Автор: Денис Аветисян
Новый обзор исследует, как современные языковые модели применяются для автоматизации создания и анализа программной документации.
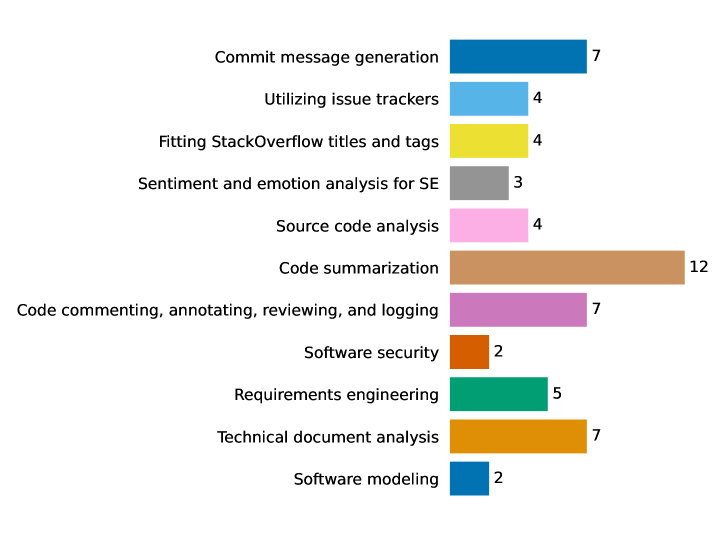
Систематический анализ 57 исследований показывает потенциал больших языковых моделей в задачах документирования и моделирования программного обеспечения, но не выявляет существенных прорывов.
Несмотря на стремительное развитие генеративного искусственного интеллекта, его реальное влияние на практику разработки программного обеспечения остается предметом дискуссий. В настоящем обзоре ‘Large Language Models in Software Documentation and Modeling: A Literature Review and Findings’ проведен систематический анализ 57 исследований, посвященных применению больших языковых моделей (LLM) в задачах, связанных с документацией и моделированием программного обеспечения. Полученные результаты демонстрируют, что LLM обладают значительным потенциалом для улучшения существующих рабочих процессов, однако пока не привели к революционным изменениям в данной области. Какие перспективы открываются для дальнейшего исследования и внедрения LLM в процессы разработки программного обеспечения, и какие ограничения необходимо преодолеть для реализации их полного потенциала?
Иллюзия Революции: Современные Вызовы в Разработке ПО
Современная разработка программного обеспечения сталкивается с растущей сложностью систем, обусловленной необходимостью интеграции многочисленных компонентов, соответствия жестким требованиям к производительности и безопасности, а также поддержания масштабируемости. Традиционные методологии и практики, успешно применявшиеся ранее, зачастую оказываются неэффективными при работе с такими сложными проектами, что приводит к увеличению сроков разработки, росту затрат и снижению качества конечного продукта. Данная ситуация обуславливает острую необходимость в поиске и внедрении инновационных подходов, способных автоматизировать рутинные задачи, упростить процесс проектирования и повысить надежность разрабатываемого программного обеспечения. Подобные решения должны учитывать специфику современных технологий и потребностей быстро меняющегося рынка.
Крупные языковые модели (LLM4SE) представляют собой принципиально новый подход к разработке программного обеспечения, обещая автоматизацию и повышение интеллекта на всех этапах жизненного цикла продукта. От автоматической генерации кода и тестирования до документирования и отладки — LLM4SE способны существенно ускорить и упростить рутинные задачи, освобождая разработчиков для более творческой и сложной работы. Вместо традиционного последовательного подхода, LLM4SE позволяют интегрировать интеллектуальные инструменты непосредственно в процесс разработки, обеспечивая более гибкое и адаптивное решение проблем. Это смещение парадигмы открывает возможности для создания самооптимизирующегося и самодокументирующегося программного обеспечения, что в перспективе может привести к значительному повышению качества и эффективности разработки.
Для полной реализации потенциала больших языковых моделей (LLM) в области разработки программного обеспечения необходим тщательный анализ их возможностей и ограничений. Исследование, охватившее анализ 57 научных работ, демонстрирует, что простого внедрения LLM недостаточно; требуется глубокое понимание того, как эти модели взаимодействуют с различными этапами жизненного цикла разработки. Полученные результаты подчеркивают важность систематической оценки эффективности LLM в таких задачах, как генерация кода, обнаружение ошибок и автоматизация тестирования. В частности, анализ показал, что LLM наиболее эффективны при решении узкоспециализированных задач и требуют дополнительной настройки и валидации для обеспечения надежности и безопасности генерируемого кода. Таким образом, критически важно не просто использовать LLM, а понимать принципы их работы и адаптировать их к конкретным потребностям разработки программного обеспечения.
