Автор: Денис Аветисян
Исследователи предлагают метод, позволяющий системам искусственного интеллекта более эффективно использовать знания, представленные в виде графов, для формирования более точных и логичных ответов.
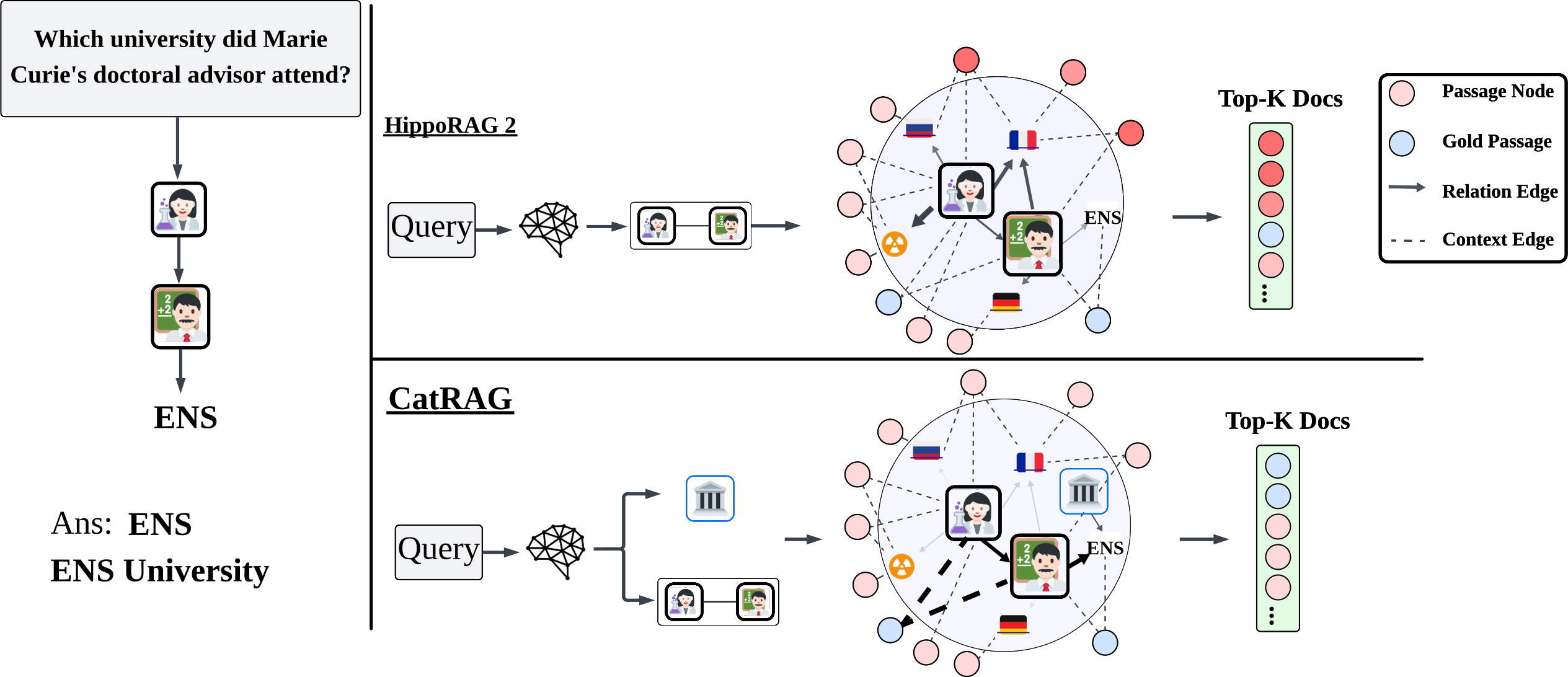
Предложенная архитектура CatRAG адаптирует обход графа знаний в зависимости от контекста запроса, повышая устойчивость к семантическому дрейфу и улучшая многошаговое рассуждение.
