Автор: Денис Аветисян
Исследователи предлагают метод, позволяющий создавать более длинные и связные видеоролики без переобучения модели, фокусируясь на коррекции процесса генерации.

Предложен метод Test-Time Correction (TTC) для улучшения качества и связности видео, генерируемых авторегрессионными диффузионными моделями.
Несмотря на успехи дистиллированных авторегрессионных диффузионных моделей в синтезе коротких видео, генерация длинных последовательностей страдает от накопления ошибок. В работе ‘Pathwise Test-Time Correction for Autoregressive Long Video Generation’ предложен новый подход, позволяющий стабилизировать процесс генерации видео без переобучения модели. В основе метода Test-Time Correction (TTC) лежит калибровка промежуточных состояний генерации относительно стабильного начального кадра, что обеспечивает временную согласованность. Сможет ли данная техника открыть путь к созданию реалистичных и продолжительных видеороликов с минимальными вычислительными затратами?
Проблема Временной Когерентности в Генерации Видео
Авторегрессионная генерация видео, несмотря на свою впечатляющую способность создавать детализированные последовательности, по своей сути подвержена накоплению ошибок при увеличении длительности генерируемого видеоряда. Каждый новый кадр создается на основе предыдущих, что означает, что любая неточность, возникшая на ранних этапах, будет усиливаться и распространяться на последующие кадры. Этот процесс подобен эффекту снежного кома, когда небольшая погрешность в начале постепенно разрастается, приводя к значительным искажениям и несоответствиям в более поздних частях видео. В результате, даже самые современные модели авторегрессионной генерации сталкиваются с трудностями при создании длинных и связных видеороликов, где сохранение визуальной консистентности становится критически важной задачей.
Накопление ошибок в процессе генерации видео, особенно при использовании авторегрессивных моделей, приводит к явлению, известному как временной дрейф. Этот дрейф проявляется как постепенная потеря согласованности между кадрами, что приводит к визуальным артефактам и нарушению правдоподобности видеоряда. Представьте себе, что небольшие неточности в начале последовательности, например, незначительное смещение объекта, со временем усиливаются, приводя к существенному искажению изображения к концу видео. В результате, даже если отдельные кадры выглядят реалистично, общая последовательность может восприниматься как неестественная и непоследовательная, что серьезно ограничивает применимость таких методов для создания длинных и правдоподобных видеороликов.
Существующие методы генерации видео, несмотря на значительный прогресс, сталкиваются с серьезными трудностями при создании длинных, связных последовательностей. Проблема заключается в постепенной потере согласованности — объекты могут незаметно менять форму, освещение — мерцать, а сюжетные линии — прерываться. Это обусловлено тем, что каждый новый кадр генерируется на основе предыдущего, и любая незначительная ошибка накапливается, приводя к заметным артефактам и разрушению визуальной целостности. В результате, практическое применение этих технологий для задач, требующих длительной и реалистичной видеосъемки, например, для создания полнометражных фильмов или интерактивных виртуальных миров, остается ограниченным и требует дальнейших инноваций.

За Пределами Последовательного Предсказания: Продвинутые Генеративные Архитектуры
Диффузионные модели представляют собой мощную альтернативу традиционным авторегрессионным подходам в генерации последовательностей, таких как видео. В основе их работы лежит итеративный процесс шумоподавления: начиная с чистого шума, модель последовательно уточняет данные, удаляя шум на каждом шаге. Этот процесс, основанный на принципах немарковского процесса диффузии, позволяет синтезировать как движение, так и внешний вид объектов. В отличие от моделей, предсказывающих следующий кадр на основе предыдущих, диффузионные модели рассматривают генерацию как обратный процесс диффузии, что позволяет им генерировать более разнообразные и реалистичные результаты. Ключевым преимуществом является способность моделировать сложные распределения данных, что особенно важно для задач, требующих высокой степени детализации и реализма.
Двунаправленные модели отличаются от последовательных подходов тем, что осуществляют процесс шумоподавления (denoising) одновременно для всех кадров временной последовательности. Вместо обработки кадров последовательно, как в авторегрессионных сетях, двунаправленные модели учитывают глобальный временной контекст, анализируя все кадры параллельно. Это позволяет им более эффективно улавливать долгосрочные зависимости и улучшать согласованность генерируемой последовательности, поскольку информация из будущих кадров может быть использована для уточнения текущих. Такой подход позволяет добиться более реалистичной и когерентной генерации видео или других временных данных.
Несмотря на высокую эффективность диффузионных и двунаправленных моделей в генерации последовательностей, их преобразование в эффективные авторегрессионные пайплайны представляет собой сложную задачу. Основная проблема заключается в том, что эти модели, изначально не предназначенные для последовательной генерации, требуют значительных вычислительных ресурсов и оптимизации для работы в режиме реального времени. Эффективная реализация авторегрессии подразумевает минимизацию задержки и снижение требований к памяти, что требует разработки новых алгоритмов дискретизации и квантования, а также аппаратной оптимизации для параллельных вычислений. Необходимость сохранения качества генерируемых данных при одновременном повышении скорости обработки остается ключевым препятствием в практическом применении этих передовых моделей.

