Автор: Денис Аветисян
Исследователи представляют V-Retrver — систему, которая позволяет языковым моделям самостоятельно находить и анализировать визуальные доказательства для повышения точности поиска.
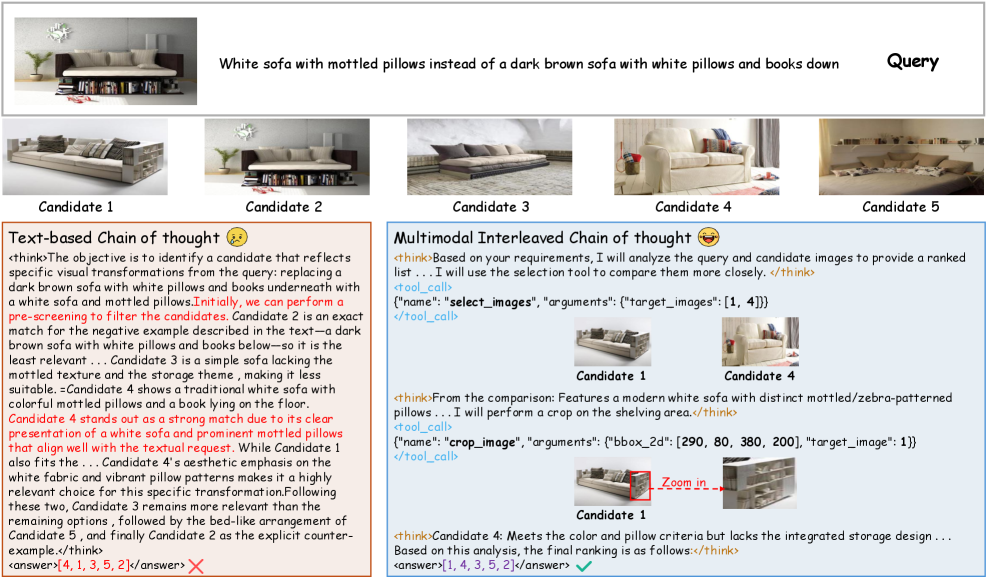
Предложен фреймворк V-Retrver, использующий агентный подход и обучение с подкреплением для улучшения мультимодального поиска за счет активного сбора визуальных доказательств.
Несмотря на успехи больших мультимодальных языковых моделей в задачах поиска информации, существующие подходы часто полагаются на статичные визуальные представления, упуская возможность активной верификации визуальных доказательств. В данной работе, посвященной разработке фреймворка ‘V-Retrver: Evidence-Driven Agentic Reasoning for Universal Multimodal Retrieval’, предложен новый подход, рассматривающий мультимодальный поиск как процесс агентного рассуждения, основанного на визуальном анализе. V-Retrver позволяет модели выборочно извлекать визуальные доказательства с помощью внешних инструментов, сочетая генерацию гипотез и целенаправленную визуальную верификацию. Способствует ли такой подход к построению более надежных и обобщающих мультимодальных систем поиска, способных эффективно справляться с неоднозначными визуальными данными?
Проблема Мультимодального Рассуждения
Традиционные методы поиска информации сталкиваются с серьезными трудностями при обработке мультимодальных данных, объединяющих различные типы информации, такие как текст и изображения. Сложность заключается в том, что эти методы часто разрабатывались для работы с однородными данными, например, только с текстом, и не способны эффективно учитывать взаимосвязи между различными модальностями. Это приводит к тому, что релевантные результаты могут быть упущены, поскольку поисковые системы не могут правильно интерпретировать и сопоставить визуальную информацию с текстовыми запросами. В результате, доступ к информации становится менее эффективным, а пользователям приходится тратить больше времени и усилий на поиск нужных данных в условиях растущего объема мультимедийного контента.
