Автор: Денис Аветисян
Новый подход позволяет извлекать определения ключевых понятий из научных статей, значительно упрощая процесс анализа и систематизации информации.
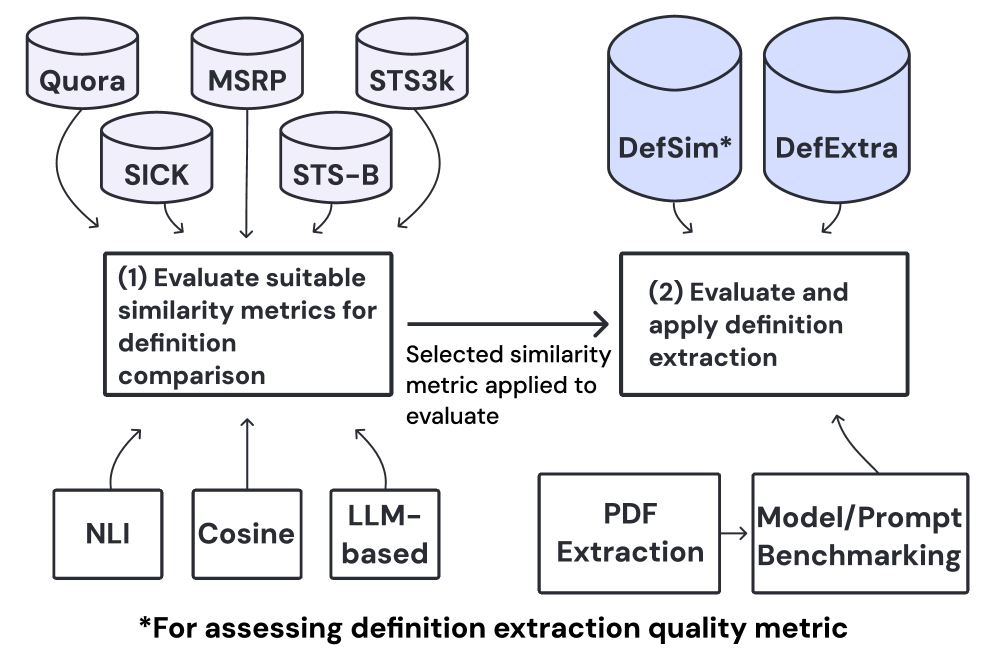
Представлена система SciDef, использующая большие языковые модели для автоматического извлечения определений из научной литературы, а также новые наборы данных для оценки эффективности.
Несмотря на фундаментальную роль определений в научной работе, экспоненциальный рост публикаций затрудняет их систематический поиск. В данной статье представлена система ‘SciDef: Automating Definition Extraction from Academic Literature with Large Language Models’, предназначенная для автоматизированного извлечения определений из научной литературы. Проведенные тесты на новых наборах данных DefExtra и DefSim показали, что многоступенчатые запросы и оптимизация с помощью DSPy значительно повышают точность извлечения. Не ограничиваясь просто поиском определений, возникает вопрос: как эффективно отбирать наиболее релевантные из них, учитывая склонность моделей к избыточному генерированию?
Раскрытие Знания: Вызовы и Возможности Определений
Научная литература представляет собой колоссальный массив знаний, однако извлечение точных определений из этих текстов остается серьезным препятствием для автоматизированного открытия новых знаний. Объем и сложность научных публикаций постоянно растут, что делает ручной сбор и систематизацию определений практически невозможным. Автоматические системы сталкиваются с трудностями в понимании контекста, неоднозначности терминологии и эволюции научных понятий. Неспособность точно определить ключевые термины ограничивает возможности создания полных и достоверных баз знаний, необходимых для прогресса в различных областях науки и техники. В результате, автоматизированный анализ и интерпретация научных данных замедляется, а потенциальные открытия могут оставаться незамеченными.
Традиционные методы извлечения определений из научной литературы сталкиваются с серьезными трудностями, обусловленными сложностью и неоднозначностью научного языка. Научные тексты часто используют специализированную терминологию, метафоры и имплицитные значения, которые сложно интерпретировать алгоритмам. Более того, определения в науке не статичны — они могут изменяться и уточняться по мере развития исследований. Это приводит к тому, что автоматически построенные базы знаний оказываются неполными или содержат устаревшие сведения, что снижает их ценность для дальнейшего анализа и открытий. Неспособность учесть динамичность определений и лингвистические особенности научной коммуникации является ключевым препятствием на пути к созданию точных и актуальных баз данных знаний.
