Автор: Денис Аветисян
Представлен комплексный подход к оценке и улучшению поиска информации для систем, использующих искусственный интеллект в научных исследованиях.
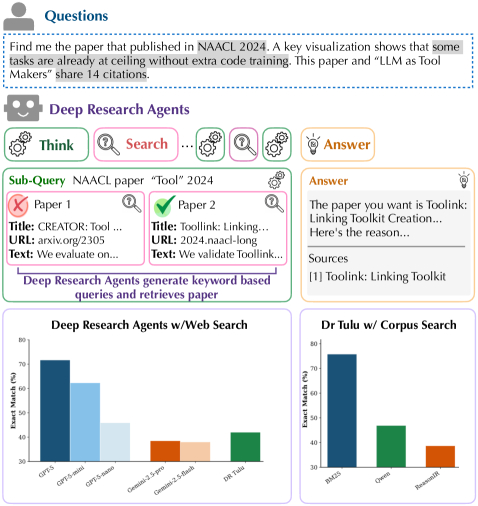
В статье представлен бенчмарк Sage для оценки эффективности систем поиска, а также показано, что масштабирование на уровне корпуса данных значительно повышает производительность систем, использующих большие языковые модели.
Несмотря на прогресс в области глубоких агентов для научных исследований, остается неясным, насколько эффективно современные системы поиска могут поддерживать сложные запросы, требующие логических рассуждений. В данной работе, посвященной ‘SAGE: Benchmarking and Improving Retrieval for Deep Research Agents’, представлен новый бенчмарк SAGE, состоящий из 1200 запросов и корпуса из 200 000 научных статей, для оценки эффективности поиска в контексте глубоких агентов. Полученные результаты показывают, что традиционные методы, такие как BM25, превосходят современные LLM-основанные системы поиска в задачах, требующих логического вывода, однако предложенный метод масштабирования на этапе тестирования, использующий LLM для обогащения метаданных документов, позволяет значительно улучшить производительность. Сможет ли подобный подход преодолеть ограничения LLM-основанных систем и обеспечить эффективный поиск в сложных научных задачах?
Преходящая сложность научного поиска
Традиционные методы информационного поиска, такие как BM25, часто оказываются неэффективными при обработке сложных научных запросов, требующих не просто сопоставления ключевых слов, а глубокого понимания контекста и логических связей. Недавние исследования показали, что в ряде случаев BM25 демонстрирует результаты на 30% превосходящие современные языковые модели (LLM) в задачах поиска научной информации. Этот парадоксальный результат указывает на то, что, несмотря на впечатляющие возможности LLM в обработке естественного языка, существующие системы поиска, основанные на более простых алгоритмах, все еще могут быть более эффективными в определенных сценариях, особенно когда требуется точное соответствие терминологии и избежание нерелевантных результатов, свойственных более «творческим» подходам LLM.
Современная научная литература характеризуется экспоненциальным ростом объема и сложности, что предъявляет качественно новые требования к системам поиска и анализа информации. Простого сопоставления ключевых слов уже недостаточно для эффективной работы с массивами данных, поскольку научные тексты часто содержат сложные аргументы, неявные связи и контекстуальные зависимости. Для адекватной обработки такой информации необходимы системы, способные к глубокому пониманию смысла, синтезу различных источников и выявлению скрытых закономерностей. Такие системы должны не просто находить документы, содержащие определенные термины, но и извлекать из них знания, строить логические цепочки и делать обоснованные выводы, имитируя процесс научного мышления.
Для адекватной оценки эффективности систем, предназначенных для работы со сложной научной информацией, необходимо переходить от простых тестов на извлечение фактов к более сложным бенчмаркам, проверяющим истинные способности к рассуждению. Традиционные методы оценки, фокусирующиеся на точном совпадении ключевых слов или прямом извлечении данных, оказываются недостаточными для выявления систем, способных к синтезу информации, логическому выводу и решению сложных научных задач. Новые критерии оценки должны включать задачи, требующие не просто поиска фактов, а анализа взаимосвязей между ними, выявления скрытых закономерностей и формулирования обоснованных выводов. Такой подход позволит более точно определить, какие системы действительно способны поддерживать ученых в процессе научных исследований и открытий, а не просто предоставлять им доступ к большому объему информации.