Применение трансформаторных моделей к мультимодальным задачам, несмотря на их впечатляющие возможности, сталкивается со значительными вычислительными трудностями. Увеличение размера моделей и объемов данных, необходимых для эффективной обработки визуальной и текстовой информации, приводит к экспоненциальному росту требуемых ресурсов. Это ограничивает глубину рассуждений, которые модель способна выполнить, поскольку сложные логические выводы требуют значительных вычислительных затрат. В результате, даже самые современные архитектуры могут испытывать трудности при анализе сложных мультимодальных сцен и установлении тонких связей между различными модальностями, что снижает их эффективность в задачах, требующих глубокого понимания и обобщения информации. Поиск эффективных методов масштабирования и оптимизации трансформаторных моделей для работы с мультимодальными данными остается актуальной задачей в области искусственного интеллекта.
Существенным препятствием в современных системах поиска информации является неспособность эффективно интегрировать визуальные данные в процесс извлечения релевантных результатов. Традиционные методы, ориентированные преимущественно на текстовые запросы, зачастую игнорируют богатый контекст, содержащийся в изображениях и видео. Это приводит к тому, что системы упускают важные детали и предоставляют неполные или неточные ответы. Исследования показывают, что включение визуальной информации может значительно повысить точность и релевантность поиска, особенно в задачах, требующих понимания сложных взаимосвязей между текстом и изображениями. Разработка алгоритмов, способных эффективно анализировать и интегрировать визуальные данные, представляет собой ключевую задачу для улучшения качества систем поиска и обеспечения более полного доступа к информации.

V-Retriever: Рассуждение, Основанное на Доказательствах
V-Retrver использует многоступенчатый конвейер извлечения информации, начинающийся с грубой фильтрации и постепенно переходящий к более детальному анализу. Первоначально, система идентифицирует большой набор потенциально релевантных элементов, основываясь на общих признаках. Затем, этот набор последовательно сужается посредством нескольких этапов фильтрации, в ходе которых применяются более строгие критерии отбора. Такой подход позволяет значительно снизить вычислительные затраты и время обработки, поскольку детальный анализ выполняется только над ограниченным числом наиболее вероятных кандидатов, что повышает общую эффективность системы.
В основе V-Retrver лежит механизм переплетенного рассуждения типа «Цепочка мыслей» (Chain-of-Thought), который обеспечивает бесшовную интеграцию текстовой и визуальной информации. Этот подход предполагает последовательное применение логических шагов, при этом каждая стадия рассуждений опирается как на текстовые данные, так и на анализ визуальных элементов. В процессе рассуждений система динамически переключается между обработкой текста и изображений, извлекая релевантные сведения из обоих источников и комбинируя их для формирования обоснованных ответов. Такая интеграция позволяет V-Retrver учитывать взаимосвязь между визуальным контекстом и текстовым содержанием, что повышает точность и надежность принимаемых решений.
В основе работы V-Retrver лежит активное использование внешних визуальных инструментов, в частности SELECT-IMAGE и ZOOM-IN, для проверки и подтверждения доказательств. SELECT-IMAGE позволяет системе выделять конкретные области изображения, релевантные заданному вопросу, для более детального анализа. Инструмент ZOOM-IN, в свою очередь, обеспечивает увеличение выбранных фрагментов изображения, что позволяет выявить детали, которые могли быть упущены при общем просмотре. Использование этих инструментов не является пассивным; система активно инициирует их использование в процессе рассуждений, что повышает точность и надежность извлеченных данных и обоснованность принимаемых решений.

Обучение с Учетом Сложности: К Надежному Рассуждению
Обучение модели V-Retrver осуществляется по трехэтапной программе: начальный этап — Cold-Start, далее — Fine-Tuning с использованием метода отбора траекторий (Rejection Sampling), и завершающий этап — оптимизация политики, ориентированная на доказательства (Evidence-Aligned Policy Optimization). Данный подход позволяет последовательно улучшать способность модели к рассуждениям, начиная с базового уровня и постепенно повышая надежность и точность генерации ответов. Каждый этап фокусируется на конкретных аспектах обучения, что обеспечивает комплексное развитие навыков модели и максимизирует ее производительность.
