Автор: Денис Аветисян
Новый подход Context Forcing позволяет создавать реалистичные и последовательные видеосюжеты, решая проблему долгосрочной когерентности в генеративных моделях.
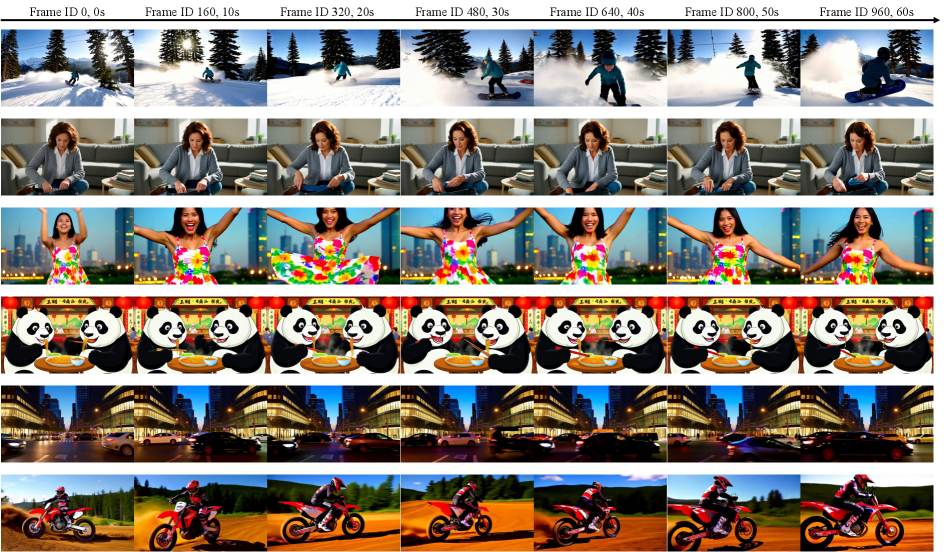
Исследователи предлагают метод дистилляции знаний от «учителя» с длинным контекстом к «ученику», используя медленную и быструю память для повышения стабильности генерации.
Попытки генерации длинных видеороликов часто сталкиваются с проблемой поддержания согласованности во времени из-за ограниченного контекста, доступного моделям. В работе ‘Context Forcing: Consistent Autoregressive Video Generation with Long Context’ предложен новый подход, основанный на дистилляции знаний от «учителя» с длинным контекстом к «ученику», что позволяет создавать более когерентные видеоролики. Ключевой особенностью является устранение несоответствия между учителем и учеником за счет использования «Slow-Fast Memory» для эффективного управления контекстом. Сможем ли мы с помощью подобных методов преодолеть ограничения существующих подходов и добиться действительно долгосрочной согласованности в генерации видео?
Проблема Долгосрочной Когерентности в Генерации Видео
Традиционные модели генерации видео сталкиваются со значительными трудностями при создании последовательностей большой длительности, проявляющимися в двух основных ошибках: “забывании” и “уходе от темы”. Ошибка “забывания” возникает, когда модель теряет информацию о начальных кадрах, что приводит к несогласованности в более поздних фрагментах видео. В то же время, “уход от темы” проявляется в постепенном отклонении от исходного замысла или стиля, приводя к непредсказуемым и нелогичным изменениям в генерируемом контенте. Эти проблемы обусловлены сложностью удержания долгосрочных зависимостей в видеопотоке, что требует от модели способности эффективно запоминать и использовать информацию из отдаленных кадров, что является вычислительно сложной задачей.
Проблема «Забывания и Смещения» в генерации видео возникает из-за фундаментальной сложности удержания долгосрочных зависимостей между кадрами без экспоненциального увеличения вычислительных затрат. Каждый кадр видео зависит от предыдущих, формируя сложную цепочку взаимосвязей, и для точного воссоздания последовательности модель должна «помнить» информацию на протяжении всего видео. Однако, чем длиннее видео, тем больше информации необходимо хранить и обрабатывать, что приводит к быстрому росту требований к памяти и вычислительной мощности. Это создает дилемму: либо модель жертвует точностью и «забывает» важные детали на протяжении длительного времени, что приводит к несогласованности, либо пытается удержать всю информацию, что становится практически невыполнимым с точки зрения вычислительных ресурсов. Таким образом, поддержание когерентности в длинных видеопоследовательностях остается сложной задачей, требующей инновационных подходов к управлению информацией и оптимизации вычислительных процессов.
