Автор: Денис Аветисян
Исследователи разработали усовершенствованный механизм, позволяющий проводить конфиденциальный анализ огромных массивов данных с повышенной скоростью и точностью.
В статье представлен метод AIM+GReM, использующий остаточные запросы и эффективный алгоритм реконструкции для улучшения масштабируемости и производительности дифференциально-приватного анализа.
Несмотря на значительный прогресс в области дифференциальной приватности, эффективная обработка запросов к крупным табличным данным остается сложной задачей. В работе ‘Fast Private Adaptive Query Answering for Large Data Domains’ предложен новый механизм AIM+GReM, использующий остаточные запросы и оптимизированный алгоритм реконструкции для существенного повышения производительности и масштабируемости при ответах на запросы о маржинальных распределениях. Ключевым нововведением является применение многомерных массивов для представления остаточных запросов и адаптивное распределение бюджета приватности, что позволяет снизить погрешность и ускорить процесс. Каковы перспективы дальнейшей оптимизации механизмов дифференциальной приватности для анализа все более масштабных и сложных наборов данных?
Вызов Маргинальных Запросов: Баланс между Знанием и Конфиденциальностью
Анализ данных зачастую требует ответа на так называемые «маргинальные запросы» — вопросы, направленные на определение распределения конкретных характеристик внутри исследуемого набора. Представьте, что необходимо выяснить, какова доля пользователей определенного возраста в онлайн-игре, или какое процентное соотношение различных типов товаров предпочитают покупатели интернет-магазина. Эти запросы, касающиеся распределения отдельных признаков, позволяют выявить ключевые тенденции и закономерности, необходимые для принятия обоснованных решений в различных областях — от маркетинга и экономики до здравоохранения и социальных наук. По сути, маргинальные запросы представляют собой фундаментальный инструмент для извлечения полезной информации из больших объемов данных, позволяя исследователям и аналитикам понять, как устроена изучаемая система и какие факторы на нее влияют.
Традиционные методы ответа на краевые запросы, направленные на анализ распределения определенных характеристик в данных, зачастую сопряжены с риском раскрытия конфиденциальной информации. Принципы работы многих алгоритмов, требующих детального изучения статистических свойств набора данных, могут непреднамеренно выявить индивидуальные данные, даже если прямая идентификация отсутствует. Например, анализ частоты встречаемости редких комбинаций признаков может позволить восстановить информацию об отдельных участниках исследования. В связи с этим, существующие подходы нуждаются в усилении мер защиты, гарантирующих соблюдение конфиденциальности и предотвращающих несанкционированный доступ к личным данным, что является критически важным для поддержания доверия к системам анализа данных и соблюдения этических норм.
Современная наука о данных сталкивается с фундаментальной проблемой: необходимо найти баланс между полезностью информации, извлекаемой из данных, и строгими гарантиями конфиденциальности. Анализ данных, направленный на получение ценных знаний, часто требует ответов на вопросы о распределении определенных признаков, однако прямое раскрытие такой информации может нарушить приватность отдельных лиц или организаций. Разработка методов, позволяющих получать статистически значимые результаты, не раскрывая при этом конфиденциальные данные, представляет собой сложную задачу, требующую инновационных подходов в области криптографии, статистики и машинного обучения. Эффективное решение этой проблемы является ключевым для обеспечения широкого и ответственного использования данных в различных областях, от здравоохранения и финансов до маркетинга и социальных исследований.
AIM: Адаптивная Реконструкция для Усиленной Приватности
Механизм адаптации в AIM (Adaptive Reconstruction for Enhanced Privacy) функционирует путем динамической настройки процесса реконструкции данных в зависимости от характеристик как входных данных, так и конкретного запроса. Это означает, что система анализирует статистические свойства данных и сложность запроса, чтобы выбрать оптимальную стратегию реконструкции. В частности, AIM может переключаться между использованием Gaussian Residual Maximization (GReM) и Private Graphical Model (Private_PGM) в зависимости от этих характеристик, что позволяет достичь баланса между скоростью вычислений, точностью ответа на запрос и уровнем защиты конфиденциальности данных. Такой подход позволяет эффективно использовать вычислительные ресурсы и минимизировать потери точности при обработке различных типов данных и запросов.
Метод AIM выполняет реконструкцию распределения данных, используя один из двух подходов: Gaussian Residual Maximization (GReM) или Private Graphical Model (Private_PGM). GReM является методом, основанным на гауссовских моделях, и позволяет эффективно восстановить данные с минимальными потерями информации. Private_PGM, в свою очередь, использует частные графические модели для представления зависимостей между переменными, обеспечивая дополнительную защиту конфиденциальности. Выбор между GReM и Private_PGM зависит от конкретных характеристик данных и требований к уровню конфиденциальности и скорости обработки.