Глубокие исследовательские агенты: новый виток эволюции
Глубокие исследовательские агенты представляют собой новый подход к автоматизированному научному исследованию, стремящийся воспроизвести многоступенчатое рассуждение, характерное для работы ученых. В отличие от традиционных систем поиска информации, которые выдают результаты на основе ключевых слов, эти агенты способны разбивать сложные вопросы на последовательность более простых подзадач, итеративно уточнять поисковые запросы и синтезировать информацию из больших массивов научных публикаций. Целью является не просто предоставление релевантных документов, а формирование обоснованных ответов и выводов, аналогичных тем, которые делает исследователь в процессе анализа научной литературы. Данный подход позволяет автоматизировать части процесса научного открытия, сокращая время, необходимое для обзора литературы и выявления ключевых тенденций в определенной области знаний.
Агенты глубоких исследований используют LLM-основанные извлекатели (Retrievers) для итеративного уточнения поисковых запросов и синтеза информации из обширных корпусов научных публикаций. Процесс начинается с первоначального запроса, после чего извлекатель, обученный на базе больших языковых моделей, идентифицирует релевантные фрагменты текста. Затем LLM анализирует полученные данные, формулирует уточненные запросы, и цикл повторяется. Эта итеративная процедура позволяет агенту не просто находить документы, содержащие ключевые слова, но и извлекать, обобщать и синтезировать информацию из различных источников, обеспечивая более глубокое понимание исследуемой темы и выявление скрытых связей между научными работами.
Ключевым элементом функционирования агентов глубоких исследований является генерация подзапросов, позволяющая декомпозировать сложные исследовательские вопросы на последовательность более простых, управляемых шагов. Этот процесс предполагает автоматическое разбиение исходного запроса на ряд конкретных подвопросов, каждый из которых направлен на получение определенной части необходимой информации. Полученные ответы на подзапросы затем агрегируются и синтезируются для формирования ответа на исходный, комплексный вопрос. Использование подзапросов значительно повышает эффективность поиска и снижает вероятность получения нерелевантных результатов, поскольку позволяет агенту фокусироваться на конкретных аспектах проблемы на каждом этапе исследования.
Исследуя ландшафт LLM-основанного поиска
В настоящее время активно исследуются различные системы поиска информации, основанные на больших языковых моделях (LLM), предназначенные для задач научного поиска. К числу наиболее заметных относятся Promptriever, ReasonIR, LLM2Vec и GritLM. Каждая из этих систем использует различные подходы к построению векторных представлений документов и поиску релевантной информации. Promptriever использует возможности промпт-инжиниринга для формирования запросов, ReasonIR фокусируется на логическом выводе при сопоставлении запроса и документа, LLM2Vec применяет методы векторного представления, а GritLM использует генеративные модели декодера для улучшения качества поиска.
Различные LLM-основанные системы поиска информации отличаются подходами к построению векторных представлений и организации поиска. Некоторые методы, такие как Promptriever и ReasonIR, используют инструктивное обучение (instruction-tuning) для оптимизации LLM в качестве ретривера, что позволяет модели напрямую сопоставлять запросы с релевантными документами. Другие, например LLM2Vec и GritLM, применяют генеративные модели на основе декодера, где LLM генерирует векторные представления документов и запросов, а поиск осуществляется на основе близости этих векторов в векторном пространстве. Такой подход позволяет учитывать семантические нюансы и контекст, однако требует значительных вычислительных ресурсов для обучения и индексации.
Метод масштабирования на уровне корпуса (Corpus-Level Test-Time Scaling) демонстрирует потенциал для повышения эффективности поиска информации. Экспериментальные данные показывают, что применение данного подхода приводит к увеличению точности поиска на 8% при обработке коротких запросов и на 2% — для вопросов открытого типа. Это указывает на возможность улучшения результатов релевантного поиска за счет динамической адаптации моделей к специфике корпуса документов в процессе выполнения запроса.
Оценка производительности на эталоне Sage
Платформа Sage Benchmark представляет собой строгий инструмент для оценки способностей к рассуждению у современных исследовательских агентов, использующих глубокое обучение. Особенностью данной платформы является использование двух форматов вопросов: кратких, требующих конкретного ответа, и развернутых, предполагающих детальное объяснение и анализ. Такой подход позволяет всесторонне оценить не только скорость и точность получения информации, но и умение агентов логически мыслить, строить гипотезы и представлять результаты в связном и понятном виде. Благодаря разнообразию вопросов и строгости критериев оценки, Sage Benchmark служит надежным ориентиром для разработчиков и исследователей, стремящихся к созданию более интеллектуальных и эффективных систем искусственного интеллекта.
