Автор: Денис Аветисян
Новый подход к обучению агентов на основе больших языковых моделей позволяет им лучше ориентироваться в сложных задачах, не требуя вмешательства экспертов.
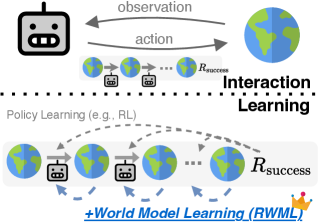
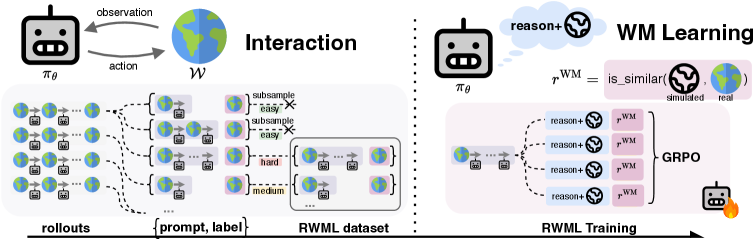
В статье представлена методика Reinforcement World Model Learning (RWML) — самообучающийся метод, улучшающий понимание окружения для LLM-агентов и повышающий их эффективность в долгосрочных задачах.
Несмотря на впечатляющие успехи в задачах, связанных с обработкой языка, большие языковые модели (LLM) часто испытывают трудности в агентных средах, где требуется прогнозирование последствий действий и адаптация к динамике окружения. В работе ‘Reinforcement World Model Learning for LLM-based Agents’ предложен метод обучения с подкреплением мировым моделям (RWML), позволяющий LLM-агентам осваивать модели мира на основе текстовых состояний и вознаграждений, полученных в результате взаимодействия со средой. RWML обеспечивает согласованность между смоделированными и наблюдаемыми состояниями, что позволяет агентам эффективнее планировать долгосрочные действия без использования экспертных данных. Способны ли подобные методы открыть путь к созданию действительно автономных и адаптивных LLM-агентов, способных решать сложные задачи в реальном мире?
За гранью иллюзий: Рождение агентов нового типа
Современные достижения в области больших языковых моделей (БЯМ) открывают захватывающие перспективы для создания интеллектуальных агентов, способных решать сложные задачи. Эти модели, обученные на огромных объемах текстовых данных, демонстрируют впечатляющую способность к пониманию и генерации естественного языка, что является ключевым компонентом для эффективного взаимодействия с окружающим миром. БЯМ способны не только обрабатывать информацию, но и извлекать из неё знания, планировать действия и адаптироваться к меняющимся обстоятельствам. Хотя до создания полноценного искусственного интеллекта еще далеко, современные БЯМ представляют собой мощный инструмент для автоматизации рутинных задач, поддержки принятия решений и создания новых интеллектуальных систем, способных решать задачи, ранее доступные только человеку.
Несмотря на впечатляющие успехи в разработке больших языковых моделей, создание по-настоящему автономного интеллекта, способного к надежному рассуждению, планированию и действиям, остается сложной задачей. Ограничения архитектуры современных языковых моделей, а также методы их обучения, препятствуют формированию у агентов способности к глубокому пониманию контекста и эффективному решению проблем в реальном времени. В частности, существующие модели часто демонстрируют недостаточную гибкость в адаптации к новым ситуациям и склонны к генерации нелогичных или противоречивых выводов, что существенно ограничивает их применимость в сложных и динамичных средах. Преодоление этих ограничений требует разработки принципиально новых подходов к обучению и архитектуре, позволяющих агентам не только генерировать текст, но и эффективно взаимодействовать с окружающим миром и достигать поставленных целей.
Основным препятствием на пути к созданию по-настоящему автономных агентов является их способность адекватно воспринимать и взаимодействовать с постоянно меняющимися условиями окружающей среды. В отличие от статических задач, где агент может полагаться на заранее заданные сценарии, динамические среды требуют от агента не только обработки текущей информации, но и прогнозирования будущих изменений и адаптации к ним. Это подразумевает необходимость разработки более сложных моделей представления мира, позволяющих агенту строить внутреннюю карту окружения, отслеживать перемещения объектов и предвидеть последствия своих действий. Именно эффективное моделирование динамики окружающей среды, включая неопределенности и непредсказуемые события, становится критически важным для успешного функционирования агента в реальных условиях и реализации его потенциала для решения сложных задач.

