Автор: Денис Аветисян
Исследователи предлагают инновационный метод адаптивной фильтрации токенов, позволяющий значительно повысить эффективность диффузионных трансформеров без потери качества генерируемых изображений.
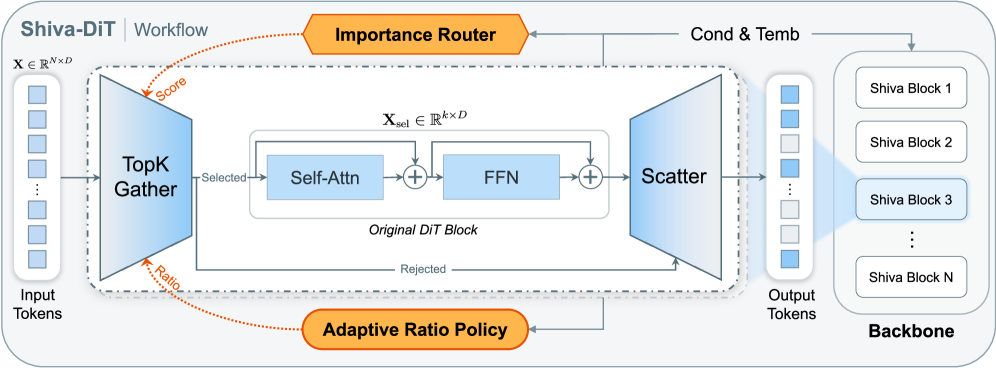
Представлен фреймворк Shiva-DiT, использующий остаточную дифференцируемую сортировку и адаптивную политику для эффективного отсеивания токенов в диффузионных трансформерах.
Вычислительные затраты, связанные с архитектурами Diffusion Transformers (DiT), становятся препятствием для их широкого применения, особенно при строгих ограничениях аппаратных ресурсов. В данной работе, представленной под названием ‘Shiva-DiT: Residual-Based Differentiable Top-$k$ Selection for Efficient Diffusion Transformers’, предлагается новый подход к разрежению DiT, основанный на дифференцируемом отборе наиболее значимых токенов с использованием остаточных связей. Этот метод позволяет достичь значительного ускорения вычислений, сохраняя при этом высокую точность генерации изображений благодаря адаптивной политике выбора токенов и эффективной оценке градиентов. Сможет ли Shiva-DiT стать ключевым элементом в создании более эффективных и доступных моделей генеративного искусственного интеллекта?
Эффективность Трансформеров: Квадратичная Сложность как Препятствие
Несмотря на впечатляющие успехи в различных областях, стандартные архитектуры Transformer сталкиваются с серьезными трудностями при масштабировании вычислительных ресурсов. Основная проблема заключается в том, что сложность вычислений растет квадратично с увеличением длины последовательности, что делает обработку длинных текстов или сложных данных крайне затратной. Это препятствует применению Transformer в задачах, требующих глубокого анализа и рассуждений, таких как обработка больших объемов научной литературы, детальный анализ видео или создание сложных диалоговых систем. В результате, потенциал этих мощных моделей ограничивается доступными вычислительными мощностями, что требует разработки новых подходов к оптимизации и масштабированию архитектуры Transformer.
Для достижения более глубокого понимания и сложных рассуждений нейронные сети-трансформеры требуют экспоненциального увеличения вычислительных ресурсов. Эта потребность обусловлена тем, что количество операций, необходимых для обработки последовательности, растет пропорционально квадрату её длины O(n^2). Это означает, что при увеличении длины входной последовательности в два раза, требуемое количество вычислений увеличивается в четыре раза, что создает серьезные ограничения для обработки длинных текстов, видео или других последовательных данных. Такая квадратичная сложность становится критическим препятствием для масштабирования трансформеров и применения их к задачам, требующим анализа больших объемов информации, что стимулирует поиск новых архитектур и алгоритмов, способных снизить вычислительные затраты без потери качества.
Современные методы разреженной обработки в нейронных сетях, направленные на повышение скорости вычислений, часто оказываются перед сложным компромиссом. Стремление к эффективности нередко приводит к снижению качества модели, поскольку упрощения, необходимые для ускорения, могут негативно сказаться на способности сети к глубокому анализу и точному прогнозированию. Эта ситуация формирует своего рода трилемму: сохранение дифференцируемости — необходимое условие для обучения, — поддержание высокой эффективности — ключевой фактор для работы с большими объемами данных, — и соблюдение жестких бюджетных ограничений на вычислительные ресурсы. Попытки оптимизировать один из этих аспектов, как правило, приводят к ухудшению двух других, что требует разработки принципиально новых подходов к разреженной обработке, способных преодолеть данное противоречие и обеспечить оптимальный баланс между качеством, скоростью и стоимостью вычислений.
