Автор: Денис Аветисян
Исследователи представили инновационную архитектуру для эффективного сжатия и восстановления видеоданных, основанную на диффузионных моделях и трансформерах.

Предлагается One-DVA — видео автоэнкодер, использующий адаптивное сжатие переменной длины и диффузионное декодирование для высококачественной реконструкции и генеративных задач.
Современные модели генерации видео часто сталкиваются с ограничениями, связанными с фиксированным сжатием и негибкостью архитектур. В данной работе представлена модель ‘Adaptive 1D Video Diffusion Autoencoder’, использующая трансформаторный подход для адаптивного одномерного кодирования и диффузионного декодирования видео. Предлагаемая архитектура позволяет динамически регулировать длину скрытого представления и достигать сопоставимого с 3D-CNN автоэнкодерами качества реконструкции при более высокой степени сжатия. Сможет ли подобный подход открыть новые горизонты в области генерации и редактирования видеоконтента, обеспечивая баланс между качеством и эффективностью сжатия?
Преодолевая Ограничения Традиционного Сжатия Видео
Традиционные методы сжатия видео часто сталкиваются с трудностями в сохранении воспринимаемого качества, что приводит к заметным артефактам при реконструкции изображения. Эти артефакты, проявляющиеся в виде блочности, размытости или неточности цветопередачи, возникают из-за потерь информации, неизбежных при уменьшении размера видеофайла. Существующие алгоритмы, оптимизированные для минимизации среднеквадратичной ошибки между исходным и восстановленным изображением, не всегда учитывают особенности человеческого восприятия. В результате, даже незначительные искажения, невидимые для стандартных метрик, могут существенно снижать субъективное качество видео, делая просмотр некомфортным и ухудшая общее впечатление от контента. Разработка методов, способных более эффективно сохранять визуальное качество при высокой степени сжатия, остается актуальной задачей в области обработки видеоинформации.
Традиционные метрики оценки качества восстановления видео, такие как PSNR, часто оказываются неспособными адекватно отразить восприятие человеческим глазом. Даже незначительные искажения, невидимые при анализе на основе пиксельной точности, могут существенно снижать субъективное качество видеоряда. Предложенный подход демонстрирует результат в 36.02 PSNR, что сопоставимо с показателями передовых современных методов, однако, в отличие от них, он нацелен на более точную корреляцию с человеческим восприятием, позволяя выявлять и минимизировать даже слабо выраженные дефекты реконструкции, которые остаются незамеченными стандартными метриками.
