Автор: Денис Аветисян
Исследователи представили UniAudio 2.0 — универсальную модель для обработки звука, способную понимать и создавать аудиоконтент, подобно тому, как языковые модели работают с текстом.
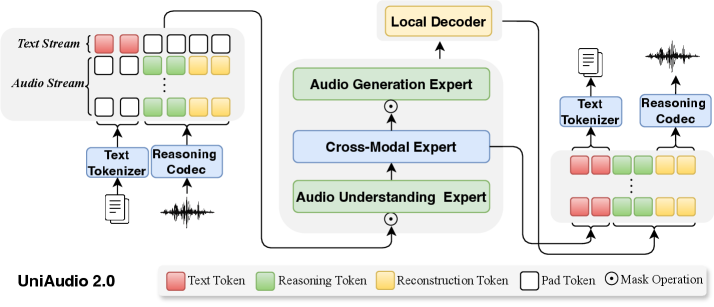
UniAudio 2.0 использует новый дискретный аудио-токенизатор ReasoningCodec и специализированную авторегрессионную архитектуру для достижения высокой производительности в широком спектре задач по обработке и генерации звука.
Несмотря на значительный прогресс в области обработки естественного языка, создание универсальных моделей для понимания и генерации аудио остается сложной задачей. В работе ‘UniAudio 2.0: A Unified Audio Language Model with Text-Aligned Factorized Audio Tokenization’ предложен новый подход к созданию аудио-языковых моделей, основанный на дискретном токенизаторе ReasoningCodec и унифицированной авторегрессионной архитектуре. Разработанная модель UniAudio 2.0, обученная на 100B текстовых и 60B аудио токенов, демонстрирует конкурентоспособные результаты в различных задачах обработки звука, речи и музыки, включая обобщение в условиях ограниченного количества данных. Каковы перспективы масштабирования подобных моделей для решения еще более сложных задач, связанных с анализом и синтезом звуковой информации?
Разрыв между Пониманием и Созданием: К Унифицированной АудиоОбработке
Современные методы обработки звука зачастую сталкиваются с трудностями при одновременном выполнении задач понимания и генерации, что приводит к фрагментированной производительности. Традиционно, системы распознавания речи, анализа звуковых событий и синтеза звука разрабатываются как отдельные компоненты, что ограничивает их способность к комплексному анализу и творчеству. В результате, модель, отлично справляющаяся с расшифровкой речи, может оказаться неэффективной при создании музыкального произведения или идентификации конкретного звука в шумной среде. Эта разрозненность требует значительных вычислительных ресурсов и ограничивает возможности для создания интеллектуальных систем, способных полноценно взаимодействовать со звуковым миром, понимая его нюансы и генерируя реалистичные и осмысленные аудиосигналы.
Разработка единой платформы для обработки звука становится все более актуальной, поскольку существующие подходы часто разделяют задачи понимания и генерации, что приводит к снижению общей эффективности. Предлагаемая концепция подразумевает создание универсальной модели, способной одинаково успешно решать широкий спектр задач — от распознавания речи и анализа звуковых событий до синтеза музыки и генерации реалистичных звуковых эффектов. Такой подход позволяет избежать необходимости обучения отдельных моделей для каждой задачи, что значительно снижает вычислительные затраты и упрощает интеграцию различных аудио-приложений. Более того, единая модель, обучаясь на разнообразных данных, потенциально способна выявлять скрытые взаимосвязи между различными аспектами звука, что открывает новые возможности для инноваций в области искусственного интеллекта и звуковых технологий.
