Автор: Денис Аветисян
Исследование раскрывает, как минималистичный алгоритм PMD-mean обеспечивает эффективную постобработку больших языковых моделей, предотвращая переобучение и повышая надежность.
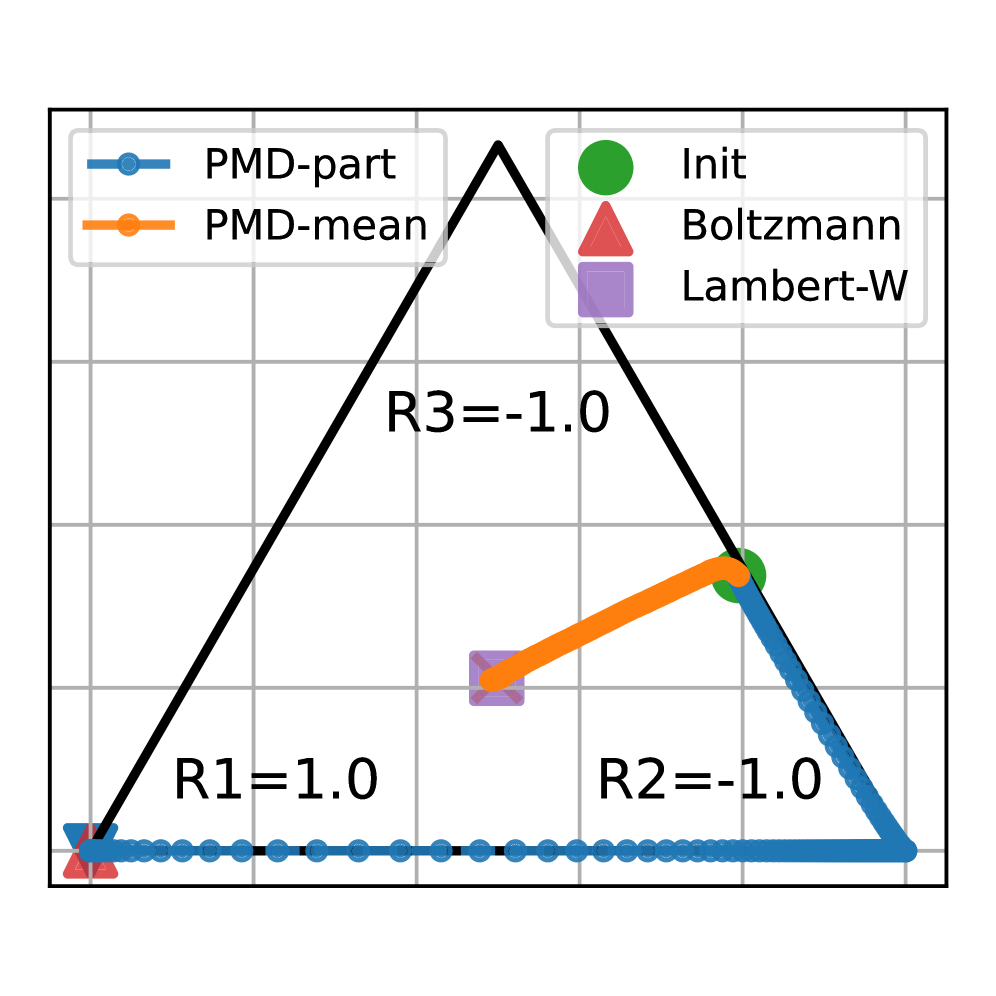
Анализ алгоритма PMD-mean показывает его эквивалентность методу зеркального спуска с комбинированным KL-χ2 регуляризатором, обеспечивающим неявную регуляризацию и улучшенную стабильность.
