Автор: Денис Аветисян
Исследователи предлагают инновационный метод предварительного обучения больших языковых моделей, позволяющий значительно сократить время обучения и повысить качество результатов.
Метод Late-to-Early Training (LET) использует знания от меньших моделей для ускорения и улучшения обучения больших языковых моделей.
Несмотря на впечатляющие успехи больших языковых моделей (LLM), их предварительное обучение остается ресурсоемким и замедляет прогресс. В данной работе, озаглавленной ‘Late-to-Early Training: LET LLMs Learn Earlier, So Faster and Better’, предложен новый подход — Late-to-Early Training (LET), позволяющий ускорить обучение LLM за счет использования знаний, полученных от предварительно обученных моделей меньшего размера. Ключевая идея заключается в передаче информации от поздних слоев предварительно обученной модели к ранним слоям обучаемой, что позволяет добиться более быстрой сходимости и повышения производительности в задачах языкового моделирования и последующей тонкой настройки. Может ли парадигма LET стать стандартным методом обучения LLM, обеспечивая эффективное использование вычислительных ресурсов и ускорение развития искусственного интеллекта?
Преодолевая границы масштаба: вызов современным языковым моделям
Современные большие языковые модели (LLM) демонстрируют впечатляющие достижения в обработке естественного языка, однако их колоссальный размер обуславливает значительные вычислительные и ресурсные потребности. Обучение и функционирование таких моделей требует огромных объемов данных и мощнейших вычислительных кластеров, что создает серьезные препятствия для широкого доступа и дальнейшего развития. Каждый новый скачок в количестве параметров влечет за собой экспоненциальный рост необходимых ресурсов, ставя под вопрос устойчивость и экономическую целесообразность дальнейшего увеличения масштаба LLM. В связи с этим, актуальной задачей является поиск эффективных методов обучения и оптимизации, позволяющих добиться сопоставимых результатов при меньших затратах вычислительной мощности и данных.
Традиционные методы предварительного обучения больших языковых моделей (LLM) часто сталкиваются с проблемой неполного использования потенциала огромного числа параметров. По мере увеличения размера модели, прирост производительности от добавления новых параметров постепенно снижается, что приводит к закономерности уменьшающейся отдачи. Это означает, что для достижения незначительного улучшения в качестве работы модели требуется экспоненциально больше вычислительных ресурсов и данных. Неэффективное использование параметров не только увеличивает стоимость обучения, но и ограничивает возможности масштабирования и развития LLM, препятствуя демократизации доступа к передовым технологиям обработки естественного языка.
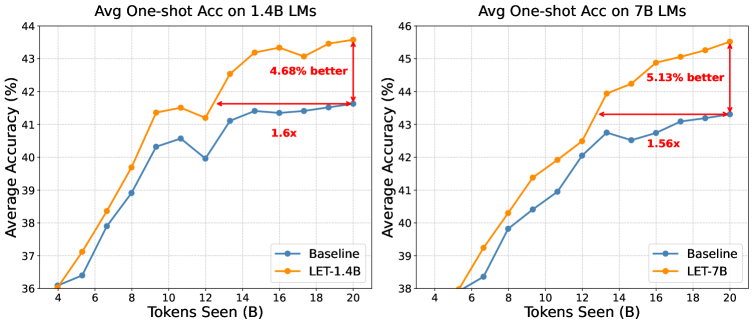
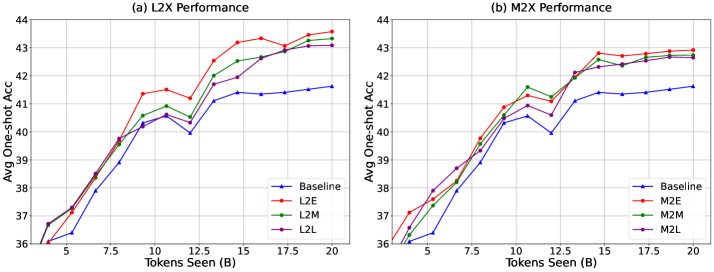
Повышение эффективности предварительного обучения больших языковых моделей (LLM) имеет решающее значение для обеспечения широкого доступа к передовым технологиям обработки естественного языка и дальнейшего развития этой области. Предложенный подход, известный как Late-to-Early Training (LET), демонстрирует значительные улучшения в производительности, достигая прироста до 1.6x на различных задачах. Примечательно, что такая эффективность достигается даже при использовании моделей, в десять раз меньших по размеру, чем стандартные, что открывает возможности для обучения и развертывания LLM на менее мощном оборудовании и снижает связанные с этим затраты. Это делает передовые технологии обработки языка более доступными для исследователей и разработчиков с ограниченными ресурсами, способствуя инновациям и расширению сферы применения LLM.