Большие Языковые Модели: Новый Подход к Извлечению Определений
Большие языковые модели (БЯМ) демонстрируют выдающиеся способности к пониманию и генерации естественного языка, что делает их перспективными кандидатами для автоматизации процесса извлечения определений. Эти модели, обученные на огромных объемах текстовых данных, способны выявлять семантические связи и контекст, необходимые для точного определения значения терминов и понятий. В отличие от традиционных методов, основанных на правилах и регулярных выражениях, БЯМ способны обрабатывать неоднозначность языка и извлекать определения даже из сложных и неструктурированных текстов. Их способность к обобщению и адаптации позволяет эффективно обрабатывать разнообразные предметные области и типы текстов, значительно снижая потребность в ручном труде и повышая точность извлечения определений.
Эффективная извлечение определений с использованием больших языковых моделей (LLM) напрямую зависит от тщательно разработанных стратегий промптинга. Качество и точность извлеченных определений критически зависят от того, как сформулирован запрос к LLM. Необходимо учитывать факторы, такие как четкая инструкция, предоставление контекста, указание формата выходных данных и использование примеров. Продуманные промпты позволяют минимизировать неоднозначность и направляют LLM на предоставление последовательных и корректных определений, а также контролировать длину и стиль генерируемого текста. Экспериментирование с различными подходами к промптингу, включая few-shot learning и chain-of-thought prompting, позволяет оптимизировать процесс извлечения определений и добиться максимальной производительности LLM.
Существуют два основных подхода к использованию больших языковых моделей (LLM) для извлечения определений: использование моделей с открытым исходным кодом и проприетарных (закрытых) моделей. Модели с открытым исходным кодом, такие как Llama 2 или Falcon, предоставляют большую гибкость в настройке и адаптации к конкретным задачам, а также позволяют избежать затрат на лицензирование. Однако, они могут потребовать значительных вычислительных ресурсов для обучения и тонкой настройки, а их производительность может быть ниже, чем у проприетарных моделей. Проприетарные модели, такие