Метод отбора траекторий (Rejection Sampling Fine-Tuning) представляет собой этап дообучения модели, направленный на повышение надежности процесса рассуждений. В ходе этого этапа генерируются различные последовательности шагов решения задачи, после чего отбираются только те, которые соответствуют высоким стандартам качества, определяемым на основе внутренней оценки согласованности и логической корректности. Отбраковка низкокачественных траекторий позволяет предотвратить распространение ошибок на последующих этапах, снижая вероятность получения неверных или недостоверных результатов и повышая общую стабильность и предсказуемость работы модели.
Оптимизация политики, ориентированная на доказательства, представляет собой этап обучения, на котором модель поощряется за проявление автономности (agentic behavior) в процессе использования визуальной верификации. Данный метод подразумевает вознаграждение модели за действия, которые эффективно используют визуальные данные для подтверждения или опровержения гипотез, что позволяет максимизировать производительность и повысить надежность принимаемых решений. Система оценки основывается на степени соответствия действий модели визуальным доказательствам, полученным из окружающей среды, что способствует развитию способности к обоснованному и подтвержденному визуально рассуждению.

Эмпирические Результаты и Прирост Производительности
Оценка модели на бенчмарке M-BEIR продемонстрировала существенный прирост производительности по сравнению с существующими мультимодальными моделями поиска информации. Средний показатель Recall, достигаемый моделью, составил 69.7%, что свидетельствует о значительно улучшенной способности находить релевантные данные в разнообразных мультимедийных запросах. Этот результат подтверждает эффективность предложенного подхода к объединению различных модальностей данных для более точного и полного поиска, что особенно важно в задачах, требующих анализа изображений и текста одновременно.
В ходе оценки модели V-Retrver на общепринятых бенчмарках мультимодального поиска информации были получены значительно улучшенные показатели Recall@K. В частности, модель продемонстрировала превосходство над наиболее сильным конкурентом, U-MARVEL-7B, на 4.9 процентных пункта. Данный результат указывает на повышенную эффективность V-Retrver в извлечении релевантных данных из мультимодальных источников, что свидетельствует о её способности более точно соответствовать информационным потребностям пользователей и предоставлять более полные и уместные ответы на запросы.
В ходе оценки на бенчмарке CIRCO, модель V-Retrver продемонстрировала значительное превосходство в точности поиска релевантной информации. Её показатель MAP@5 достиг значения 48.2%, что существенно превышает результаты, показанные другими моделями — MM-Embed-7B (35.5) и LamRA-7B (42.8). Этот результат указывает на способность V-Retrver более эффективно ранжировать и извлекать наиболее подходящие данные из мультимодальных источников, обеспечивая повышенную информативность и точность поиска по сравнению с существующими решениями.
В ходе оценки на бенчмарке GeneCIS, система V-Retrver продемонстрировала значительное превосходство в точности извлечения информации. Достигнутый показатель Recall@K составил 30.7%, что на 5.9 процентных пункта выше результата, показанного моделью LamRA-7B (24.8%). Этот результат указывает на повышенную эффективность V-Retrver в поиске релевантных данных в сложных биологических задачах, где точное извлечение информации имеет решающее значение для дальнейших исследований и открытий. Превосходство в точности извлечения подчеркивает потенциал системы для применения в областях, связанных с геномикой и биоинформатикой.

Перспективы Развития: К Интеллектуальным Мультимодальным Системам
Исследования в области визуальных инструментов будущего направлены на расширение их возможностей для решения более сложных задач, требующих логического вывода и анализа. Вместо простого поиска изображений по ключевым словам, разрабатываются системы, способные понимать взаимосвязи между объектами на картинке, определять причинно-следственные связи и делать обоснованные выводы. Это предполагает создание алгоритмов, имитирующих когнитивные процессы человека, таких как абстрактное мышление и аналогия. Успешная реализация этих технологий позволит создавать интеллектуальные системы, способные решать задачи, которые ранее были доступны только человеку, например, диагностику заболеваний по медицинским изображениям или анализ сложных инженерных чертежей. Дальнейшее развитие этих инструментов обещает революционизировать области, где визуальная информация играет ключевую роль.
