Автор: Денис Аветисян
Новое исследование показывает, что поздние слои больших языковых моделей организуют информацию, опираясь на угловые зависимости, напрямую связанные с точностью предсказаний.

В работе продемонстрирована зависимость между организацией представлений в поздних слоях больших языковых моделей и их предсказательной способностью, при этом ранние слои демонстрируют более общую геометрическую структуру без прямого влияния на прогнозы.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), механизмы, лежащие в основе их способности к прогнозированию, остаются недостаточно изученными. В работе «Depth-Wise Emergence of Prediction-Centric Geometry in Large Language Models» показано, что поздние слои LLM демонстрируют глубинный переход от обработки контекста к формированию предсказаний, организованный посредством специфической геометрической структуры представлений. В частности, угловая организация этих представлений параметризует сходство предсказываемых распределений, в то время как нормы представлений кодируют контекстную информацию, не влияющую напрямую на предсказания. Какие новые возможности для интерпретации и контроля над LLM открывает понимание этой геометрической организации вычислений?
Геометрия Мысли: Раскрытие Внутренней Структуры Языковых Моделей
Современные большие языковые модели демонстрируют впечатляющую способность генерировать текст, переводить языки и отвечать на вопросы, однако механизмы, лежащие в основе этих возможностей, остаются в значительной степени непрозрачными. Несмотря на выдающиеся результаты, сложность архитектуры этих моделей затрудняет понимание того, как именно информация кодируется и обрабатывается внутри них. Эта непрозрачность создает серьезные препятствия для улучшения производительности, повышения надежности и обеспечения контролируемости — ведь без понимания внутренних процессов трудно целенаправленно оптимизировать или исправить возникающие ошибки. В результате, разработчики сталкиваются с необходимостью поиска новых методов анализа, позволяющих “заглянуть внутрь” этих сложных систем и раскрыть принципы их работы.
Понимание того, как большие языковые модели (БЯМ) структурируют и представляют информацию, играет ключевую роль в повышении их эффективности и надежности. Исследования показывают, что внутреннее представление знаний в БЯМ не является хаотичным, а формирует своего рода «геометрию мышления», где различные понятия и связи между ними располагаются в многомерном пространстве. Анализ этой геометрии позволяет выявить закономерности в организации знаний, понять, как модель делает выводы и предсказывает результаты. Изучение этой структуры открывает возможности для оптимизации процессов обучения, улучшения способности к обобщению и повышения устойчивости к нежелательным искажениям, что в конечном итоге ведет к созданию более интеллектуальных и предсказуемых систем искусственного интеллекта.
Долгое время большие языковые модели (БЯМ) рассматривались как непрозрачные системы, своеобразные «чёрные ящики», где внутренние процессы оставались скрытыми от исследователей. Однако, новый геометрический подход позволяет взглянуть «внутрь» этих моделей и составить карту их знаний. Вместо абстрактных весов и сложных вычислений, представления, формируемые БЯМ, можно визуализировать как многомерные пространства, где близкие понятия располагаются рядом друг с другом. Такое картирование позволяет выявить структуру знаний, понять, как модель связывает различные концепции, и обнаружить потенциальные пробелы или искажения в её понимании мира. Благодаря этому, исследователи получают возможность не просто оценивать результаты работы модели, но и анализировать сам процесс «мышления», открывая путь к более эффективным и контролируемым системам искусственного интеллекта.
Геометрический анализ внутренней структуры больших языковых моделей открывает перспективы для создания более эффективных и управляемых систем, обходя ограничения, связанные с простым увеличением масштаба. Традиционные подходы к улучшению производительности LLM часто фокусируются на наращивании вычислительных ресурсов и объемов данных, что приводит к экспоненциальному росту затрат и энергопотребления. Вместо этого, изучение геометрии представления знаний позволяет выявить оптимальные способы организации информации внутри модели, потенциально снижая потребность в огромных ресурсах для достижения аналогичных или даже лучших результатов. Подобный подход предполагает не просто увеличение размера модели, а её более разумную и структурированную организацию, что может привести к созданию более компактных, быстрых и экономичных LLM, способных к более эффективному решению сложных задач и более предсказуемому поведению.