Автоматизация Документации: Миф об Идеальном Коде
Несмотря на критическую важность, документация к программному обеспечению часто оказывается упущенной из виду в процессе разработки, что приводит к значительному увеличению расходов на поддержку и сопровождение. Отсутствие актуальной и полной документации усложняет понимание кода, замедляет внесение изменений и повышает риск возникновения ошибок. Это особенно актуально для крупных и сложных проектов, где поддержание согласованности и точности документации требует значительных усилий и ресурсов. В результате, организации несут существенные финансовые потери, связанные с увеличением времени на отладку, внесение изменений и обучение новых разработчиков.
Автоматическое суммирование кода с использованием больших языковых моделей (LLM) представляет собой процесс генерации текстовых описаний фрагментов программного кода. Данная технология позволяет автоматизировать создание документации, значительно снижая затраты на её поддержание и повышая общую понятность кодовой базы. LLM анализируют синтаксис и семантику кода, формируя краткие и информативные описания, которые могут использоваться разработчиками для быстрого понимания функциональности отдельных компонентов или целых модулей. В результате автоматизации, документация может поддерживаться в актуальном состоянии параллельно с изменениями в коде, что особенно важно в динамично развивающихся проектах.
Для оценки качества автоматически генерируемых LLM-моделями текстовых описаний кода используются метрики BLEU, ROUGE и Side Metric. BLEU (Bilingual Evaluation Understudy) измеряет совпадение n-грамм между сгенерированным текстом и эталонными описаниями. ROUGE (Recall-Oriented Understudy for Gisting Evaluation) оценивает перекрытие между сгенерированным текстом и эталонными описаниями, фокусируясь на полноте. Side Metric, в свою очередь, оценивает семантическую близость между сгенерированным текстом и исходным кодом. Анализ 57 научных работ показал устойчивую тенденцию к улучшению результатов, достигаемых с помощью LLM, в автоматизации генерации документации и повышению эффективности существующих рабочих процессов в этой области.
Оптимизация Отслеживания Задач: Иллюзия Контроля
Эффективное отслеживание задач является критически важным аспектом управления проектами разработки программного обеспечения. Однако, ручная категоризация и приоритизация этих задач может быть значительно трудоемкой и занимать значительное время у команды разработчиков. Это связано с необходимостью анализа каждого сообщения об ошибке или запроса на доработку, определения его типа, серьезности и назначения ответственного исполнителя. В результате, время, затрачиваемое на организацию задач, может снижать общую производительность команды и задерживать выпуск продукта.
Для оптимизации процессов отслеживания ошибок и ускорения их решения в системах Issue Tracker все чаще применяются большие языковые модели (LLM), такие как GPT-4. Эти модели автоматизируют классификацию поступающих запросов, позволяя избежать ручной категоризации и расстановки приоритетов. Автоматическая классификация позволяет быстрее направлять запросы соответствующим специалистам и сокращает время, затрачиваемое на обработку каждого инцидента, что в конечном итоге повышает эффективность работы команды разработчиков.
Внедрение больших языковых моделей (LLM), таких как CodeT5, способствует улучшению взаимодействия разработчиков на платформе StackOverflow посредством автоматической генерации заголовков и тегов для публикаций, в рамках проектов SOTitle+ и PTM4Tag+. Важно отметить, что все проанализированные исследования, посвященные данной тематике, финансируются исключительно из фонда Европейского Союза NextGenerationEU, что подчеркивает стратегическую важность данной инициативы для развития европейской технологической экосистемы.
Валидация Подходов LLM4SE: Между Обещанием и Реальностью
Автоматизированное создание сообщений коммитов (commit messages) играет ключевую роль в эффективном контроле версий программного обеспечения, однако значимость этой задачи часто недооценивается разработчиками. Качественное сообщение коммита позволяет четко понимать внесенные изменения, облегчает совместную работу и упрощает отладку. Несмотря на это, многие программисты склонны к написанию кратких или неинформативных сообщений, что затрудняет последующее понимание истории проекта. Игнорирование этой практики приводит к снижению продуктивности команды и увеличению вероятности ошибок, поскольку отсутствие контекста усложняет процесс анализа и внесения изменений в код. В связи с этим, разработка и внедрение автоматизированных инструментов, способных генерировать содержательные и осмысленные сообщения коммитов, представляется важной задачей современной разработки программного обеспечения.
Для автоматизации создания осмысленных сообщений коммитов в системах контроля версий применяются современные языковые модели, такие как CommitBART, KADEL и OMEGA. Эти модели обучаются и оцениваются на специализированных наборах данных, в частности, на MCMD Dataset, который содержит примеры коммитов и соответствующих описаний. Использование MCMD Dataset позволяет количественно оценить способность моделей генерировать сообщения, отражающие суть внесенных изменений в коде, и сравнить эффективность различных подходов к автоматизации этого процесса. Оценка проводится с целью обеспечения практической применимости и облегчения работы разработчиков.