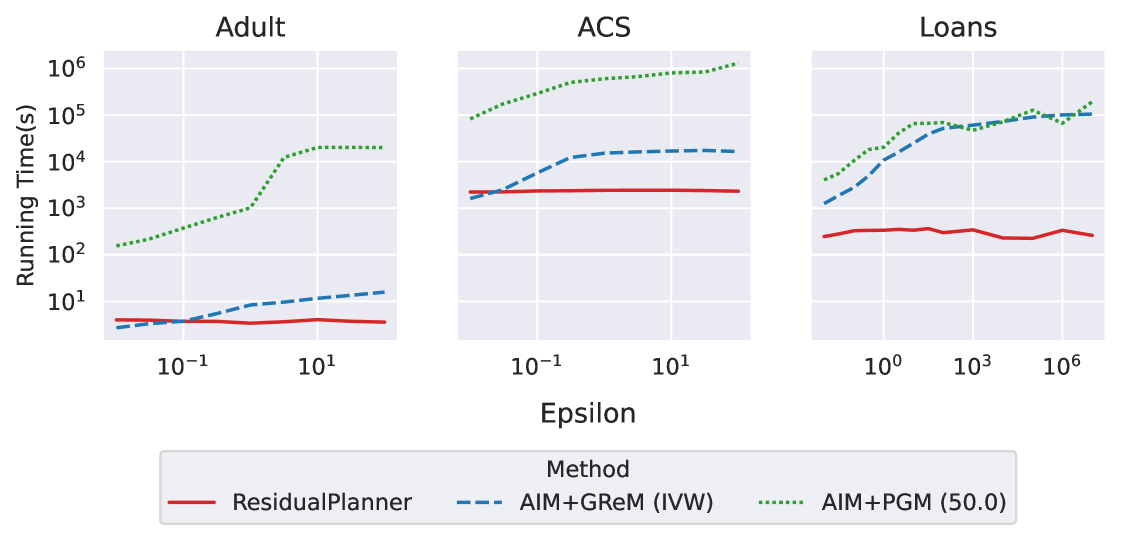
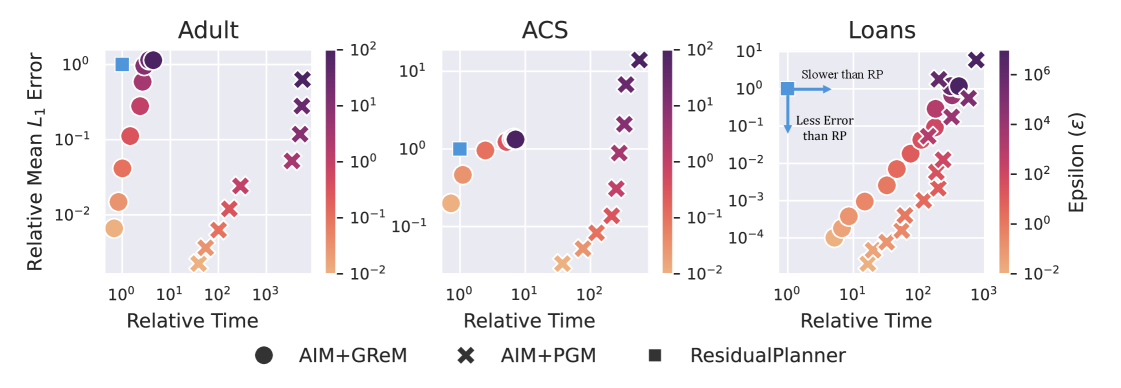
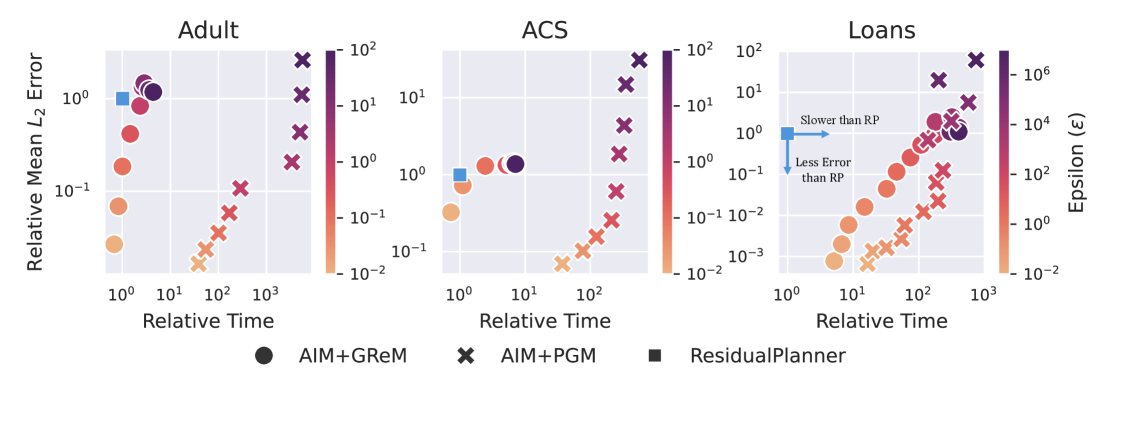
Восстановление данных, реализованное в AIM, позволяет отвечать на маргинальные запросы с минимальной потерей конфиденциальности, что повышает полезность данных. В частности, комбинация AIM и алгоритма Gaussian Residual Maximization (GReM) демонстрирует значительное ускорение работы по сравнению с ResidualPlanner — до 697 раз на наборе данных ACS. Это достигается за счет адаптивной реконструкции, которая оптимизирует процесс для конкретных характеристик данных и запроса, позволяя эффективно извлекать информацию при сохранении приватности.