Несмотря на успехи в области генеративных моделей с расширением поиска (RAG), существующие подходы часто сталкиваются с проблемой семантического отклонения при обходе графов знаний. В работе ‘Breaking the Static Graph: Context-Aware Traversal for Robust Retrieval-Augmented Generation’ предложен новый фреймворк CatRAG, направленный на решение этой проблемы путем адаптации графа знаний к контексту запроса. CatRAG использует символьное закрепление, динамическое взвешивание ребер и усиление ключевых фактов для обеспечения более эффективного обхода графа и улучшения многоступенчатого рассуждения. Способна ли эта технология преодолеть разрыв между частичным поиском контекста и обеспечением полностью обоснованного вывода?
Пределы Плотного Поиска: Семантический Сдвиг
Традиционные методы плотного поиска информации, несмотря на свою эффективность в извлечении релевантных документов, сталкиваются с серьезными ограничениями при решении задач, требующих сложного логического вывода и анализа длинных текстов. Суть проблемы заключается в так называемом «семантическом дрейфе» — постепенном отклонении от первоначального смысла запроса по мере углубления в поисковое пространство. Этот дрейф возникает из-за неспособности моделей улавливать тонкие нюансы и контекстуальные связи в длинных документах, что приводит к извлечению фрагментов, лишь косвенно связанных с исходным вопросом. В результате, система может предоставлять информацию, формально соответствующую ключевым словам, но фактически не отвечающую на суть запроса или вводящую в заблуждение. Таким образом, хотя плотные векторы и позволяют быстро находить семантически близкие документы, их применение в задачах, требующих глубокого понимания и логического вывода, требует осторожности и дополнительных механизмов для предотвращения семантического дрейфа.
Статичные графовые структуры, используемые в системах поиска, зачастую усугубляют проблему отхода от релевантных данных. В то время как знания постоянно развиваются и взаимосвязи становятся все более сложными, фиксированные графы не способны адаптироваться к нюансам запросов и многогранности отношений между фактами. Это приводит к тому, что система не может правильно интерпретировать сложные вопросы, требующие анализа взаимосвязанных данных, и в итоге предоставляет неполные или неточные ответы. Неспособность динамически перестраиваться и учитывать контекст запроса ограничивает эффективность поиска и снижает надежность извлекаемой информации, особенно при работе с большими объемами знаний и сложными темами.
Ограничения, присущие фиксированным графовым структурам и плотным векторным представлениям, существенно затрудняют извлечение полных цепочек доказательств, что негативно сказывается на надежности получаемой информации. Традиционные методы, оперирующие статичными графами, не способны адаптироваться к нюансам запросов и сложным взаимосвязям внутри массива знаний. В результате, система может упускать важные звенья в логической цепи, приводя к неполным или неверным выводам. Неспособность динамически отслеживать и учитывать контекст, а также ограничения, связанные с фиксированным размером векторов, препятствуют эффективному поиску и объединению релевантных доказательств, что особенно критично при решении сложных задач, требующих глубокого анализа и многоступенчатых рассуждений.
Графы Знаний: Создание Семантической Основы
Графы знаний представляют собой мощную альтернативу традиционным методам представления информации, поскольку они явно моделируют сущности и связи между ними. В отличие от подходов, полагающихся на статистические корреляции в тексте, графы знаний фиксируют семантические отношения, позволяя улавливать долгосрочные зависимости, которые могут быть скрыты в локальном контексте. Это достигается путем представления знаний в виде узлов (сущностей) и ребер (связей), что позволяет системе логически выводить информацию и устанавливать связи между удаленными концепциями, недоступные при анализе только последовательных текстовых фрагментов. Такая структура позволяет эффективно выполнять сложные запросы и анализировать данные, требующие понимания взаимосвязей между различными элементами информации.
Методы извлечения информации открытого типа (OpenIE) автоматизируют процесс построения графов знаний из неструктурированного текста. Эти методы идентифицируют сущности и отношения между ними непосредственно из текста, без предварительного определения схемы или онтологии. Алгоритмы OpenIE обычно используют лингвистический анализ, такой как части речи и синтаксический разбор, для выявления триплетов вида (сущность1, отношение, сущность2). Извлеченные триплеты затем используются для создания графа, где сущности являются узлами, а отношения — ребрами. Автоматизация этого процесса значительно упрощает организацию и структурирование больших объемов текстовых данных, позволяя создавать базы знаний без ручного ввода и кураторства.
