Автор: Денис Аветисян
Исследователи представили HIVE — систему, позволяющую языковым моделям анализировать изображения более глубоко и делать более обоснованные выводы, не полагаясь только на текстовые объяснения.
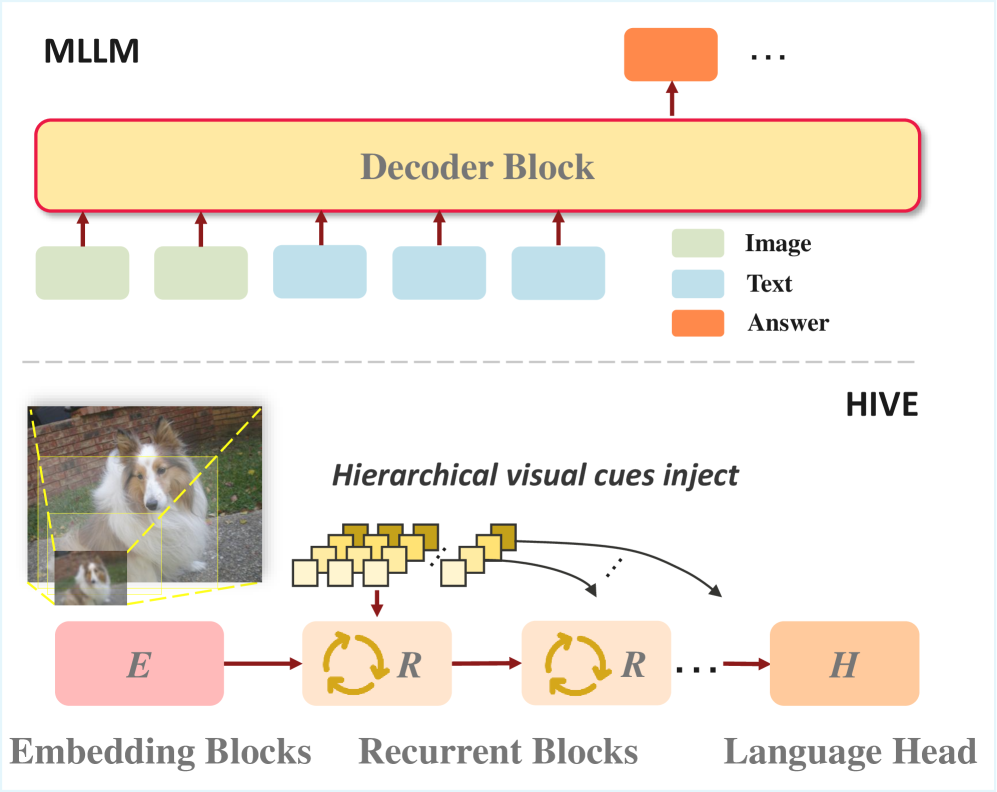
Новая система HIVE использует иерархические визуальные подсказки и петлевые трансформаторы для обеспечения более надежного и продуманного рассуждения в мультимодальных больших языковых моделях.
Несмотря на впечатляющие возможности современных мультимодальных больших языковых моделей, их рассуждения зачастую сводятся к поверхностным, «быстрым» выводам, подверженным галлюцинациям. В данной работе, посвященной проблеме ‘Multimodal Latent Reasoning via Hierarchical Visual Cues Injection’, предлагается новый подход к организации рассуждений в скрытом пространстве, интегрирующий визуальные сигналы различного уровня детализации. Предложенный фреймворк HIVE, использующий рекурсивные трансформаторные блоки и иерархические визуальные подсказки, позволяет модели осуществлять многоступенчатый, обоснованный вывод, избегая зависимости от явных текстовых объяснений. Способна ли подобная архитектура обеспечить более глубокое понимание сложных сцен и открыть новые горизонты в области визуального мышления?
Пределы Явного Рассуждения
Традиционные большие языковые модели, несмотря на свою вычислительную мощь, часто испытывают трудности при решении сложных, многоступенчатых задач, полагаясь на последовательную обработку информации — токен за токеном. Этот подход, хотя и позволяет обрабатывать огромные объемы текста, становится узким местом при необходимости синтеза информации или вывода новых знаний. Каждая операция требует значительных вычислительных ресурсов, а вероятность ошибки возрастает с каждым шагом рассуждений. В отличие от человеческого мышления, способного к параллельной обработке и интуитивным скачкам, модели обрабатывают информацию линейно, что ограничивает их способность к эффективному решению задач, требующих глубокого понимания контекста и абстрактного мышления.