Несмотря на успехи обучения больших языковых моделей (LLM) с помощью обучения с подкреплением, точная оценка функции разделения в алгоритме зеркального спуска политики (PMD) остается сложной задачей при ограниченном количестве траекторий. В данной работе, посвященной ‘Approximation of Log-Partition Function in Policy Mirror Descent Induces Implicit Regularization for LLM Post-Training’, исследуется алгоритм PMD-mean, который аппроксимирует логарифм функции разделения средним вознаграждением, демонстрируя его эквивалентность зеркальному спуску с адаптивным смешанным KL - χ^2 регуляризатором. Полученные результаты показывают, что PMD-mean обеспечивает повышенную стабильность и устойчивость к ошибкам оценки, улучшая производительность на задачах логического вывода. Позволит ли данное понимание PMD-mean разработать более эффективные алгоритмы обучения с подкреплением для LLM и расширить границы их возможностей?
Стабилизация Языковых Моделей: Вызов Обновления Политики
Последующая настройка, или пост-тренировка, является критически важным этапом в приведении больших языковых моделей (LLM) к соответствию желаемому поведению и этическим нормам. Однако, несмотря на свою необходимость, данные методы часто демонстрируют нестабильность, приводящую к непредсказуемым результатам и ухудшению производительности. Эта нестабильность возникает из-за чувствительности LLM к даже незначительным изменениям в процессе обучения, особенно при попытке корректировки уже сформировавшихся паттернов генерации текста. Неустойчивость проявляется в виде резких скачков в вероятности определенных ответов, отклонении от заданных ограничений и даже полной деградации способности модели генерировать связный и осмысленный текст. Поэтому, разработка надежных и устойчивых методов пост-тренировки представляет собой одну из ключевых задач в области искусственного интеллекта.
Точное вычисление логарифма функции разделения является критическим препятствием при обучении больших языковых моделей, поскольку эта функция нормализует обновления политики и предотвращает её расхождение. Представьте себе, что модель пытается научиться избегать нежелательных ответов; обновления политики, направленные на это, должны быть правильно масштабированы, чтобы не привести к непредсказуемому поведению или полной потере полезных навыков. Z = \in t e^{-E(x)} dx — эта функция, по сути, определяет вероятность каждого возможного ответа модели, и её неточная оценка может привести к тому, что модель начнет генерировать совершенно нерелевантный или вредный контент. Неспособность точно оценить эту функцию приводит к нестабильности процесса обучения, заставляя модель колебаться между желаемым и нежелательным поведением, и требует разработки новых, более эффективных методов нормализации.
Традиционные методы аппроксимации логарифмической функции разделения, критически важной для стабилизации обновлений языковых моделей, сталкиваются с существенными ограничениями в плане масштабируемости. Вычислительные затраты, связанные с такими подходами, как методы Монте-Карло или вариационного вывода, быстро растут с увеличением размера модели и объема данных. Кроме того, многие упрощения, необходимые для практической реализации, вносят значительную смещенность в оценку, что может привести к неточным обновлениям политики и, как следствие, к ухудшению производительности или даже к расхождению модели. В результате, эффективное и точное вычисление логарифмической функции разделения остается сложной задачей, препятствующей широкому применению методов пост-обучения для больших языковых моделей и требующей разработки новых, более эффективных алгоритмов.
PMD-mean: Упрощенный Подход к Оптимизации Политики
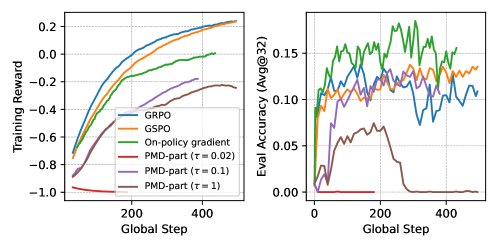
Метод PMD-mean вносит ключевое нововведение, заключающееся в аппроксимации логарифма функции разделения (log-partition function) посредством среднего значения вознаграждения. Традиционные методы требуют сложных вычислений для оценки этой функции, что существенно увеличивает вычислительные затраты при обучении больших языковых моделей (LLM). PMD-mean заменяет эти сложные вычисления на простую оценку математического ожидания среднего вознаграждения, что значительно снижает требуемые ресурсы и позволяет использовать более крупные размеры пакетов (batch sizes) при обучении. Данная аппроксимация не только упрощает процесс вычислений, но и обеспечивает стабильность обновления параметров модели, что является критически важным для эффективного обучения LLM.