Результаты экспериментов демонстрируют существенное снижение времени выполнения алгоритма AIM при использовании метода Gaussian Residual Maximization (GReM) по сравнению с Private Graphical Model (Private_PGM). Данное преимущество наблюдается на всех протестированных наборах данных и при различных бюджетах конфиденциальности. В частности, использование GReM позволяет значительно ускорить процесс реконструкции данных, что критически важно для приложений, требующих оперативного анализа больших объемов информации с сохранением приватности. Разница во времени выполнения между AIM+GReM и AIM+PGM является стабильной и значимой, что подтверждает эффективность GReM как более производительного подхода в рамках данной архитектуры.
GReM: Гауссовские Остатки и Эффективная Реконструкция
GReM (Gaussian Residual Maximization) использует итеративный процесс максимизации правдоподобия для восстановления распределения данных, основываясь на гауссовских остатках. Данный подход позволяет эффективно реконструировать данные даже при ограниченном объеме исходной информации. В отличие от традиционных методов, GReM фокусируется на моделировании остатков после применения базового преобразования, что позволяет снизить вычислительную сложность и повысить скорость реконструкции. Алгоритм предполагает последовательное уточнение параметров гауссовского распределения остатков, стремясь к минимизации расхождения между реконструированными и исходными данными. p(x) = \mathcal{N}(\mu, \Sigma) — представление гауссовского распределения, используемого в процессе реконструкции.
Восстановление данных в GReM оптимизируется за счет применения математических операций InAxisTransformation и KroneckerProduct. InAxisTransformation позволяет эффективно преобразовывать данные для последующей обработки, снижая вычислительную сложность. Использование KroneckerProduct обеспечивает компактное представление данных и ускоряет матричные операции, необходимые для реконструкции. В результате данной оптимизации, GReM демонстрирует ускорение до 3.75x по сравнению с базовым алгоритмом Shuffle при выполнении аналогичных задач по восстановлению данных.
GReM использует механизм Zero-Concentrated Differential Privacy (zCDP) для обеспечения надежной защиты конфиденциальности данных. zCDP гарантирует, что вероятность любого конкретного результата, полученного из приватного механизма, не сильно отличается от вероятности того же результата, полученного из исходных данных. Это достигается путем добавления контролируемого шума к данным, при этом zCDP позволяет более точно контролировать величину этого шума, обеспечивая более сильные гарантии конфиденциальности по сравнению с традиционной дифференциальной приватностью. В GReM, zCDP позволяет минимизировать влияние добавленного шума на точность реконструируемых данных, сохраняя при этом высокую степень защиты персональной информации.
Эффективное распределение шума (Noise Allocation) посредством ResidualPlanner является ключевым фактором для достижения баланса между конфиденциальностью и точностью в процессе реконструкции данных. ResidualPlanner динамически определяет количество шума, добавляемого к различным компонентам данных, основываясь на их вкладе в общую функцию потерь. Этот подход позволяет минимизировать влияние шума на наиболее важные аспекты данных, сохраняя их информативность, при одновременном обеспечении строгих гарантий дифференциальной приватности. Оптимизация распределения шума осуществляется путем анализа остатков (residuals) после каждой итерации реконструкции, что позволяет точно настроить уровень шума для каждого компонента данных и добиться оптимального соотношения между конфиденциальностью и полезностью данных. ε и δ — параметры, определяющие уровень приватности, напрямую зависят от стратегии Noise Allocation, реализованной в ResidualPlanner.