Традиционный подход к обработке информации в больших языковых моделях, основанный на последовательном анализе токенов, требует значительных вычислительных ресурсов. Эта методика становится особенно уязвимой при работе с визуальными данными, где даже незначительные нюансы могут существенно повлиять на конечный результат. Поскольку каждая деталь изображения требует отдельной обработки, вероятность ошибки экспоненциально возрастает, что ограничивает способность моделей к надежному и точному визуальному рассуждению. Таким образом, сложность и затратность данного подхода подчеркивает необходимость разработки более эффективных механизмов, способных к обобщению и абстракции визуальной информации.
Потребность в более эффективных и надежных механизмах рассуждений стимулировала исследования альтернативных архитектур, имитирующих человеческое “Системное мышление 2”. В отличие от традиционных моделей, полагающихся на последовательную обработку информации, эти новые подходы стремятся воспроизвести способность к осознанному, целенаправленному анализу и синтезу, характерную для людей. Такие архитектуры, часто вдохновленные когнитивной психологией, включают в себя механизмы для формирования гипотез, планирования действий и самоконтроля, позволяя моделям не просто обрабатывать данные, но и активно строить логические цепочки и оценивать их достоверность. Исследователи полагают, что подобные системы способны преодолеть ограничения, присущие традиционным моделям, и достичь более высокого уровня интеллектуальной гибкости и адаптивности.
Погружение во Латентное Пространство: Рассуждения без Явного Вычисления
Рассуждение в скрытом пространстве (Latent Space Reasoning) представляет собой принципиально новый подход к вычислениям, осуществляя обработку информации непосредственно в непрерывном скрытом состоянии модели. В отличие от традиционных методов, оперирующих с дискретными токенами и требующих явного манипулирования символами, данный подход позволяет выполнять вычисления, изменяя значения векторов в скрытом пространстве. Это позволяет обходить ограничения, связанные с обработкой больших объемов данных в формате токенов, и потенциально значительно повышает скорость и эффективность рассуждений, особенно в задачах, требующих обработки сложных взаимосвязей и паттернов.
Методы, такие как ‘Coconut’ и ‘SoftCoT’, реализуют перевод этапов логических рассуждений в манипуляции со скрытым состоянием модели. ‘Coconut’ использует механизм извлечения и повторного использования релевантной информации из скрытого состояния, а ‘SoftCoT’ позволяет модели генерировать “мягкие” (вероятностные) цепочки рассуждений непосредственно в скрытом пространстве, избегая необходимости в явном представлении токенов. Такой подход обеспечивает более компактное представление данных и ускоряет процесс вычислений, поскольку операции выполняются непосредственно над непрерывными векторами в скрытом пространстве, а не над дискретными символами.
Использование латентного пространства для вычислений позволяет снизить вычислительную нагрузку и повысить эффективность рассуждений, особенно при работе с визуальными данными. Традиционные методы требуют явной обработки токенов и промежуточных результатов, что связано с большими затратами памяти и времени. В отличие от них, методы, такие как Coconut и SoftCoT, оперируют непосредственно в непрерывном скрытом состоянии модели, представляя шаги рассуждений как манипуляции в этом пространстве. Это приводит к более компактному представлению информации и ускоряет процесс вычислений, поскольку исключается необходимость в явном хранении и обработке промежуточных токенов. Преимущества наиболее заметны при работе с визуальными входами, где размер входных данных может быть значительным, а необходимость в обработке большого количества токенов — критичной.
![В нашей системе предварительно обученный визуальный энкодер сопоставляет визуальные признаки с пространством встраивания большой языковой модели посредством группы легковесных блоков объединения патчей, при этом токен [CLS] удаляется для обеспечения мультимодального выравнивания.](https://arxiv.org/html/2602.05359v1/x2.png)
HIVE: Мультимодальный Разум в Латентном Пространстве
Фреймворк HIVE демонстрирует расширение подхода Latent Space Reasoning на мультимодальные задачи, объединяя визуальную и лингвистическую информацию для улучшения процесса рассуждений. В основе лежит идея представления визуальных данных в латентном пространстве, сопоставимом с текстовым, что позволяет большой языковой модели (LLM) эффективно обрабатывать и интегрировать оба типа данных. Это достигается путем преобразования визуальных признаков в векторное представление, совместимое с пространством вложений LLM, и последующего объединения этих векторов с текстовыми данными для формирования единого контекста. В результате, LLM может осуществлять рассуждения, опираясь на информацию, полученную из обоих модальностей, что повышает точность и надежность принимаемых решений.