Дистилляция Двунаправленной Мощности: Rectified Flow и CausVid
Метод Rectified Flow обеспечивает преобразование двунаправленных моделей в причинно-авторегрессивные, что позволяет существенно повысить эффективность генерации. В основе подхода лежит построение отображения, сохраняющего распределение данных, но обеспечивающего однонаправленный поток информации. Это достигается путем обучения сети, которая моделирует обратный процесс диффузии, позволяя генерировать данные последовательно, начиная с шума. В отличие от стандартных двунаправленных моделей, требующих решения сложной системы уравнений, причинно-авторегрессивные модели генерируют данные итеративно, что снижает вычислительные затраты и упрощает процесс вывода. Такой подход особенно важен для задач, требующих генерации длинных последовательностей, например, в обработке видео или текста, где эффективная генерация является критически важной.
CausVid использует технику преобразования двунаправленных моделей в авторегрессионные, что позволяет создать диффузионную модель для видео, функционирующую в режиме авторегрессии. Это расширяет возможности как Rectified Flow, обеспечивая эффективную генерацию, так и традиционных диффузионных моделей, позволяя моделировать временную зависимость в видеоданных. В основе CausVid лежит последовательное предсказание будущих кадров на основе предыдущих, что позволяет генерировать когерентные видеопоследовательности, используя преимущества авторегрессионного подхода и диффузионного моделирования для повышения качества и реалистичности генерируемого видеоконтента.
Метод Few-step Distilled Diffusion оптимизирует процесс дистилляции, заменяя детерминированные решатели (solvers) на стохастическую выборку. В традиционных подходах дистилляции, детерминированные решатели используются для предсказания последовательности состояний, что может быть вычислительно затратно и ограничивать возможности модели. Переход к стохастической выборке позволяет моделировать неопределенность и генерировать более разнообразные и реалистичные результаты, при этом снижая вычислительную сложность и повышая эффективность процесса дистилляции. Использование стохастической выборки позволяет уменьшить количество шагов, необходимых для генерации, не ухудшая качество выходных данных, что особенно важно для задач, требующих высокой скорости обработки, например, в видеогенерации.
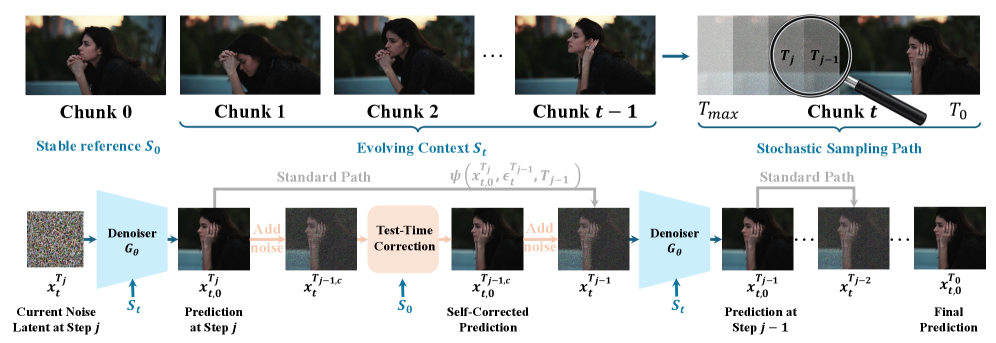
Стабилизация Долговременной Генерации: Механизмы Поглощения и За Его Пределами
Механизмы “поглощения” (sink mechanisms) играют ключевую роль в стабилизации процесса генерации длинных видеопоследовательностей, предотвращая накопление временных отклонений (temporal drift). Эти механизмы работают путем постепенного приведения генерируемых кадров к более стабильному состоянию, что достигается за счет введения дополнительных условий или ограничений в процесс генерации. По сути, они действуют как регуляторы, минимизирующие расхождения между последовательными кадрами и поддерживая визуальную когерентность на протяжении всей последовательности. Отсутствие эффективных механизмов “поглощения” приводит к экспоненциальному росту ошибок и, как следствие, к быстрой деградации качества генерируемого видео.
Методы Self-Forcing, Rolling Forcing и LongLive используют механизмы “утопления” (sink mechanisms) в сочетании с переобучением DMD (Dynamic Mode Decomposition) в скользящем окне для обеспечения минутной согласованности генерируемого видео. В рамках этих подходов, механизмы “утопления” направляют генерируемые кадры к стабильному состоянию, уменьшая временной дрейф. Переобучение DMD в скользящем окне позволяет модели адаптироваться к изменениям в видеопоследовательности и поддерживать когерентность на протяжении более длительного периода времени. Совместное использование этих двух компонентов обеспечивает стабильную генерацию видео продолжительностью до минуты, минимизируя визуальные артефакты и поддерживая согласованность во времени.
Разработанный метод коррекции во время генерации, не требующий предварительного обучения, позволяет создавать стабильные видео продолжительностью до 30 секунд. В ходе тестирования продемонстрировано, что качество сгенерированных видео, полученных с использованием данного метода, сопоставимо с результатами, достигнутыми с помощью подходов, требующих обучения модели. Это достигается за счет применения коррекций непосредственно во время генерации видео, что позволяет минимизировать накопление ошибок и поддерживать визуальную консистентность на протяжении всей последовательности кадров.