Метод PMD-mean обеспечивает стабильное и эффективное обновление языковых моделей (LLM) за счет замены сложных вычислений на одно ожидаемое значение. Такой подход позволяет значительно увеличить размер пакета (batch size) данных, используемого при обучении, что приводит к ускорению процесса в 4.6 раза. Упрощение вычислений позволяет проводить более частые и масштабные обновления модели, что потенциально ускоряет процесс её настройки и согласования с заданными критериями. Увеличение размера пакета напрямую влияет на скорость сходимости алгоритма оптимизации.
Упрощение вычислений в PMD-mean позволяет существенно увеличить частоту и размер обновлений модели. Традиционные методы оптимизации политик требуют значительных вычислительных ресурсов, ограничивая возможность частого обновления параметров модели. PMD-mean, за счет снижения вычислительной сложности, позволяет выполнять обновления чаще и с использованием более крупных пакетов данных. Это, в свою очередь, потенциально ускоряет процесс выравнивания модели с заданными предпочтениями и целями, так как модель быстрее адаптируется к обратной связи и улучшает свою производительность на целевых задачах. Более частые обновления также могут способствовать более стабильному обучению и предотвращению расхождения модели от желаемого поведения.
Обеспечение Стабильности с Адаптивной Регуляризацией
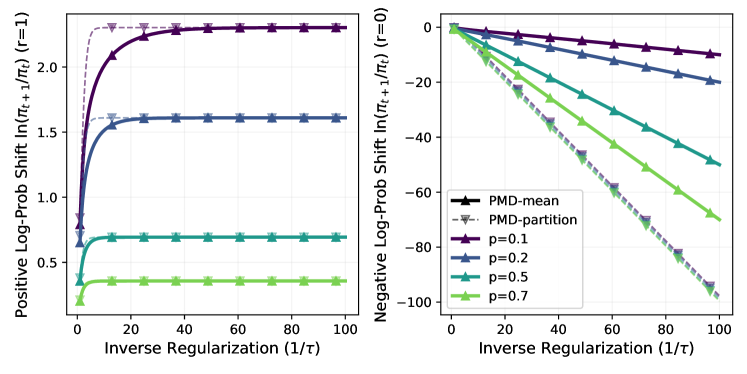
Метод PMD-mean использует смешанную KL-χ2 регуляризацию для адаптивного баланса между исследованием (exploration) и использованием (exploitation) в процессе обновления политики. KL-дивергенция (D_{KL}(π||π_{old})) ограничивает отклонение новой политики от старой, способствуя стабильности обучения, в то время как χ2-регуляризация штрафует за значительные изменения в распределении действий, поощряя исследование. Комбинирование этих двух регуляризаций позволяет PMD-mean динамически настраивать степень исследования и использования в зависимости от неопределенности в среде и прогресса обучения, что приводит к более эффективному и надежному обучению политики.
Функция преимущества играет ключевую роль в алгоритме PMD-mean, определяя направление обновления политики. Она количественно оценивает разницу между предсказанной и фактической наградой, позволяя агенту оценивать, насколько предпочтительно было совершено действие по сравнению со средним ожидаемым результатом. Более высокая функция преимущества указывает на то, что действие привело к значительно более высокой награде, чем ожидалось, и, следовательно, должно быть усилено в процессе обновления политики. Использование функции преимущества позволяет PMD-mean эффективно фокусироваться на действиях, которые приводят к улучшению результатов, тем самым оптимизируя процесс обучения и повышая общую производительность агента. Математически, функция преимущества обычно рассчитывается как A(s, a) = Q(s, a) - V(s), где Q(s, a) — ожидаемая награда за совершение действия a в состоянии s, а V(s) — ценность состояния s.
Теоретическая основа PMD-mean заключается в использовании функции Ламберта-W (Lambert-WW Function) для получения точных решений в процессе обновления политики. Данная функция позволяет аналитически выразить оптимальное обновление, избегая итерационных методов и обеспечивая сходимость алгоритма. В частности, функция Ламберта-W применяется для решения трансцендентного уравнения, возникающего при вычислении шага обновления, что позволяет получить явную формулу для обновления параметров политики. Это обеспечивает точное и эффективное вычисление обновления, W(x), в контексте алгоритма PMD-mean, гарантируя стабильность и предсказуемость поведения агента.
