Автор: Денис Аветисян
Новая реализация оптимизатора Shampoo позволяет значительно сократить время обучения сложных моделей, используя возможности современных GPU.
В статье представлена высокопроизводительная реализация оптимизатора Shampoo с использованием пакетной блочной предобусловки и эффективных методов решения обратных задач.
Оптимизаторы второго порядка, такие как Shampoo, демонстрируют высокую эффективность, однако их применение часто сдерживается значительными вычислительными затратами. В работе ‘DASH: Faster Shampoo via Batched Block Preconditioning and Efficient Inverse-Root Solvers’ предложен новый подход — DASH, позволяющий существенно ускорить оптимизацию Shampoo за счет оптимизации использования GPU, применения инновационных численных методов, включая итерацию Newton-DB, и усовершенствования масштабирования матриц. Разработанная реализация позволяет добиться ускорения в 4.83\times по сравнению с оптимизированным Distributed Shampoo, одновременно улучшая производительность модели. Сможет ли DASH стать стандартом де-факто для эффективной оптимизации моделей глубокого обучения?
Масштабируемость и Пределы Первичных Методов Оптимизации
Современные нейронные сети, стремящиеся к всё большей сложности и объёму, в значительной степени полагаются на методы оптимизации первого порядка, такие как AdaGrad. Однако, по мере увеличения размеров модели и объёма данных, эти методы сталкиваются с серьёзными вычислительными трудностями. Проблема заключается в том, что каждый шаг оптимизации требует вычисления градиента по всем параметрам сети, что становится непомерно затратным по времени и ресурсам. Несмотря на свою простоту и эффективность для небольших моделей, масштабирование методов первого порядка до уровня, необходимого для обучения современных гигантских нейронных сетей, представляет собой существенное препятствие, ограничивающее скорость и качество обучения. Это заставляет исследователей искать альтернативные подходы, способные эффективно справляться с растущими вычислительными потребностями.
Вычислительная сложность методов второго порядка, требующих оперирования с полной матрицей Гессе, становится критическим препятствием при обучении масштабных нейронных сетей. Для моделей, содержащих миллиарды параметров, вычисление и обращение такой матрицы требует огромных объемов памяти и процессорного времени, что делает их практическую реализацию невозможной. В результате, несмотря на теоретическое преимущество методов второго порядка в скорости сходимости и точности, обучение становится значительно замедленным или вовсе невозможным из-за чрезмерных вычислительных затрат. Это обстоятельство вынуждает исследователей искать альтернативные подходы, направленные на приближенное вычисление информации второго порядка или использование более эффективных алгоритмов оптимизации, позволяющих обойти данное ограничение и обеспечить эффективное обучение сложных моделей.
В связи с вычислительными ограничениями, возникающими при использовании методов второго порядка для обучения масштабных нейронных сетей, активно исследуются различные приближения и специализированные техники. Эти подходы направлены на эффективное использование информации второго порядка — кривизны функции потерь — без экспоненциального увеличения вычислительных затрат. Разрабатываются методы, такие как квазиньютоновские оптимизаторы и адаптивные методы с оценкой кривизны, позволяющие приблизиться к преимуществам методов второго порядка — более быстрая сходимость и улучшенная обобщающая способность — при сохранении практической реализуемости. Использование таких техник является ключевым направлением в развитии алгоритмов обучения, позволяющим преодолеть ограничения, связанные с масштабированием моделей и повысить эффективность процесса оптимизации.
Shampoo: Послойное Предобуславливание для Ускоренного Обучения
Оптимизатор Shampoo использует подход к предварительной обработке по слоям (layer-wise preconditioning), аппроксимируя обратную матрицу Гессе H^{-1} для ускорения сходимости во время обучения. Вместо вычисления полной обратной матрицы Гессе, что является вычислительно затратным, Shampoo оценивает ее по каждому слою сети отдельно. Это позволяет снизить вычислительную сложность и потребление памяти, особенно при работе с большими моделями. Предварительная обработка по слоям нормализует градиенты для каждого слоя, улучшая обусловленность задачи оптимизации и позволяя использовать более крупные шаги обучения, что приводит к более быстрой сходимости. Эффективность метода заключается в приближении H^{-1} с использованием методов, масштабируемых для больших размерностей.
Оптимизатор Shampoo снижает вычислительную сложность за счет разделения процесса оптимизации по слоям нейронной сети. Традиционные оптимизаторы, такие как Adam, вычисляют одно обновление параметров для всех слоев, что требует значительных ресурсов при обучении крупных моделей. Shampoo, напротив, вычисляет и применяет отдельные обновления для каждого слоя, аппроксимируя обратную матрицу Гессе для каждого слоя независимо. Это позволяет снизить общую вычислительную нагрузку и требования к памяти, особенно при использовании моделей с большим количеством параметров. Разделение оптимизации по слоям обеспечивает более эффективное масштабирование обучения на больших моделях и позволяет использовать более крупные пакеты данных без увеличения времени обучения.