Дистилляция знаний: ступень к эффективности
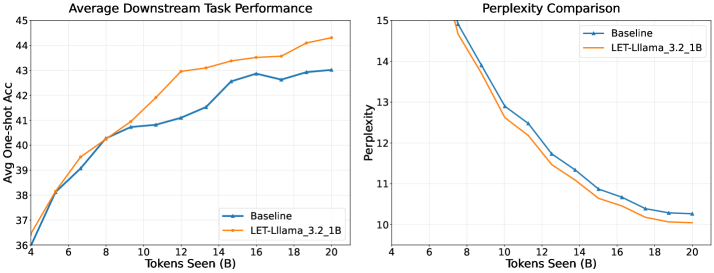
Дистилляция знаний (Knowledge Distillation, KD) представляет собой метод сжатия больших, сложных моделей машинного обучения для создания более компактных и эффективных версий. В основе KD лежит передача знаний от большой, предварительно обученной «модели-учителя» к меньшей «модели-ученику». Этот процесс включает в себя не только передачу правильных ответов, но и «мягких меток» — вероятностей, присвоенных каждому классу, что позволяет модели-ученику усвоить более тонкие различия и обобщающие способности модели-учителя. В результате модель-ученик может достичь производительности, близкой к модели-учителю, при значительно меньшем количестве параметров и вычислительных затратах.
Обратное дистилляционное обучение (Reverse Knowledge Distillation, RKD) представляет собой методологию, при которой знания переносятся от меньшей, специализированной модели (“учителя”) к более крупной модели (“ученику”). В отличие от традиционного дистилляционного обучения, где большая модель передает знания меньшей, RKD позволяет крупным моделям использовать преимущества компактных, но высокоэффективных “учителей”, обученных для решения конкретных задач. Этот подход позволяет повысить производительность и эффективность больших моделей, используя узкоспециализированные знания, полученные от меньших моделей, без необходимости полного переобучения.
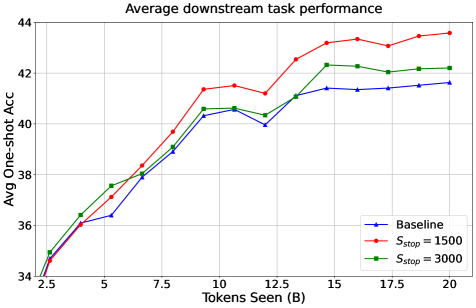
Несмотря на эффективность методов дистилляции знаний (Knowledge Distillation, KD) и обратной дистилляции знаний (Reverse Knowledge Distillation, RKD), их применение часто требует тщательной настройки параметров и не всегда решает проблему масштабирования больших языковых моделей (LLM). В то же время, предложенный подход LET (Learning with Expert Teachers) демонстрирует среднее улучшение производительности в 5.13% на различных задачах, превосходя многие традиционные методы KD. Это указывает на потенциал LET как более эффективной стратегии передачи знаний для LLM.
Обучение с позднего начала: новая парадигма выравнивания
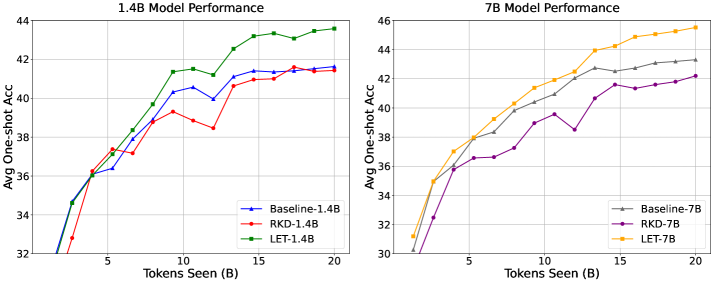
Метод обучения с позднего начала на ранние слои (Late-to-Early Training, LET) представляет собой новый подход к предварительному обучению больших языковых моделей (LLM). В его основе лежит использование представлений, полученных от меньших, предварительно обученных моделей, таких как GPT-2 и SmolLM. Вместо традиционного обучения с нуля или тонкой настройки, LET использует знания, уже заложенные в эти компактные модели, для инициализации и направления процесса обучения более крупной LLM. Это позволяет ускорить сходимость и повысить эффективность обучения за счет переноса знаний из небольших моделей в большую архитектуру.