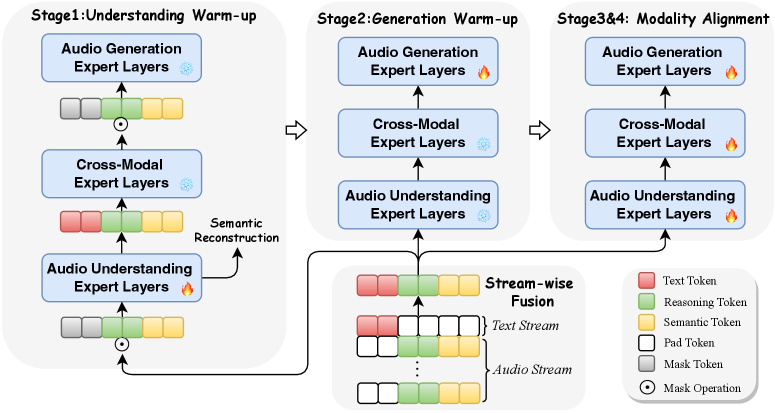
ReasoningCodec: Новый Подход к АудиоПредставлениям
UniAudio 2.0 использует ReasoningCodec, представляющий собой механизм факторизации аудиопредставлений на дискретные токены рассуждения (reasoning tokens) и токены реконструкции (reconstruction tokens) для повышения эффективности обработки. Разделение аудиоданных на эти два типа токенов позволяет модели концентрироваться на семантическом понимании высокого уровня посредством токенов рассуждения, в то время как токены реконструкции сохраняют детальную акустическую информацию. Этот подход позволяет уменьшить вычислительную сложность и объем данных, необходимых для обработки аудио, без потери качества звука, что особенно важно для масштабных задач обработки и обучения моделей.
Разделение аудиопредставления на токены рассуждений и токены реконструкции позволяет модели эффективно обрабатывать аудиоданные на разных уровнях абстракции. Токены рассуждений кодируют семантическую информацию высокого уровня, что способствует пониманию содержания аудио. В то же время, токены реконструкции сохраняют детализированные акустические характеристики, необходимые для точного воссоздания звука. Такая структура позволяет модели одновременно фокусироваться на содержательном анализе и качественном воспроизведении аудиосигнала, обеспечивая оптимальный баланс между семантическим пониманием и акустической точностью.
Представление аудио в дискретном виде, как последовательность токенов, позволяет модели UniAudio 2.0 обрабатывать звуковые данные аналогично текстовым данным. Это принципиально важно для применения методов, успешно зарекомендовавших себя в обработке естественного языка, в частности, масштабного предварительного обучения (pre-training). Традиционные методы работы с аудио, основанные на непрерывных сигналах, затрудняют использование таких подходов. Дискретизация позволяет применять к аудио модели, обученные на больших объемах текстовых данных, и эффективно использовать их возможности для извлечения семантической информации и генерации звука.
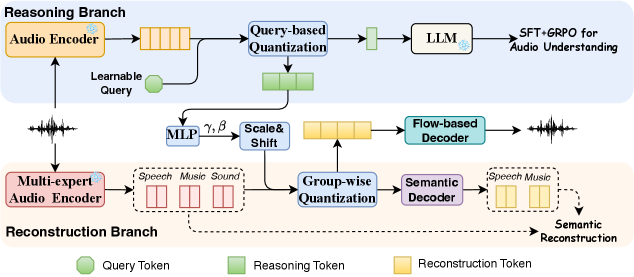
Функциональная Специализация для Оптимальной Производительности
UniAudio 2.0 использует функциональную специализацию слоев (FunctionalLayerSpecialization), разделяя слои трансформера на специализированных экспертов. Данный подход предполагает выделение отдельных модулей, отвечающих за конкретные задачи: понимание аудио, кросс-модальное выравнивание (сопоставление аудио и текста) и генерацию аудио. Каждый эксперт оптимизирован для своей узкоспециализированной функции, что позволяет более эффективно использовать вычислительные ресурсы и повысить общую производительность модели при обработке аудиоданных и связанных с ними задач.
Архитектура UniAudio 2.0 обеспечивает эффективное распределение ресурсов за счет функциональной специализации слоев трансформатора. Разделение на экспертов, каждый из которых обучен конкретной задаче — пониманию аудио, кросс-модальному выравниванию или генерации аудио — позволяет оптимизировать использование вычислительных мощностей. Такой подход способствует повышению производительности, поскольку каждый эксперт фокусируется на узкой области, улучшая точность и скорость обработки данных в рамках своей специализации. Это позволяет модели достигать лучших результатов по сравнению с универсальными слоями трансформатора, выполняющими все задачи одновременно.