Тщательная оценка подходов к автоматической генерации сообщений коммитов включает в себя комбинацию автоматизированных метрик и экспертной оценки. Автоматические показатели, такие как BERTScore, позволяют количественно оценить семантическое сходство с эталонными сообщениями, а анализ тональности помогает определить, насколько сообщение передает намерения разработчика. Однако, для подтверждения практической полезности и принятия разработчиками, необходима экспертная оценка, позволяющая оценить ясность, точность и информативность сгенерированных сообщений в контексте реальных проектов. Сочетание этих методов обеспечивает надежную валидацию и позволяет определить, насколько эффективно модель соответствует потребностям разработчиков и способствует поддержанию качественной истории изменений в коде.
Перспективы LLM4SE: Куда Ведет Нас Иллюзия Прогресса?
Активные исследования в области применения больших языковых моделей (LLM) к разработке программного обеспечения, известных как LLM4SE, находят отражение в ведущих научных изданиях. Результаты этих работ регулярно публикуются в таких авторитетных журналах, как IEEE Transactions on Software Engineering, ACM Transactions on Software Engineering and Methodology, а также в сборниках Springer Empirical Software Engineering. Этот факт свидетельствует о растущем признании и важности данного направления исследований в академическом сообществе, подтверждая его значимость для развития современной практики разработки программного обеспечения и стимулируя дальнейшие инновации в этой области.
Систематический обзор литературы играет ключевую роль в обобщении полученных результатов и выявлении новых тенденций в области применения больших языковых моделей (LLM) для разработки программного обеспечения. Проведенный анализ охватывает 57 научных работ, что позволяет комплексно оценить текущее состояние исследований, определить наиболее перспективные направления и выявить существующие пробелы. Такой подход не только консолидирует разрозненные знания, но и способствует более эффективному планированию будущих исследований, позволяя избежать дублирования усилий и сосредоточиться на решении наиболее актуальных задач в данной быстро развивающейся области. Подобный анализ становится незаменимым инструментом для исследователей и практиков, стремящихся к инновациям в сфере разработки программного обеспечения с использованием LLM.
Дальнейшие исследования в области применения больших языковых моделей (LLM) в разработке программного обеспечения, вероятно, будут сосредоточены на преодолении существующих ограничений и повышении устойчивости моделей к различным входным данным и сценариям. Ожидается, что акцент будет сделан на расширении спектра применения LLM на всех этапах жизненного цикла разработки программного обеспечения — от анализа требований и проектирования архитектуры до кодирования, тестирования и развертывания. Исследователи стремятся к созданию более надежных и адаптивных инструментов, способных автоматизировать сложные задачи и повысить эффективность работы разработчиков, а также к изучению возможностей применения LLM в новых областях, таких как автоматическое исправление ошибок, генерация документации и оптимизация производительности кода.
Изучение применения больших языковых моделей в документировании и моделировании программного обеспечения, представленное в данной работе, закономерно выявляет отсутствие революционных изменений. Авторы тщательно проанализировали 57 исследований, и результат предсказуем: инструменты улучшают существующие процессы, но не предлагают принципиально новых подходов. Как и всегда, энтузиазм сталкивается с суровой реальностью. Впрочем, это не ново. Как однажды заметил Джон Маккарти: «Это всего лишь ещё один способ сделать что-то, что уже делалось». И пусть новые библиотеки и фреймворки появляются ежедневно, в конечном итоге, всё сводится к решению старых проблем с использованием новых, зачастую переусложнённых инструментов. И документация, конечно, остаётся ахиллесовой пятой любого проекта.
Что дальше?
Итак, пятьдесят семь исследований, потраченных на то, чтобы научить машину писать комментарии к коду. Похвально, конечно, но давайте будем честны: каждая «революция» в области автоматизации документации неизбежно превращается в технический долг. LLM, возможно, и умеют генерировать текст, похожий на документацию, но кто-нибудь проверял, не генерируют ли они заодно и новые баги? Тесты — это, как известно, форма надежды, а не гарантия качества.
Вместо того чтобы мечтать о полной автоматизации, стоит сосредоточиться на более приземленных задачах. Например, на разработке инструментов, которые помогут разработчикам эффективнее писать документацию, а не заменят их полностью. Или на создании систем, которые смогут автоматически выявлять устаревшую или неточную документацию. Потому что, как показывает практика, скрипт, который обещал автоматизировать все процессы, рано или поздно удаляет прод.
Будущие исследования, вероятно, столкнутся с проблемой контекста. LLM хорошо генерируют текст, но им трудно понять смысл кода и его место в общей архитектуре системы. Поэтому, возможно, стоит переключиться на разработку более сложных моделей, которые смогут учитывать не только синтаксис, но и семантику кода. Но, конечно, это лишь очередная ступень на пути к неизбежному техническому долгу.
Оригинал статьи: https://arxiv.org/pdf/2602.04938.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Квантовая механика: скрытый детерминизм?
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Моделирование биомолекул: новый импульс от нейросетей
- Ловушки для ИИ: Как выявить критические ошибки в больших языковых моделях
2026-02-07 09:07