Автор: Денис Аветисян
Новый подход к обучению мультимодальных моделей позволяет им более эффективно фокусироваться на визуальной информации, улучшая ответы на вопросы по изображениям.
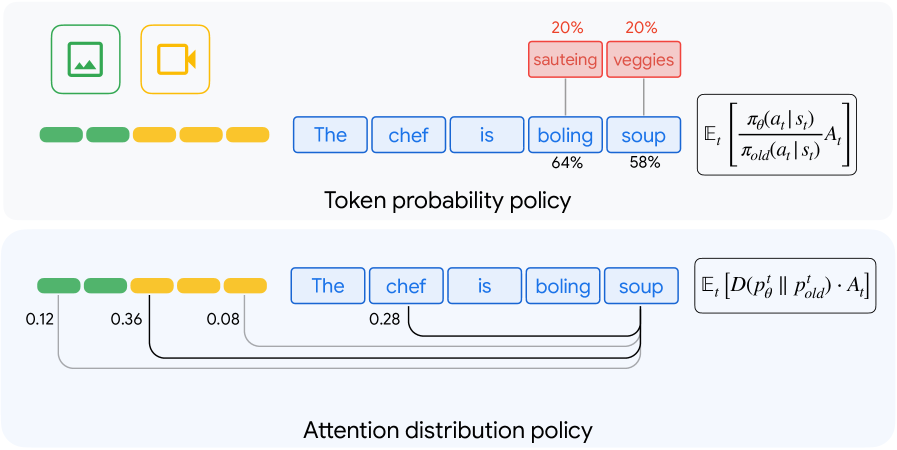
В статье представлена методика Reinforced Attention Learning (RAL) — парадигма постобучения, оптимизирующая распределение внимания в больших мультимодальных языковых моделях для повышения точности визуального обоснования и логического мышления.
Несмотря на успехи обучения с подкреплением в улучшении логических способностей больших языковых моделей, применение этого подхода к мультимодальным моделям часто дает ограниченные результаты, особенно в задачах, требующих эффективной обработки визуальной информации. В данной работе, озаглавленной ‘Reinforced Attention Learning’, предложен новый метод, оптимизирующий не последовательность выходных токенов, а распределение внимания внутри модели. Такой подход позволяет улучшить визуальное обоснование и логические рассуждения, демонстрируя превосходство над существующими методами на различных бенчмарках для изображений и видео. Возможно ли, что оптимизация внимания станет ключевым направлением для развития принципиально новых стратегий пост-обучения мультимодальных моделей?
Разоблачение Мультимодального Разума: Вызовы и Перспективы
Современные большие языковые модели демонстрируют впечатляющие способности в обработке текстовой информации, однако подлинный интеллект предполагает умение интегрировать и анализировать данные, поступающие из различных источников — зрения, видео, звука и других модальностей. Ограничение исключительно текстовыми данными создает существенные препятствия для достижения полноценного понимания окружающего мира. Способность к мультимодальному рассуждению, то есть к одновременной обработке и сопоставлению информации из разных каналов восприятия, является ключевым аспектом когнитивных способностей человека и необходимой составляющей для создания действительно интеллектуальных систем. Именно интеграция различных типов данных позволяет формировать более полную и точную картину реальности, что открывает возможности для решения сложных задач, требующих не только лингвистического, но и визуального, аудиального и других видов анализа.
Существующие подходы к мультимодальному обучению часто демонстрируют предвзятость в сторону текстовой информации, что приводит к недооценке визуальных данных. Исследования показывают, что модели склонны полагаться преимущественно на текстовые подсказки, даже когда визуальная составляющая содержит критически важную информацию для решения задачи. Этот дисбаланс особенно заметен в сценариях, требующих комплексного понимания, например, при ответах на вопросы по изображениям или видео, где игнорирование визуальных деталей приводит к неточным или неполным ответам. Устранение этой модальной предвзятости является ключевой задачей для создания действительно интеллектуальных систем, способных полноценно интегрировать и анализировать информацию из различных источников.
Неспособность к равноценной обработке различных типов информации, в частности, преобладание текстовых данных над визуальными, существенно ограничивает возможности систем искусственного интеллекта в задачах, требующих целостного понимания. В частности, это проявляется в снижении эффективности при решении вопросов по изображениям, где для правильного ответа необходимо не просто распознать объекты, но и интерпретировать их взаимосвязь и контекст, представленные визуально. Например, система может правильно идентифицировать объекты на фотографии, но ошибочно интерпретировать происходящее, если не учитывает пространственные отношения между ними или другие визуальные подсказки. Таким образом, преодоление этой диспропорции является ключевым шагом к созданию действительно интеллектуальных систем, способных к полноценному взаимодействию с окружающим миром.

