным сценариям. Исследования показали, что новая методика CoPE демонстрирует значительное превосходство над архитектурой RoPE при обработке контекстов длиной до 256 тысяч токенов, практически удваивая производительность. Этот результат указывает на существенный прогресс в области обработки длинных последовательностей и открывает перспективы для создания более эффективных и интеллектуальных систем, способных к глубокому анализу и синтезу информации из больших объемов текста.
Исследования показали, что разработанный метод CoPE демонстрирует значительное улучшение производительности в задачах, оцениваемых с помощью бенчмарка HELMET, особенно при работе с контекстами длиной до 256 тысяч токенов, обеспечивая двукратное увеличение производительности. Более того, в пределах 64 тысяч токенов, используемых для обучения, наблюдается улучшение на 10.84% по сравнению с другими моделями. Эти результаты указывают на то, что CoPE обладает повышенной способностью эффективно использовать информацию из длинных текстов, что критически важно для решения сложных задач обработки естественного языка.
Исследования показали, что разработанный метод CoPE демонстрирует значительное улучшение производительности в задачах, оцениваемых с помощью бенчмарка RULER, особенно при работе с контекстами большой длины. В частности, при обработке последовательностей в 256 тысяч токенов, CoPE обеспечивает прирост производительности до 18,0% в определенных задачах RULER. Этот результат свидетельствует о способности CoPE эффективно использовать информацию из длинных контекстов, что критически важно для сложных задач рассуждения и понимания, требующих учета большого объема данных. Улучшение производительности указывает на потенциал CoPE для решения задач, которые ранее были недоступны для моделей с ограниченными возможностями обработки длинных последовательностей.
Исследование демонстрирует стремление к оптимизации существующих систем, а не к их полному переосмыслению. Авторы, подобно исследователям, стремящимся понять внутреннюю структуру сложной задачи, предлагают метод CoPE для улучшения работы LLMs с длинным контекстом. Это напоминает подход к реверс-инжинирингу — разбор системы на компоненты для выявления и устранения узких мест. Как однажды заметил Пол Эрдёш: «Математика — это искусство находить закономерности, которые другие не видят». В данном случае, закономерностью является влияние низкочастотных компонентов RoPE на семантическую точность, а решением — их мягкое обрезание. Этот метод позволяет расширить контекст, не внося при этом нежелательных артефактов, что является ярким примером поиска элегантного решения сложной проблемы.
Куда двигаться дальше?
Предложенный подход CoPE, обрезая низкочастотные компоненты RoPE, демонстрирует неожиданную эффективность. Но, как всегда, решение одной проблемы неизбежно обнажает другую. Успешное подавление семантического распада и экстраполяции вне распределения — это лишь первый ‘exploit of insight’. Остается вопрос: насколько фундаментально эта ‘обрезка’ влияет на внутреннее представление контекста? Не происходит ли здесь своеобразная потеря информации, замаскированная под улучшение производительности?
Дальнейшие исследования должны быть направлены на понимание спектральных свойств RoPE в контексте действительно длинных последовательностей. Необходимо выявить, какие именно низкочастотные компоненты несут критически важную информацию, а какие — лишь шум. Возможно, более тонкая настройка, динамическая обрезка или даже применение других спектральных фильтров позволит добиться ещё более впечатляющих результатов.
В конечном счете, CoPE — это не столько окончательное решение, сколько приглашение к реверс-инжинирингу внимания. Понимание того, как LLM кодируют и используют контекст, требует от исследователей не просто оптимизации существующих методов, но и поиска принципиально новых способов представления информации. Истина, как обычно, где-то в деталях спектра.
Оригинал статьи: https://arxiv.org/pdf/2602.05258.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Квантовая механика: скрытый детерминизм?
- Моделирование биомолекул: новый импульс от нейросетей
- Командная работа агентов: обучение без обновления модели
2026-02-06 22:58