Архитектура “Loop Transformer” в составе HIVE обеспечивает рекурсивную обработку данных, позволяя модели итеративно уточнять свои выводы на основе визуальной и текстовой информации. Иерархическое внедрение визуальных сигналов (Hierarchical Visual Cue Injection) позволяет эффективно интегрировать детализированные визуальные признаки на различных уровнях абстракции. Этот процесс начинается с извлечения базовых визуальных признаков и постепенно интегрирует более сложные, контекстуально значимые детали, что повышает точность и надежность процесса рассуждений модели. Рекурсивная обработка и иерархическое внедрение визуальных признаков совместно позволяют HIVE эффективно использовать мультимодальные данные для решения сложных задач, требующих глубокого понимания визуального контента.
Модули “Patch Merger” и “Vision Encoder” обеспечивают эффективную трансформацию визуальных признаков в формат, совместимый с пространством вложений большой языковой модели (LLM). “Vision Encoder” преобразует входное изображение в последовательность векторов признаков. “Patch Merger” затем объединяет эти векторы, оптимизируя их для соответствия размерности и структуре, ожидаемой LLM. Этот процесс позволяет бесшовно интегрировать визуальную информацию в процесс рассуждений языковой модели, избегая потери данных и обеспечивая эффективное использование вычислительных ресурсов.
Фреймворки, такие как HIVE, демонстрируют эффективность комбинирования рассуждений в латентном пространстве с методами обучения с контролем результата, например, Vision-r1, для обеспечения достоверности рассуждений. Vision-r1 использует подход обучения с подкреплением, вознаграждая модель за корректные ответы и наказывая за неверные, что позволяет оптимизировать процесс рассуждений непосредственно на основе желаемого результата. Комбинирование этого с латентным пространством позволяет модели эффективно кодировать и обрабатывать информацию, получая доступ к более широкому контексту и улучшая способность к обобщению. Такой подход способствует повышению надежности и точности выводимых заключений, особенно в сложных задачах, требующих интеграции различных источников информации.
За Пределами Текущих Ограничений: Влияние и Перспективы Развития
Переход от явной манипуляции токенами к неявным вычислениям в латентном пространстве открывает новые горизонты для создания более эффективных и масштабируемых мультимодальных моделей. Традиционные подходы, требующие последовательной обработки каждого шага рассуждений в виде токенов, оказываются вычислительно затратными и ограничивают возможности параллельной обработки. Новые методы, напротив, позволяют сжать сложные цепочки рассуждений в компактные представления в латентном пространстве, где вычисления могут производиться значительно быстрее и эффективнее. Это особенно важно для обработки больших объемов данных и работы с ресурсоограниченными устройствами, где оптимизация вычислительных ресурсов является критически важной задачей. Такой подход не только ускоряет процесс рассуждений, но и позволяет создавать модели, способные к более сложным и абстрактным умозаключениям, что является ключевым шагом на пути к созданию действительно интеллектуальных систем.
Способность сжимать сложные этапы рассуждений в латентные состояния открывает значительные преимущества в условиях ограниченных ресурсов. Вместо обработки каждого шага логической цепочки, модели, использующие данный подход, кодируют всю последовательность рассуждений в компактное представление, что существенно снижает вычислительные затраты и потребление памяти. Это особенно важно для развертывания передовых моделей искусственного интеллекта на мобильных устройствах, встроенных системах или в сценариях, где доступ к большим вычислительным мощностям ограничен. Такая компрессия не только повышает эффективность, но и позволяет интегрировать сложные процессы рассуждений в более широкие системы, делая их доступными для более разнообразного круга приложений и пользователей.