Геометрический Инструментарий: Исследование Представлений в Языковых Моделях
Геометрический анализ предоставляет набор инструментов для изучения векторных представлений токенов в больших языковых моделях. Ключевыми метриками являются косинусное сходство (Cosine Similarity), позволяющее оценить близость между векторами на основе угла между ними, а также евклидово расстояние и угловое расстояние, количественно определяющие расстояние между векторами в многомерном пространстве. Косинусное сходство рассчитывается по формуле \frac{A \cdot B}{||A|| \cdot ||B||}, где A и B — векторы токенов. Евклидово расстояние измеряет прямую линию между двумя векторами, а угловое расстояние — величину угла между ними. Использование этих метрик позволяет характеризовать структуру репрезентационного пространства и выявлять закономерности в кодировании информации.
Количественная оценка геометрических свойств векторных представлений токенов, таких как косинусное сходство, евклидово расстояние и угловое расстояние, позволяет характеризовать структуру репрезентационного пространства больших языковых моделей (LLM). Анализ этих метрик предоставляет информацию о том, как LLM организует и кодирует информацию, выявляя кластеризацию токенов, степень семантической близости и общую структуру пространства признаков. Например, низкое евклидово расстояние между представлениями семантически связанных токенов указывает на их близость в репрезентационном пространстве, в то время как высокий косинус угла между векторами может свидетельствовать о различной направленности семантического значения. Использование таких количественных показателей позволяет перейти от качественного описания репрезентаций к их формальному анализу и сравнению между различными моделями и слоями.
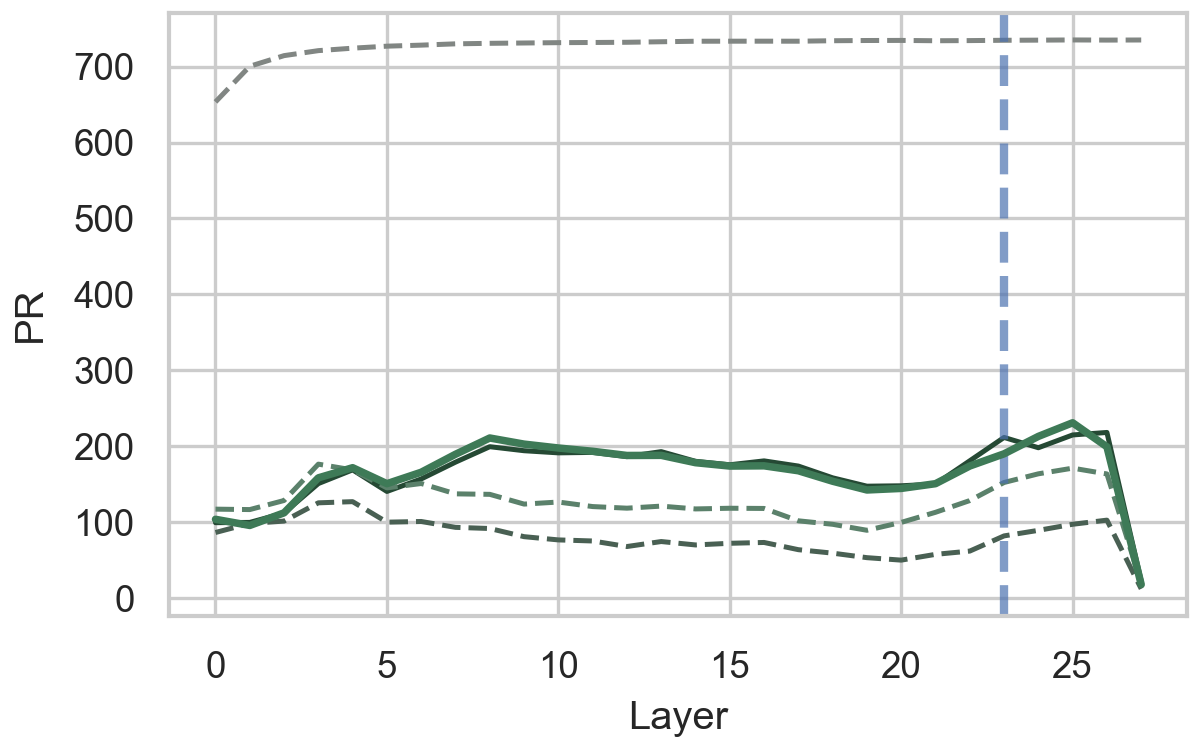
Коэффициент участия (Participation Ratio) и размерность (Dimensionality) предоставляют количественные показатели, характеризующие эффективность кодирования информации в векторных представлениях языковых моделей. Коэффициент участия, рассчитываемый как \frac{1}{N} \sum_{i=1}^{N} (\sum_{j=1}^{D} a_{ij}^2) , где N — количество токенов, а D — размерность вектора, показывает, как распределена активность по различным