Динамическая Обрезка Токенов: Первый Шаг к Эффективности
Динамическое отбрасывание токенов (Dynamic Token Pruning) представляет собой метод снижения вычислительной нагрузки в моделях обработки последовательностей путём выборочного исключения токенов в процессе обработки. В отличие от статического прунинга, осуществляемого до развертывания модели, динамический прунинг позволяет адаптироваться к входным данным и отбрасывать наименее информативные токены непосредственно во время инференса. Это достигается путем оценки значимости каждого токена и исключения тех, которые не оказывают существенного влияния на выходные данные модели. В результате уменьшается объем вычислений, необходимый для обработки последовательности, что потенциально ведет к ускорению работы модели и снижению энергопотребления.
Для динамического отсечения токенов предлагается ряд методов, включая Gumbel-Softmax, DiffCR и NeuralSort. Gumbel-Softmax использует дискретные выборочные методы, что может приводить к градиентным проблемам при обучении. DiffCR (Differentiable Convolutional Rate) применяет дифференцируемые операции для определения важности токенов, однако требует дополнительных вычислений. NeuralSort ранжирует токены на основе их значимости, но страдает от высокой вычислительной сложности и потенциального увеличения объема памяти, особенно при работе с длинными последовательностями. Каждый из этих подходов имеет свои ограничения в плане эффективности, точности и применимости к различным архитектурам нейронных сетей.
Несмотря на потенциальную эффективность, существующие методы динамической обрезки токенов часто сталкиваются с компромиссами. Некоторые реализации ориентированы прежде всего на совместимость с существующим аппаратным обеспечением, что ограничивает их оптимизацию. Другие испытывают трудности с обучаемостью, требуя значительных вычислительных ресурсов для достижения приемлемой точности. Важной проблемой является и сложность масштабирования: некоторые подходы вводят квадратичную зависимость потребления памяти от длины последовательности O(n^2), что делает их непрактичными для обработки длинных текстов или больших пакетов данных.