Исследования, направленные на совершенствование методов сжатия цепочки рассуждений, такие как ‘Heima’, демонстрируют перспективные результаты в повышении эффективности обработки информации. Этот подход, заключающийся в кодировании сложных этапов рассуждений в компактные токены, позволяет значительно снизить вычислительные затраты и объем занимаемой памяти. Параллельно, коллективные алгоритмы поиска, например ‘Mulberry’, открывают возможности для более глубокого и всестороннего анализа данных, объединяя усилия нескольких поисковых стратегий для достижения оптимального решения. Ожидается, что дальнейшее развитие этих направлений позволит создавать модели, способные к более сложному и надежному рассуждению, преодолевая ограничения существующих систем и расширяя границы искусственного интеллекта.
Перспективы развития мультимодального рассуждения неразрывно связаны с созданием архитектур, органично объединяющих вычисления в латентном пространстве с обучением под контролем результатов. Такой подход позволяет моделям не просто обрабатывать информацию из различных источников, но и формировать более достоверные и эффективные цепочки рассуждений. Интеграция латентного пространства, где сложные зависимости кодируются в сжатом виде, с обучением, ориентированным на конечный результат, способствует оптимизации процесса принятия решений и повышению точности прогнозов. В результате, модели смогут не только достигать поставленных целей, но и объяснять логику своих действий, что критически важно для доверия и применения в реальных задачах, требующих прозрачности и надежности.
Исследование, представленное в статье, демонстрирует стремление к созданию систем, способных к более глубокому и обдуманному рассуждению, выходящему за рамки простого сопоставления текстовых данных. Подобный подход к мультимодальному обучению созвучен высказыванию Джеффри Хинтона: «Искусственный интеллект должен уметь учиться, как дети, — сначала быстро и грубо, а потом, с опытом, — медленно и точно». В HIVE, благодаря иерархической инъекции визуальных подсказок и использованию loop transformers, модель получает возможность последовательно уточнять свои выводы, приближаясь к более обоснованным решениям. Такой механизм, по сути, имитирует переход от интуитивного, быстрого мышления (Система 1) к аналитическому, основанному на доказательствах (Система 2), что открывает новые перспективы для развития систем визуального вопросно-ответного анализа.
Куда же дальше?
Представленная работа, несомненно, демонстрирует элегантность подхода к проблеме латентного рассуждения. Однако, истинная проверка любого алгоритма — в его универсальности. Симметричность внедрения иерархических визуальных подсказок в архитектуру Loop Transformers — это шаг к более гармоничному взаимодействию между модальностями, но остается открытым вопрос о масштабируемости данной конструкции. Неизбежно возникнет необходимость в доказательстве устойчивости к «шуму» в визуальных данных — какие минимальные искажения способны нарушить логику, выстроенную в латентном пространстве?
Помимо этого, необходимо учитывать, что «System 1/System 2» мышление — лишь метафора, удобная для понимания, но не являющаяся строгим математическим принципом. Разработка метрик, позволяющих объективно оценивать «глубину» рассуждений модели, представляется сложной, но необходимой задачей. Достаточно ли простого повышения точности ответов на вопросы, или же требуется разработка методов, позволяющих «прочитать» процесс рассуждения модели, убедиться в его корректности и исключить случайные совпадения?
В конечном счете, перспективным направлением представляется исследование возможности интеграции представленного подхода с другими архитектурами, стремящимися к объяснимому искусственному интеллекту. Истинная элегантность алгоритма заключается не только в его эффективности, но и в его способности предоставить ясное и недвусмысленное объяснение своих действий — а это, несомненно, более сложная задача, чем просто достижение высоких показателей точности.
Оригинал статьи: https://arxiv.org/pdf/2602.05359.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Искусственный интеллект, который учится играть: новая платформа для стабильного обучения агентов
- Наука из текста: извлечение знаний из научных публикаций
- Вероятностный компьютер на фотонных чипах: новая эра вычислений
- Моделирование биомолекул: новый импульс от нейросетей
- Сплетение света и времени: аттосекундная спектроскопия на квантовых парах
- Робот-исследователь: новый подход к автономной навигации
- Наука на Автопилоте: Система для Самостоятельных Исследований
- Самообучающиеся признаки: новый подход к машинному обучению
- Биомолекулярные связи: новый тест для искусственного интеллекта
- Искусственный интеллект: хрупкость визуального мышления
2026-02-09 04:50