Метод «grafting» в оптимизаторе Shampoo позволяет использовать существующие, хорошо настроенные графики изменения скорости обучения (learning rate schedules) без необходимости их перенастройки для нового оптимизатора. Это достигается путем адаптации существующего графика к специфике предобуславливания (preconditioning), применяемого Shampoo. Такой подход значительно упрощает внедрение Shampoo, так как позволяет избежать трудоемкого процесса поиска оптимальных параметров скорости обучения с нуля, и обеспечивает более высокую производительность на начальных этапах обучения за счет использования проверенных и эффективных стратегий изменения скорости обучения.
Распределенный Shampoo и DASH: Масштабирование на Многопроцессорные Системы
Распределенный Shampoo расширяет функциональность оптимизатора Shampoo для сценариев распределенного обучения, позволяя осуществлять параллельную обработку данных на нескольких графических процессорах (GPU). Вместо последовательной обработки параметров модели на одном GPU, Distributed Shampoo разделяет задачу между несколькими GPU, что значительно сокращает общее время обучения. Это достигается путем разделения тензоров и операций между GPU, с последующей синхронизацией градиентов. Такая архитектура позволяет эффективно масштабировать обучение моделей до больших размеров и объемов данных, недоступных для обучения на одном GPU, и использовать преимущества параллельных вычислений для ускорения процесса оптимизации.
Реализация Distributed Accelerated Shampoo (DASH) оптимизирует производительность за счет стратегического распределения слоев между GPU посредством балансировки нагрузки (Load Balancing). Это позволяет эффективно использовать вычислительные ресурсы и минимизировать время простоя. Для повышения эффективности вычислений DASH использует блочные матричные структуры (Block Matrix structures), что снижает сложность операций и потребление памяти. В частности, применение блочных структур позволяет ускорить вычисления за счет локализации доступа к данным и оптимизации кэширования, что особенно важно при работе с большими моделями и наборами данных.
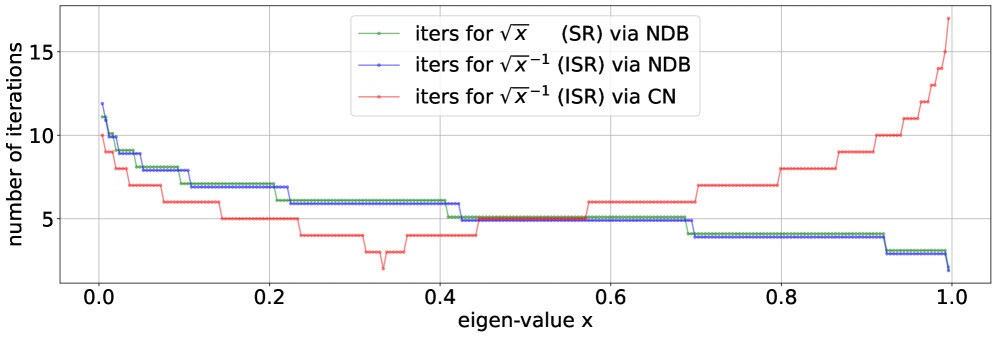
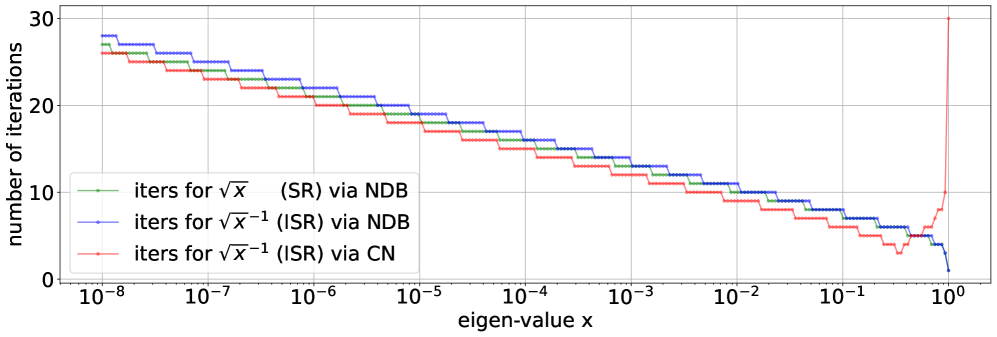
Для эффективного вычисления матричных операций в Distributed Accelerated Shampoo (DASH) используются итеративные методы, такие как Power Iteration, Multi-Power Iteration, аппроксимация полиномами Чебышева, метод Кранка-Николсона (CN) и NDB (Non-Diagonal Block). Power Iteration и Multi-Power Iteration позволяют эффективно находить собственные значения и собственные векторы, критически важные для вычисления обратных матриц. Аппроксимация полиномами Чебышева предоставляет альтернативный подход к решению задач линейной алгебры с высокой точностью. Методы CN и NDB применяются для решения систем линейных уравнений, возникающих в процессе оптимизации, и обеспечивают стабильность и эффективность вычислений. Использование этих итеративных методов позволяет снизить вычислительную сложность и ускорить процесс обучения модели.