Оценка качества восстановления видео не может ограничиваться простым сопоставлением пикселей. Традиционные метрики, хоть и позволяют количественно оценить разницу между исходным и реконструированным изображением, часто не отражают субъективное восприятие человека. Важно учитывать, что зрительная система человека способна игнорировать незначительные погрешности, не влияющие на общее впечатление от видео, но остро реагирует на артефакты, нарушающие целостность изображения. Поэтому для адекватной оценки качества реконструкции необходимы метрики, которые коррелируют с человеческим суждением, учитывая особенности зрительного восприятия и позволяя выявить даже незначительные искажения, влияющие на визуальное качество видеоряда. Такой подход позволяет более точно оценивать эффективность алгоритмов восстановления и создавать видеоматериалы, максимально приближенные к исходному качеству.
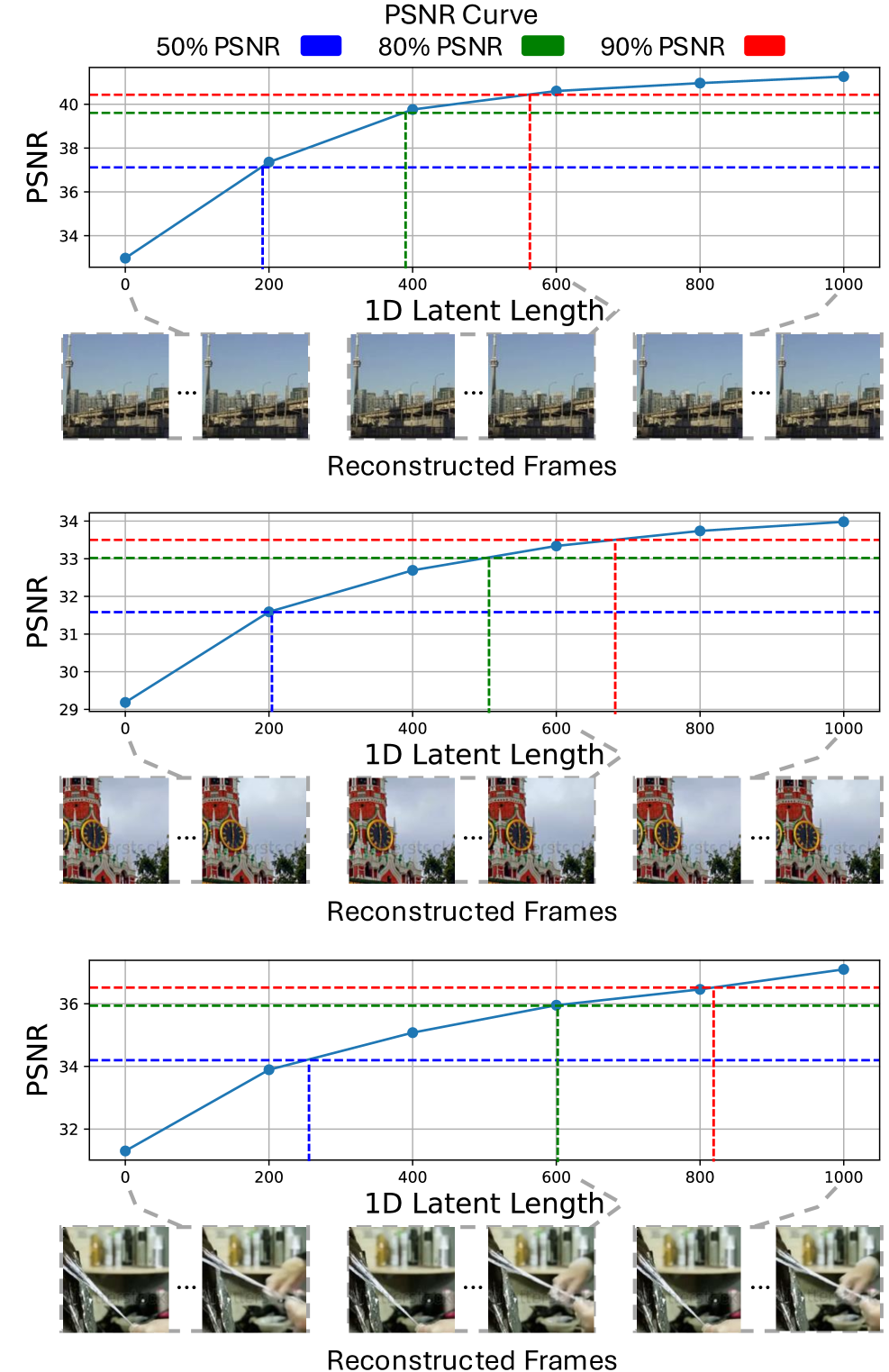
За Пределами Попиксельного Сравнения: Оценка Восприятия
Индекс структурного сходства (SSIM) представляет собой улучшение по сравнению с PSNR, поскольку учитывает структурную информацию изображения, а не только разницу в пикселях. В то время как PSNR оценивает качество изображения на основе среднеквадратичной ошибки между исходным и реконструированным изображением, SSIM анализирует изменения в яркости, контрастности и структуре. Однако, несмотря на эти улучшения, SSIM не полностью соответствует человеческому восприятию, поскольку не учитывает все аспекты визуального качества, такие как текстура и детализация. Это означает, что изображения с высоким значением SSIM могут все еще восприниматься человеком как имеющие недостатки, а изображения с более низким значением SSIM могут казаться визуально более привлекательными.
Функции перцептивных потерь (Perceptual Loss) оптимизируют процесс реконструкции изображений, ориентируясь непосредственно на восприятие человеком, а не на минимальное пиксельное отклонение. В отличие от традиционных метрик, таких как среднеквадратичная ошибка (MSE), они извлекают признаки из промежуточных слоев предварительно обученных сверточных нейронных сетей (CNN), таких как VGG, и минимизируют разницу между этими признаками для исходного и реконструированного изображений. Это позволяет создавать изображения, которые визуально более близки к оригиналу, даже если разница в значениях отдельных пикселей остается значительной. По сути, алгоритм стремится к сохранению высокоуровневых характеристик изображения, влияющих на его восприятие, а не к точной копии пиксельных значений.
Современные метрики оценки качества видео, такие как Reduced Fréchet Video Distance (rFVD) и KL-дивергенция, направлены на количественную оценку не только соответствия (fidelity) сгенерированного видео исходному, но и разнообразия (diversity) генерируемых кадров. В отличие от традиционных метрик, фокусирующихся исключительно на пиксельных различиях, rFVD и KL-дивергенция используют признаки, извлеченные из глубоких нейронных сетей, для сравнения распределений признаков исходного и сгенерированного видео. Наша разработанная методика достигает значения rFVD равного 67.56, что свидетельствует о высоком уровне как соответствия, так и разнообразия в генерируемых видеопотоках.