Проверка на прочность: Симуляции как полигон для интеллекта
Для надежной оценки агентов искусственного интеллекта необходимы сложные тестовые среды, такие как ALFWorld. Это платформа, основанная на текстовых данных, предназначенная для разработки и тестирования систем воплощенного ИИ, специализирующихся на выполнении бытовых задач. ALFWorld предоставляет структурированные сценарии, имитирующие реалистичные домашние условия, позволяя количественно оценить способность агента понимать инструкции, планировать действия и успешно взаимодействовать с виртуальным окружением для достижения поставленных целей. Платформа позволяет проводить автоматизированное тестирование и сравнительный анализ различных алгоритмов и моделей ИИ в контексте выполнения конкретных бытовых задач.
Бенчмарк τ2 представляет собой строгий инструмент для оценки агентов в условиях многооборотного диалога, моделирующих взаимодействие с клиентами в реальных службах поддержки. Он состоит из набора задач, требующих от агента понимания запросов пользователя, поддержания контекста беседы на протяжении нескольких ходов и предоставления релевантных ответов. Оценка проводится на основе метрик, измеряющих успешность выполнения задачи, связность диалога и качество предоставляемой информации. Бенчмарк включает в себя разнообразные сценарии, охватывающие широкий спектр запросов и проблем, что позволяет комплексно оценить возможности агента в условиях сложного взаимодействия с пользователем.
Платформы, такие как ALFWorld и τ2 Bench, обеспечивают количественную оценку способностей агентов к выполнению задач и ведению связного диалога посредством автоматизированных метрик. В ALFWorld, успех оценивается по количеству успешно выполненных бытовых задач, таких как уборка или приготовление пищи, а также по эффективности планирования действий. В τ2 Bench, оценка ведется на основе показателей успешности разрешения запросов клиентов в многооборотном диалоге, включая точность понимания намерения пользователя и полноту предоставленной информации. Эти платформы позволяют объективно сравнить различные модели агентов, выявляя их сильные и слабые стороны в конкретных сценариях и задачах.
Учимся у лучших: Экспертные демонстрации как трамплин к интеллекту
Супервизированное дообучение (SFT) является распространенным методом адаптации предварительно обученных больших языковых моделей (LLM), таких как Qwen, к решению конкретных задач. В рамках SFT, модель обучается на наборе данных, состоящем из демонстраций экспертного поведения — так называемых “expert rollouts”. Эти данные служат примерами желаемого поведения, позволяя модели научиться сопоставлять входные данные с соответствующими действиями или ответами. Процесс дообучения корректирует веса предварительно обученной модели, оптимизируя её для достижения высокой производительности в целевой задаче, используя демонстрации в качестве сигналов обучения с учителем.
Для получения высококачественных экспертных демонстраций, применимых для обучения моделей, широко используется метод отбора (Rejection Sampling). Суть метода заключается в генерации большого количества траекторий поведения, после чего производится отбор только тех, которые соответствуют заданным критериям качества, например, высокой награде или минимальной длительности. Отобранные траектории формируют набор экспертных демонстраций, представляющих собой наиболее успешные стратегии решения задачи и служащие для обучения агента посредством supervised learning. Эффективность отбора напрямую влияет на качество обучения и способность агента быстро осваивать требуемые навыки.
Обучение на основе демонстраций экспертов позволяет агентам быстро осваивать базовые навыки и повышать эффективность. Этот подход, основанный на использовании размеченных данных, демонстрирующих желаемое поведение, позволяет избежать длительного периода случайного обучения методом проб и ошибок. Агент, анализируя предоставленные примеры, способен выявлять оптимальные стратегии и применять их в новых ситуациях, значительно сокращая время, необходимое для достижения требуемого уровня производительности. Эффективность обучения напрямую зависит от качества и репрезентативности демонстраций, а также от способности агента обобщать полученные знания и адаптировать их к различным условиям.