как GPT-4 или Gemini, обычно демонстрируют более высокую производительность “из коробки” и требуют меньше усилий для внедрения, но связаны с затратами на использование API и ограничениями в плане кастомизации и контроля над моделью. Выбор между этими подходами зависит от конкретных требований проекта, доступных ресурсов и приоритетов в отношении стоимости, гибкости и производительности.
Оценка Качества Определений: Метрики и Эталонные Наборы Данных
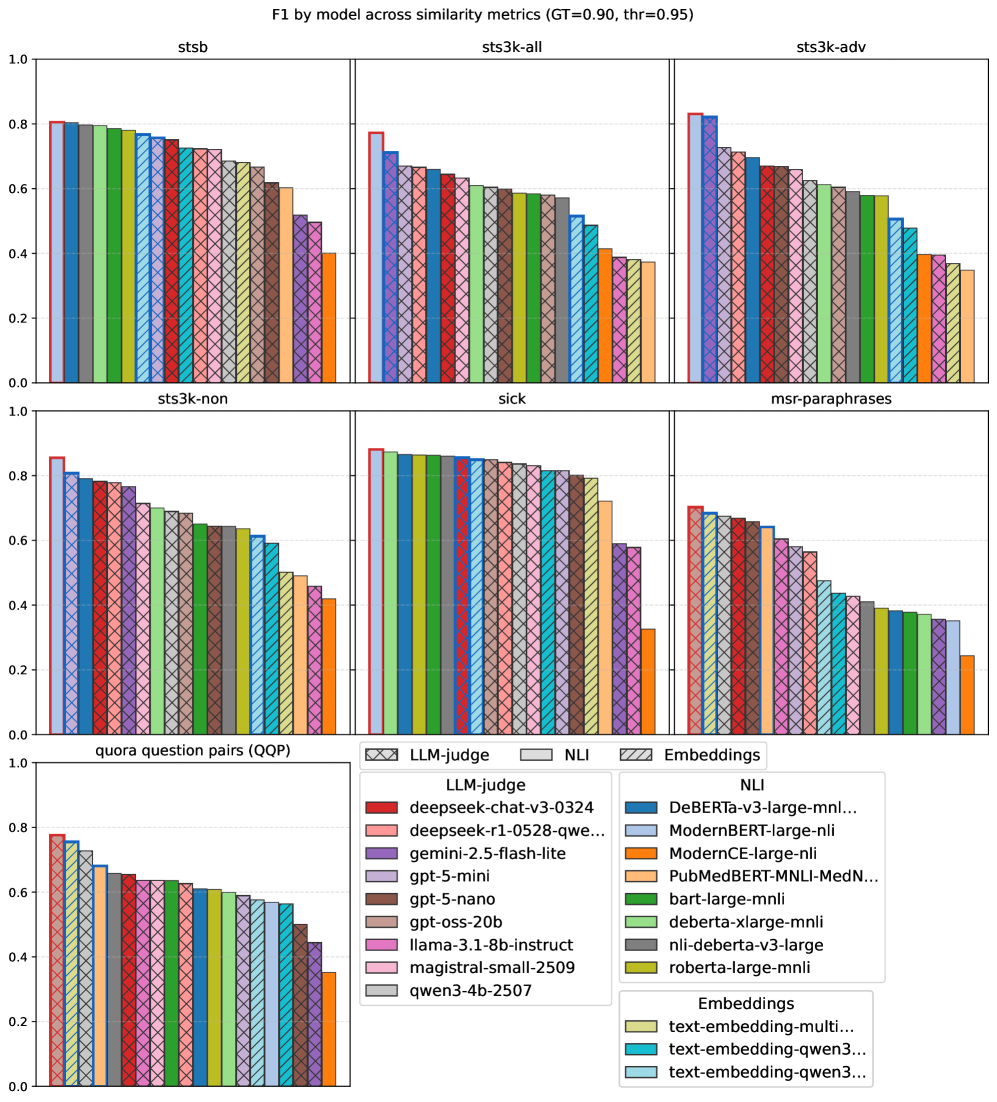
Для точной оценки систем извлечения определений необходимы надежные метрики, основанные на семантической схожести. Традиционные метрики, такие как точность и полнота, часто оказываются недостаточными для оценки качества извлеченных определений, поскольку они не учитывают синонимию и различные способы выражения одной и той же концепции. Метрики, использующие векторные представления слов и предложений (embedding-based metrics), позволяют измерять семантическое расстояние между извлеченным и эталонным определением. Альтернативно, метрики, основанные на естественном выводе (NLI-based metrics), проверяют, следует ли из эталонного определения извлеченное, обеспечивая более глубокий анализ семантической связи. Комбинирование этих подходов позволяет получить более полное и объективное представление о качестве работы системы извлечения определений.
Метрики, основанные на векторных представлениях (embedding-based metrics), и метрики, использующие модели логического вывода (NLI-based metrics), предоставляют взаимодополняющие подходы к оценке семантической близости между извлеченными и эталонными определениями. Embedding-based метрики, такие как косинусное сходство векторов, полученных с помощью моделей, обученных на больших корпусах текста, эффективно выявляют лексическую и семантическую близость. В то время как NLI-based метрики, использующие модели, обученные для определения логических связей между предложениями (влечение, противоречие, нейтральность), позволяют оценить, насколько хорошо извлеченное определение логически соответствует эталонному, учитывая контекст и смысл. Комбинирование этих двух подходов позволяет получить более полную и надежную оценку качества извлеченных определений, чем использование только одного типа метрики.