Несмотря на впечатляющую производительность, современные методы генерации видео, такие как Diffusion Transformers (DiTs), сталкиваются с серьезными вычислительными ограничениями при создании длинных последовательностей. Суть проблемы заключается в необходимости хранения и обработки огромного объема информации о предыдущих кадрах — так называемого Key-Value кэша. Вследствие этого, эффективная длительность хранения этого кэша, определяющая способность модели поддерживать когерентность на протяжении всего видео, обычно ограничена всего лишь 1.5-9.2 секундами. Это означает, что модель, по сути, «забывает» детали начальных кадров, что приводит к потере согласованности и логичности в более длинных видеороликах, что делает создание действительно продолжительных и правдоподобных видеозаписей крайне сложной задачей.

Контекстное Принуждение: Рамки Надежного Переноса Знаний
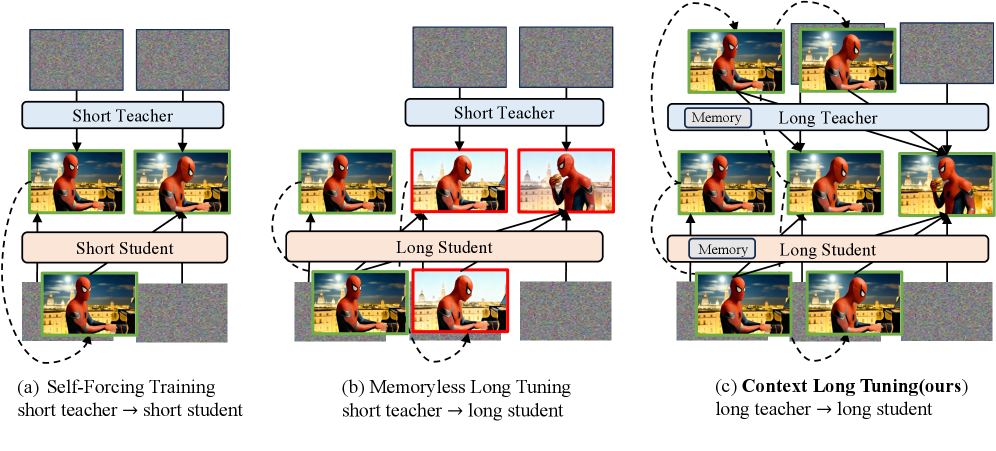
Предлагается методика “Context Forcing”, разработанная для решения проблемы несоответствия между моделями-учителями и моделями-учениками в задачах генерации каузальных видеороликов большой длительности. Несоответствие возникает из-за сложности передачи знаний о долгосрочных зависимостях и причинно-следственных связях. “Context Forcing” направлена на преодоление этой проблемы путем структурированного переноса знаний от более мощной модели-учителя к менее сложной модели-ученику, что позволяет последней эффективно моделировать и генерировать видеоролики с последовательными и логически связанными событиями на протяжении длительного времени.
В основе подхода Context Forcing лежит использование “Long-Context Teacher” — модели-учителя, способной эффективно обрабатывать и запоминать информацию на протяжении длительных временных интервалов. Знания, накопленные этой моделью, передаются (дистиллируются) в модель-ученик, что позволяет последнему значительно улучшить способность к логическому мышлению и построению причинно-следственных связей на больших временных масштабах. Данный процесс обучения, основанный на передаче знаний от учителя к ученику, направлен на преодоление проблемы несоответствия между способностями моделей к обработке долгосрочных зависимостей и необходимостью генерации последовательностей с протяжённым контекстом.
Для эффективного захвата как непосредственного локального контекста, так и ключевых кадров с высокой энтропией, в рамках данной архитектуры используется подход “Slow-Fast Memory”. Это позволяет модели сохранять информацию в Key-Value кэше в течение 20+ секунд, обеспечивая доступ к релевантным данным на протяжении длительных последовательностей видео. Архитектура предполагает раздельное хранение информации: быстродоступная память для немедленного контекста и медленная память для ключевых кадров, что оптимизирует использование ресурсов и повышает эффективность долгосрочного рассуждения.
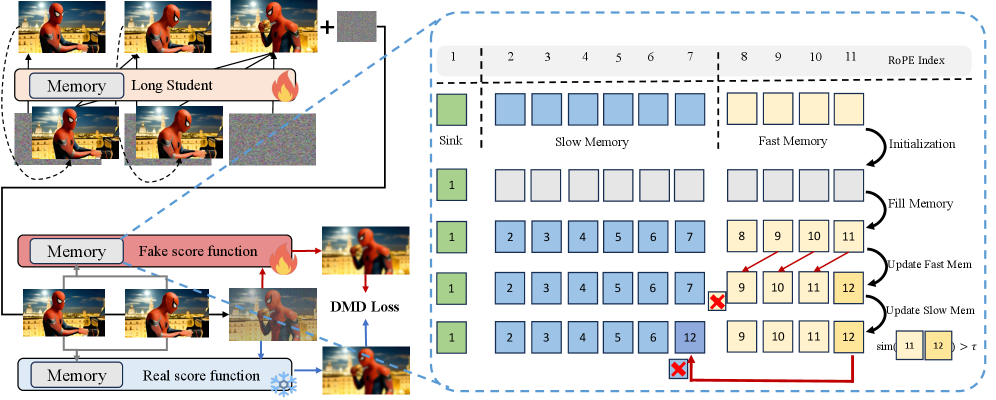
Рассечение Архитектуры Медленная-Быстрая Память
Архитектура “Медленная-Быстрая Память” объединяет в себе “Быструю Память”, реализованную как кольцевой FIFO-буфер для хранения недавней информации, и “Медленную Память” для удержания долгосрочного контекста. “Быстрая Память” обеспечивает быстрый доступ к последним данным, необходимым для обработки текущего запроса, в то время как “Медленная Память” хранит более широкий контекст, позволяя модели учитывать предшествующую информацию, выходящую за рамки непосредственной истории. Такая комбинация позволяет эффективно обрабатывать длинные последовательности, сохраняя при этом вычислительную эффективность за счет ограниченного размера “Быстрой Памяти” и избирательного использования “Медленной Памяти” для релевантной информации.