Использование половинной точности (FP16) значительно снижает потребление памяти и ускоряет вычислительные операции в процессе обучения. Переход от одинарной точности (FP32) к FP16 уменьшает размер каждого параметра модели вдвое, что приводит к сокращению общего объема памяти, необходимого для хранения и обработки данных. Это позволяет обучать более крупные модели или использовать большие пакеты данных, не превышая ограничения памяти GPU. Кроме того, многие современные GPU имеют специализированные аппаратные средства для ускорения вычислений FP16, что приводит к повышению пропускной способности и сокращению времени обучения. В частности, это особенно эффективно при выполнении матричных операций, являющихся основой глубокого обучения.
В ходе экспериментов, предложенная реализация Distributed Accelerated Shampoo (DASH) продемонстрировала ускорение обучения до 5 раз по сравнению с Distributed Shampoo. Данное ускорение достигается за счет оптимизации распределения слоев нейронной сети посредством балансировки нагрузки и эффективных матричных вычислений, что позволяет существенно сократить время, необходимое для завершения одного шага оптимизации и, следовательно, всего процесса обучения. Результаты экспериментов подтверждают, что DASH обеспечивает значительное повышение производительности при обучении моделей на многопроцессорных GPU-системах.
Валидация и Влияние: Достижение Современной Производительности
Экспериментальные результаты демонстрируют, что оптимизатор DASH обеспечивает значительное ускорение процесса обучения по сравнению с существующими аналогами, особенно при работе с моделями очень больших размеров. Наблюдаемое увеличение скорости обучения позволяет существенно сократить время, необходимое для достижения оптимальных параметров модели, что критически важно для задач, требующих обработки огромных объемов данных. Эффективность DASH проявляется в способности более быстро сходиться к оптимальному решению, что позволяет исследователям и разработчикам эффективнее использовать вычислительные ресурсы и ускорить процесс создания передовых языковых моделей. Данное ускорение достигается благодаря инновационной архитектуре DASH, оптимизированной для параллельных вычислений и эффективного использования памяти.
Оценка с использованием метрики Validation Perplexity подтверждает, что DASH не только поддерживает, но и улучшает точность модели при одновременном сокращении времени обучения. Проведенные эксперименты демонстрируют, что оптимизатор DASH достигает сопоставимых или лучших результатов в задачах языкового моделирования, измеряемых Validation Perplexity, по сравнению с существующими методами. В частности, при использовании нормализации NDB и Power-Iteration, DASH показывает perplexity в 11.68, что сравнимо с 11.87, достигнутым методами EVD и CN. Данный результат указывает на то, что DASH является эффективным инструментом для обучения масштабных моделей, позволяющим добиться высокой точности без значительного увеличения вычислительных затрат, что особенно важно для задач обработки естественного языка и создания продвинутых языковых моделей.
В ходе экспериментов оптимизатор DASH продемонстрировал выдающиеся результаты в задачах оценки качества языковых моделей. При использовании нормализации NDB и Power-Iteration, DASH достиг показателя Validation Perplexity в 11.68, что свидетельствует о высокой точности генерируемого текста. Применение альтернативных методов нормализации, а именно EVD и CN, позволило DASH достичь сопоставимого уровня точности — 11.87, подтверждая стабильность и надежность оптимизатора в различных конфигурациях. Данные результаты демонстрируют, что DASH не только ускоряет процесс обучения, но и обеспечивает сохранение, а в некоторых случаях и улучшение качества языковых моделей, что делает его перспективным инструментом для развития современных систем обработки естественного языка.
Экспериментальные результаты демонстрируют, что оптимизатор DASH, при использовании смешанной точности CN-FP16, сокращает время обучения в 4.83 раза по сравнению с Distributed Shampoo, работающим в FP32. Данное ускорение достигается за счет эффективной реализации алгоритма и оптимизации использования памяти, что позволяет значительно повысить производительность при работе с крупномасштабными моделями и большими объемами данных. Такое существенное снижение времени обучения открывает новые возможности для более быстрой итерации и разработки передовых языковых моделей.