Shiva-DiT: Разрешение Трилеммы с Помощью Дифференцируемой Сортировки
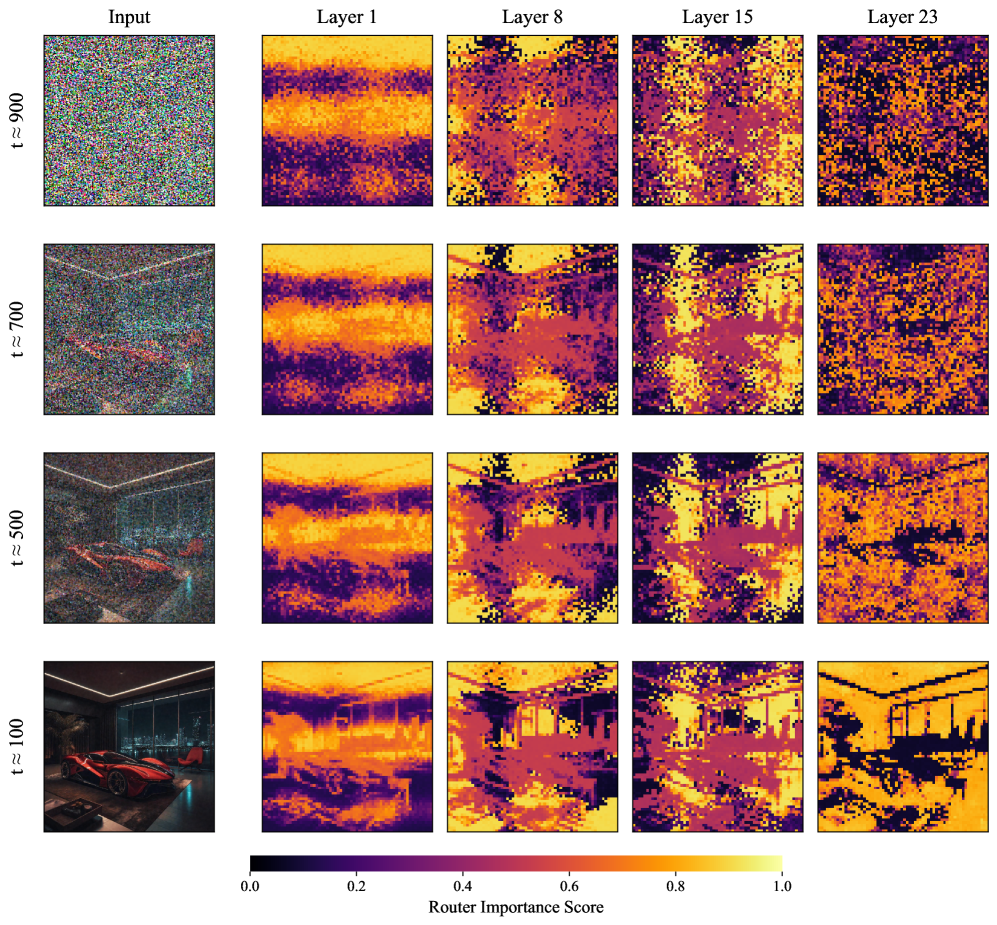
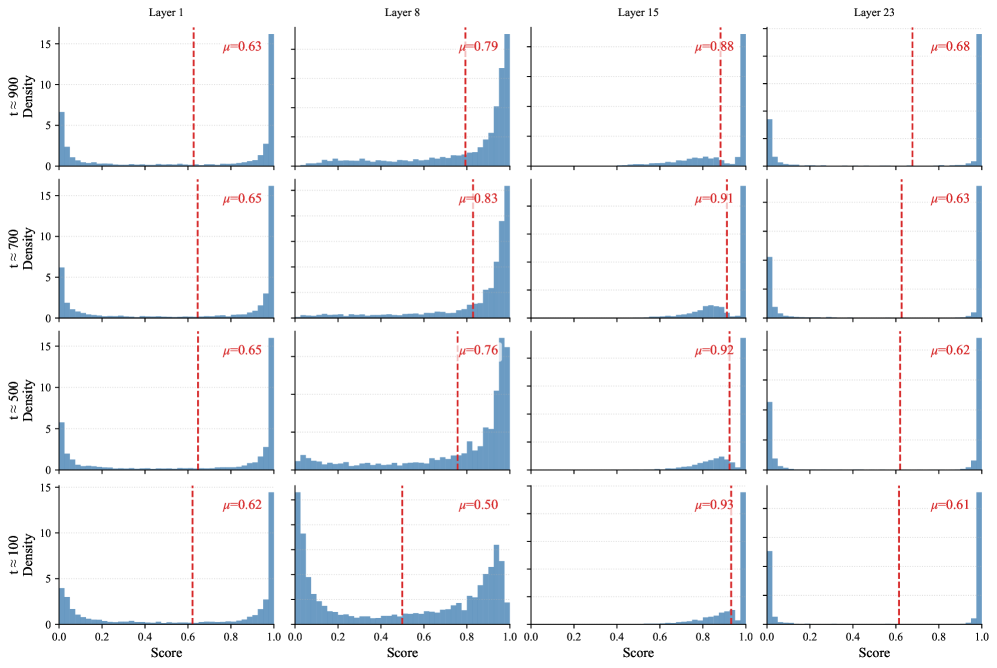
Shiva-DiT представляет собой новую структуру, направленную на решение проблемы компромисса между эффективностью, качеством и скоростью обработки в задачах генерации изображений. В основе подхода лежит дифференцируемая сортировка токенов, реализованная в рамках остаточных блоков (residual blocks). Это позволяет динамически определять наиболее важные токены и оптимизировать вычислительные ресурсы, направляя их на обработку этих токенов. В отличие от традиционных методов, требующих дискретных решений о прореживании, Shiva-DiT использует непрерывный процесс сортировки, что обеспечивает более точную и эффективную оптимизацию модели и позволяет достичь баланса между скоростью и качеством генерации.
В основе Shiva-DiT лежит механизм контекстно-зависимого маршрутизатора (Context-Aware Router), предназначенного для оценки важности токенов на основе текущего контекста входных данных. Эта оценка используется в сочетании с адаптивной политикой распределения вычислительных ресурсов (Adaptive Ratio Policy), которая динамически регулирует объем вычислений, выделяемых каждому токену, как в пространстве признаков, так и во времени. Политика позволяет назначать больше вычислительных ресурсов наиболее важным токенам, тем самым оптимизируя общую эффективность обработки и снижая вычислительные затраты на менее значимые элементы последовательности. Данный подход обеспечивает эффективное распределение ресурсов, направленное на максимизацию качества генерируемых данных при минимальных вычислительных затратах.