Дистилляция Знаний: Уменьшение Размера без Потери Интеллекта
Метод обучения с подкреплением, известный как On-Policy Distillation, представляет собой эффективный способ передачи знаний от большой, предварительно обученной “модели-учителя” к более компактной “модели-ученику”. В процессе дистилляции модель-ученик обучается имитировать поведение модели-учителя, стремясь воспроизвести ее выходные данные и внутренние представления на основе одних и тех же входных данных. Это позволяет модели-ученику перенимать сложные навыки и знания, полученные моделью-учителем, при значительно меньшем количестве параметров и вычислительных затратах. В отличие от традиционных методов, On-Policy Distillation фокусируется на обучении модели-ученика на основе текущей политики модели-учителя, что обеспечивает более стабильное и эффективное обучение.
Традиционные методы дистилляции знаний, основанные на выравнивании вероятностей на уровне токенов, демонстрируют ограниченную эффективность при передаче сложных паттернов рассуждений от большой модели к меньшей. Такой подход фокусируется на имитации распределения вероятностей для каждого отдельного токена, игнорируя более глобальные зависимости и логические связи, необходимые для решения задач, требующих многоступенчатого анализа и синтеза информации. В результате, студент, обученный таким образом, может успешно воспроизводить простые ответы, но испытывает трудности при решении более сложных задач, требующих глубокого понимания контекста и применения логических правил.
В рамках обучения эффективных мультимодальных моделей используется подход, основанный на передаче знаний от более крупной модели-учителя Qwen-2.5-VL-32B к более компактной модели-ученику Qwen-2.5-VL-7B. Модель Qwen-2.5-VL-32B выступает в роли эксперта, предоставляя целевые данные для обучения Qwen-2.5-VL-7B, что позволяет последней перенимать сложные навыки и знания, сохраняя при этом значительно меньший размер и вычислительную сложность. Данный метод позволяет эффективно дистиллировать знания, передавая возможности более мощной модели в более компактную архитектуру.
Целью данного подхода является сохранение способности к рассуждению, присущей большой модели, в более компактной архитектуре. Это достигается путем передачи знаний от большой модели Qwen-2.5-VL-32B, выступающей в роли учителя, к меньшей модели Qwen-2.5-VL-7B, выступающей в роли ученика. Сохранение логических способностей в уменьшенной модели позволяет добиться сопоставимой производительности при значительно меньших вычислительных затратах и требованиях к памяти, что важно для развертывания на устройствах с ограниченными ресурсами и для ускорения процесса инференса.
Оптимизация Внимания: Настройка Разума для Глубокого Понимания
Обучение с подкреплением внимания (Reinforced Attention Learning) представляет собой метод постобучения, направленный на непосредственную оптимизацию распределения внимания внутри модели-ученика. В отличие от стандартных методов обучения, которые фокусируются на оптимизации выходных данных, данный подход непосредственно корректирует веса, определяющие, на какие части входных данных модель обращает наибольшее внимание. Это достигается путем применения алгоритмов обучения с подкреплением, где модель получает вознаграждение за концентрацию внимания на областях, коррелирующих с правильными ответами, и штраф за игнорирование релевантной информации. Таким образом, происходит целенаправленное изменение распределения внимания, что позволяет модели более эффективно извлекать и использовать информацию из входных данных.
В процессе обучения с подкреплением внимания, модель вознаграждается за фокусировку на частях входных данных, которые коррелируют с правильными ответами. Это достигается путем анализа внимания, уделяемого различным элементам входных данных при решении задачи, и усиления тех паттернов внимания, которые приводят к успешному результату. Механизм вознаграждения направлен на то, чтобы модель научилась выделять наиболее релевантную информацию, игнорируя отвлекающие факторы, и, таким образом, улучшить свою способность к логическому выводу и решению задач.
Для оценки соответствия распределений внимания модели-ученика и модели-учителя используется метрика Дженсена-Шеннона (Jenson-Shannon Divergence, JSD). JSD представляет собой симметричную и сглаженную версию расхождения Кульбака-Лейблера, что делает ее более подходящей для сравнения вероятностных распределений, особенно в случаях, когда одно из распределений имеет нулевые значения. Формально, JSD(P||Q) = 0.5 <i> (KL(P||M) + KL(Q||M)), где M = 0.5 </i> (P + Q), а KL — расхождение Кульбака-Лейблера. Минимизация JSD между распределениями внимания позволяет добиться более точного соответствия и, как следствие, улучшить процесс передачи знаний от модели-учителя к модели-ученику.