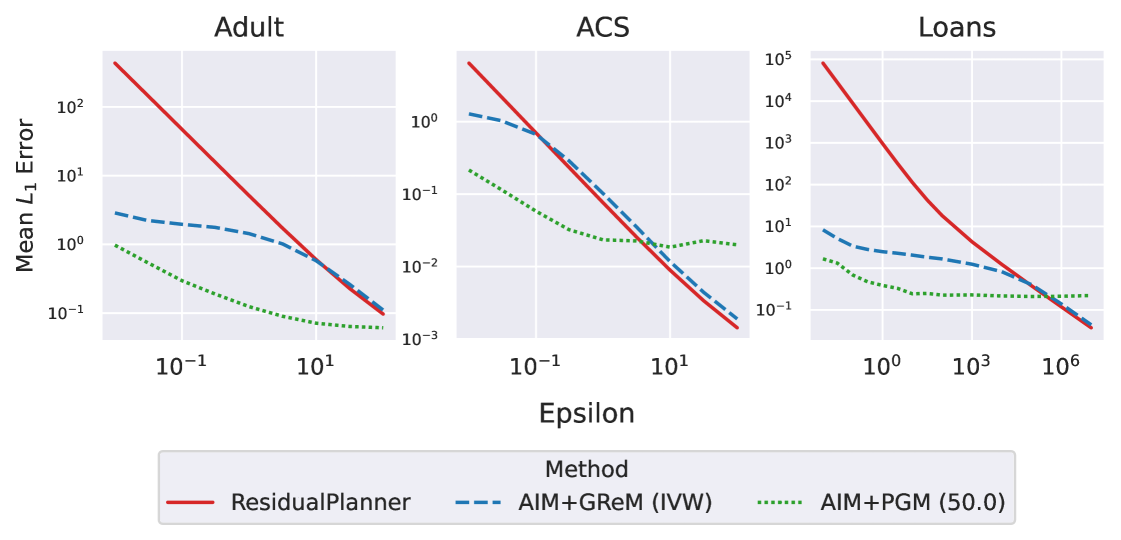
Результаты экспериментов показывают, что алгоритм AIM+GReM демонстрирует сопоставимую или более низкую среднюю абсолютную ошибку (Mean L1 Error) по сравнению с алгоритмами ResidualPlanner и AIM+PGM на различных наборах данных. Данный показатель позволяет оценить точность реконструкции данных, и более низкое значение указывает на более высокую точность. Сравнение производилось на нескольких стандартных датасетах для обеспечения статистической значимости результатов, подтверждая эффективность GReM в задачах реконструкции с сохранением конфиденциальности.
Практическое Применение Приватности и Полезности
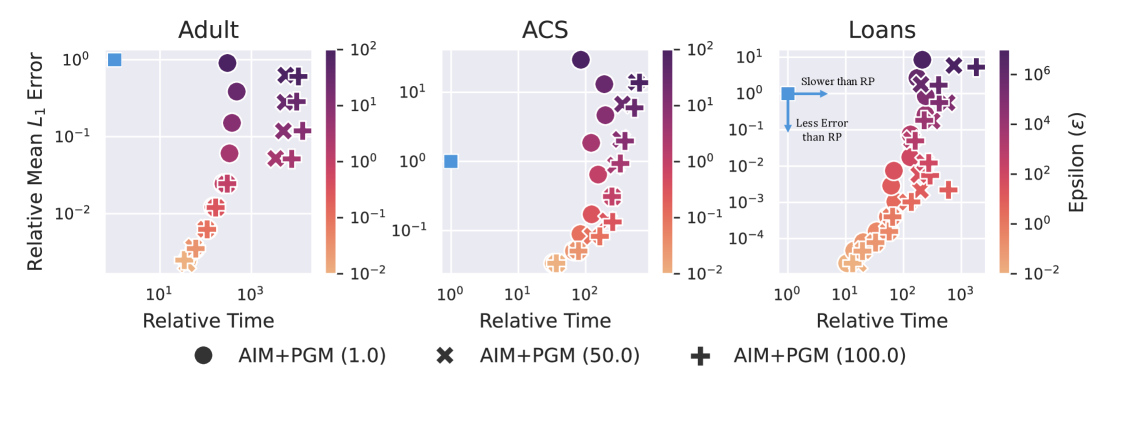
Метод AIM, основанный на использовании GReM и Private_PGM, демонстрирует существенный прогресс в достижении баланса между конфиденциальностью данных и полезностью получаемых результатов анализа. В отличие от традиционных подходов, которые часто вынуждают выбирать между строгой защитой персональной информации и точностью статистических оценок, AIM позволяет существенно улучшить оба показателя одновременно. Это достигается благодаря адаптивному механизму, который динамически подстраивается под особенности конкретного набора данных и типа запроса, минимизируя утечку информации, сохраняя при этом высокую степень достоверности полученных результатов. В результате, анализ конфиденциальных данных становится не только более безопасным, но и более информативным, открывая новые возможности для исследований в таких областях, как здравоохранение, финансы и социальные науки.