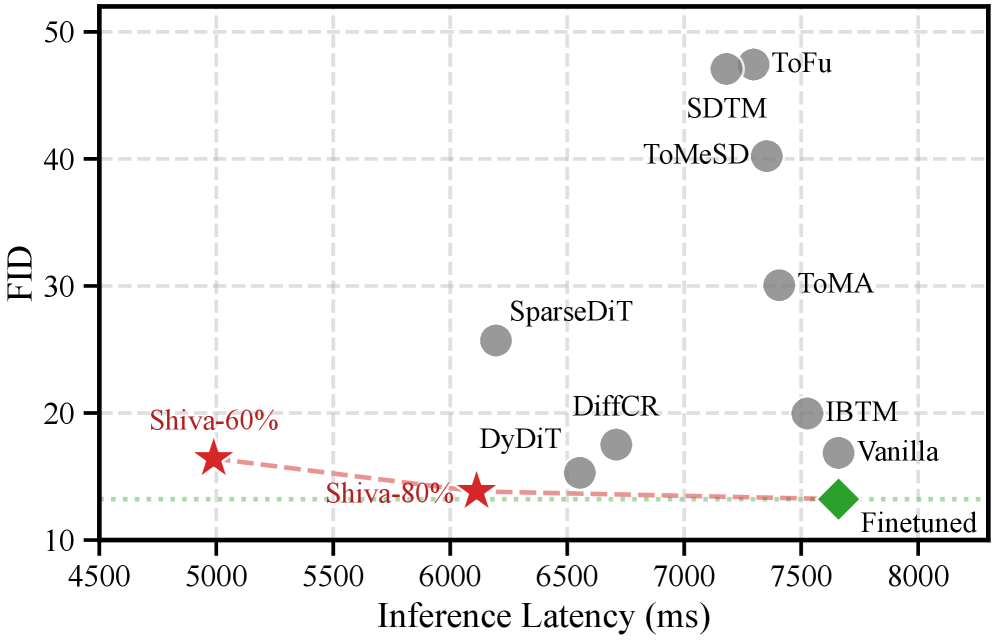
Ключевым нововведением в Shiva-DiT является формулировка отсеивания токенов как дифференцируемого выбора top-k внутри остаточных блоков. Для обеспечения стабильности обучения используется оценочный градиент и нормализация слоев. В результате, Shiva-DiT демонстрирует ускорение в 1.54 раза по времени выполнения (wall-clock speedup) при сохранении превосходной генеративной точности на бенчмарке SD3.5. Данный подход позволяет эффективно оптимизировать вычислительные ресурсы, выделяя наиболее важные токены для обработки и повышая общую скорость генерации изображений без снижения качества.

Shiva-DiT в Действии: Интеграция с Диффузионными Трансформерами
Shiva-DiT органично встраивается в архитектуру Diffusion Transformers — мощного подхода к генеративному моделированию, основанного на последовательном уточнении данных из случайного шума. Данная интеграция позволяет использовать сильные стороны обеих технологий: эффективность и масштабируемость Shiva-DiT сочетаются с возможностями Diffusion Transformers по созданию высококачественных и реалистичных изображений. Такое взаимодействие открывает новые горизонты в области генерации контента, позволяя создавать сложные и детализированные изображения с повышенной скоростью и меньшими вычислительными затратами. В результате, Shiva-DiT не просто ускоряет существующие модели, но и расширяет их потенциал, обеспечивая более эффективный и гибкий процесс генерации.
В рамках данной архитектуры для повышения эффективности используются такие передовые методы, как RoPE (Rotary Positional Embeddings) и Classifier-Free Guidance. RoPE позволяет модели эффективно обрабатывать информацию о положении элементов в последовательности, что критически важно для генерации связных и реалистичных изображений. Classifier-Free Guidance, в свою очередь, обеспечивает более точное управление процессом генерации, позволяя модели фокусироваться на наиболее релевантных характеристиках и создавать изображения, соответствующие заданным условиям. Комбинация этих методов значительно улучшает качество генерируемых образцов и позволяет достичь выдающихся результатов в сложных задачах генерации, что подтверждается высокими показателями, такими как FID = 13.83 на бенчмарке SD3.5 и IQA = 0.5051, превосходящими все существующие методы ускорения.
Интеграция Shiva-DiT с диффузионными трансформаторами демонстрирует значительное повышение эффективности масштабирования и качества генерируемых образцов в сложных задачах. В ходе тестирования на бенчмарке SD3.5, Shiva-DiT достиг показателя FID в 13.83 и оценки IQA в 0.5051 — наивысших результатов среди всех известных методов ускорения генерации изображений. Данные метрики свидетельствуют о способности Shiva-DiT создавать более реалистичные и детализированные изображения при сохранении высокой скорости работы, что делает его перспективным решением для ресурсоемких задач генеративного моделирования.