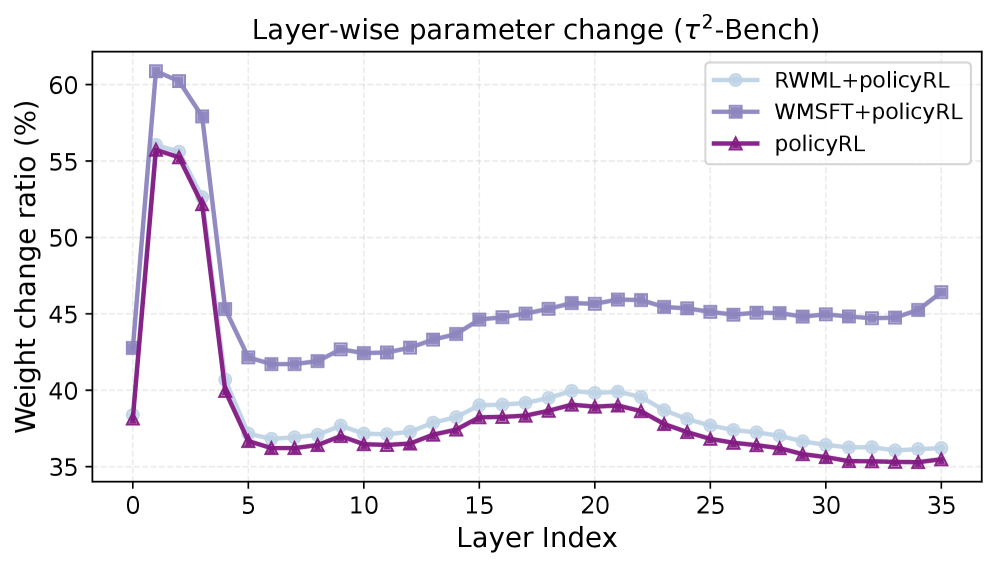
Искусство самосовершенствования: Оптимизация поведения с помощью обучения с подкреплением
Обучение с подкреплением (Policy RL) представляет собой мощный подход к оптимизации поведения агентов посредством последовательных проб и ошибок. В основе этого метода лежит принцип максимизации получаемого вознаграждения за успешное выполнение поставленной задачи. Агент, взаимодействуя с окружающей средой, формирует стратегию (политику) выбора действий, стремясь к увеличению суммарного вознаграждения. Данный процесс позволяет агенту адаптироваться к сложным условиям и находить оптимальные решения без явного программирования, что особенно ценно в задачах, где заранее неизвестны наилучшие действия. Эффективность Policy RL обусловлена способностью агента к самообучению и постоянному совершенствованию стратегии на основе полученного опыта.
Эффективность обучения с подкреплением, основанного на политике, напрямую зависит от точности и продуманности функции вознаграждения. В частности, сигнал, указывающий на успешное выполнение поставленной задачи — так называемое вознаграждение за успех — играет ключевую роль в формировании оптимального поведения агента. Недостаточно четко определенная или неполная функция вознаграждения может привести к тому, что агент будет обучаться нежелательным стратегиям или не сможет эффективно решать поставленную задачу. Поэтому разработка адекватной функции вознаграждения является критически важным этапом при применении обучения с подкреплением, поскольку именно она определяет, какие действия агента будут поощряться, а какие — нет, формируя тем самым его стратегию поведения и общую эффективность.