Ключевыми компонентами архитектуры Slow-Fast Memory являются механизм «Attention Sink» и кэш «KV Cache». Attention Sink стабилизирует процесс внимания, предотвращая его расхождение при обработке длинных последовательностей. Он функционирует как точка фокусировки, обеспечивая согласованность внимания на протяжении всей последовательности. KV Cache (ключ-значение кэш) служит для эффективного извлечения контекста, сохраняя ранее вычисленные ключи и значения, что позволяет избежать повторных вычислений при обращении к предыдущим данным. Это значительно ускоряет процесс обработки и снижает вычислительные затраты, особенно при работе с большими объемами данных.
Архитектура, использующая ‘Bounded Positional Encoding’ (ограниченное позиционное кодирование), предназначена для повышения стабильности при обработке длинных последовательностей. В отличие от стандартного позиционного кодирования, которое может испытывать трудности с обобщением на последовательности, превышающие длину обучающего набора, данная реализация ограничивает значения позиционных кодировок определенным диапазоном. Это позволяет модели более эффективно экстраполировать информацию на новые, более длинные последовательности, предотвращая затухание градиентов и обеспечивая более устойчивое внимание к релевантным частям контекста. Ограничение значений позиционного кодирования также способствует уменьшению вычислительной сложности и повышению эффективности использования памяти.
Дистилляция Знаний и Надежные Методы Обучения
Для эффективной передачи способностей моделирования долгосрочных зависимостей от учителя к ученику используется метод «Contextual Distribution Matching Distillation». Данный подход предполагает сопоставление распределений контекстных представлений, генерируемых учителем и учеником, что позволяет ученику имитировать способность учителя к удержанию и использованию информации из предыдущих временных шагов. В процессе обучения минимизируется расхождение между этими распределениями, что обеспечивает более точную передачу знаний о долгосрочных зависимостях и улучшает производительность ученика в задачах, требующих анализа последовательностей данных.
Метод Error-Recycling Fine-Tuning (ERFT) повышает устойчивость модели за счет намеренного внесения реалистичных, накапливающихся ошибок в контекст, предоставляемый учителю. В процессе обучения ERFT учитель намеренно подвергается воздействию симулированных ошибок, отражающих типичные неточности, возникающие в реальных условиях эксплуатации. Это позволяет учителю научиться генерировать более надежные прогнозы даже при наличии входных данных, содержащих ошибки, и, следовательно, передавать эту устойчивость студенческой модели в процессе дистилляции знаний. Внедрение накопленных ошибок в контекст учителя создает более сложный и реалистичный сценарий обучения, способствуя улучшению обобщающей способности и повышению надежности системы в целом.
Обучение и оценка предложенных методов — Contextual Distribution Matching Distillation и Error-Recycling Fine-Tuning (ERFT) — проводились на нескольких наборах данных для видеоаналитики, включая ‘Sekai’, ‘Ultravideo’ и ‘VidProM’. Для стандартизированной оценки производительности и надежности моделей использовался бенчмарк ‘VBench’, позволяющий сравнивать результаты с другими подходами в данной области. Наборы данных ‘Sekai’, ‘Ultravideo’ и ‘VidProM’ характеризуются различной сложностью и содержанием, что обеспечивает всестороннюю проверку эффективности предложенных техник.

Перспективы и Широкие Последствия
Предложенный подход демонстрирует значительный прогресс в генерации видео длинных последовательностей, открывая новые горизонты для создания более реалистичных и захватывающих виртуальных опытов. Благодаря возможности последовательно и когерентно создавать видеофрагменты продолжительностью, ранее недоступной, появляется возможность моделировать сложные сценарии и взаимодействия. Это особенно важно для приложений, требующих правдоподобной симуляции, таких как виртуальная реальность, интерактивные игры и обучение с использованием имитационных моделей. Повышенная реалистичность и плавность генерируемого видео способствуют более глубокому погружению пользователя и повышают эффективность виртуальных взаимодействий, что делает предложенную технологию перспективной для широкого спектра применений, направленных на улучшение пользовательского опыта и расширение возможностей визуальной коммуникации.