В основе UniAudio 2.0 лежит авторегрессионный трансформатор (AutoregressiveTransformer), обеспечивающий последовательную обработку данных, необходимую как для аудио, так и для текстовой информации. Данная архитектура позволяет модели учитывать контекст входных данных, прогнозируя последующие элементы последовательности на основе предыдущих. Последовательная обработка особенно важна для аудио, где временная зависимость между отдельными фрагментами сигнала имеет критическое значение, и для текста, где порядок слов определяет смысл предложения. Использование авторегрессионного подхода позволяет эффективно моделировать сложные зависимости в данных и генерировать когерентные выходные последовательности.
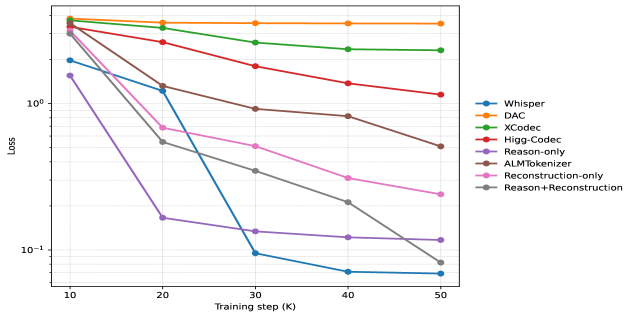
Масштабное Обучение и Семантическое Обогащение
UniAudio 2.0 проходит предварительное обучение с использованием подхода LargeScaleTraining, включающего разнообразные аудио- и текстовые данные. Особое внимание уделяется использованию AuditorySentences — последовательностей аудиофрагментов, предназначенных для стимуляции способности модели к композиционному мышлению и пониманию взаимосвязей между отдельными звуковыми элементами. Такой подход позволяет модели не просто распознавать отдельные звуки, но и анализировать их комбинации и контекст, что положительно влияет на качество выполнения задач, требующих понимания сложной звуковой информации.
Извлечение семантических признаков в UniAudio 2.0 осуществляется посредством MultiExpertSemanticEncoder, архитектуры, предназначенной для выделения модально-специфических признаков из аудиоданных. Этот энкодер использует несколько экспертов, каждый из которых специализируется на извлечении определенных типов признаков, что позволяет модели более эффективно представлять и понимать сложные аудиосигналы. Разделение признаков по модальностям позволяет добиться большей точности и эффективности в задачах, требующих семантического понимания аудиоконтента.
Использование предварительно обученной большой языковой модели (LLM) обеспечивает значительное повышение возможностей модели в обработке и понимании текста. Предварительная инициализация модели с использованием LLM позволяет ей эффективно использовать накопленные знания о языке, включая синтаксис, семантику и контекст. Это приводит к улучшению языкового моделирования, генерации текста и способности к решению задач, требующих глубокого понимания естественного языка, таких как ответы на вопросы и суммирование текста. Перенос знаний из LLM позволяет сократить время обучения и улучшить производительность модели в задачах, связанных с текстом, по сравнению с обучением «с нуля».
Модель, содержащая 3 миллиарда параметров, демонстрирует улучшенные показатели в задачах, решаемых без предварительного обучения (zero-shot), по сравнению с моделями меньшего размера, что подчеркивает важность масштаба модели. В частности, при автоматическом распознавании речи (ASR) достигнуты коэффициенты ошибок слов (Word Error Rate) на уровне современных моделей-аналогов. При генерации текстовых описаний аудио (audio captioning) модель обеспечивает результаты, измеряемые метрикой CIDER, сопоставимые с лучшими в отрасли (SOTA).
К Будущему Унифицированного АудиоИнтеллекта
Разработка ReasoningCodec, в сочетании с функциональной специализацией и масштабным обучением, знаменует собой важный прогресс в создании действительно единого аудиоинтеллекта. Данная модель объединяет обработку и генерацию как аудио, так и текстовой информации в рамках единой архитектуры, что позволяет ей понимать и реагировать на запросы, сформулированные в любой из этих форм. Масштабное обучение на огромных массивах данных обеспечивает высокую точность и гибкость модели, позволяя ей решать сложные задачи, такие как преобразование речи в текст и наоборот, а также генерация реалистичного и качественного аудиоконтента. В результате, ReasoningCodec представляет собой значительный шаг на пути к созданию интеллектуальных систем, способных беспрепятственно взаимодействовать с человеком посредством естественного языка и звука.