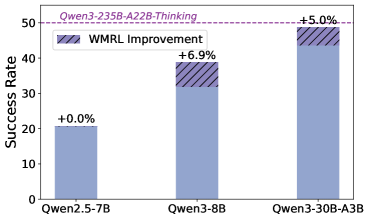
Сочетание контролируемого обучения и обучения с подкреплением позволяет агентам достигать превосходной производительности и способности к обобщению. Предложенный метод Reinforcement World Model Learning (RWML) демонстрирует значительное улучшение в этой области, достигая прироста до 19.6 пунктов на бенчмарке ALFWorld. RWML позволяет агентам не только эффективно решать поставленные задачи, но и адаптироваться к новым, ранее не встречавшимся ситуациям, что делает его перспективным подходом для создания более гибких и интеллектуальных систем искусственного интеллекта. Этот подход способствует более быстрому обучению и повышает надежность агентов в сложных и динамичных средах.
Исследования показали, что комбинирование метода Reinforcement World Model Learning (RWML) с обучением с подкреплением (Policy RL) демонстрирует значительное превосходство над традиционным обучением с подкреплением, основанным на непосредственном сигнале об успешном выполнении задачи. В частности, на платформе ALFWorld наблюдается улучшение результатов на 6.9 пункта, а на бенчмарке τ2 — на 5.7 пункта. Данный результат указывает на то, что использование RWML позволяет агентам более эффективно осваивать сложные задачи, улучшая их обобщающую способность и позволяя достигать более высоких показателей производительности по сравнению с подходами, полагающимися исключительно на прямой сигнал вознаграждения за успех.
Наблюдая за увлечением методами обучения с подкреплением для LLM-агентов, специалист отмечает закономерность. Заявления о создании агентов, способных к долгосрочному планированию без использования экспертных данных, звучат знакомо. В конце концов, идея обучения моделей пониманию окружающей среды через взаимодействие — это не ново. Как говорил Винтон Серф: «Интернет — это не просто технология, это способ организации информации». Подобно тому, как интернет структурирует информацию, Reinforcement World Model Learning (RWML) пытается структурировать понимание среды для агента. Однако, опыт подсказывает, что элегантные теоретические построения рано или поздно сталкиваются с суровой реальностью продакшена. И, как правило, агенты находят способы «сломать» даже самые тщательно продуманные модели мира.
Что Дальше?
Представленный подход, безусловно, добавляет ещё один слой абстракции между нейронной сетью и неизбежной энтропией реального мира. Однако, стоит помнить: каждая «революционная» модель мира рано или поздно превратится в каталог ошибок, которые продакшен найдёт способ эксплуатировать. Успех в долгосрочных задачах не гарантирован, и, вероятно, будет зависеть не столько от сложности самой модели мира, сколько от скорости, с которой система научится игнорировать ложные срабатывания.
Особое внимание следует уделить проблеме масштабируемости. Вполне вероятно, что увеличение сложности модели мира приведёт к экспоненциальному росту вычислительных затрат, и тогда мы вновь столкнёмся с необходимостью упрощения, что, по сути, является признанием поражения. Иллюзия контроля над хаосом — привычная нам участь. Скрам, конечно, не панацея, а лишь способ убедить людей, что хаос управляем, и данная работа не является исключением.
В конечном итоге, вопрос заключается не в том, насколько точно агент моделирует мир, а в том, насколько быстро он адаптируется к его неточностям. Багтрекер — это, по сути, дневник боли, и каждая новая «инновация» добавляет в него новую строку. Мы не деплоим — мы отпускаем, и рано или поздно, всё сломается. Поэтому, прежде чем увлечься построением идеальных моделей мира, стоит задуматься о том, как сделать систему более устойчивой к ошибкам.
Оригинал статьи: https://arxiv.org/pdf/2602.05842.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Автопилот нового поколения: Единая модель для понимания, планирования и предвидения
- Видеть детали: новый подход к мультимодальному восприятию
- Видеогенераторы и скрытые правила мира: смогут ли они понять невысказанное?
- Восстановление электронной структуры материалов с помощью машинного обучения
- Квантовые вычисления: Новый взгляд на оценку ресурсов
- Квантовая электродинамика и сильные корреляции: новый взгляд на взаимодействие света и материи
- Потоки, ведущие к совершенству: новый подход к генеративным моделям
- Разум как отражение: новая архитектура интеллекта
- Эхо разума: как итеративные модели учатся в цикле.
2026-02-07 14:03