Экспериментальные результаты демонстрируют, что оптимизатор DASH, при использовании методов Нормализации по Дивизионному Базису (NDB) и Итерации по Степени, обеспечивает значительное ускорение обучения по сравнению с Distributed Shampoo. В частности, зафиксировано снижение времени обучения в 3.81 раза. NDB, использующий нормы Фробениуса и Оператора для масштабирования, способствует стабилизации и ускорению сходимости процесса оптимизации, позволяя эффективно обучать масштабные языковые модели за существенно меньшее время. Данное улучшение производительности открывает возможности для разработки и внедрения более сложных и мощных моделей обработки естественного языка.
Метод DASH использует масштабирование на основе нормы Фробениуса и операторной нормы, что существенно повышает стабильность и скорость сходимости процесса оптимизации. Применение этих норм позволяет более эффективно регулировать величину градиентов, предотвращая их взрыв или затухание, особенно при работе с большими моделями и сложными наборами данных. В частности, норма Фробениуса обеспечивает контроль над общей величиной изменений параметров, в то время как операторная норма позволяет учитывать структуру матрицы и направлять процесс оптимизации вдоль наиболее перспективных направлений. Это приводит к более надежной и быстрой сходимости, позволяя достигать лучших результатов при обучении масштабных языковых моделей и снижая потребность в тонкой настройке гиперпараметров.
Возможность эффективной тренировки масштабных моделей открывает перед исследователями принципиально новые горизонты в области разработки языковых моделей. Оптимизатор DASH, благодаря своей способности ускорять процесс обучения при сохранении или улучшении точности, позволяет создавать более сложные и мощные системы, способные обрабатывать и генерировать текст с беспрецедентным качеством. Это особенно важно в контексте постоянно растущих объемов данных и усложняющихся архитектур нейронных сетей, где традиционные методы оптимизации становятся узким местом. Благодаря DASH, становится возможным исследовать и внедрять более глубокие и сложные модели, расширяя границы возможностей в таких областях, как машинный перевод, генерация контента и понимание естественного языка. В перспективе, это может привести к созданию искусственного интеллекта, способного к более естественному и эффективному взаимодействию с человеком.
Представленная работа демонстрирует стремление к математической чистоте в реализации алгоритмов оптимизации. Как отмечает Тим Бернерс-Ли: «В конечном итоге, веб — это не просто коллекция гипертекстов, а инструмент для создания общих знаний». Аналогично, DASH не просто ускоряет процесс обучения моделей, но и обеспечивает более надежные и предсказуемые результаты благодаря оптимизации методов решения, таких как Newton-DB и улучшенному масштабированию матриц. Подобный подход к оптимизации, где точность и доказуемость алгоритма превалируют над эвристическими решениями, является ключевым для создания действительно эффективных и масштабируемых систем машинного обучения.
Что Дальше?
Представленная работа, безусловно, демонстрирует заметный прогресс в ускорении оптимизации второго порядка. Однако, красота алгоритма проявляется не в трюках, а в непротиворечивости его границ и предсказуемости. Ускорение, достигнутое благодаря DASH, является существенным, но остаётся открытым вопрос о фундаментальных ограничениях применимости методов, основанных на обращении матриц. Необходимо исследовать, насколько эффективно предложенные техники масштабируются с ростом размерности моделей и сложности задач. Устойчивость численных методов, таких как Newton-DB, в условиях плохо обусловленных матриц требует дальнейшего изучения и, возможно, разработки более робастных альтернатив.
Особый интерес представляет вопрос о взаимосвязи между структурой матрицы, определяемой моделью, и эффективностью различных схем предобуславливания. Простое ускорение вычислений не является самоцелью; важнее понять, как оптимизировать процесс обучения, минимизируя количество необходимых итераций для достижения сходимости. Игнорирование этих аспектов приведёт лишь к поверхностным улучшениям, не затронув глубинную природу проблемы.
Будущие исследования должны быть сосредоточены на разработке алгоритмов, которые адаптируются к конкретным характеристикам задачи, а не полагаются на универсальные эвристики. Истинная элегантность кода проявляется в его математической чистоте. Любое решение либо корректно, либо ошибочно — промежуточных состояний нет. Алгоритм должен быть доказуем, а не просто «работать на тестах».
Оригинал статьи: https://arxiv.org/pdf/2602.02016.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Квантовая механика: скрытый детерминизм?
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Математический интеллект: как улучшить навыки решения задач у больших языковых моделей
2026-02-08 17:07