Механизм, используемый в данной работе, отличается своей адаптивностью, что позволяет ему демонстрировать высокую эффективность при анализе разнообразных наборов данных и типов запросов. В отличие от традиционных подходов, требующих жесткой настройки параметров для каждого конкретного случая, данный механизм способен автоматически корректировать свою работу в зависимости от характеристик входных данных и специфики запроса. Это достигается благодаря использованию динамических алгоритмов, которые позволяют оптимизировать баланс между конфиденциальностью и полезностью информации. Такая гибкость особенно важна при работе с данными, полученными из различных источников и имеющих разную структуру, а также при решении задач, требующих обработки сложных и неоднородных запросов. В результате, обеспечивается стабильно высокая производительность и точность анализа даже в условиях значительной изменчивости данных и типов запросов.
Предложенный подход открывает принципиально новые возможности для анализа конфиденциальных данных в таких критически важных областях, как здравоохранение, финансы и социальные науки. Благодаря повышенному уровню защиты приватности при сохранении полезности информации, становится возможным проводить исследования и получать ценные выводы из данных, которые ранее были недоступны из-за соображений конфиденциальности. В медицине это может означать выявление закономерностей в данных о пациентах для разработки более эффективных методов лечения, в финансовом секторе — обнаружение мошеннических операций, а в социальных науках — изучение сложных социальных явлений без нарушения прав на неприкосновенность частной жизни. Такой баланс между защитой данных и аналитической ценностью позволяет существенно расширить горизонты научных исследований и принятия обоснованных решений в различных сферах деятельности.
Исследование, представленное в статье, демонстрирует стремление к элегантности в обработке данных, особенно в контексте дифференциальной приватности. Авторы предлагают механизм AIM+GReM, который оптимизирует баланс между конфиденциальностью и полезностью, используя остаточные запросы и эффективный алгоритм реконструкции. Этот подход напоминает принцип, высказанный Джоном Маккарти: «Всякое решение либо корректно, либо ошибочно — промежуточных состояний нет.» В данном случае, корректность решения определяется не только точностью ответа на запрос, но и гарантией сохранения конфиденциальности данных. Авторы, подобно математикам, доказывающим теорему, стремятся к построению алгоритма, который будет доказуемо корректным, а не просто «работать на тестах», обеспечивая тем самым надёжность и предсказуемость системы даже при работе с большими объемами данных.
Что дальше?
Представленный механизм AIM+GReM, несомненно, представляет собой шаг вперед в области дифференциальной приватности, однако истинная элегантность алгоритма всегда проявляется в его границах. Вопрос о масштабируемости для действительно огромных доменов данных, где количество запросов стремится к бесконечности, остается открытым. Попытки оптимизации реконструкции, безусловно, важны, но не решают фундаментальной проблемы: каждая операция, даже самая эффективная, все равно вносит вклад в общую погрешность.
Будущие исследования, вероятно, будут сосредоточены на разработке методов, позволяющих уменьшить эту неизбежную погрешность без ущерба для приватности. Интересным направлением представляется изучение адаптивных механизмов, способных динамически регулировать уровень шума в зависимости от характеристик данных и типа запроса. Но следует помнить: совершенство недостижимо. Цель состоит не в том, чтобы создать абсолютно приватный и абсолютно точный алгоритм, а в том, чтобы найти оптимальный баланс между этими двумя противоречивыми требованиями.
В конечном счете, прогресс в этой области зависит от способности взглянуть на проблему с математической строгостью. Любое упрощение, любая эвристика должна быть тщательно обоснована. Иначе мы рискуем создать иллюзию приватности, а не реальную защиту данных. И в этом, возможно, и заключается главный парадокс дифференциальной приватности: стремление к защите данных требует от нас максимальной прозрачности и строгости.
Оригинал статьи: https://arxiv.org/pdf/2602.05674.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Моделирование биомолекул: новый импульс от нейросетей
- Искусственный интеллект: хрупкость визуального мышления
- Квантовая запутанность спиновых кубитов: новый резонансный подход
- Табулярные данные: новый взгляд на обучение без учителя
2026-02-08 22:12