Структурирование информации в виде графа знаний значительно расширяет возможности Structure-Aware RAG (Retrieval-Augmented Generation) за счет предоставления более богатого контекста для поиска и генерации ответов. В отличие от традиционных методов, которые полагаются на поверхностное соответствие ключевых слов, Structure-Aware RAG, использующий граф знаний, способен учитывать семантические связи между сущностями и отношениями. Это позволяет извлекать информацию, которая может быть неявно связана с запросом, но имеет важное значение для формирования полного и точного ответа. Учет структуры знаний повышает релевантность извлеченных документов и уменьшает вероятность получения неточной или вводящей в заблуждение информации, особенно в сложных предметных областях.
HippoRAG & CatRAG: Динамическая Навигация для Надежного RAG
HippoRAG использует алгоритм Personalized PageRank, применяемый к графам знаний, для моделирования ассоциативной памяти и улучшения релевантности извлечения информации. В отличие от традиционных методов поиска, Personalized PageRank учитывает индивидуальные предпочтения пользователя и контекст запроса, позволяя устанавливать связи между разрозненными фактами в графе знаний. Это достигается путем присвоения каждому узлу (факту) веса, отражающего его значимость и связь с другими узлами, что позволяет алгоритму находить наиболее релевантные факты, даже если они не находятся в непосредственной близости от исходного запроса. Такой подход способствует более полному и контекстно-зависимому извлечению информации из графа знаний.
CatRAG развивает функциональность HippoRAG за счет внедрения продвинутых методов, таких как динамическое взвешивание ребер с учетом запроса (Query-Aware Dynamic Edge Weighting) и повышение значимости отрывков, содержащих ключевые факты (Key-Fact Passage Weight Enhancement). Эти техники позволяют системе осуществлять навигацию по графу знаний, ориентируясь на конкретный запрос пользователя и повышая релевантность извлекаемой информации. Динамическое взвешивание ребер корректирует важность связей между узлами графа в зависимости от содержания запроса, а усиление ключевых фактов в отрывках текста позволяет выделить наиболее значимую информацию для ответа на запрос.
Для повышения стабильности процесса поиска и снижения семантического дрейфа, CatRAG использует метод символьной привязки (Symbolic Anchoring). Данный метод предполагает создание слабых топологических якорей внутри графа знаний, что позволяет удерживать вектор поиска в пределах релевантных данных. В результате применения символьной привязки, CatRAG демонстрирует показатель Full Chain Retrieval в 34.6%, что на 4.1% выше, чем у HippoRAG 2 (30.5%). Это свидетельствует о значительном улучшении способности CatRAG к полному извлечению цепочки релевантной информации.
Улучшение Производительности: Плотные Векторы и Иерархические Структуры
Современные системы поиска информации все чаще используют комбинацию плотных векторных представлений и графовых структур для повышения эффективности и релевантности извлечения данных. Методы, такие как E5-Mistral, NV-Embed и GritLM, позволяют кодировать информацию в компактные векторные представления, что значительно ускоряет процесс поиска. Однако, для работы со сложными взаимосвязями между данными, эти векторы интегрируются с графовыми структурами, формируя систему, способную не только быстро находить релевантные фрагменты, но и учитывать контекст и связи между ними. Такой подход позволяет значительно улучшить начальную релевантность результатов поиска, предоставляя пользователю более точную и полезную информацию.
Методы LightRAG и RAPTOR наглядно демонстрируют преимущества иерархической организации в рамках Structure-Aware RAG, позволяя эффективно ориентироваться в сложных информационных ландшафтах. Вместо последовательного поиска по всему корпусу знаний, эти системы строят многоуровневую структуру, где информация организована по категориям и взаимосвязям. Это позволяет значительно ускорить процесс поиска, фокусируясь на наиболее релевантных разделах и избегая избыточного анализа. Благодаря такому подходу, системы способны не только быстро находить нужную информацию, но и более эффективно использовать контекст, что особенно важно при решении сложных задач, требующих глубокого понимания взаимосвязей между различными фактами и понятиями. Иерархическая организация позволяет эффективно обходить большие объемы данных, имитируя способ, которым человек структурирует и использует знания.