Метод Late-to-Early Training (LET) концентрируется на согласовании ранних слоев большой языковой модели (LLM) с представлениями, полученными из предварительно обученных небольших моделей, таких как GPT-2 или SmolLM. Этот процесс согласования направлен на то, чтобы задать начальное направление обучения для LLM, что позволяет более эффективно использовать вычислительные ресурсы и сократить время, необходимое для достижения оптимальной производительности. Согласование именно ранних слоев позволяет задать базовые представления о языке, которые затем уточняются в процессе дальнейшего обучения, что способствует более стабильному и эффективному процессу обучения всей модели.
Метод Late-to-Early Training (LET) использует преимущества как больших, так и малых языковых моделей, создавая синергетическую среду обучения. В рамках LET, производительность не снижается по сравнению со стандартными методами, несмотря на использование дополнительных (вспомогательных) моделей для выравнивания слоев. Экспериментальные данные демонстрируют, что оптимальные результаты достигаются при выравнивании с третьим слоем целевой большой языковой модели, что указывает на ключевую роль этого слоя в процессе переноса знаний от меньших моделей.
Механизмы и валидация эффективности LET
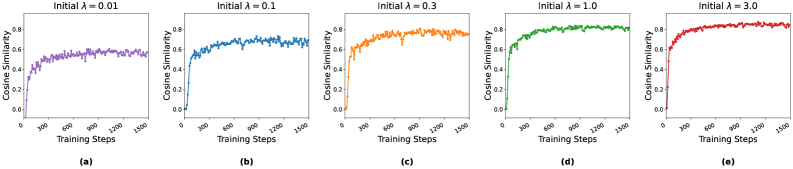
Метод LET использует косинусное сходство (Cosine Similarity) и функцию LogSum Loss для обеспечения точного выравнивания представлений между моделями. Косинусное сходство позволяет измерять близость векторов представлений, стимулируя модели генерировать схожие представления для одинаковых входных данных. LogSumLoss эффективно минимизирует разницу между распределениями представлений, что способствует более согласованному обучению и улучшает обобщающую способность моделей. Комбинация этих техник направлена на максимизацию соответствия между представлениями, создаваемыми различными моделями, что в свою очередь повышает эффективность передачи знаний и улучшает производительность в задачах, требующих совместного обучения или дистилляции знаний.
Анализ матрицы Гессе показал, что метод LET (Learning to Extract) улучшает обусловленность ландшафта функции потерь. Более конкретно, вычисленные значения собственных чисел матрицы Гессе демонстрируют снижение дисперсии, что указывает на более гладкий и стабильный процесс оптимизации. Улучшенная обусловленность позволяет использовать более высокие скорости обучения без риска расходимости, сокращая время обучения и повышая эффективность сходимости алгоритма. Это достигается за счет регуляризации, вводимой LET, которая способствует формированию более выпуклого и хорошо масштабируемого ландшафта потерь, облегчая поиск глобального минимума. H — матрица Гессе.
Результаты экспериментов на эталонных наборах данных HellaSwag и Winogrande продемонстрировали существенное улучшение производительности в задачах, решаемых после применения предложенного метода. В частности, зафиксировано увеличение эффективности до 1.6 раз по сравнению с существующими подходами. Данное улучшение свидетельствует о способности метода эффективно переносить знания, полученные в процессе обучения, на новые, ранее не встречавшиеся задачи, что подтверждается стабильными результатами на различных тестовых примерах.
Перспективы развития: масштабирование и обобщение LET
Дальнейшие исследования должны быть направлены на масштабирование метода LET для работы с еще более крупными моделями и наборами данных, что позволит расширить границы возможностей языковых моделей. Увеличение вычислительных ресурсов и оптимизация алгоритмов обучения являются ключевыми факторами для достижения этой цели. Эксперименты с различными архитектурами моделей и стратегиями параллельного обучения могут существенно ускорить процесс и повысить эффективность. По мере увеличения масштаба, важно исследовать возможности распределенного обучения и использования специализированного оборудования для обработки данных, что позволит справляться с возрастающей сложностью и объемом информации, необходимой для обучения современных языковых моделей. Ожидается, что масштабирование LET приведет к значительному улучшению производительности в различных задачах обработки естественного языка и откроет новые возможности для создания более интеллектуальных и полезных систем.