измерениям пространства представлений. Низкий коэффициент участия указывает на то, что информация кодируется относительно небольшим подмножеством измерений, в то время как высокий коэффициент указывает на более равномерное распределение. Анализ размерности позволяет определить, какое количество измерений необходимо для сохранения большей части информации, закодированной в представлениях. Снижение эффективной размерности с увеличением глубины модели указывает на то, что информация сжимается и становится более абстрактной, что влияет на способность модели к обобщению и решению различных задач.
Анализ показал, что вычислительная организация больших языковых моделей (LLM) характеризуется двухфазным принципом. В начальных слоях (~первые 2/3 слоев) более эффективны интервенции, ориентированные на входные данные (input-centric), то есть манипуляции с входными токенами. В поздних слоях (~последняя 1/3 слоев) доминируют интервенции, ориентированные на предсказание (prediction-centric), подразумевающие вмешательства в процесс генерации выходных токенов. Это разделение указывает на то, что начальные слои LLM преимущественно обрабатывают и кодируют входную информацию, в то время как поздние слои больше сосредоточены на использовании этой информации для формирования предсказаний и генерации текста.
Управляя Мыслью Модели: Интервенционный Анализ
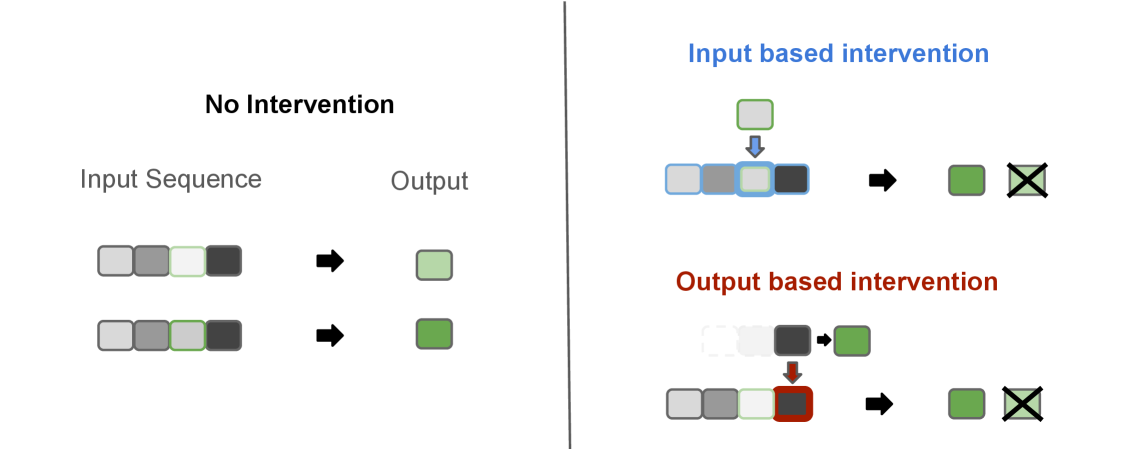
Интервенционный анализ больших языковых моделей (LLM) заключается в намеренном изменении внутренних представлений модели — активаций нейронов на различных слоях — и последующем наблюдении за изменениями в генерируемом прогнозе. Этот метод позволяет выявить причинно-следственные связи между конкретными внутренними представлениями и выходными данными. Путем введения контролируемых возмущений и анализа результирующих изменений в прогнозах, исследователи могут определить, какие части модели наиболее важны для принятия определенных решений или генерации конкретного текста. Такой подход отличается от простой корреляции, поскольку позволяет оценить, как изменение внутреннего представления приводит к изменению выходных данных, выявляя, таким образом, причинные связи, а не просто статистические зависимости.