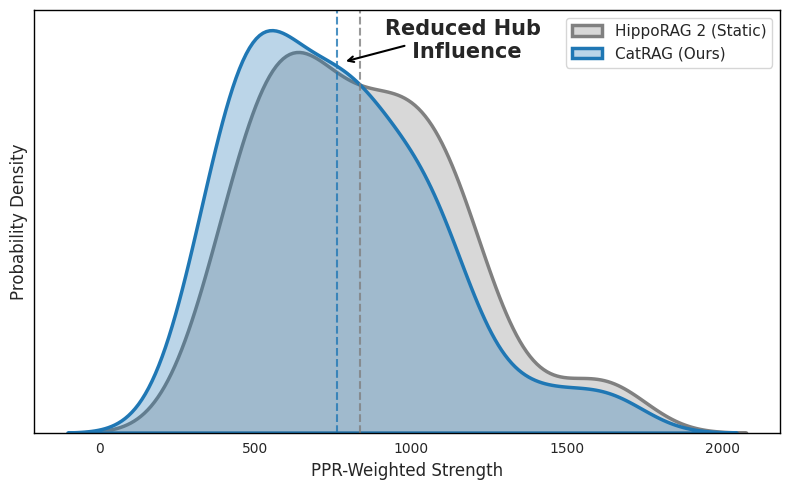
Сочетание сильных сторон плотных векторных представлений и графовых структур демонстрирует значительное повышение эффективности в задачах, требующих сложного рассуждения. В частности, система CatRAG достигает общего показателя успешности в 31.1%, что на 18.7% выше, чем у HippoRAG 2. При оценке качества извлечения информации, показатель Recall@5 на наборе данных MuSiQue улучшается до 64.9% (превышая аналогичный показатель стандартного плотного извлекателя на 8.1%), а на HotpotQA достигает 89.5%. Кроме того, наблюдается снижение показателя Mean PPR-Weighted Strength до 761.7 по сравнению с 837.0, что свидетельствует о снижении предвзятости, связанной с концентрацией внимания на отдельных узлах информации.
Представленная работа демонстрирует стремление к упрощению сложных систем извлечения знаний. Авторы предлагают CatRAG — подход, динамически адаптирующий обход графа знаний в зависимости от контекста запроса. Это позволяет нивелировать семантический дрейф, часто возникающий при многошаговом рассуждении. Как однажды заметил Дональд Дэвис: «Простота — высшая форма изысканности». В данном случае, элегантность решения заключается в отказе от статических графов в пользу контекстно-зависимого обхода, что позволяет более эффективно использовать знания и повысить точность ответов, генерируемых LLM. Такой подход отражает стремление к ясности и функциональности, а не к излишнему усложнению.
Куда Далее?
Представленная работа, стремясь обуздать неустойчивость семантического поиска в графах знаний, лишь обнажает глубинную проблему: иллюзию полноты. Каждый пройденный «хоп» в графе, каждое извлечение информации — это шаг к упрощению, к навязыванию структуры хаосу. Успех CatRAG, если он будет подтвержден, не в совершенствовании алгоритма обхода графа, а в искусстве признания его недостатков. Следующим этапом видится не углубление в многоходовой анализ, а поиск способов работы с неполнотой, с двусмысленностью, с тем, что неизбежно ускользает от формализации.
Очевидным ограничением является зависимость от качества исходного графа знаний. Но куда более фундаментальная проблема — в самом представлении знания как набора дискретных узлов и связей. Будущие исследования должны быть направлены на разработку систем, способных работать с «размытыми» графами, с вероятностными связями, с представлениями знания, которые не стремятся к исчерпывающей точности, а признают свою собственную ограниченность.
В конечном счете, совершенство в этой области — это не достижение максимальной производительности, а исчезновение автора из процесса. Система, которая не нуждается в постоянной корректировке, в ручном управлении, в искусственном интеллекте, — вот истинная цель. Стремление к «интеллекту» лишь уводит от сути: простоты, ясности, и признания того, что любое знание — это всегда лишь приближение к истине.
Оригинал статьи: https://arxiv.org/pdf/2602.01965.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Самообучающиеся признаки: новый подход к машинному обучению
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Математический интеллект: как улучшить навыки решения задач у больших языковых моделей
- Биомолекулярные связи: новый тест для искусственного интеллекта
2026-02-08 18:37