В результате применения метода Reinforced Attention Learning, обученная модель-студент демонстрирует не только повышение точности предсказаний, но и улучшение способности к рассуждению, приближающееся к человеческому. Это проявляется в более эффективном выделении релевантных частей входных данных при решении задач, что подтверждается анализом распределения внимания и его соответствием тем областям входных данных, которые действительно важны для получения правильного ответа. Наблюдаемое сходство в паттернах внимания между моделью и человеком указывает на возможность использования данного подхода для создания более интерпретируемых и надежных систем искусственного интеллекта.
Проверка на Практике: Оценка на Видеоданных
Оценка предложенного подхода проводилась на наборе данных Video-R1, являющемся стандартным бенчмарком для задачи видео-вопросов и ответов (Video Question Answering, VQA). Video-R1 содержит обширную коллекцию видеороликов, аннотированных вопросами и соответствующими ответами, что позволяет объективно оценить способность модели к пониманию визуального контента и установлению логических связей между видео и заданным вопросом. Использование данного набора данных обеспечивает сопоставимость результатов с другими современными подходами в области видео-понимания и позволяет определить эффективность предложенной методики в решении задач VQA.
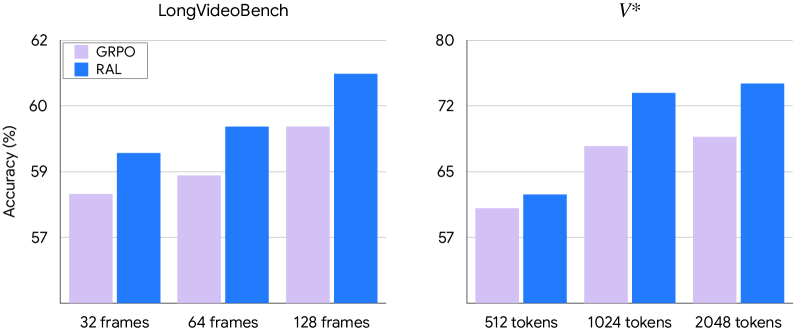
Оптимизированная студенческая модель продемонстрировала улучшенные результаты по сравнению с базовыми методами, особенно в задачах, требующих временного рассуждения. Набор данных LongVideoBench показал прирост точности на 2.2%, NExT-QA — на 3.4%, а MVBench — на 1.5% по сравнению с GRPO. Данные результаты указывают на эффективность предложенной техники обучения с подкреплением для захвата динамических взаимосвязей внутри видеопоследовательностей и повышения точности анализа видеоконтента, требующего понимания временной последовательности событий.
Полученные улучшения в производительности демонстрируют эффективность разработанной методики обучения с подкреплением внимания (Reinforced Attention Learning) в задачах анализа видео. Данный подход позволяет модели более точно выявлять и учитывать динамические взаимосвязи между кадрами видеопоследовательности, что критически важно для понимания временных зависимостей и контекста. В результате, модель способна более эффективно обрабатывать видеоданные и предоставлять более точные ответы на вопросы, требующие анализа последовательности событий и изменений во времени.
В ходе оценки были зафиксированы значительные улучшения в точности на различных задачах видеопонимания по сравнению с GRPO. Набор данных V∗V∗ показал прирост точности на 5.8%, MME — на 94.1%, ChartQA — на 2.8%, а VizWiz — на 3.8%. Дополнительно, точность на V∗V∗ при использовании видео высокого разрешения (2048 токенов) увеличилась на 6.3%, что свидетельствует об эффективности подхода в обработке визуально насыщенного контента.
Поддержание временной согласованности (temporal coherence) является критически важным фактором для надежного понимания видеоданных. Отсутствие согласованности во временной последовательности событий может привести к неверной интерпретации действий, объектов и их взаимосвязей в видеоролике. Это особенно важно для задач, требующих анализа динамики сцены, прогнозирования будущих событий или ответа на вопросы, связанные с последовательностью действий. Надежное понимание видео требует способности модели корректно отслеживать изменения во времени и устанавливать причинно-следственные связи между различными кадрами и событиями, что напрямую зависит от способности поддерживать временную согласованность.
Взгляд в Будущее: Адаптивное Мультимодальное Интеллекта
Отделение оптимизации механизма внимания от задачи предсказания следующего токена открывает принципиально новые возможности для адаптации моделей к различным модальностям данных. Традиционно, внимание в мультимодальных системах тесно связано с предсказанием следующего элемента последовательности, что ограничивает гибкость и способность модели эффективно обрабатывать информацию из разных источников. Предложенный подход позволяет независимо настраивать механизм внимания, фокусируясь на наиболее релевантных аспектах каждого входного сигнала, будь то визуальный ряд, звук или текст. Это приводит к значительному повышению эффективности модели при обработке данных, представленных в различных форматах, и способствует созданию более универсальных и интеллектуальных систем, способных к комплексному пониманию окружающего мира.