Способность модели беспрепятственно обрабатывать и генерировать как аудио, так и текст открывает захватывающие перспективы для широкого спектра приложений. Представьте себе голосовых помощников, которые не просто реагируют на команды, но и понимают нюансы речи, генерируют осмысленные ответы и даже адаптируются к эмоциональному состоянию пользователя. В сфере музыкального творчества, такая технология способна стать мощным инструментом для композиторов, позволяя им мгновенно преобразовывать наброски идей в полноценные музыкальные произведения. Кроме того, эта возможность имеет огромный потенциал в сфере создания контента, упрощая процесс производства аудио- и видеоматериалов, автоматизируя рутинные задачи и позволяя создавать уникальный и персонализированный контент с беспрецедентной скоростью и качеством.
Для обеспечения выдающегося качества реконструированного звука в системе ReasoningCodec используется FlowBasedDiffusionDecoder. Данный декодер, основанный на принципах диффузионных моделей и потоковых сетей, позволяет добиться высокой точности восстановления аудиосигнала, минимизируя искажения и артефакты. В отличие от традиционных методов, FlowBasedDiffusionDecoder способен улавливать тонкие нюансы звука и воссоздавать его с поразительной реалистичностью. Этот подход особенно важен для приложений, требующих безупречного качества звука, таких как создание музыки, обработка речи и генерация аудиоконтента, где даже незначительные дефекты могут существенно снизить восприятие пользователем.
Исследование UniAudio 2.0, с его акцентом на дискретную токенизацию аудио и функционально-специализированную архитектуру, закономерно вызывает усмешку. Авторы стремятся к универсальности, к созданию единой модели для решения широкого спектра задач. Однако, как показывает практика, «всё, что называют scalable, на деле просто не тестировалось под нагрузкой». Универсальность — это иллюзия, рано или поздно система упрётся в ограничения, и тогда элегантная теория столкнётся с суровой реальностью продакшена. Впрочем, попытки объединить аудио и текст достойны внимания, особенно если это помогает хоть немного приблизиться к пониманию того, как работает звук. Как однажды заметил Винтон Серф: «Интернет — это не технология, это способ мышления». И UniAudio 2.0, в своей попытке создать единое аудио-языковое пространство, демонстрирует тот же принцип — стремление к объединению и взаимопониманию.
Что дальше?
Представленная работа, безусловно, добавляет ещё один кирпичик в монумент «фундаментальных моделей» для звука. Однако, не стоит обольщаться. За каждой новой архитектурой, обещающей «универсальное понимание», неминуемо возникнет задача масштабирования. Чем больше данных, тем больше узких мест, и тем быстрее модель начнёт выдавать правдоподобные, но совершенно бессмысленные результаты. Эта UniAudio 2.0, вероятно, покажет себя неплохо в лабораторных условиях, но как она поведет себя, когда её попытаются интегрировать в реальные системы, где шум, помехи и некачественные записи — норма жизни?
Особый интерес вызывает этот “ReasoningCodec”. Дискретизация звука — это всегда компромисс между точностью и вычислительной сложностью. Вопрос в том, насколько этот компромисс оправдан, и не станет ли он «бутылочным горлышком» при решении более сложных задач. Авторегрессионные модели, несмотря на свою элегантность, всё ещё требуют значительных вычислительных ресурсов. Не исключено, что в ближайшем будущем фокус сместится в сторону более эффективных, но менее «теоретически красивых» подходов.
В конечном итоге, UniAudio 2.0 — это ещё один шаг к автоматизации обработки звука. Но не стоит забывать старую истину: автоматизация не решает проблемы, она просто перекладывает её на другого человека. И этот человек, скорее всего, будет вынужден разбираться с ошибками, которые эта модель допустила в самый неподходящий момент.
Оригинал статьи: https://arxiv.org/pdf/2602.04683.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Наука из текста: извлечение знаний из научных публикаций
- Искусственный интеллект: хрупкость визуального мышления
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Моделирование биомолекул: новый импульс от нейросетей
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Облачные вычисления для науки: гибкость и масштабируемость
2026-02-08 23:55