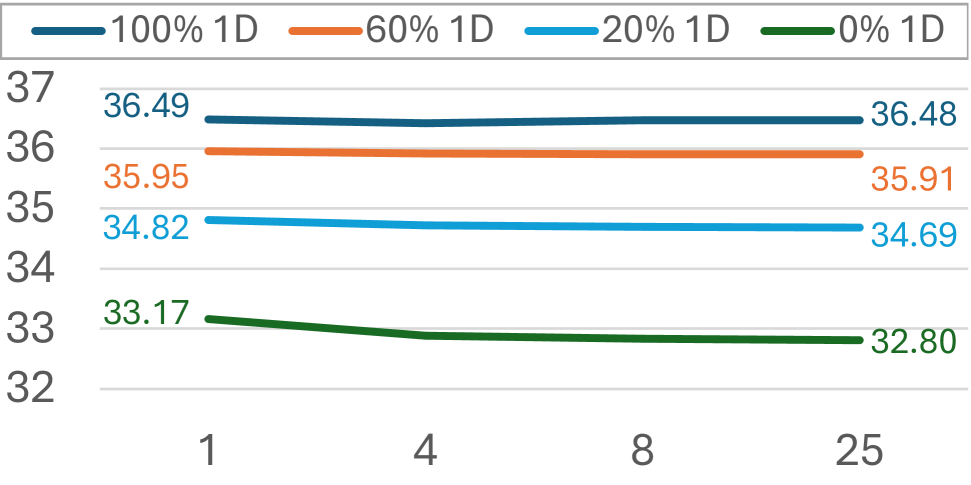
Генеративное Декодирование и Диффузионные Модели для Повышения Точности
Генеративное декодирование использует генеративные модели в качестве декодеров внутри автоэнкодеров, что позволяет создавать более реалистичные и детализированные реконструкции. В отличие от традиционных автоэнкодеров, использующих детерминированные слои для декодирования, генеративные модели, такие как вариационные автоэнкодеры (VAE) или генеративно-состязательные сети (GAN), обучаются генерировать данные, близкие к исходному распределению. Это позволяет восстанавливать недостающие или поврежденные данные с большей точностью и создавать более правдоподобные результаты, особенно в задачах, где требуется высокая степень детализации и реалистичности, например, при восстановлении видео или изображений высокого разрешения.
Диффузионные модели играют ключевую роль в генеративном декодировании, обеспечивая восстановление видеокадров посредством обучения обращению процессу диффузии. В основе метода лежит постепенное добавление шума к исходному кадру до полного искажения, после чего модель обучается восстанавливать кадр из шума, шаг за шагом удаляя добавленный шум. Этот процесс, основанный на вероятностном моделировании, позволяет генерировать высококачественные и детализированные кадры, эффективно решая задачу восстановления информации, утраченной при сжатии или повреждении видео.
Для повышения эффективности обучения диффузионных моделей и стабилизации процессов генерации и реконструкции видео используется методика Flow Matching. В ходе экспериментов, применение данной методики позволило достичь качества сгенерированного видео, оцениваемого метрикой gFVD в 210.9, что соответствует результатам, демонстрируемым моделью Hi-VAE. Это свидетельствует о сравнимой производительности и эффективности предложенного подхода в задачах восстановления и генерации видеоматериалов.

Исследование демонстрирует элегантность подхода к сжатию и реконструкции видео, где ключевым элементом выступает диффузионное декодирование в латентном пространстве. Авторы стремятся к математической чистоте представления данных, что находит отражение в использовании трансформерной архитектуры для эффективного моделирования последовательностей. Как однажды заметил Ян ЛеКун: «Машинное обучение — это математика, замаскированная под магией». Данная работа стремится снять эту маскировку, предлагая доказуемый алгоритм, способный к высококачественной реконструкции видеоданных, а не полагаясь на эмпирические результаты тестов. Особенно заметно стремление к созданию инвариантного представления, позволяющего эффективно решать задачи генерации и сжатия.
Что Дальше?
Представленная работа, хотя и демонстрирует впечатляющие результаты в области реконструкции видео, поднимает ряд вопросов, требующих дальнейшего осмысления. Оптимизация без анализа, как известно, — это самообман и ловушка для неосторожного исследователя. Утверждения о высокой точности реконструкции должны быть подтверждены не только количественными метриками, но и строгим математическим доказательством сходимости процесса декодирования. Иначе говоря, необходимо продемонстрировать, что предложенный метод действительно приближается к оптимальному решению, а не просто хорошо работает на ограниченном наборе тестовых данных.
Особое внимание следует уделить масштабируемости предложенного подхода. Использование архитектуры Transformer, хотя и оправдано с точки зрения возможности моделирования долгосрочных зависимостей, влечет за собой значительные вычислительные затраты. Необходимо исследовать альтернативные методы сжатия и декодирования, которые обеспечивали бы сравнимую точность реконструкции при меньших вычислительных ресурсах. В частности, перспективным направлением представляется разработка алгоритмов, основанных на принципах разреженного представления и сжатия информации.
Наконец, следует признать, что предложенный метод, как и большинство современных подходов к генеративному моделированию, остается «черным ящиком». Понимание того, как именно происходит процесс декодирования и генерации видео, является ключевым для разработки более надежных и контролируемых систем. Разработка методов интерпретации и визуализации латентного пространства представляется важной задачей, способной раскрыть скрытые закономерности и улучшить качество генерируемого видео.
Оригинал статьи: https://arxiv.org/pdf/2602.04220.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Самообучающиеся признаки: новый подход к машинному обучению
- Иллюзия Компетентности: Как ИИ Переоценивает Себя
2026-02-09 01:29