Исследования показывают, что оптимизация процесса согласования больших языковых моделей (LLM) напрямую зависит от архитектуры и графика обучения модели-учителя. В частности, эксперименты с различными типами архитектур — от трансформеров с разреженным вниманием до смесей экспертов — могут значительно повлиять на качество передаваемых знаний и, следовательно, на производительность LLM. Не менее важен график обучения: более длительные и постепенные этапы обучения, а также использование адаптивных алгоритмов оптимизации, позволяют модели-учителю более эффективно передавать сложные концепции и нюансы, минимизируя риск переобучения и обеспечивая более надежное согласование с целевой моделью. Дальнейшие исследования в этой области направлены на разработку автоматизированных методов подбора оптимальной архитектуры и графика обучения, что позволит существенно повысить эффективность и масштабируемость процесса согласования LLM.
Для полной реализации потенциала инновационного подхода к предварительному обучению, известного как LET, необходимо адаптировать его к разнообразным модальностям и задачам. Исследования показывают, что универсальность модели напрямую зависит от её способности эффективно обрабатывать информацию, поступающую из различных источников — от текста и изображений до аудио и видео. Расширение возможностей LET для работы с мультимодальными данными позволит создавать системы, способные к более комплексному пониманию окружающего мира и выполнению широкого спектра задач, включая анализ контента, генерацию креативных материалов и взаимодействие с пользователем на качественно новом уровне. Успешная адаптация к различным задачам, таким как машинный перевод, ответы на вопросы и суммаризация текстов, станет ключевым фактором в повышении практической ценности и широком внедрении данной технологии.
Исследование представляет собой элегантную деконструкцию традиционного подхода к предварительному обучению больших языковых моделей. Авторы предлагают не просто оптимизировать процесс, но и переосмыслить его, используя знания, полученные от более компактных моделей, для ускорения обучения их более крупных аналогов. Это напоминает принцип дистилляции знаний, когда суть сложной системы передается в более простую форму. Как заметил Марвин Минский: «Лучший способ понять что-то — это построить это». В данном случае, построение моста между маленькой и большой моделью позволяет не только ускорить обучение, но и глубже понять механизмы представления знаний. Каждый «патч», каждая оптимизация — это философское признание несовершенства текущих моделей и стремление к более эффективным алгоритмам.
Куда Ведет Эта Дорога?
Представленный подход к обучению больших языковых моделей, названный Late-to-Early Training, безусловно, ставит под сомнение устоявшиеся догмы. Если прежде считалось, что обучение должно быть последовательным наращиванием сложности, то здесь предлагается своего рода “реверс-инжиниринг” знаний — начать с уже сформированных представлений, а затем «взламывать» их, адаптируя к новым задачам. Однако, истинный вызов заключается не в скорости обучения, а в понимании того, что именно обучается. Достаточно ли простого соответствия между входными и выходными данными, или же модель действительно формирует некое внутреннее представление о мире?
Очевидным ограничением является зависимость от качества «учителя» — предобученной модели меньшего размера. Если исходное знание искажено или неполно, то и «ученик» унаследует эти недостатки. Перспективным направлением представляется исследование методов автоматической оценки и коррекции этих искажений, своеобразный “антивирус” для знаний. Кроме того, необходимо исследовать возможности применения данного подхода к другим модальностям данных — зрению, слуху, осязанию — и создать универсальные алгоритмы обучения, способные адаптироваться к любым источникам информации.
В конечном счете, истинный прогресс не измеряется скоростью обучения или точностью предсказаний, а способностью моделей к генерации принципиально новых идей. Вопрос в том, сможет ли этот подход открыть путь к созданию искусственного интеллекта, способного не просто имитировать человеческое мышление, а превзойти его, обнаруживая закономерности и связи, недоступные человеческому разуму. И это, пожалуй, самая интересная загадка.
Оригинал статьи: https://arxiv.org/pdf/2602.05393.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Квантовая механика: скрытый детерминизм?
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Отчетность об устойчивом развитии: Автоматизация анализа с помощью искусственного интеллекта
2026-02-07 06:05