В рамках анализа, основанного на вмешательствах, применяются два основных подхода к модификации внутренних представлений языковой модели. Входно-ориентированное вмешательство (Input-Centric Intervention) предполагает изменение представления входных токенов, то есть векторов, представляющих слова или части слов, на входе модели. Выходно-ориентированное вмешательство (Output-Centric Intervention) воздействует непосредственно на финальный слой модели, изменяя вероятности предсказания следующего токена. Оба подхода позволяют оценить, как изменения в конкретных частях модели влияют на конечный результат, однако отличаются целевыми областями воздействия — входные представления против вероятностей предсказания.
Задача «Месяцы» (Months Task) представляет собой надежный эталон для оценки влияния интервенций на производительность языковых моделей. Она заключается в предсказании следующего месяца в последовательности, что требует от модели сохранения и обработки информации о временной последовательности. Устойчивость данной задачи к незначительным изменениям входных данных и четкая однозначность правильного ответа позволяют точно измерить, как различные интервенции — будь то изменение представления входных токенов или прямое влияние на конечный прогноз — сказываются на способности модели к логическому выводу и запоминанию фактов. Высокая воспроизводимость результатов, полученных при использовании «Месяцев», делает её ценным инструментом для сравнительного анализа эффективности различных методов интервенционного анализа.
Анализ показал значимую положительную корреляцию между угловым расстоянием (Angular Distance) и расхождением предсказаний в поздних слоях языковой модели. В то время как евклидово расстояние (Euclidean Distance) не демонстрирует стабильной корреляции с расхождением предсказаний. Это указывает на то, что угловая геометрия играет важную роль в процессе предсказания на более поздних этапах обработки информации в модели, в отличие от простой величины вектора.
К Механистическому Пониманию и Надежным Языковым Моделям
Механистическая геометрия представляет собой расширение существующих методов анализа больших языковых моделей (LLM), устанавливающее прямую связь между геометрией представлений и причинно-следственным контролем над предсказаниями модели. В отличие от традиционных подходов, которые сосредотачиваются на корреляциях, данный метод позволяет исследовать, как конкретные геометрические свойства внутренних представлений влияют на выходные данные. Исследователи обнаружили, что определенные геометрические структуры, такие как углы и расстояния между векторами, кодируют информацию, необходимую для принятия решений моделью. По сути, это позволяет не просто наблюдать за поведением LLM, но и понимать, как модель приходит к тем или иным выводам, открывая возможности для целенаправленных вмешательств и оптимизации, а также повышения надежности и обобщающей способности.
Понимание взаимосвязей между внутренним представлением знаний в больших языковых моделях и их способностью к прогнозированию открывает возможности для целенаправленных и эффективных вмешательств. Исследования показывают, что, манипулируя определенными аспектами внутреннего представления, можно значительно повысить устойчивость модели к различным помехам и искажениям входных данных. Это позволяет не только улучшить точность прогнозов в стандартных условиях, но и обеспечить более надежную работу в нестандартных ситуациях, а также расширить возможности обобщения на новые, ранее не встречавшиеся данные. Таким образом, целенаправленное вмешательство в структуру представления знаний становится ключевым инструментом для создания более надежных и универсальных языковых моделей.