Будущее Эффективных Рассуждений: За Пределами Shiva-DiT
Разработка Shiva-DiT знаменует собой существенный прогресс в области создания эффективных и масштабируемых систем искусственного интеллекта. В основе этой инновации лежит применение дифференцируемой сортировки, позволяющей оптимизировать процессы обучения и обработки данных. В отличие от традиционных методов, требующих значительных вычислительных ресурсов, дифференцируемая сортировка позволяет алгоритму самостоятельно адаптироваться и находить оптимальные решения, что значительно повышает скорость и эффективность работы модели. Данный подход открывает новые возможности для создания более мощных и экономичных систем ИИ, способных решать сложные задачи в различных областях, от обработки естественного языка до компьютерного зрения.
Дальнейшие исследования направлены на расширение возможностей разработанной архитектуры и применение её к более сложным моделям и задачам. Ученые планируют адаптировать принципы дифференцируемой сортировки, успешно реализованные в текущей работе, для решения задач, требующих обработки значительно больших объемов данных и выполнения более сложных вычислений. Особое внимание уделяется возможности интеграции данного подхода с другими передовыми методами машинного обучения, что позволит создавать гибридные системы, сочетающие в себе преимущества различных технологий. Ожидается, что расширение рамок применения данной архитектуры откроет новые перспективы в областях, требующих эффективной обработки и анализа информации, таких как компьютерное зрение, обработка естественного языка и робототехника.
Разработка Shiva-DiT открывает перспективы для создания искусственного интеллекта, способного к эффективному и быстрому рассуждению в самых разных областях. Достигнутая скорость обучения в 1.73 it/s и сокращение времени на эпоху до приблизительно 35 минут, а также 1.24-кратное ускорение по сравнению с базовой моделью Flux.1-dev, демонстрируют значительный прогресс в масштабируемости и производительности. Это позволяет создавать более сложные и интеллектуальные системы, способные решать задачи, требующие логического мышления и анализа, и тем самым расширяет возможности применения ИИ в науке, инженерии, медицине и других ключевых сферах человеческой деятельности.
Предложенный Shiva-DiT демонстрирует глубокое понимание неизбежной энтропии в сложных системах. Авторы, стремясь к ускорению Diffusion Transformers за счет отсеивания токенов, не просто оптимизируют производительность, но и признают, что любая система со временем стареет. Как однажды заметил Винтон Серф: «Интернет — это не просто сеть компьютеров, это сеть людей». Это наблюдение применимо и к Shiva-DiT: адаптивная политика и дифференцируемый механизм сортировки позволяют системе эволюционировать и сохранять функциональность, несмотря на потерю части ресурсов. Работа подчеркивает, что инциденты — не ошибки, а шаги к зрелости, позволяющие системе приспосабливаться и становиться более устойчивой к изменениям.
Что Дальше?
Представленный фреймворк Shiva-DiT, безусловно, демонстрирует возможность ускорения Diffusion Transformers посредством адаптивной «редкости» токенов. Однако, не стоит забывать: каждая оптимизация — это лишь временное состояние, задержка, которую платит каждый запрос за кажущуюся эффективностью. Вопрос не в том, насколько быстро система обрабатывает данные, а в том, как долго она сможет поддерживать приемлемое качество генерации в условиях постоянно растущих требований к разрешению и сложности изображений.
Ключевым ограничением остается зависимость от дифференцируемой сортировки, которая, по сути, является попыткой обмануть время. Стабильность, которую она обеспечивает, — это иллюзия, закэшированная вычислениями. Будущие исследования, вероятно, будут сосредоточены на поиске более элегантных решений, возможно, вдохновленных принципами самоорганизующихся систем, где «обрезание» токенов происходит не насильственно, а естественно, как часть процесса обучения.
Следует признать, что настоящая проблема заключается не в ускорении отдельных операций, а в создании систем, способных к эволюции и адаптации. Ведь все системы стареют — вопрос лишь в том, делают ли они это достойно. В конечном итоге, успех Shiva-DiT будет определяться не его текущей производительностью, а его способностью предвосхищать и решать проблемы, которые еще предстоит увидеть.
Оригинал статьи: https://arxiv.org/pdf/2602.05605.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Искусственный интеллект: хрупкость визуального мышления
- Моделирование биомолекул: новый импульс от нейросетей
- Ruyi2: Семейство языковых моделей для эффективного обучения и развертывания
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Самообучающиеся признаки: новый подход к машинному обучению
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Облачные вычисления для науки: гибкость и масштабируемость
2026-02-09 01:37