Предложенный подход к адаптации внимания, изначально разработанный для анализа видео, обладает значительным потенциалом для применения в более широком спектре задач. Исследования показывают, что оптимизация внимания, отделенная от предсказания следующего токена, позволяет модели эффективно обрабатывать информацию из различных источников. Это открывает возможности для создания систем, способных генерировать текстовые описания изображений, обеспечивая более точное и контекстуально релевантное описание визуального контента. Более того, данный метод применим к решению задач аудио-визуального рассуждения, где модель должна интегрировать информацию как из аудио-, так и из видеопотока для принятия обоснованных решений или ответов на вопросы. Таким образом, универсальность подхода способствует развитию мультимодального искусственного интеллекта, способного к комплексному пониманию окружающего мира и эффективному взаимодействию с ним.
Предстоящие исследования направлены на интеграцию методов обучения с подкреплением для дальнейшей оптимизации механизма внимания в мультимодальных моделях. Использование обучения с подкреплением позволит модели не просто предсказывать следующий токен, а активно изучать и совершенствовать стратегии фокусировки внимания на наиболее релевантных элементах различных модальностей. Это приведет к созданию более гибких и обобщающих систем, способных адаптироваться к новым задачам и данным без необходимости переобучения. Ожидается, что такой подход значительно улучшит способность моделей к рассуждениям, особенно в сложных сценариях, требующих интеграции информации из нескольких источников, и откроет новые возможности для создания искусственного интеллекта, способного к более глубокому пониманию окружающего мира.
В конечном итоге, представленная работа вносит значительный вклад в создание более адаптивных и интеллектуальных мультимодальных систем, способных к подлинному пониманию окружающего мира. Развитие подобных систем предполагает не просто обработку различных типов данных — изображений, звука, текста — но и их интеграцию для формирования целостного представления о происходящем. Способность к адаптации позволяет этим системам эффективно функционировать в меняющихся условиях и извлекать полезную информацию из неоднозначных или неполных данных. В перспективе, такие системы смогут не только распознавать объекты и события, но и понимать их взаимосвязи, контекст и намерения, приближаясь к уровню понимания, присущему человеку. Это открывает широкие возможности для применения в различных областях, включая робототехнику, автоматизированное вождение, медицинскую диагностику и создание более интуитивных интерфейсов взаимодействия с машинами.
Исследование демонстрирует стремление к оптимизации внимания в мультимодальных больших языковых моделях, что созвучно мысли Джона Маккарти: «Каждый эксплойт начинается с вопроса, а не с намерения». Подобно тому, как взлом системы требует глубокого понимания её структуры, предложенный подход Reinforced Attention Learning (RAL) направлен на точное выстраивание внимания модели, чтобы улучшить её способность к визуальному обоснованию и логическим рассуждениям. RAL, оптимизируя распределение внимания, словно задаёт модели правильные вопросы, позволяя ей более эффективно извлекать и использовать информацию из визуальных данных. Это подтверждает идею о том, что ключ к успешному решению задачи лежит в правильной постановке вопроса, а не в слепом следовании шаблонам.
Куда же дальше?
Представленная работа, оптимизируя распределение внимания в мультимодальных больших языковых моделях, не столько решает проблему, сколько обнажает её истинную природу. По сути, RAL демонстрирует, что даже самые сложные системы искусственного интеллекта всё ещё нуждаются в тонкой настройке фундаментальных механизмов — в данном случае, в том, как модель смотрит на мир. Вопрос не в увеличении количества параметров, а в более глубоком понимании того, как эти параметры используются. Это напоминает о старом принципе: не важно, насколько мощный двигатель, важно — как он направляет свою силу.
Очевидным направлением дальнейших исследований является исследование обобщающей способности RAL на различные мультимодальные задачи, выходящие за рамки визуальных вопросов и ответов. Устойчивость к «шуму» в данных, способность к адаптации к новым модальностям, и, что самое главное, преодоление предвзятости, встроенной в обучающие данные — вот те вызовы, которые предстоит решить. Иначе, оптимизируя внимание, мы рискуем просто научить систему более эффективно игнорировать то, что ей не нравится.
В конечном счете, RAL — это ещё один шаг на пути к созданию систем, которые не просто имитируют интеллект, а действительно понимают мир вокруг себя. И хотя до этого ещё далеко, важно помнить, что истинная безопасность — это не обфускация, а прозрачность. Понимание внутренних механизмов системы — ключ к её контролю и, следовательно, к предотвращению нежелательных последствий. Попытки же просто “закрыть ящик” — иллюзия контроля, обречённая на провал.
Оригинал статьи: https://arxiv.org/pdf/2602.04884.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Моделирование биомолекул: новый импульс от нейросетей
- Квантовая механика: скрытый детерминизм?
- Нейросети учатся обобщать: новый подход к работе с наборами данных
2026-02-08 12:00