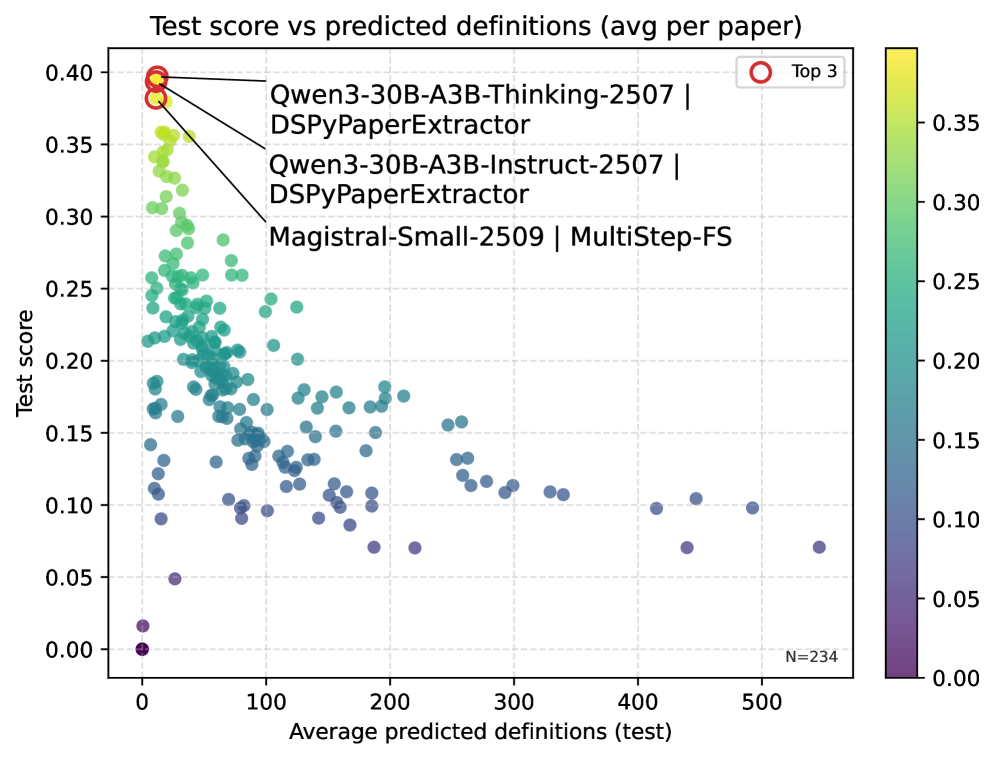
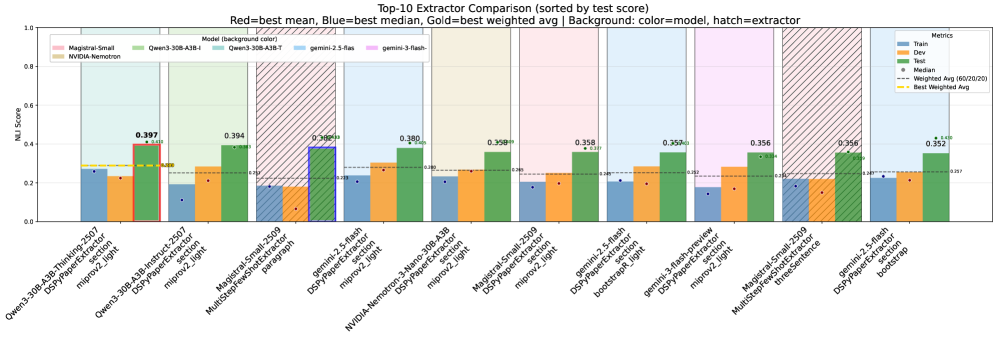
Для объективной оценки и сравнения методов извлечения определений необходимы эталонные наборы данных. DefSim содержит 6060 пар определений, размеченных по степени семантической близости, что позволяет количественно оценивать соответствие извлеченных определений эталонным. Более крупный набор данных DefExtra включает 268268 определений, полученных из 7575 научных статей, и предоставляет обширный ресурс для обучения и тестирования систем извлечения определений. Результаты исследований показывают, что использование многошаговых подсказок и оптимизации с помощью DSPy позволяет улучшить показатели семантической близости, оцениваемые на основе моделей NLI (Natural Language Inference).
За Пределами Эталонов: Влияние и Перспективы Развития
Применение автоматического извлечения определений к сложным областям, таким как ‘Предвзятость СМИ’, открывает возможности для детального анализа и выявления непоследовательности в терминологии. Традиционные методы часто упускают из виду тонкие нюансы и субъективные интерпретации, свойственные оценке медиаконтента. Автоматизированный подход позволяет не только фиксировать явные определения, но и выявлять скрытые предположения и контекстуальные изменения в значениях ключевых слов, таких как ‘объективность’, ‘нейтралитет’ или ‘пропаганда’. Это, в свою очередь, способствует более глубокому пониманию механизмов формирования общественного мнения и позволяет оценить степень предвзятости различных источников информации, что особенно важно в эпоху информационного перенасыщения.