Эмпирическая Валидация и Производительность на Различных Моделях
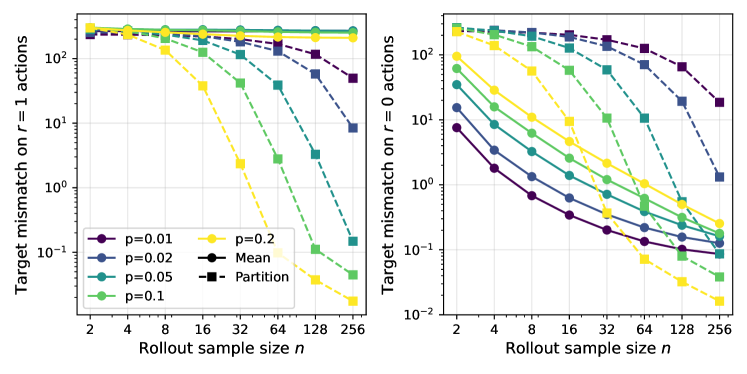
Исследование продемонстрировало универсальность метода PMD-mean посредством его применения к различным языковым моделям, включая Qwen2.5-7B и Qwen3-30B-A3B-Base. Данный подход успешно интегрировался в архитектуры моделей различного масштаба, подтверждая его адаптивность и эффективность вне зависимости от количества параметров. Результаты показали, что PMD-mean не требует значительной перенастройки для достижения оптимальной производительности на различных платформах, что делает его ценным инструментом для улучшения способностей языковых моделей в широком спектре задач и применений.
Исследование продемонстрировало эффективность предложенного метода на датасете DAPO-Math-17k, предназначенном для оценки способностей моделей в решении математических задач. Результаты показали, что улучшения в производительности наблюдаются при использовании моделей различных размеров — от небольших 7-параметровых до крупных 30-параметровых. Это указывает на то, что метод не зависит от конкретной архитектуры или масштаба модели, а представляет собой универсальный подход к повышению точности решения математических задач в области обработки естественного языка. Полученные данные подтверждают потенциал метода для широкого применения в различных системах искусственного интеллекта, требующих высокой точности математических вычислений.
Оценка метода PMD-mean на бенчмарке AIME продемонстрировала его эффективность в решении сложных математических задач. Результаты показали значительное улучшение показателей: для модели размером 7B достижен прирост в +2.6% в оценке AIME 2024, а для модели 30B — впечатляющие +14.6%. Данные результаты подтверждают, что PMD-mean способен существенно повысить производительность языковых моделей при решении математических задач, особенно в случае с более крупными моделями, где эффект от применения метода оказывается наиболее заметным. Это указывает на потенциал PMD-mean в качестве эффективного инструмента для улучшения способностей моделей к рассуждениям и решению задач, требующих логического мышления.