Современные языковые модели, такие как Llama, Mistral и Qwen, демонстрируют значительное улучшение характеристик благодаря применению методов, обеспечивающих детальный контроль и оптимизацию их работы. Эти техники позволяют исследователям не просто оценивать производительность модели, но и целенаправленно изменять её внутренние представления и механизмы принятия решений. В результате, становится возможным точное выявление и коррекция слабых мест, повышение устойчивости к нежелательным входным данным и улучшение способности к обобщению знаний. Такой подход открывает новые перспективы для создания более надежных и эффективных систем искусственного интеллекта, способных решать сложные задачи с высокой точностью и предсказуемостью.
Исследования показали, что вычислительная организация больших языковых моделей (LLM) характеризуется двухфазным принципом. Более поздние слои нейронной сети демонстрируют угловую геометрию, которая напрямую связана с формированием предсказаний — то есть, именно в этих слоях происходит кодирование информации, определяющей результат работы модели. В то же время, ранние слои сети специализируются на обработке контекста и поступающей информации, но не оказывают непосредственного влияния на финальное предсказание. Данная архитектура предполагает, что модель последовательно обрабатывает информацию: сначала извлекает и кодирует контекст, а затем, на поздних этапах, использует эту информацию для генерации предсказаний, что позволяет повысить точность и надежность работы LLM, таких как Llama, Mistral и Qwen.

Исследование демонстрирует, что поздние слои больших языковых моделей организуют представления угловым образом, что тесно связано с предсказаниями. Этот феномен подтверждает идею о том, что структура определяет поведение системы. Как отмечал Брайан Керниган: «Простота — это высшая степень утонченности». В контексте данной работы, угловая организация поздних слоев можно рассматривать как воплощение этой простоты, позволяющее модели эффективно кодировать информацию, необходимую для прогнозирования. Более ранние слои, обладающие более общими геометрическими свойствами, служат фундаментом, но именно угловая структура поздних слоев оказывает непосредственное влияние на предсказательную способность модели, формируя ее поведение во времени.
Куда дальше?
Представленные данные указывают на любопытную закономерность: угловая организация представлений в поздних слоях больших языковых моделей не является случайным артефактом, но тесно связана с предсказательной способностью. Однако, возникает вопрос: является ли это финальной формой организации знаний, или же более глубокие принципы лежат в основе, проявляясь лишь на определённых уровнях абстракции? Простое выявление геометрической структуры, пусть и причинно связанной с предсказанием, не объясняет, как эта структура возникает и поддерживается в процессе обучения.
Более того, акцент на поздних слоях оставляет без внимания потенциальную роль ранних, более общих геометрических свойств. Возможно, именно в этих слоях кроется ключ к пониманию того, как модель формирует базовое представление о мире, а поздние слои лишь специализируются на прогнозировании, подобно надстройке над прочным фундаментом. Необходимо исследовать, как информация «течёт» между слоями, и как эти различные геометрические представления взаимодействуют друг с другом.
Наконец, важно помнить о предельности любой модели. Углы и расстояния — удобные инструменты анализа, но они не являются самим знанием. Истинное понимание требует выхода за рамки геометрических аналогий и обращения к более фундаментальным принципам когнитивной архитектуры. В противном случае, рискуем увидеть лишь отражение в зеркале, а не саму реальность.
Оригинал статьи: https://arxiv.org/pdf/2602.04931.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Самообучающиеся признаки: новый подход к машинному обучению
- Быстрый поиск похожих объектов: GPU-ускорение с IVF-RaBitQ
- Моделирование биомолекул: новый импульс от нейросетей
- Квантовая механика: скрытый детерминизм?
- Искусственный интеллект: хрупкость визуального мышления
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Защита от вредоносных данных в федеративном обучении: новый подход
2026-02-08 17:10