Для повышения эффективности и точности извлечения информации с использованием больших языковых моделей (LLM) активно разрабатываются специализированные фреймворки, такие как DSPy. Данный подход позволяет оптимизировать цепочки запросов (prompting pipelines) путем автоматического поиска наиболее эффективных стратегий формулирования запросов и управления взаимодействием с LLM. Вместо ручной настройки каждого запроса, DSPy использует методы программирования и тестирования для автоматической адаптации и улучшения процесса извлечения. Это значительно сокращает время и ресурсы, необходимые для получения надежных и точных результатов, особенно в сложных областях, где неоднозначность терминологии и контекста представляет серьезную проблему. В конечном итоге, применение подобных фреймворков открывает путь к созданию более интеллектуальных и автоматизированных систем обработки информации.
Автоматизированное извлечение определений открывает путь к созданию всеобъемлющих и динамически обновляемых графов знаний, что способно существенно ускорить научные открытия и разработку более интеллектуальных информационных систем. Вместо статических, вручную создаваемых баз данных, подобные графы знаний формируются автоматически из огромных объемов текста, постоянно адаптируясь к новым данным и уточняя связи между понятиями. Это позволяет исследователям быстро находить релевантную информацию, выявлять скрытые закономерности и генерировать новые гипотезы. Более того, такие динамические графы знаний могут служить основой для создания интеллектуальных помощников, способных не только отвечать на вопросы, но и самостоятельно анализировать информацию, предсказывать тенденции и предлагать инновационные решения в различных областях науки и техники.
Представленная работа демонстрирует подход к извлечению определений из научной литературы, что неразрывно связано с пониманием лежащих в основе систем знаний. Как отмечает Дональд Кнут: «Прежде чем оптимизировать код, убедитесь, что он не работает.» Подобно тому, как необходимо тщательно проверить работоспособность программы перед её оптимизацией, SciDef стремится к точному извлечению определений, используя многоступенчатое промптирование и оптимизацию DSPy. Это позволяет не просто находить определения, но и верифицировать их корректность, что критически важно для создания надежных и воспроизводимых научных знаний, соответствующих принципам FAIR.
Что дальше?
Представленный подход, автоматизирующий извлечение определений из научных текстов, можно рассматривать как попытку декомпиляции реальности. Научная литература — это, по сути, исходный код, описывающий наблюдаемый мир, но он написан на языке, требующем постоянной интерпретации. SciDef — это лишь один из инструментов для чтения этого кода, и пока что весьма несовершенный. Остается вопрос: достаточно ли просто извлекать определения, или необходимо понимать контекст, намерения автора, скрытые предположения? Автоматическое понимание — задача, требующая не просто обработки языка, но и моделирования когнитивных процессов, что пока выходит за рамки возможностей современных больших языковых моделей.
Очевидным направлением развития является расширение наборов данных, таких как DefExtra и DefSim. Однако, истинный прогресс потребует не просто увеличения объема данных, но и повышения их качества, разнообразия и репрезентативности. Необходимо учитывать, что определения в научных текстах часто являются не абсолютными истинами, а рабочими гипотезами, подверженными пересмотру. Следовательно, система должна уметь распознавать неопределенность, противоречия и эволюцию научного знания. Иначе говоря, SciDef должна научиться не просто читать код, но и понимать его историю.
В конечном итоге, успех подобных систем будет зависеть от их способности не только извлекать информацию, но и генерировать новые знания. Автоматическое выявление пробелов в существующих определениях, формулирование новых гипотез и проведение автоматического научного поиска — вот те вызовы, которые предстоит решить в будущем. Реальность — это открытый исходный код, который еще предстоит полностью прочитать, и автоматизация этого процесса — задача, требующая не только технических навыков, но и философского осмысления.
Оригинал статьи: https://arxiv.org/pdf/2602.05413.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Автопилот нового поколения: Единая модель для понимания, планирования и предвидения
- Видеть детали: новый подход к мультимодальному восприятию
- Разум как отражение: новая архитектура интеллекта
- Эхо разума: как итеративные модели учатся в цикле.
- Квантовые вычисления: линейная алгебра на службе симуляции
- Восстановление электронной структуры материалов с помощью машинного обучения
- Квантовые вычисления: Новый взгляд на оценку ресурсов
- Видеогенераторы и скрытые правила мира: смогут ли они понять невысказанное?
- Квантовая электродинамика и сильные корреляции: новый взгляд на взаимодействие света и материи
2026-02-08 05:08