Исследования показывают значительный потенциал адаптации архитектуры V-Retrver, изначально разработанной для визуального поиска, к обработке и поиску информации в других модальностях, таких как аудио и видео. Перенос принципов, лежащих в основе V-Retrver — эффективное кодирование информации и поиск релевантных фрагментов на основе семантического сходства — позволяет создавать мультимодальные системы, способные объединять и анализировать данные из различных источников. Это открывает возможности для разработки интеллектуальных систем, способных понимать контекст аудио- и видеоматериалов, находить соответствующие фрагменты и предоставлять пользователям более точные и релевантные результаты поиска, выходя за рамки простого текстового поиска и учитывая содержание визуальных и звуковых данных.
Разработка адаптивных и персонализированных мультимодальных систем поиска информации представляет собой перспективное направление, способное значительно улучшить пользовательский опыт и эффективность доступа к знаниям. Вместо универсальных алгоритмов, подобные системы будут учитывать индивидуальные предпочтения, контекст запроса и историю взаимодействия с информацией, формируя поисковые результаты, наиболее релевантные конкретному пользователю. Это достигается за счет использования методов машинного обучения, позволяющих системе “обучаться” на данных о поведении пользователя и адаптироваться к его потребностям. Персонализация может включать учет визуального стиля, предпочитаемых форматов представления данных, а также специфических интересов, что приведет к более интуитивному и эффективному поиску, а также к снижению информационного перегруза.
Представленная работа демонстрирует стремление к созданию алгоритмов, не просто успешно функционирующих на заданном наборе данных, но и обладающих внутренней логической непротиворечивостью. V-Retrver, используя принцип активного поиска визуальных доказательств, воплощает идею о том, что истинная производительность системы определяется не количеством обработанных данных, а глубиной и точностью рассуждений. Как однажды заметил Джеффри Хинтон: «Я считаю, что лучший способ научить машину чему-то — это дать ей возможность задавать вопросы и учиться на ответах». Этот подход перекликается с концепцией Evidence-Aligned Learning, предложенной в статье, где акцент делается на проверке и обосновании каждого шага рассуждений, что является необходимым условием для создания действительно надежных и обобщающих систем.
Куда же дальше?
Представленная работа, безусловно, демонстрирует потенциал активного сбора визуальных доказательств для улучшения мультимодального поиска. Однако, следует помнить, что элегантность алгоритма не измеряется количеством «рабочих» примеров, а его математической доказуемостью. Пока что, V-Retrver представляет собой скорее эмпирический успех, чем строго обоснованное решение. Необходимо более глубокое исследование границ применимости и условий, при которых активный сбор информации действительно приводит к устойчивому улучшению, а не просто маскирует недостатки базовой модели.
Очевидным направлением дальнейших исследований является формализация процесса выбора инструментов и стратегий сбора доказательств. Оптимизация без анализа — самообман и ловушка для неосторожного разработчика. Необходимо перейти от эвристических подходов к более строгим методам, возможно, используя принципы байесовского вывода или теории принятия решений, чтобы гарантировать, что собранные доказательства действительно релевантны и снижают неопределенность.
Наконец, важно рассмотреть вопрос о масштабируемости и вычислительной сложности предложенного подхода. Активный сбор доказательств может потребовать значительных ресурсов, что ограничивает его применение в реальных сценариях. Разработка более эффективных алгоритмов и методов оптимизации является критически важной задачей для будущего мультимодального поиска.
Оригинал статьи: https://arxiv.org/pdf/2602.06034.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Автопилот нового поколения: Единая модель для понимания, планирования и предвидения
- Видеть детали: новый подход к мультимодальному восприятию
- Восстановление электронной структуры материалов с помощью машинного обучения
- Видеогенераторы и скрытые правила мира: смогут ли они понять невысказанное?
- Квантовая электродинамика и сильные корреляции: новый взгляд на взаимодействие света и материи
- Эхо разума: как итеративные модели учатся в цикле.
- Квантовые вычисления: линейная алгебра на службе симуляции
- Сердце под контролем ИИ: новый подход к диагностике
- Разум как отражение: новая архитектура интеллекта
2026-02-08 00:10