Оценка и Уточнение Временной Стабильности
Исследования показали, что применение коррекции во время генерации видео, основанной на стохастической выборке, позволяет эффективно смягчать проблему дрейфа — постепенной потери согласованности и реалистичности в динамических сценах. Данный метод, осуществляющий уточнение видео непосредственно в процессе его создания, позволяет генерировать более стабильные и правдоподобные видеоролики. Вместо однократной генерации, стохастическая выборка предполагает многократное повторение процесса с небольшими случайными изменениями, что позволяет найти оптимальное решение, минимизирующее визуальные артефакты и обеспечивающее плавность переходов между кадрами. Такой подход особенно важен для сложных сцен с большим количеством движущихся объектов, где поддержание временной согласованности является ключевой задачей.
Исследования показали значительное улучшение показателей генерируемых видео по всем 16 метрикам, представленным в бенчмарке VBench. Данный результат подтверждает эффективность предложенного подхода к коррекции видео в процессе инференса. Систематическая оценка по разнообразным параметрам, включая частоту кадров, четкость изображения и согласованность контента, позволила установить, что предложенная методика способна повысить качество генерируемых видеороликов, обеспечивая более плавное и реалистичное отображение динамических сцен. Полученные данные демонстрируют, что предложенный метод является универсальным и применимым к широкому спектру задач генерации видео, что делает его ценным инструментом для исследователей и разработчиков в области компьютерного зрения и машинного обучения.
Исследование демонстрирует, что разработанный метод поддерживает превосходную динамическую степень, что свидетельствует о достижении баланса между стабильностью генерируемого видео и качеством движения. Низкие показатели JEPA-Std и JEPA-Diff, полученные в ходе тестирования, подтверждают улучшенную временную согласованность и сохранение семантического смысла на протяжении длительных последовательностей. Это означает, что генерируемые видео не только стабильны и не подвержены резким изменениям, но и сохраняют логичность и правдоподобность повествования во времени, что особенно важно для реалистичного и убедительного визуального контента.

Представленная работа демонстрирует стремление к устойчивости алгоритмов при генерации длинных видеопоследовательностей. Авторы предлагают метод Test-Time Correction (TTC), направленный на стабилизацию процесса стохастической выборки. Данный подход позволяет создавать более когерентные видео без необходимости переобучения модели, что соответствует фундаментальному принципу: пусть N стремится к бесконечности — что останется устойчивым? Как заметил Ян Лекун: «Машинное обучение — это не просто аппроксимация функций, а поиск инвариантных представлений». Именно к такому поиску и стремится TTC, обеспечивая надежность генерации даже при увеличении длительности видео, что особенно важно для долгосрочного прогнозирования и создания реалистичных визуальных последовательностей.
Куда же это всё ведёт?
Предложенный метод коррекции траектории выборки (Test-Time Correction) демонстрирует примечательную способность стабилизировать авторегрессионную генерацию видео, избегая необходимости переобучения модели. Однако, за кажущейся элегантностью решения скрывается фундаментальный вопрос: насколько допустимо вмешательство в стохастический процесс ради достижения когерентности? Иначе говоря, полученный результат — это истинное творчество алгоритма, или лишь искусственно наведённый порядок? Доказательство устойчивости такого вмешательства к незначительным возмущениям — задача, требующая пристального внимания.
Очевидным направлением дальнейших исследований представляется разработка методов оценки достоверности сгенерированных траекторий. Если результат нельзя воспроизвести с заданной точностью, то его ценность, с математической точки зрения, стремится к нулю. Необходимо исследовать, как TTC взаимодействует с различными архитектурами диффузионных моделей и как его можно адаптировать для задач, требующих генерации не только когерентных, но и семантически осмысленных видеопоследовательностей.
В конечном счёте, истинный прогресс в области генерации видео заключается не в увеличении длины сгенерированных фрагментов, а в создании алгоритмов, способных к самокоррекции и адаптации, алгоритмов, чья внутренняя логика прозрачна и доказуема. Просто “работает на тестах” — недостаточно. Необходима математическая красота и безупречная детерминированность.
Оригинал статьи: https://arxiv.org/pdf/2602.05871.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Автопилот нового поколения: Единая модель для понимания, планирования и предвидения
- Видеть детали: новый подход к мультимодальному восприятию
- Эхо разума: как итеративные модели учатся в цикле.
- Квантовые вычисления: линейная алгебра на службе симуляции
- Видеогенераторы и скрытые правила мира: смогут ли они понять невысказанное?
- Восстановление электронной структуры материалов с помощью машинного обучения
- Квантовая электродинамика и сильные корреляции: новый взгляд на взаимодействие света и материи
- Сердце под контролем ИИ: новый подход к диагностике
- Квантовые вычисления: Новый взгляд на оценку ресурсов
2026-02-07 15:44