Исследование проводит сравнительный анализ возможностей передовых агентов искусственного интеллекта, таких как DR Tulu, GPT-5 и Gemini-2.5-Pro, в решении задач, представленных в бенчмарке Sage. В рамках тестирования была применена методика масштабирования на уровне корпуса данных, что позволило добиться значительного улучшения результатов. В частности, точность ответов на вопросы короткого формата увеличилась на 8%, а для вопросов, требующих развернутого ответа, — на 2%. Полученные данные демонстрируют эффективность данного подхода к оптимизации производительности и предоставляют ценную информацию для дальнейшего совершенствования алгоритмов и архитектур интеллектуальных агентов.
Проведенная оценка производительности на базе эталонного набора Sage предоставляет ценные сведения о сильных и слабых сторонах различных подходов к созданию интеллектуальных агентов. Анализ результатов, полученных от DR Tulu, GPT-5 и Gemini-2.5-Pro, позволяет выявить конкретные области, где каждая из моделей демонстрирует наибольший успех или испытывает трудности. Эти данные служат основой для дальнейшей оптимизации и совершенствования алгоритмов, направленных на повышение способности агентов к рассуждениям и решению сложных задач. Понимание этих нюансов крайне важно для направленного развития искусственного интеллекта и создания более эффективных и надежных систем.
Исследование, представленное в данной работе, подчеркивает важность адаптации систем поиска информации к сложным задачам, требующим глубокого анализа научных текстов. В контексте возрастающей роли LLM-агентов в научных исследованиях, способность эффективно извлекать релевантные знания становится критически важной. Как однажды заметил Алан Тьюринг: «Искусственный интеллект — это не попытка заменить человеческий интеллект, а дополнить его». В данном исследовании показано, что применение методов масштабирования на уровне корпуса позволяет значительно улучшить производительность систем поиска, что свидетельствует о возможности создания более эффективных инструментов для поддержки научных открытий. По сути, это подтверждает идею о том, что системы, подобно живым организмам, нуждаются в постоянной адаптации и развитии, чтобы сохранять свою функциональность и актуальность во времени.
Что же дальше?
Представленный анализ систем извлечения информации для интеллектуальных агентов, безусловно, выявляет закономерность, знакомую всякой сложной системе — трудности с задачами, требующими глубокого рассуждения. Неудивительно, что архитектуры, полагающиеся на поверхностные соответствия, спотыкаются там, где требуется истинное понимание. Время, однако, не стоит на месте, и масштабирование на уровне корпуса, продемонстрированное в работе, лишь отсрочивает неизбежное — устаревание текущих подходов.
Вопрос не в том, чтобы «улучшить» системы извлечения, а в том, чтобы признать их временный характер. Каждое нововведение, как и каждое здание, рано или поздно потребует переосмысления, адаптации или, в конечном итоге, замены. Более перспективным представляется не поиск идеальной архитектуры, а разработка методов, позволяющих системам адаптироваться к меняющимся требованиям и, возможно, даже предвидеть собственное устаревание.
Следующим этапом представляется исследование механизмов, позволяющих агентам не просто извлекать информацию, а синтезировать новые знания, формировать гипотезы и проверять их. Ведь в конечном итоге, ценность системы определяется не её способностью хранить информацию, а её способностью создавать её.
Оригинал статьи: https://arxiv.org/pdf/2602.05975.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Видеть детали: новый подход к мультимодальному восприятию
- Автопилот нового поколения: Единая модель для понимания, планирования и предвидения
- Квантовая электродинамика и сильные корреляции: новый взгляд на взаимодействие света и материи
- Сердце под контролем ИИ: новый подход к диагностике
- Квантовые вычисления: Новый взгляд на оценку ресурсов
- Видеогенераторы и скрытые правила мира: смогут ли они понять невысказанное?
- Потоки, ведущие к совершенству: новый подход к генеративным моделям
- Разум как отражение: новая архитектура интеллекта
- Восстановление электронной структуры материалов с помощью машинного обучения
2026-02-07 17:31