Предложенная архитектура обладает значительным потенциалом для применения в различных областях, включая автономное вождение, робототехнику и создание контента. В контексте беспилотных автомобилей, система способна генерировать реалистичные и последовательные видеопоследовательности, что критически важно для обучения моделей восприятия и принятия решений в сложных дорожных условиях. В робототехнике, данная технология позволит роботам лучше понимать окружающую среду и прогнозировать действия других объектов, повышая безопасность и эффективность их работы. Кроме того, в сфере создания контента, архитектура открывает новые возможности для автоматической генерации видеоматериалов, сокращая затраты и время на производство, а также предоставляя инструменты для создания уникального и персонализированного контента.
Дальнейшие исследования направлены на расширение архитектуры модели для генерации еще более длинных видеопоследовательностей, что позволит создавать контент с повышенной детализацией и реалистичностью. Параллельно ведется поиск новых методов эффективной передачи знаний между различными слоями сети и моделями, что позволит значительно сократить время обучения и потребление ресурсов. Особое внимание уделяется разработке алгоритмов, способных к адаптации и обучению на ограниченном объеме данных, что откроет возможности применения данной технологии в условиях ограниченной вычислительной мощности и нехватки размеченных данных. Успешная реализация этих направлений позволит значительно расширить сферу применения модели, включая создание сложных виртуальных миров и реалистичных симуляций.

Представленная работа демонстрирует стремление к математической чистоте в области генерации видео, что находит отклик в словах Дэвида Марра: «Вычисление — это не просто получение правильного ответа, а доказательство его правильности». Разработанный подход Context Forcing, направленный на обеспечение долгосрочной согласованности генерируемого видео, представляет собой попытку формализации процесса генерации. Особенно важно, что использование дистилляции знаний от «учителя» к «ученику» модели, а также методы, такие как Slow-Fast Memory и Error-Recycling Fine-Tuning, служат не просто инструментами улучшения результатов, а попыткой создать алгоритм, который можно обосновать с математической точки зрения. Таким образом, исследование акцентирует внимание на необходимости доказательства корректности алгоритма, а не просто на достижении видимых результатов на тестовых данных.
Куда Далее?
Представленная работа, безусловно, демонстрирует прогресс в вопросе когерентности при генерации видео, однако истинная проблема, как это часто бывает, лишь слегка приоткрыта. Успех метода Context Forcing, основанный на дистилляции знаний, поднимает вопрос: не является ли сама постановка задачи — обучение модели предсказывать следующие кадры — фундаментально несовершенной? В конечном счете, видео — это не просто последовательность пикселей, а сложная структура, определяемая не только прошлым, но и ожидаемым будущим. Попытки “научить” модель предвидеть это будущее, используя лишь прошлое, напоминают попытки построить вечный двигатель.
Следующим логичным шагом представляется отказ от чисто каузального подхода. Необходимо исследовать возможности интеграции в архитектуру моделей механизмов, позволяющих учитывать не только предыдущие кадры, но и некоторую форму “внутренней модели” мира, определяющей вероятные сценарии развития событий. Ключевым вопросом здесь является разработка эффективных методов представления и обновления этой “модели”, а также способов ее согласования с наблюдаемыми данными. Иначе говоря, требуется выйти за рамки простого предсказания и перейти к пониманию.
Очевидно, что увеличение размера контекста и совершенствование алгоритмов дистилляции — это лишь временные меры. Истинная элегантность, как всегда, кроется в простоте и непротиворечивости. Необходимо искать решения, которые будут не просто “работать”, но и доказуемо соответствовать фундаментальным принципам восприятия и понимания видеоинформации. Иначе, мы рискуем построить сложную конструкцию, которая лишь имитирует разум, но не обладает им.
Оригинал статьи: https://arxiv.org/pdf/2602.06028.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Автопилот нового поколения: Единая модель для понимания, планирования и предвидения
- Видеть детали: новый подход к мультимодальному восприятию
- Потоки, ведущие к совершенству: новый подход к генеративным моделям
- Разум как отражение: новая архитектура интеллекта
- Эхо разума: как итеративные модели учатся в цикле.
- Квантовые вычисления: линейная алгебра на службе симуляции
- Восстановление электронной структуры материалов с помощью машинного обучения
- Квантовая электродинамика и сильные корреляции: новый взгляд на взаимодействие света и материи
- Видеогенераторы и скрытые правила мира: смогут ли они понять невысказанное?
2026-02-07 22:27