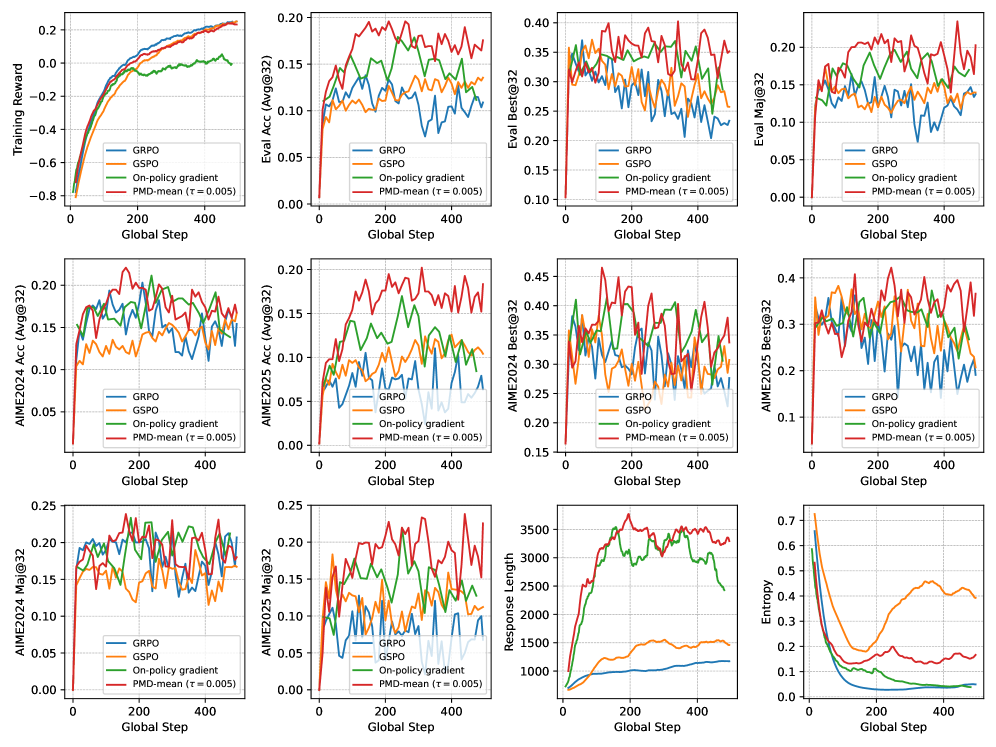
Исследование демонстрирует, что алгоритм PMD-mean, будучи минималистичным подходом к пост-обучению больших языковых моделей, обладает скрытой регуляризацией, эквивалентной методу зеркального спуска с комбинированным KL-χ2 регуляризатором. Этот механизм обеспечивает повышенную стабильность и устойчивость по сравнению со стандартными методами обучения. Как отмечал Дональд Дэвис: «Простота — высшая форма утонченности». Эта фраза прекрасно отражает суть работы, подчеркивая, что элегантное решение часто кроется в простоте и ясности структуры, где структура определяет поведение системы, а значит, и ее устойчивость. В данном случае, лаконичный алгоритм PMD-mean, благодаря своей внутренней структуре, демонстрирует неожиданно эффективные свойства регуляризации.
Что дальше?
Представленный анализ алгоритма PMD-mean обнажает его внутреннюю структуру, демонстрируя связь с зеркальным спуском и смешанным KL-χ2 регуляризатором. Однако, элегантность этой конструкции не должна заслонять фундаментальный вопрос: является ли регуляризация действительно необходимым злом, или же мы просто не можем создать системы, способные к самообучению без внешнего контроля? Масштабируется не серверная мощь, а ясность идей, и поиск минимально достаточного регуляризатора представляется задачей, требующей дальнейших исследований.
Следующим шагом видится изучение влияния различных параметров регуляризатора на обобщающую способность моделей. Вместо слепой оптимизации, необходимо понимать, как каждый параметр формирует ландшафт потерь и влияет на стабильность обучения. Это требует не просто эмпирических экспериментов, но и теоретического анализа, позволяющего предсказать поведение модели в различных условиях.
В конечном счете, LLM — это лишь часть сложной экосистемы, где каждая компонента взаимодействует с другими. Игнорирование этих взаимодействий приведет к созданию хрупких и непредсказуемых систем. Необходимо рассматривать обучение моделей не как изолированный процесс, а как эволюцию в рамках более широкой среды, где важны не только результаты, но и траектория, по которой они были достигнуты.
Оригинал статьи: https://arxiv.org/pdf/2602.05933.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Автопилот нового поколения: Единая модель для понимания, планирования и предвидения
- Видеть детали: новый подход к мультимодальному восприятию
- Потоки, ведущие к совершенству: новый подход к генеративным моделям
- Разум как отражение: новая архитектура интеллекта
- Эхо разума: как итеративные модели учатся в цикле.
- Квантовые вычисления: линейная алгебра на службе симуляции
- Восстановление электронной структуры материалов с помощью машинного обучения
- Квантовая электродинамика и сильные корреляции: новый взгляд на взаимодействие света и материи
- Видеогенераторы и скрытые правила мира: смогут ли они понять невысказанное?
2026-02-07 19:08